LLM은 거대한 사전학습 지식을 갖고 있지만, 배포 이후의 관점에서는 꽤 정적인 시스템이다.
입력 컨텍스트 안에서는 빠르게 적응하는 것처럼 보이지만, 그 지식이 모델의 장기 기억으로 자연스럽게 통합되지는 않는다.
반대로 파라미터를 계속 업데이트하면 새로운 지식을 넣는 대신 오래된 능력을 잃는 catastrophic forgetting이 나타난다.
Nested Learning: The Illusion of Deep Learning Architectures는 이 문제를 단순히 더 긴 컨텍스트, 더 큰 모델, 더 나은 optimizer의 경쟁으로 보지 않는다.
Ali Behrouz, Meisam Razaviyayn, Peilin Zhong, Vahab Mirrokni는 모델 아키텍처와 optimizer를 서로 다른 물건으로 나누어 보던 관점 자체가 병목이라고 주장한다.
논문의 핵심은 딥러닝 모델을 여러 수준의 중첩된 최적화 문제이자 연상기억 시스템으로 다시 기술하는 것이다.
이 관점에서 attention, MLP, momentum, backpropagation, in-context learning은 모두 자기만의 context flow를 압축하는 기억 모듈로 읽힌다.
그리고 이 해석을 바탕으로 저자들은 Continuum Memory System(CMS), Delta Gradient Descent(DGD), Multi-scale Momentum Muon(M3), 그리고 self-modifying Titans와 CMS를 결합한 Hope라는 proof-of-concept 아키텍처를 제안한다.
이 논문은 arXiv에는 2025년 12월 31일 올라왔고, arXiv 메타데이터와 OpenReview/NeurIPS 페이지 기준 한 버전은 NeurIPS 2025에 게재된 것으로 표시된다.
무엇을 해결하려는가
현재 Transformer형 LLM의 기억 구조를 거칠게 나누면 두 극단이 있다.
Attention은 입력 컨텍스트 안에서 토큰 간 관계를 즉시 계산하는 working memory에 가깝다.
반면 MLP block은 사전학습 단계에서 압축된 지식을 저장하지만, inference 중에는 사실상 고정되어 있다.
논문 표현을 빌리면 attention은 context 안에서 매우 높은 빈도로 갱신되는 비모수적 기억이고, MLP는 pre-training 이후 갱신 빈도가 0에 가까운 장기 기억이다.
문제는 이 두 극단만으로는 continual learning을 자연스럽게 설명하기 어렵다는 점이다.
모델이 새로운 episode, 문서, 작업, 사용자 환경을 지속적으로 만나면, 어떤 정보는 즉시 반영되어야 하고 어떤 정보는 천천히 축적되어야 한다.
인간의 기억도 빠른 online consolidation과 느린 systems consolidation이 섞여 있고, 뇌파의 여러 주파수대가 서로 다른 시간척도의 정보처리에 관여한다.
Nested Learning은 이 생물학적 비유를 그대로 모사하려는 논문은 아니지만, 업데이트 빈도와 context flow를 모델 설계의 일급 변수로 올려야 한다는 문제의식을 공유한다.

또 하나의 문제는 아키텍처와 optimizer를 분리해 온 관행이다.
보통은 “모델 구조를 설계한 뒤 어떤 optimizer로 학습할 것인가”를 묻는다.
이 논문은 반대로 optimizer도 gradient라는 context flow를 압축하는 기억 모듈이며, 아키텍처도 token/context를 압축하는 기억 모듈이라고 본다.
따라서 둘은 별개 층이 아니라 하나의 neural learning module 안에서 서로 다른 수준과 빈도로 동작하는 중첩 시스템이 된다.
핵심 아이디어 / 구조 / 동작 방식
Nested Learning의 가장 큰 전환은 “깊은 모델”을 layer stack으로만 보지 않는 데 있다.
논문은 모델과 학습 절차 전체를 여러 optimization problem의 집합으로 본다.
각 level은 자기 context를 갖고, 자기 objective를 갖고, 자기 update frequency를 갖는다.
어떤 level은 gradient를 압축하고, 어떤 level은 token sequence를 압축하며, 어떤 level은 다른 level의 초기값이나 update rule을 제공한다.
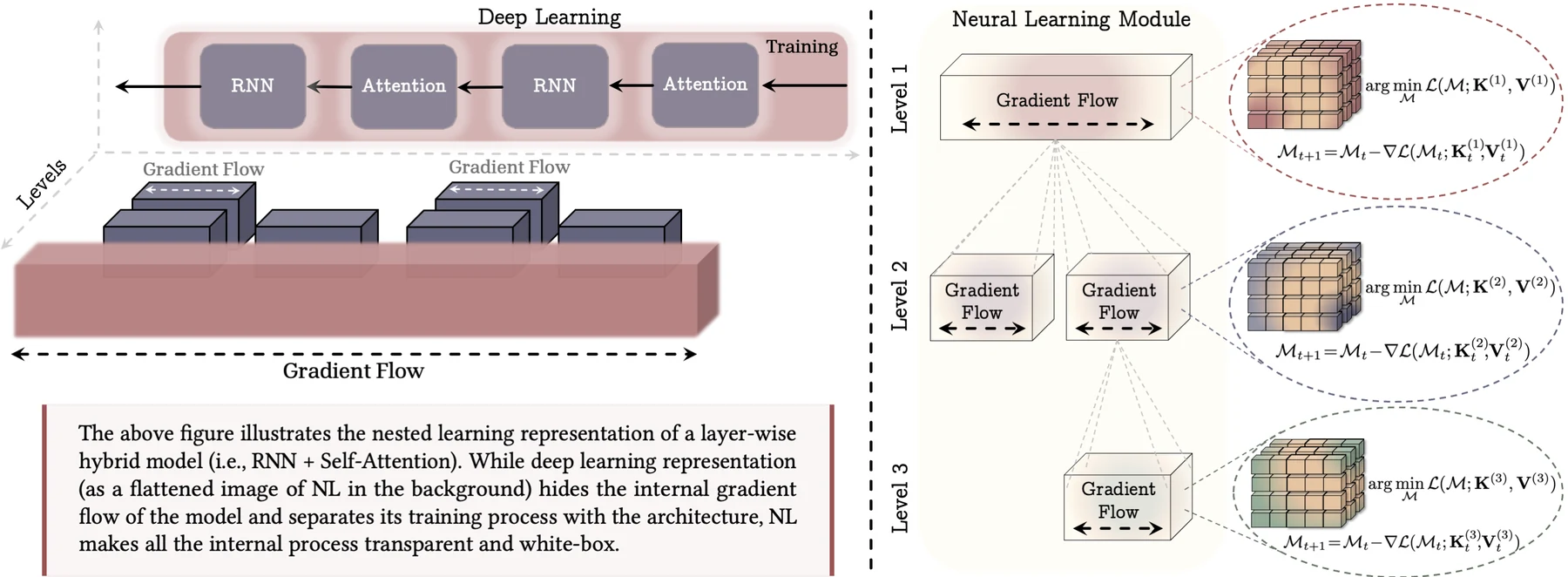
이 구조를 읽기 쉽게 풀면 다음과 같다.
| 구성 | Nested Learning 관점 | 설계상 의미 |
|---|---|---|
| Backpropagation / optimizer | gradient context를 파라미터나 momentum state에 압축하는 연상기억 | optimizer도 학습 모듈이며, long-context memory 설계 대상이 됨 |
| Attention / recurrent memory | token context를 key-value mapping으로 압축·조회하는 연상기억 | in-context learning을 특정 아키텍처가 아니라 기억 업데이트 관점으로 설명 |
| MLP block | pre-training context가 압축된 장기 지식 저장소 | inference 중 고정된 MLP만으로는 지속 적응이 제한됨 |
| CMS | 서로 다른 빈도로 업데이트되는 MLP memory block들의 spectrum | 짧은 기억과 긴 기억 사이에 여러 시간척도의 저장소를 둠 |
| Self-modifying Titans | key/value/query/learning-rate/retention 관련 memory가 context 안에서 자기 업데이트를 생성 | 모델이 단순히 데이터를 저장하는 것을 넘어 자기 update process를 바꾸도록 함 |
| Hope | self-modifying Titans 뒤에 CMS를 붙인 neural learning module | 빠른 적응과 지속 기억을 한 블록 안에서 결합하려는 proof-of-concept |
CMS는 이 논문의 가장 직관적인 설계물이다.
전통적인 long-term/short-term memory 이분법 대신, 여러 MLP block을 서로 다른 chunk size와 update frequency로 배치한다.
높은 빈도의 block은 빠르게 적응하지만 쉽게 바뀌고, 낮은 빈도의 block은 더 오래가는 지식을 보존한다.
저자들은 이렇게 하면 한 block에서 잊힌 정보가 다른 낮은 빈도 block에 남아 있고, level 간 지식 전달을 통해 다시 복원될 수 있다고 설명한다.
Hope는 이 CMS를 self-modifying Titans와 결합한다.
Titans 계열은 surprise 기반 장기 memory module로 볼 수 있지만, 논문은 여기서 한 단계 더 나아가 key, value, query, learning rate, retention gate 같은 구성요소도 context에 맞춰 적응하도록 만든다.
단순히 hidden state를 업데이트하는 것이 아니라, memory module들이 자기 자신의 값과 업데이트 방식을 생성한다는 점에서 self-referential learning module이라는 표현을 쓴다.
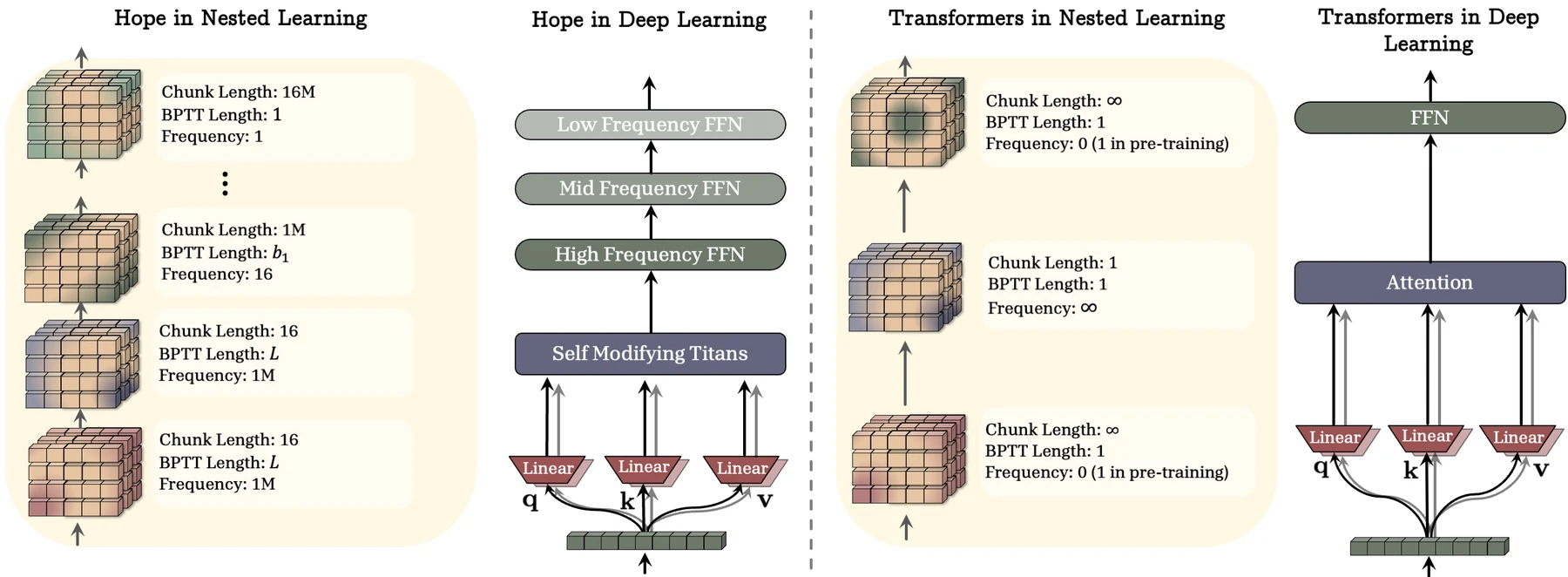
Optimizer 쪽에서도 같은 관점이 이어진다.
논문은 gradient descent와 momentum을 gradient stream을 압축하는 연상기억으로 해석한 뒤, Delta Gradient Descent와 M3를 제시한다.
M3는 Adam, Muon, CMS 아이디어를 섞은 proof-of-concept optimizer로, 최근 gradient와 더 오래된 gradient 정보를 서로 다른 momentum memory에 저장한다.
중요한 것은 M3 자체가 곧바로 실용 optimizer의 최종형이라는 주장보다는, optimizer도 여러 시간척도의 기억 시스템으로 설계할 수 있다는 데 있다.
공개된 근거에서 확인되는 점
실험은 꽤 넓게 깔려 있다.
논문은 continual learning, in-context learning, long-context reasoning, language modeling, short in-context recall, formal language recognition, optimizer 비교를 모두 다룬다.
이 폭은 장점이자 해석상의 부담이다.
하나의 benchmark에서 작은 개선을 주장하는 논문이라기보다, Nested Learning이라는 관점이 여러 설계물로 이어질 수 있음을 보이려는 논문에 가깝다.
먼저 continual learning 쪽에서는 CLINC, Banking, DBpedia class-incremental learning에서 Hope-enhanced architecture가 ICL, EWC, InCA 같은 baseline보다 높은 정확도를 보인다고 보고한다.
또한 Manchu/Kalamang을 이용한 Continual Translation of a Novel Language 설정에서는 memory level을 늘릴수록 sequential language learning에서 catastrophic forgetting을 더 잘 버티는 패턴을 제시한다.
Long-context 쪽에서는 CMS의 level 수와 낮은 빈도 memory가 중요하게 나온다.
MK-NIAH, LongHealth, QASPER에서 memory level이 늘어날수록 대체로 성능이 좋아지고, lowest frequency를 너무 높이면 가장 persistent한 memory가 약해져 성능이 떨어지는 경향을 보인다.
Google Research 블로그가 공개한 요약 figure도 이 메시지를 간단히 보여 준다.
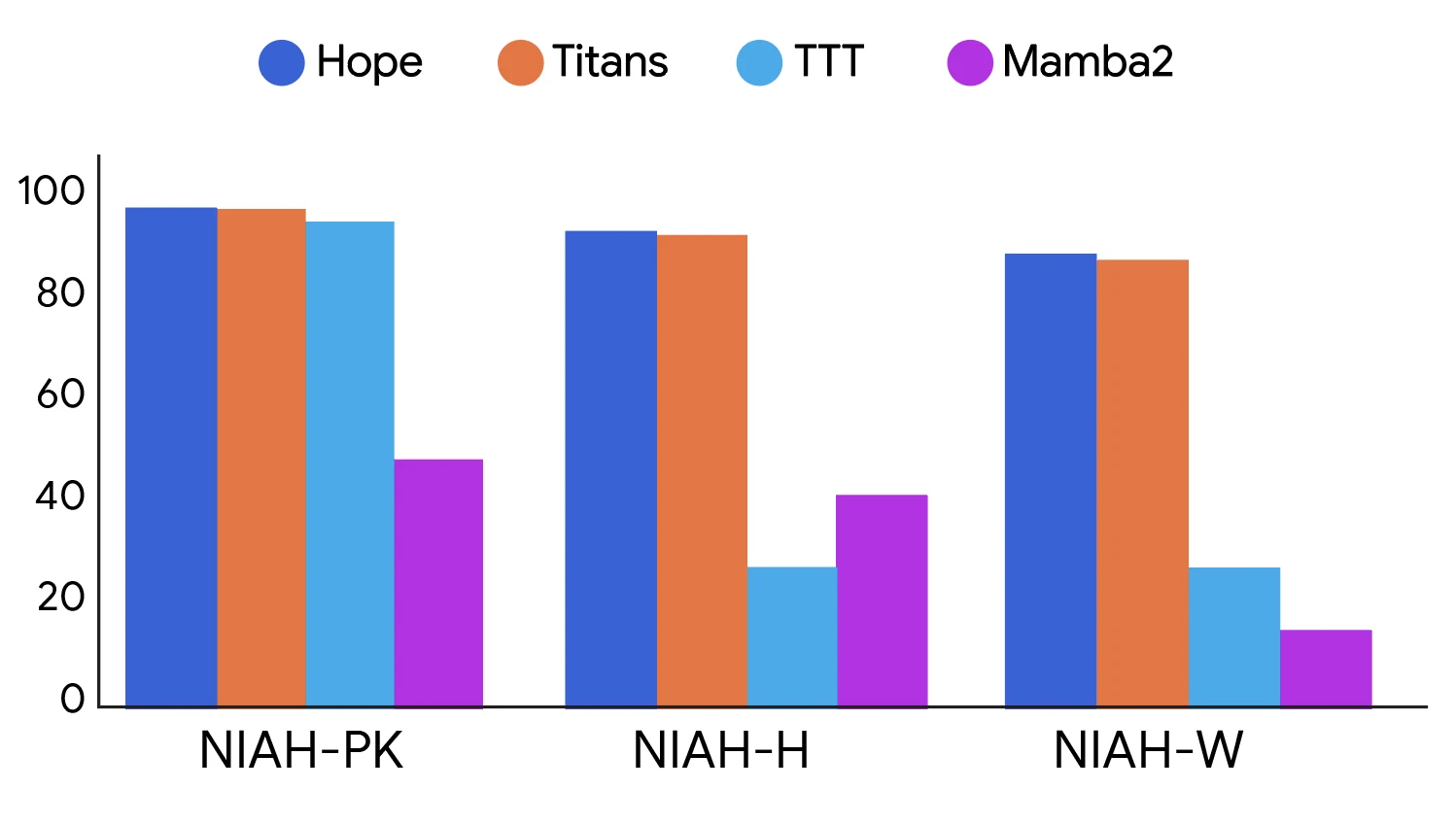
RULER NIAH 표에서는 Hope가 attention-free 비교군 중 가장 강한 쪽에 놓인다.
예를 들어 S-NIAH-1에서는 4K/8K/16K 모두 100을 기록하고, S-NIAH-2 16K에서는 Hope 78.2가 Titans 75.4보다 높다.
더 어려운 multi-query나 multi-value 설정에서도 Hope는 RWKV-7, Comba, DLA, Titans보다 높은 값을 보인다.
다만 Transformer와 Hope-Attention이 여전히 강한 항목도 있어, 이 결과를 “attention을 완전히 대체했다”로 읽기보다는 attention-free memory module의 장거리 압축 능력을 끌어올렸다로 읽는 편이 안전하다.
Language modeling과 common-sense reasoning 표도 논문의 핵심 근거다.
| 설정 | Hope 결과 | 가까운 비교군 | 해석 |
|---|---|---|---|
| 760M / 30B tokens 평균 정확도 | 52.28 | Titans 51.68, Transformer++ 50.11 | 작은 규모에서도 attention-free/deep-memory 계열 중 우위 |
| 760M / 30B tokens WikiText perplexity | 18.68 | Titans 20.08, Transformer++ 24.18 | perplexity 기준으로도 Hope가 낮음 |
| 1.3B / 100B tokens 평균 정확도 | 58.04 | Titans 56.82, Comba 55.39, Transformer++ 53.38 | 스케일이 커져도 이득이 유지됨 |
| 1.3B / 100B tokens LAMBADA perplexity | 10.08 | Titans 11.41, Samba 13.21 | language modeling 쪽에서 특히 차이가 큼 |
Ablation도 중요한 신호다.
논문은 DGD, momentum, weight decay, CMS, inner projection 설계를 하나씩 제거하면 language modeling perplexity나 reasoning accuracy가 나빠진다고 보고한다.
별도 context usage figure에서는 문맥 사용량이 늘어날수록 Hope 계열의 perplexity가 계속 내려가며, w/o CMS나 Transformer/Comba 대비 더 좋은 곡선을 보인다.
이는 CMS가 단순한 장식 모듈이 아니라 장문 context 활용에 실제로 기여한다는 근거로 쓰인다.
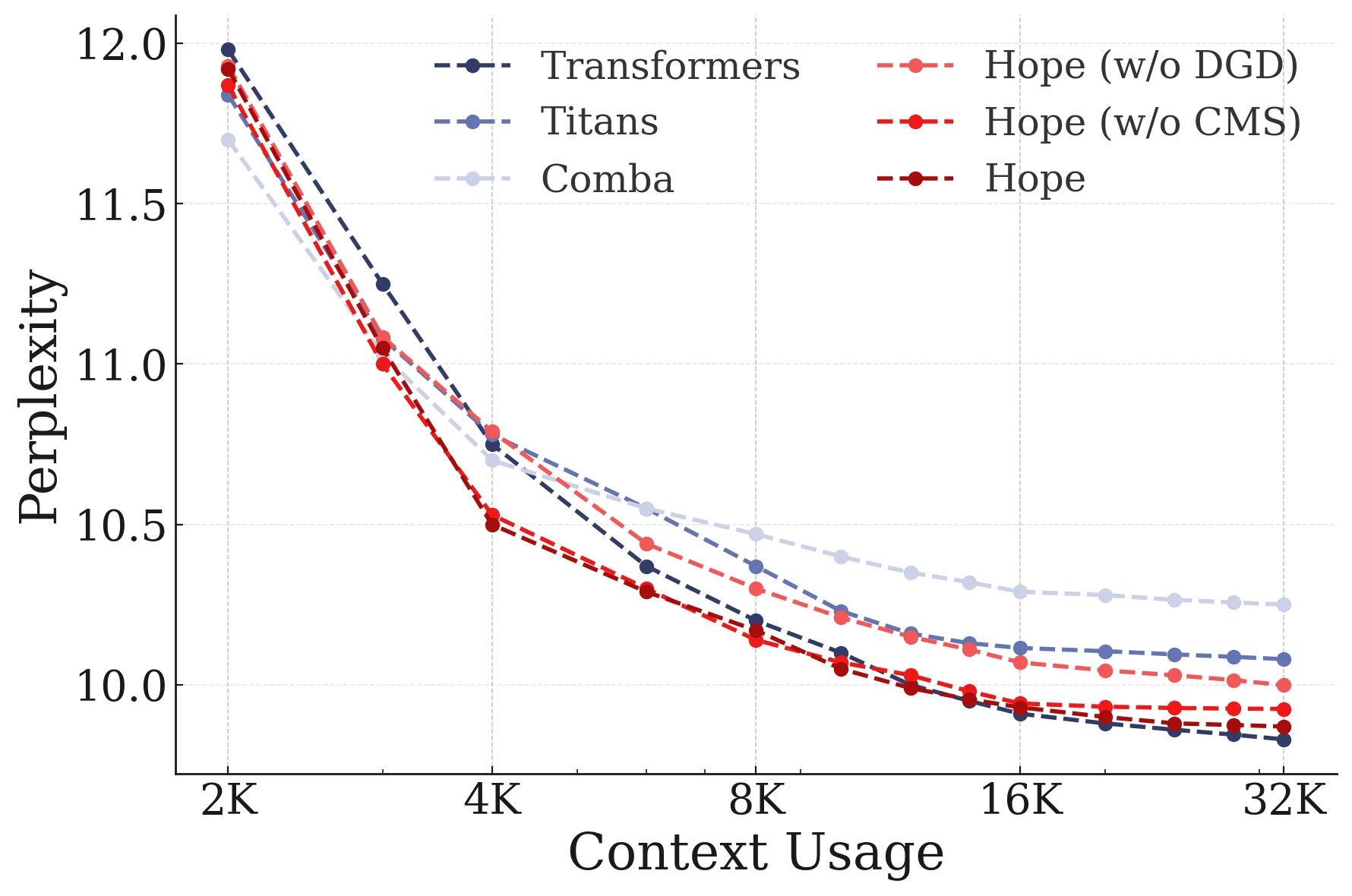
Optimizer 실험은 더 조심해서 봐야 한다.
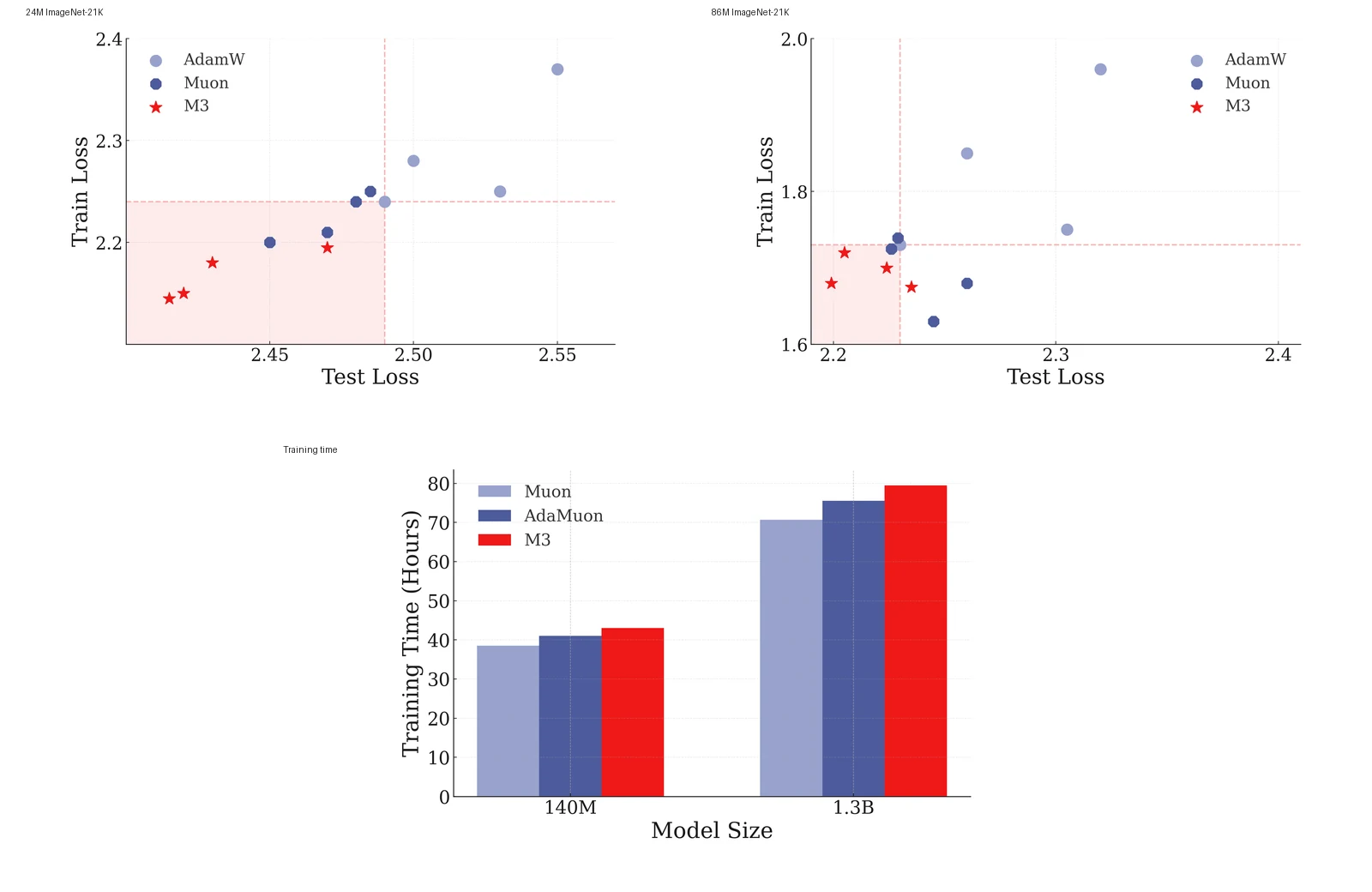
ViT를 ImageNet-21K에서 학습한 비교에서 M3는 AdamW와 Muon보다 더 낮은 train/test loss 영역에 점들이 모이는 것으로 제시된다.
하지만 대형 언어모델 학습 시간 비교에서는 M3가 Muon보다 느리고 AdaMuon과 비슷한 시간대에 놓인다.
논문도 M3가 CMS 설계의 proof-of-concept이며 scaling overhead가 있을 수 있다고 명시한다.
Release maturity 관점에서는 보수적으로 봐야 한다. arXiv source bundle 안에는 공식 GitHub나 Hugging Face 링크가 없고, arXiv abs page도 TeX source 외에 코드 링크를 제공하지 않는다.
GitHub와 Hugging Face에서 arXiv ID, 정확한 제목, Nested Learning Hope 조합을 확인해도 공식 구현이나 체크포인트로 보이는 release는 찾지 못했다.
현재 공개된 1차 자료는 arXiv/PDF, Google Research 블로그, NeurIPS/OpenReview 페이지, 논문 source figures에 가깝다.
실무 관점에서의 해석
이 논문을 제품 팀이나 연구팀 관점에서 읽을 때 가장 유용한 메시지는 “Hope를 당장 가져다 쓰자”보다 업데이트 빈도와 context flow를 아키텍처의 명시적 설계축으로 보자에 있다.
지금의 많은 LLM 시스템은 컨텍스트 창, RAG, memory store, fine-tuning, optimizer state를 서로 다른 레이어의 엔지니어링 문제로 다룬다.
Nested Learning은 이들을 모두 “무엇을, 어느 시간척도로, 어떤 objective로 압축할 것인가”라는 하나의 질문으로 묶는다.
이 관점은 continual learning뿐 아니라 에이전트 memory, long-context compression, personalized model adaptation, optimizer design에도 직접 이어진다.
예를 들어 사용자별 장기 preference, 프로젝트별 코드베이스 지식, 최근 작업 session, global pretraining knowledge를 모두 같은 빈도로 갱신할 필요는 없다.
어떤 것은 매 턴 업데이트되어야 하고, 어떤 것은 하루 단위로 요약되어야 하며, 어떤 것은 모델 가중치나 adapter에 천천히 들어가야 한다.
CMS는 이 차이를 모델 내부 구조로 가져오려는 시도다.
하지만 한계도 분명하다.
첫째, 공식 code/model release가 확인되지 않아 재현과 실사용 검토는 아직 논문 중심으로만 가능하다.
둘째, Hope는 여러 아이디어가 결합된 복합 시스템이기 때문에 어떤 구성요소가 어느 환경에서 가장 중요한지 더 세밀한 독립 검증이 필요하다.
셋째, M3처럼 optimizer에 memory level을 더하는 접근은 성능 가능성과 동시에 overhead를 가져온다.
논문 자체도 catastrophic forgetting이 “해결됐다”고 말하지 않고, 제한된 실험에서 유망한 결과를 보였을 뿐이라고 선을 긋는다.
그럼에도 Nested Learning은 꽤 좋은 질문을 남긴다.
딥러닝 아키텍처가 정말로 layer stack의 모양으로만 정의되는가, 아니면 각 구성요소가 어떤 context를 얼마나 자주 압축하는지로 정의되는가.
만약 후자라면 다음 세대의 long-context/continual model 경쟁은 단순히 더 긴 attention이나 더 큰 MLP가 아니라, 여러 시간척도의 기억을 어떻게 배치하고 서로 지식을 이동시킬 것인가의 경쟁이 될 가능성이 크다.