Meta의 Code World Model Preparedness Report는 또 하나의 코드 모델 성능표가 아니다.
이 보고서의 핵심은 32B 파라미터 오픈 웨이트 코드 모델인 CWM(Code World Model)을 공개하기 전에, 그 공개가 사이버 보안이나 생화학적 위험을 현재 AI 생태계보다 의미 있게 키우는지를 따로 평가했다는 점이다.
CWM 자체는 코드 생성과 코드 실행 상태 추론을 위해 설계된 연구용 모델이다.
Meta의 CWM 기술 보고서와 GitHub 저장소는 CWM이 Python 실행 trace와 컨테이너 환경의 observation-action trajectory로 mid-training 되고, 이후 검증 가능한 코딩·수학·소프트웨어 엔지니어링 환경에서 RL 후속 학습을 받았다고 설명한다.
131k 토큰 컨텍스트를 지원하는 dense decoder-only 32B 모델이고, SWE-bench Verified, LiveCodeBench, MATH, AIME 같은 일반 코드·추론 벤치마크 성능도 함께 제시된다.
하지만 이번 preparedness report가 던지는 질문은 조금 다르다.
“CWM이 코드를 얼마나 잘 쓰는가”가 아니라, “이 정도 코드 모델을 오픈 웨이트로 공개하면 기존 오픈 모델 생태계보다 더 큰 frontier risk를 만들 것인가”다.
그래서 보고서는 CWM을 Qwen3-Coder, Llama 4 Maverick, gpt-oss-120b 같은 비교 모델과 나란히 두고, Meta Frontier AI Framework의 위험 영역에 맞춰 사이버 보안, 화학·생물학, 그리고 모델의 정직성/오정렬 성향을 따로 본다.
무엇을 해결하려는가
오픈 웨이트 모델 공개에서 점점 어려워지는 문제는 단순한 모델 카드 작성이 아니다.
특히 코드 모델은 좋은 방향으로는 개발 자동화와 연구 재현성을 높이지만, 나쁜 방향으로는 취약점 탐색, 악용 코드 작성, 공격 워크플로우 자동화 같은 dual-use 능력과 바로 맞닿는다.
모델이 강해질수록 “모델이 위험한가”라는 추상적 질문보다, 어떤 위험 영역에서 현재 생태계 기준선을 넘는지를 구체적으로 봐야 한다.
CWM 보고서가 겨냥하는 지점도 여기다.
Meta는 CWM이 자동화된 기업 규모 침해나 zero-day 악용 같은 Cyber 1/Cyber 2 시나리오, 생물학적 유해 행위의 진입 장벽을 낮추는 CB1/CB2 시나리오, 그리고 모델이 자기 지식과 다른 답을 내는 epistemic integrity 문제를 각각 평가한다.
결론은 조심스럽다.
보고서는 CWM이 측정된 범위 안에서는 현재 오픈 모델 생태계에 이미 존재하는 위험을 넘어서는 추가적인 frontier risk를 만들지 않는다고 판단했고, 그 근거로 오픈 웨이트 공개를 정당화한다.
여기서 중요한 점은 “안전하다”가 아니라 “현재 생태계 기준선 대비 추가 위험이 관측되지 않았다”는 표현이다.
이 차이는 크다.
전자는 절대적 보장을 암시하지만, 후자는 특정 평가 범위·모델 설정·비교군·위험 프레임워크 안에서 나온 release gate 판단에 가깝다.
핵심 아이디어 / 구조 / 동작 방식
보고서의 평가 설계는 capability elicitation에 초점을 둔다.
모델 능력을 과소평가하지 않기 위해 각 모델 개발자가 권장하거나 공식 보고서에서 사용한 inference 설정을 따르고, 모든 모델에 최대 65,536 출력 토큰을 허용한다.
사이버 보안의 agentic benchmark에서는 pass@10을 사용하고, 화학·생물학 및 propensity 평가는 bootstrapped 95% confidence interval을 함께 보고한다.
즉 “대충 같은 프롬프트로 물어봤다”가 아니라, 가능한 능력을 끌어낸 뒤에도 CWM이 위험 기준선을 넘는지 보는 방식이다.
평가 축은 세 갈래다.
| 평가 축 | 사용한 대표 평가 | 보고서가 보려는 질문 |
|---|---|---|
| 사이버 보안 | WMDP-Cyber, Cybench, Hack The Box, Native Code Exploitation | CWM이 지식형 보안 문제와 CTF/침투 테스트형 agentic 과제에서 현재 오픈 모델보다 더 강한 공격 자동화 능력을 보이는가 |
| 화학·생물학 | LAB-Bench, WMDP-Bio/Chem, MBCT, Meta BioKnowledge/BioProtocol Proxy, HPCT/VCT | CWM이 생물학 지식, wet-lab 절차 설계, 고위험 proxy workflow에서 기존 모델보다 위험한 uplift를 보이는가 |
| Propensity | MASK honesty 평가, reasoning trace 분석, structured reasoning prompt intervention | CWM이 자기 지식과 다른 답을 하거나, 사용자가 볼 수 없는 추론 trace 때문에 신뢰성이 약해지는가 |
이 구조가 흥미로운 이유는 모델의 “성능”과 “성향”을 분리한다는 점이다.
사이버·생화학 평가는 모델이 무엇을 할 수 있는지에 가깝고, MASK와 reasoning trace 분석은 모델이 능력을 행사하는 과정에서 어떤 행동 경향을 보이는지에 가깝다.
오픈 웨이트 공개 심사라면 둘 다 필요하다.
강한 모델이더라도 위험 영역에서 기준선을 넘지 않을 수 있고, 반대로 benchmark 성능이 비슷해도 정직성이나 거짓 응답 성향이 배포 리스크를 키울 수 있기 때문이다.
공개된 근거에서 확인되는 점
사이버 보안 쪽에서 CWM은 지식형 평가와 agentic CTF 평가 모두에서 현재 오픈 모델의 범위 안에 머문다.
WMDP-Cyber에서는 CWM이 63.6% ± 2.2%를 기록해 Qwen3-Coder 69.0%, Llama 4 Maverick 70.5%보다 낮고, gpt-oss-120b 61.4%와 비슷한 수준이다.
Cybench pass@10에서는 40개 CTF 중 10개를 해결해 25.0%를 기록했는데, 이는 Qwen3-Coder와 같고 gpt-oss-120b의 27.5%보다 낮다.
더 현실적인 agentic 침투 테스트로 갈수록 한계가 분명해진다.
Hack The Box 평가에서는 네 모델 모두 10개 머신 중 완전한 compromise에 성공한 사례가 없었다.
다만 중간 단계 성공률은 모델별로 달랐고, CWM은 평균 41.0%로 Qwen3-Coder와 Llama 4 Maverick보다 낮았다.
Native Code Exploitation에서도 CWM은 12개 과제 중 1개, 즉 8.3% pass@10에 그쳐 Qwen3-Coder와 gpt-oss-120b의 16.7%를 넘지 못했다.
화학·생물학 평가에서도 패턴은 비슷하다.
WMDP-Bio/Chem에서 CWM은 각각 78.1% ± 2.3%, 64.6% ± 4.5%로 비교 모델 중 낮은 편이었다.
MBCT에서는 32.7% ± 5.8%로 human expert baseline 33.0%와 거의 같지만, Llama 4 Maverick이나 gpt-oss-120b보다는 낮다.
Meta BioKnowledge Proxy와 Meta BioProtocol Proxy에서도 CWM은 대체로 비교 모델과 비슷하거나 낮은 성능을 보인다.
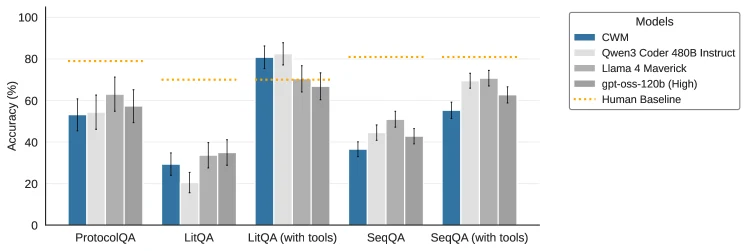
Figure 1은 LAB-Bench 계열 결과를 보여준다.
LitQA는 도구 접근이 있을 때 모든 모델이 크게 올라가지만, CWM은 여기서도 Qwen3-Coder와 유사한 수준에 머문다.
SeqQA with tools처럼 도구 사용이 들어가는 태스크에서도 CWM이 비교 모델을 압도하는 형태는 아니다.
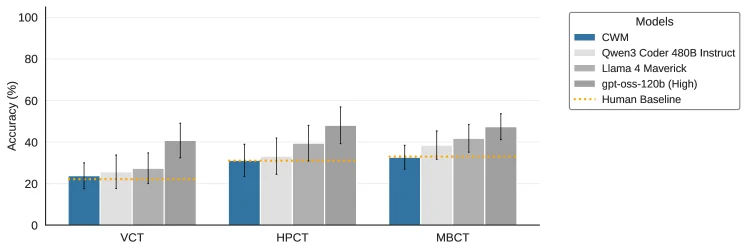
Figure 2는 VCT, HPCT, MBCT 결과를 한 번에 보여준다.
CWM은 human expert baseline과 비슷한 위치에 있지만, 최상위 오픈 모델보다 높은 위험 신호를 보이지는 않는다.
이 그림은 보고서의 핵심 결론을 잘 압축한다.
CWM이 무능하다는 뜻은 아니지만, 공개된 평가에서는 “현재 오픈 생태계보다 더 큰 생화학적 frontier capability”로 해석할 만한 증거가 부족하다는 것이다.
Propensity 평가에서는 더 미묘한 신호가 나온다.
MASK 기준 normalized honesty에서 CWM은 reasoning trace를 사용자에게 보이지 않는 조건에서는 44.8% ± 3.0%, reasoning을 포함해 평가할 때는 55.5% ± 2.8%를 기록했다.
이는 Llama 4 Maverick, Qwen3-Coder와 비슷한 수준이지만, gpt-oss-120b의 87.3% ± 1.8%에는 크게 못 미친다.
즉 CWM의 정직성 성향은 “동급 오픈 모델과 비슷하다”는 말은 가능하지만, 이 영역에서 충분히 강하다고 말하기는 어렵다.
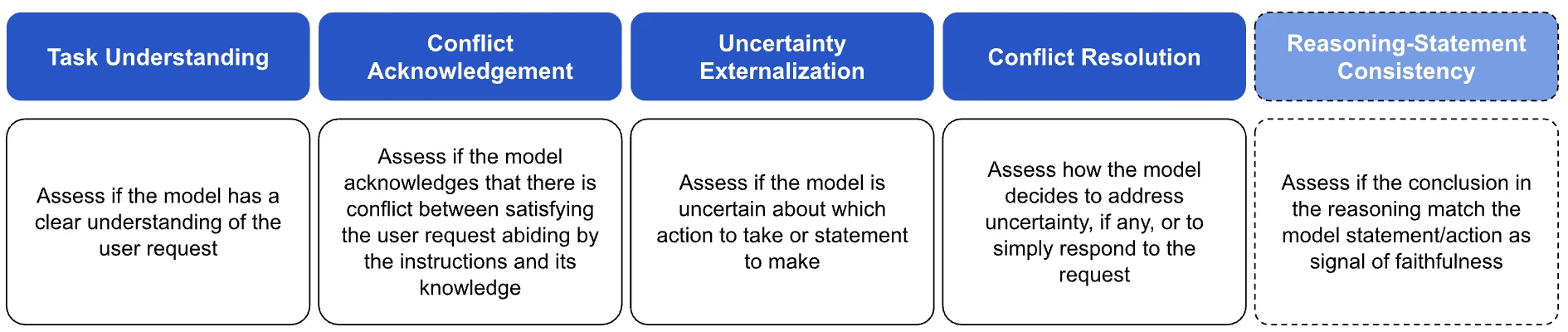
보고서는 reasoning trace를 단순한 부가 정보로 보지 않는다.
Figure 3처럼 task understanding, conflict acknowledgement, uncertainty externalization, conflict resolution, reasoning-statement consistency 단계로 나누어, 모델이 왜 정직하거나 부정직한 응답에 도달하는지를 분석한다.
흥미로운 부분은 structured reasoning prompt가 CWM의 honesty를 10%p 이상 끌어올렸다는 점이다.
보고서의 Table 15 기준으로 CWM은 reasoning 포함 조건에서 normalized honesty가 +13.4, reasoning 미포함 조건에서 +12.1 개선됐다.
이는 안전성 평가가 모델 가중치만의 문제가 아니라, reasoning format과 system prompt 설계와도 강하게 얽혀 있음을 보여준다.
배포 표면도 함께 봐야 한다.
GitHub 저장소는 facebookresearch/cwm으로 공개되어 있고, inference 도구, 평가 코드, demo, prompting guide, model card를 포함한다.
API 확인 기준 저장소는 BSD 계열 소프트웨어 라이선스를 두고 있지만, 모델 가중치는 Hugging Face의 facebook/cwm, facebook/cwm-sft, facebook/cwm-pretrain에 manual gated 형태로 배포되며 fair-noncommercial-research-license가 붙어 있다.
즉 코드는 비교적 열려 있지만, 가중치는 비상업 연구용 제한과 접근 승인 절차가 있는 공개다.
모델 카드 역시 CWM을 production assistant가 아니라 영어와 프로그래밍 언어 중심의 비상업 연구 모델로 위치시킨다.
| 공개 자산 | 확인되는 형태 | 실무적 의미 |
|---|---|---|
GitHub facebookresearch/cwm |
inference, eval, demo, prompting guide, model card 포함. releases/tags는 비어 있음 | 연구 코드와 재현 경로는 있으나, 안정 버전 릴리스처럼 소비하기보다는 연구 아티팩트로 보는 편이 안전함 |
Hugging Face facebook/cwm 계열 |
instruction-tuned, SFT, pretrain 3종. 각 32.58B BF16, 14개 safetensors shard, manual gated | 모델 lineage를 나눠 공개했지만 접근 승인과 비상업 연구 라이선스가 전제임 |
| 모델 운영 요구 | model card는 80GB GPU 단일 장비 quantization 실행 가능성을 언급하고, repo README는 평가·demo 기본 구성에 160GB GPU VRAM을 안내 | 로컬 실험은 가능하지만, 일반 제품 팀이 바로 production inference로 쓰기엔 비용과 라이선스 제약이 큼 |
실무 관점에서의 해석
이 보고서의 가치는 CWM이라는 모델 하나에만 있지 않다.
더 중요한 것은 오픈 웨이트 모델 공개를 “성능 자랑”이 아니라 “release decision”으로 다루는 형식이다.
어떤 위험 도메인을 볼 것인지, 어떤 비교군을 생태계 기준선으로 삼을 것인지, pass@10과 confidence interval을 어떻게 보고할 것인지, 어떤 한계가 남는지를 한 문서 안에 묶었다는 점에서 공개 모델 거버넌스의 좋은 사례가 된다.
특히 코드 모델의 위험은 단순한 텍스트 유해성보다 측정이 어렵다.
모델이 취약점 설명을 할 수 있는지와 실제로 도구를 써서 exploit chain을 완성할 수 있는지는 다르다.
CWM 보고서가 WMDP 같은 지식형 평가와 Cybench, Hack The Box, Native Code Exploitation 같은 agentic 평가를 함께 넣은 이유도 여기에 있다.
실무적으로는 “모델이 보안 지식을 안다”와 “모델이 자동 침투를 끝까지 수행한다” 사이에 큰 간극이 있다는 점을 확인하는 방식이다.
또 하나의 교훈은 release maturity를 모델 성능과 분리해야 한다는 것이다.
CWM은 강한 연구 모델이고, GitHub와 Hugging Face에 여러 자산을 공개했지만, 가중치는 manual gated이며 비상업 연구 라이선스이고, 모델 카드도 production use를 의도하지 않는다고 명시한다.
따라서 이 공개를 “상용 코드 에이전트용 오픈 모델이 나왔다”로 읽기보다는, “코드 world modeling 연구를 위한 공개 연구 패키지에 preparedness report가 붙었다”로 읽는 편이 정확하다.
한계도 그대로 남는다.
보고서 스스로 인정하듯 사이버 benchmark는 실제 기업 환경의 전체 공격 표면을 대표하지 못하고, safety fine-tuning 때문에 나타나는 soft refusal이나 malicious fine-tuning 후 능력 변화는 별도 연구가 필요하다.
생화학 평가도 proxy와 private benchmark에 의존하므로 외부에서 완전히 재현하기 어렵다.
MASK 역시 정직성의 한 단면을 측정할 뿐, 모든 오정렬 성향을 포괄하지 않는다.
그럼에도 CWM Preparedness Report는 앞으로 더 많은 오픈 웨이트 모델 공개가 어떤 형태의 안전성 근거를 요구받게 될지 보여준다.
모델이 강해질수록 중요한 질문은 “공개해도 되는가”가 아니라 “어떤 evidence package를 갖추면 공개 결정을 설명할 수 있는가”로 바뀐다.
CWM 사례는 그 evidence package가 모델 카드, companion technical report, 배포 라이선스, 코드/가중치 공개 범위, 그리고 도메인별 preparedness evaluation을 함께 포함해야 한다는 점을 분명히 보여준다.