올림피아드 수학·과학 문제는 LLM reasoning 평가에서 꽤 잔인한 영역이다.
정답 숫자만 맞히는 것으로는 부족하고, 여러 lemma를 세우고, 중간 가정을 검증하고, 마지막에는 엄격한 채점자가 받아들일 수 있는 완전한 증명을 써야 한다.
그래서 최근의 고성능 시스템들은 단순히 더 큰 모델을 샘플링하는 수준을 넘어, 검색·검증·수정 루프를 어떻게 설계할지로 이동하고 있다.
Achieving Gold-Medal-Level Olympiad Reasoning via Simple and Unified Scaling은 이 흐름을 30B-A3B급 오픈 모델 릴리스로 정리한 보고서다.
Shanghai AI Laboratory, CUHK, Tsinghua, Shanghai Jiao Tong, Peking University 연구진은 P1-30B-A3B backbone 위에 SFT, RL, test-time scaling을 단계적으로 얹어 SU-01을 만들고, IMO 2025와 USAMO 2026에서 test-time scaling 기준 35점을 보고한다.
논문 제목의 “simple and unified”는 모든 문제를 하나의 마법 기법으로 푼다는 뜻이 아니라, proof-oriented SFT → answer/proof RL → verification/refinement TTS를 하나의 반복 가능한 post-training 레시피로 묶었다는 의미에 가깝다.
중요한 점은 이 릴리스가 논문 점수만 던지고 끝나지 않는다는 것이다.
프로젝트 페이지, GitHub 저장소, Hugging Face 모델 카드가 함께 공개되어 있고, 모델 가중치도 Apache-2.0 license tag로 비공개 게이트 없이 배포되어 있다.
다만 재현 난이도는 낮지 않다.
학습은 slime 기반 대규모 GPU 인프라를 전제로 하고, 금메달권 수학 성능은 direct generation이 아니라 긴 verification/refinement 루프를 포함한 TTS 결과라는 점을 분리해서 읽어야 한다.
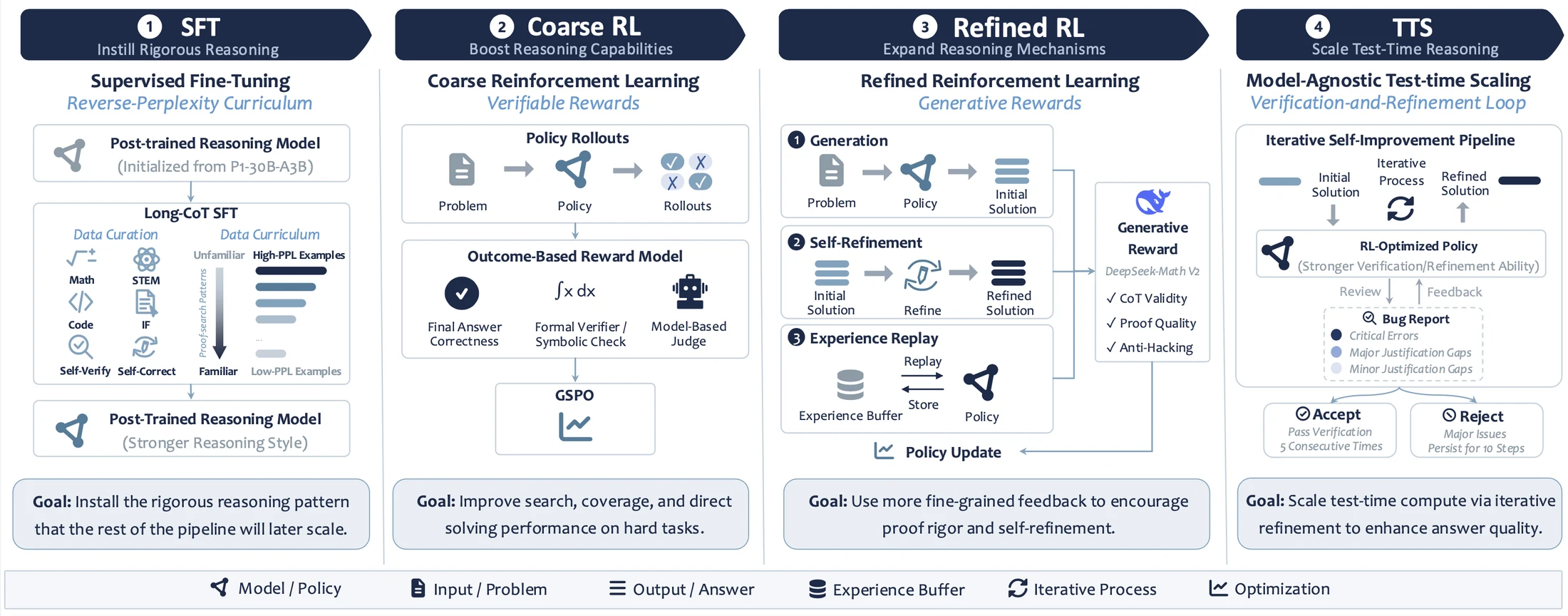
무엇을 해결하려는가
이 논문이 겨냥하는 병목은 “수학 문제를 더 잘 맞히는 모델”보다 더 좁고 어렵다.
올림피아드 문제에서는 모델이 운 좋게 정답을 찍는 것과, 채점 가능한 증명을 구성하는 것이 다르다.
기존 RLVR은 final answer가 검증 가능한 문제에서 강력하지만, 증명의 논리적 빈틈·서술 완성도·중간 주장 검증까지 자동으로 보장하지는 않는다.
또 하나의 병목은 학습과 추론 budget의 분리다.
SFT와 RL로 모델의 기본 reasoning policy를 개선해도, IMO-style proof search는 한 번의 generation 안에서 끝나지 않을 수 있다.
잘못된 lemma를 세웠다가 반례를 찾고, 증명 gaps를 메우고, 다시 전체 풀이를 정리하는 과정은 자연스럽게 여러 라운드의 생성·검증·수정을 요구한다.
SU-01의 질문은 그래서 이렇게 정리된다.
이미 post-trained된 reasoning backbone을, 외부 theorem prover나 code executor에 기대지 않고, 더 엄격한 자연어 proof solver로 바꿀 수 있는가?
논문은 답을 세 단계로 제시한다.
첫째, proof search와 self-checking 행동을 SFT로 주입한다.
둘째, verifiable reward와 proof-level reward를 나눠 RL로 강화한다.
셋째, inference time에는 모델 내부의 verification/refinement 루프에 더 많은 계산을 배정한다.
핵심 아이디어 / 구조 / 동작 방식
SU-01의 구조는 큰 틀에서 보면 post-training pipeline이다.
모델 자체는 Hugging Face config 기준 Qwen3MoeForCausalLM 계열의 MoE 모델이며, 논문과 모델 카드에서는 30B-A3B reasoning model로 설명된다.
하지만 논문의 핵심 기여는 아키텍처보다 어떤 순서로 행동을 바꾸고, 어떤 reward로 강화하고, 언제 추가 inference compute를 쓰는가에 있다.
| 단계 | 공개 자료에서 확인되는 설계 | 역할 |
|---|---|---|
| SFT | 약 338K개의 8K token 이하 long-form trajectory, reverse-perplexity curriculum, 4 epochs | post-trained backbone을 proof search·self-checking·repair 행동으로 재형성 |
| Coarse RL | 8,967개 verifiable prompt, GSPO, final-answer verifier 중심 reward | 정답 탐색 능력을 안정적으로 강화 |
| Refined RL | 16,287개 non-verifiable/proof prompt, DeepSeekMath-V2 기반 proof reward, self-refinement, experience replay | 정답만이 아니라 완전한 증명 품질을 강화 |
| TTS | solve → verify → refine 반복 루프, SGLang serving, 긴 자연어 proof trace | 어려운 문제에 inference-time 계산을 추가 배정 |
첫 단계인 SFT는 단순한 instruction tuning이 아니다.
저자들은 수학, STEM, coding, instruction-following 문제에서 긴 풀이 trajectory를 만들고, 여기에 self-verification과 self-refinement trajectory를 섞는다.
공개 figure 기준 데이터는 direct generation 54.3%, self-improvement 45.7%로 나뉘며, self-verify와 self-refine이 합쳐서 거의 절반을 차지한다.
즉 모델에게 “풀이를 쓰는 법”뿐 아니라 “자기 풀이를 의심하고 고치는 법”을 먼저 보여 주는 구성이다.

여기서 흥미로운 장치가 reverse-perplexity curriculum이다.
초기 policy가 teacher trajectory를 얼마나 낯설게 보는지 length-normalized perplexity로 측정한 뒤, 각 epoch 안에서 PPL이 높은 예시부터 낮은 예시 순으로 학습한다.
직관적으로는 모델이 이미 잘 흉내 내는 예시를 먼저 반복하는 대신, 현재 policy와 가장 먼 rigorous proof trajectory를 먼저 만나게 하는 방식이다.
논문은 이 ordering이 random 또는 ascending-PPL ordering보다 validation behavior를 더 잘 회복한다고 보고한다.
RL은 두 단계다.
Coarse RL은 final answer를 비교적 신뢰성 있게 검증할 수 있는 prompt에서 시작한다.
논문은 GSPO(Group Sequence Policy Optimization)를 사용한다고 설명하는데, token-level GRPO보다 complete-response-level reward assignment와 clipping이 outcome reward 세팅에 더 잘 맞는다는 해석이다. reward pipeline도 text matching, Math-Verify, model verifier, human arbitration 순으로 계층화해 비싼 판단을 뒤로 미룬다.
Refined RL은 더 중요한 전환점이다.
여기서는 “정답이 맞았는가”보다 “증명이 타당한가”가 목표가 된다.
DeepSeekMath-V2를 generative proof reward model로 사용해 전체 풀이의 수학적 타당성과 엄밀성을 평가하고, 실패한 풀이를 critique-and-repair prompt로 바꾸는 self-refinement를 넣는다.
또한 어려운 문제에서 드물게 발견한 성공 trajectory를 experience replay buffer에 저장했다가, 현재 policy가 아직 안정적으로 풀지 못할 때 다시 섞는다.
공개 설정 기준 self-refinement ratio는 0.2, replay ratio는 0.25다.
마지막 TTS는 “더 많이 샘플링한다”보다 구조화된 solve-verify-refine 루프에 가깝다.
모델이 먼저 완전한 후보 풀이를 만들고, verifier가 proof-level critique 또는 bug report를 내고, solver가 그 critique를 조건으로 다시 풀이를 고친다.
USAMO 2026 TTS trace 분석에서 initial solution의 median length는 약 106K tokens, refinement는 약 83K tokens로 보고된다.
금메달권 점수는 이처럼 긴 inference-time proof search를 포함한 결과다.
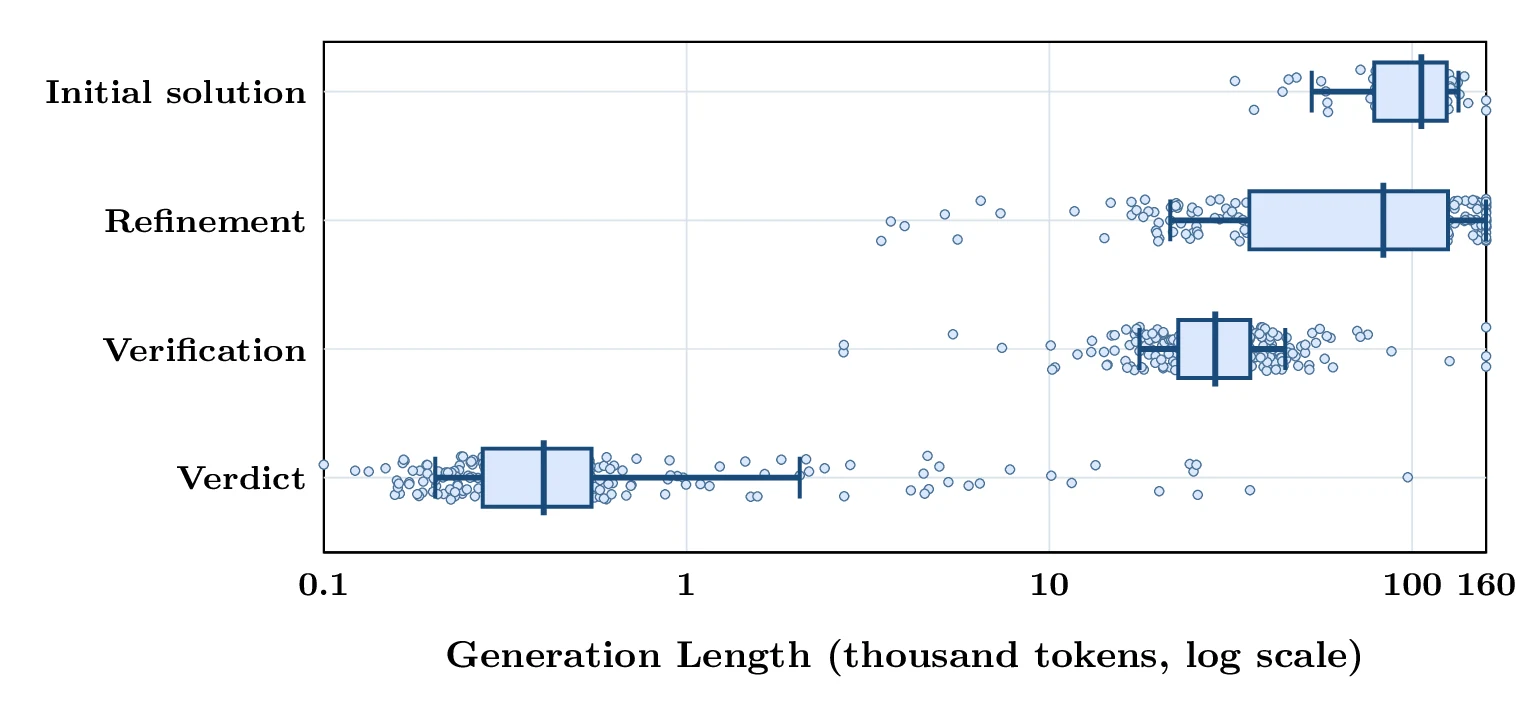
공개된 근거에서 확인되는 점
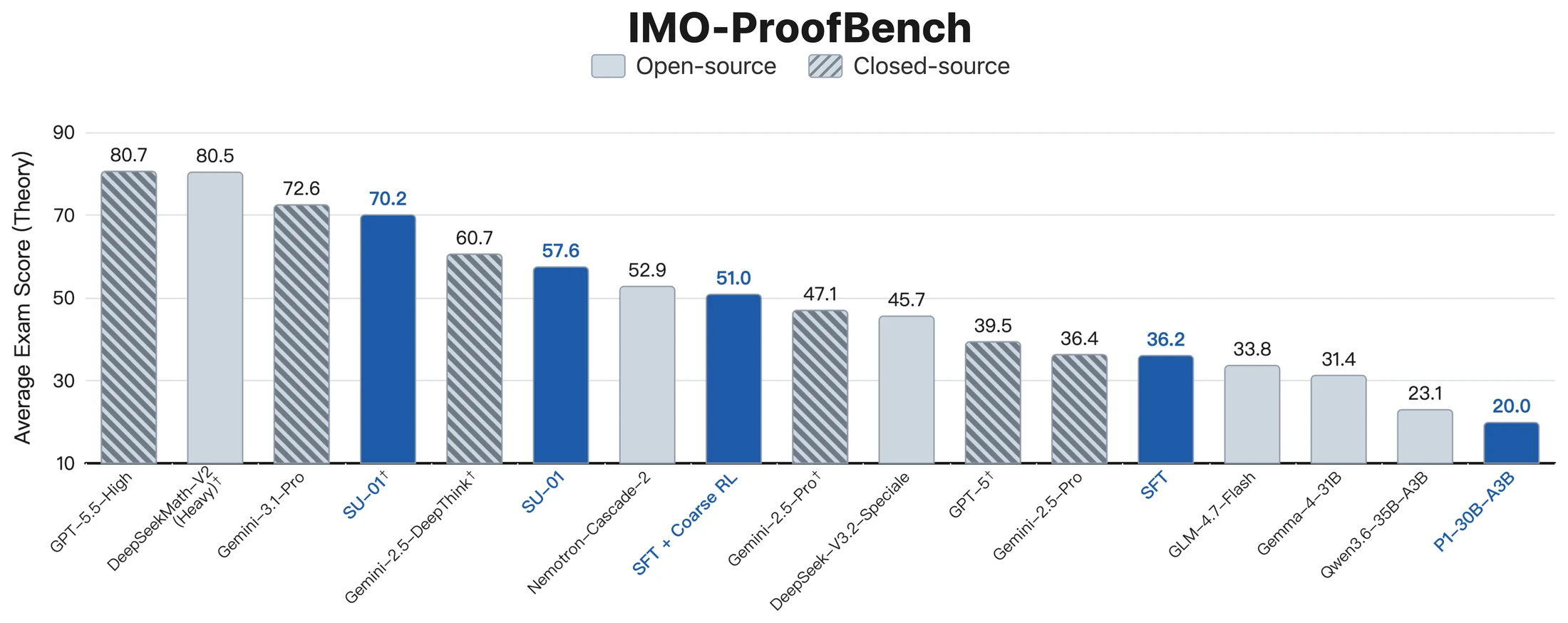
가장 눈에 띄는 결과는 competition-style 점수다.
Direct generation만 보면 SU-01은 IMO 2025에서 21점, USAMO 2026에서 15점이다.
둘 다 bronze line을 넘는 수준이지만 gold는 아니다.
반면 TTS를 적용하면 IMO 2025와 USAMO 2026 모두 35점이 되며, 논문은 이 TTS 결과가 human expert grading을 거쳤다고 표시한다.
| 평가 축 | SU-01 결과 | 해석 |
|---|---|---|
| Answer-verifiable average | 77.3% | Qwen3.6-35B-A3B 77.4%와 거의 같은 similar-size 최고권 |
| AMO-Bench | 59.8% | 표에 제시된 similar-size 비교군 중 최고 |
| AIME 2025/2026 | 94.6% / 93.3% | 수학 final-answer형 benchmark에서는 매우 강함 |
| IMO-ProofBench overall | 57.6% direct / 70.2% TTS | proof-quality 평가에서 TTS가 큰 폭으로 보강 |
| IPhO 2024/2025 | 23.5 → 25.3 / 20.3 → 21.7 | 두 해의 gold line 20.8/19.7을 TTS 기준 모두 초과 |
| IMO 2025 | 21 → 35 | TTS로 gold line 35점에 도달 |
| USAMO 2026 | 15 → 35 | TTS로 gold line 25점을 10점 초과 |
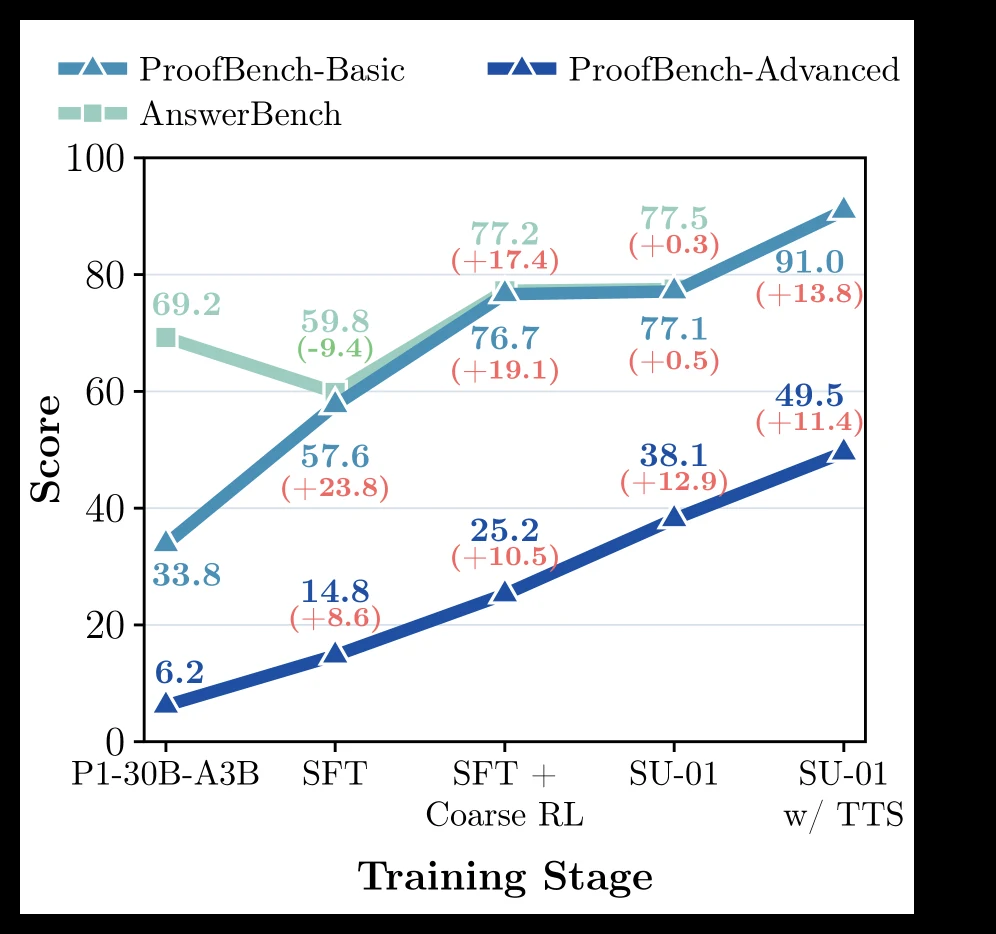
단계별 분석도 이 논문의 메시지와 잘 맞는다.
SFT 직후에는 AnswerBench가 오히려 내려가지만 ProofBench-Basic이 크게 오른다.
이는 SFT가 단기 final-answer 능력을 직접 최적화하기보다, proof-oriented behavior를 바꾸는 단계라는 해석과 일치한다.
Coarse RL은 answer-verifiable 성능을 다시 끌어올리고, refined RL은 ProofBench-Advanced처럼 더 어려운 proof-quality 축에서 이득을 만든다.
마지막 TTS는 특히 advanced proof setting에서 추가 compute를 성능으로 바꾸는 역할을 한다.
공개 릴리스 측면에서도 확인할 점이 많다.
Hugging Face API 기준 Simplified-Reasoning/SU-01은 transformers, safetensors, qwen3_moe, text-generation, long-context, license:apache-2.0 태그를 갖고 있고 gated가 아니다.
모델 파일은 13개의 safetensors shard와 index로 구성되며, index metadata에는 total parameters가 30,532,122,624로 표시된다.
Config에서는 48 layers, hidden size 2048, 128 experts, top-8 experts per token, max position embeddings 262,144가 확인된다.
조회 시점의 API 값은 downloads 265, likes 15로 아직 초기 배포 단계다.
GitHub 저장소 Simplified-Reasoning/SU-01은 논문·프로젝트 페이지·모델 카드와 같은 주장을 교차 확인하게 해 준다.
API 기준 저장소는 2026년 5월 12일 생성됐고, Apache-2.0 license metadata가 있으며, 조회 시점 stars 79, forks 5, open issues 1이다. /releases/latest는 404이고 tags도 비어 있어 versioned library라기보다는 초기 연구 release에 가깝다.
다만 root tree에는 su01-train-slime과 su01-eval이 있고, README는 SFT, coarse RL, refined RL, direct/TTS decoding, verifiable benchmark evaluation 경로를 구분해 설명한다.
실무 관점에서의 해석
SU-01에서 가장 실용적인 메시지는 “올림피아드 추론 성능은 하나의 점수가 아니라 세 종류의 scaling이 겹친 결과”라는 점이다.
데이터 scaling은 긴 proof trajectory와 self-improvement trace를 만든다.
Training scaling은 SFT와 RL을 역할별로 나눈다.
Inference scaling은 검증과 수정을 반복하면서 어려운 문제에 더 많은 token budget을 쓴다.
이 셋을 분리하지 않으면, “30B 모델이 금메달권을 찍었다”라는 너무 납작한 해석이 된다.
특히 direct generation과 TTS 결과를 구분하는 것이 중요하다.
SU-01의 direct generation은 이미 강하지만 IMO 2025와 USAMO 2026에서 gold line에 도달하지는 못한다.
금메달권 결과는 initial solution, verification, refinement, verdict를 포함한 multi-round 절차의 산물이다.
따라서 제품 관점에서는 이 결과를 single-shot latency가 중요한 환경에 그대로 외삽하기 어렵다.
반대로 연구 관점에서는 자연어 proof solver가 긴 critique-and-repair loop를 버틸 때 성능이 얼마나 올라가는지를 보여 주는 강한 사례다.
또 하나의 포인트는 refined RL의 위치다.
많은 reasoning RL 논의가 final-answer verifier에 집중하지만, 올림피아드 증명에서는 final answer reward만으로 충분하지 않다.
SU-01은 answer-verifiable RL을 거친 뒤 proof reward, self-refinement, experience replay로 다시 목표를 좁힌다.
이는 앞으로 수학·과학 reasoning 모델을 만들 때 “정답률 최적화”와 “증명 품질 최적화”를 별도 단계로 다뤄야 한다는 신호로 읽힌다.
배포 성숙도는 보수적으로 봐야 한다.
모델과 코드는 공개되어 있지만, 학습 재현은 8 GPU SFT와 64 GPU RL, slime/SGLang/DeepSeekMath-V2 reward serving 같은 인프라를 전제로 한다.
GitHub releases와 tags가 없고, training package도 일반적인 pip-first 사용자 경험보다는 연구 클러스터 스크립트에 가깝다.
즉 지금의 SU-01은 “바로 제품에 꽂는 경량 reasoning library”가 아니라, 엄격한 proof reasoning을 만들기 위한 공개 연구 bundle에 더 가깝다.
그럼에도 이 릴리스는 의미가 크다.
최근 reasoning 모델 경쟁은 더 이상 base model 크기만의 문제가 아니다.
어떤 trajectory를 보여 줄지, verifier를 어떤 순서로 쓸지, 드문 성공 proof를 어떻게 보존할지, inference-time critique를 얼마나 길게 허용할지가 성능을 좌우한다.
SU-01은 이 복잡한 조합을 비교적 읽기 쉬운 pipeline으로 정리했고, 모델·코드·프로젝트 페이지를 함께 공개해 후속 연구가 검증할 수 있는 기준점을 남겼다.