로봇용 Vision-Language-Action(VLA) 모델은 대개 pretrained Vision-Language Model(VLM)을 policy backbone의 출발점으로 쓴다.
이 선택은 자연스럽다.
VLM은 이미 이미지와 언어를 연결하는 표현을 갖고 있고, 로봇 policy는 그 표현 위에서 관측과 명령을 action으로 바꾸면 된다.
하지만 이 관점에는 중요한 질문이 숨어 있다.
어떤 VLM 표현이 실제로 좋은 VLA 초기화인가?
Rethinking VLM Representation for VLA Initialization은 이 질문을 단순히 “더 강한 VLM을 쓰면 되는가”로 풀지 않는다.
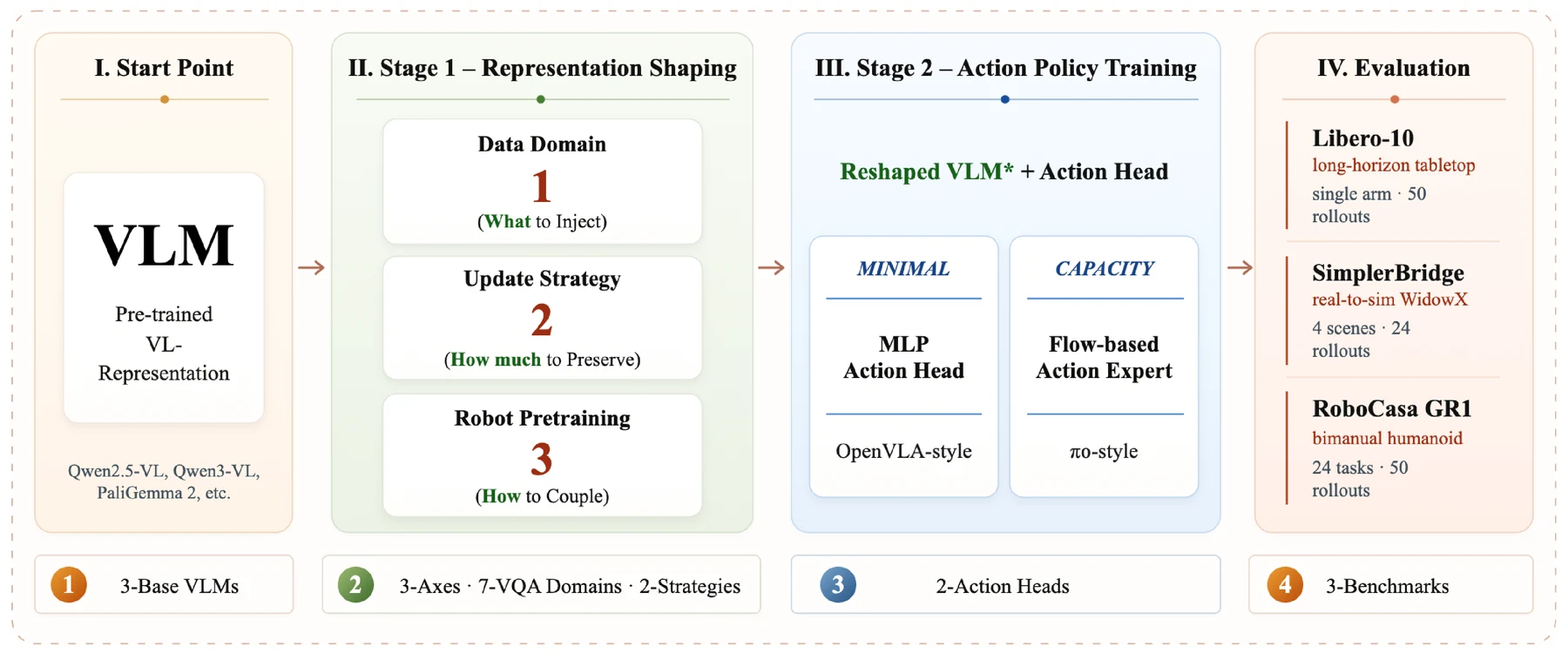
논문은 VLA 초기화를 controlled representation-design 문제로 재정의한다.
첫째, 어떤 embodied VQA 능력을 VLM에 주입할 것인가.
둘째, 그 주입을 LoRA처럼 제한적으로 할 것인가, full finetuning처럼 강하게 할 것인가.
셋째, perception-side VQA 신호와 action-side robot-data pretraining을 어떤 순서로 결합할 것인가.
이 논문의 메시지는 꽤 실용적이다.
VLM을 로봇 policy에 맞춘다는 것은 “로봇 데이터를 더 넣는다” 또는 “embodied QA를 더 많이 푼다”로 끝나지 않는다.
좋은 초기화는 action에 필요한 신호를 넣되, pretrained VLM이 이미 갖고 있던 일반적 시각-언어 표현을 너무 많이 망가뜨리지 않는 균형에서 나온다.
무엇을 해결하려는가
VLA 연구에서 pretrained VLM은 종종 기본값처럼 취급된다.
OpenVLA, π0 계열, VLM 기반 action head 구조들은 모두 큰 VLM이 만든 visual-language representation을 로봇 제어로 가져가려 한다.
문제는 로봇 제어가 일반 VQA와 다르다는 점이다.
명령을 이해하고 물체를 식별하는 능력은 필요하지만, 실제 action learning은 접촉, 위치, 조작 가능 영역, 시간적 진행, 카메라 시점, 양손 제어 같은 더 구체적인 병목을 만난다.
그래서 최근 연구들은 VLM에 embodied supervision을 더 주거나, VLM backbone을 downstream action 데이터로 더 세게 파인튜닝하려 한다.
직관적으로는 그럴듯하다.
로봇에 가까운 VQA를 잘 풀게 만들면 로봇 policy도 좋아질 것처럼 보인다.
그러나 이 논문은 그 효과가 훨씬 조건적이라고 보여준다.
어떤 VQA 도메인은 특정 benchmark에서 도움이 되지만 다른 benchmark에서는 오히려 떨어질 수 있고, 여러 도메인을 많이 섞는다고 성능이 선형적으로 더해지지도 않는다.
논문의 실험 설계는 이 혼선을 줄이기 위해 두 단계로 나뉜다.
Stage 1에서는 base VLM을 embodied VQA 데이터로 적응시켜 표현을 바꾼다.
Stage 2에서는 그 VLM을 VLA policy 초기값으로 넣고, 동일한 downstream action-training recipe로 평가한다.
이렇게 하면 차이가 action policy 학습법이 아니라 초기화된 VLM 표현의 차이에서 왔는지 더 명확히 볼 수 있다.
핵심 아이디어 / 구조 / 동작 방식
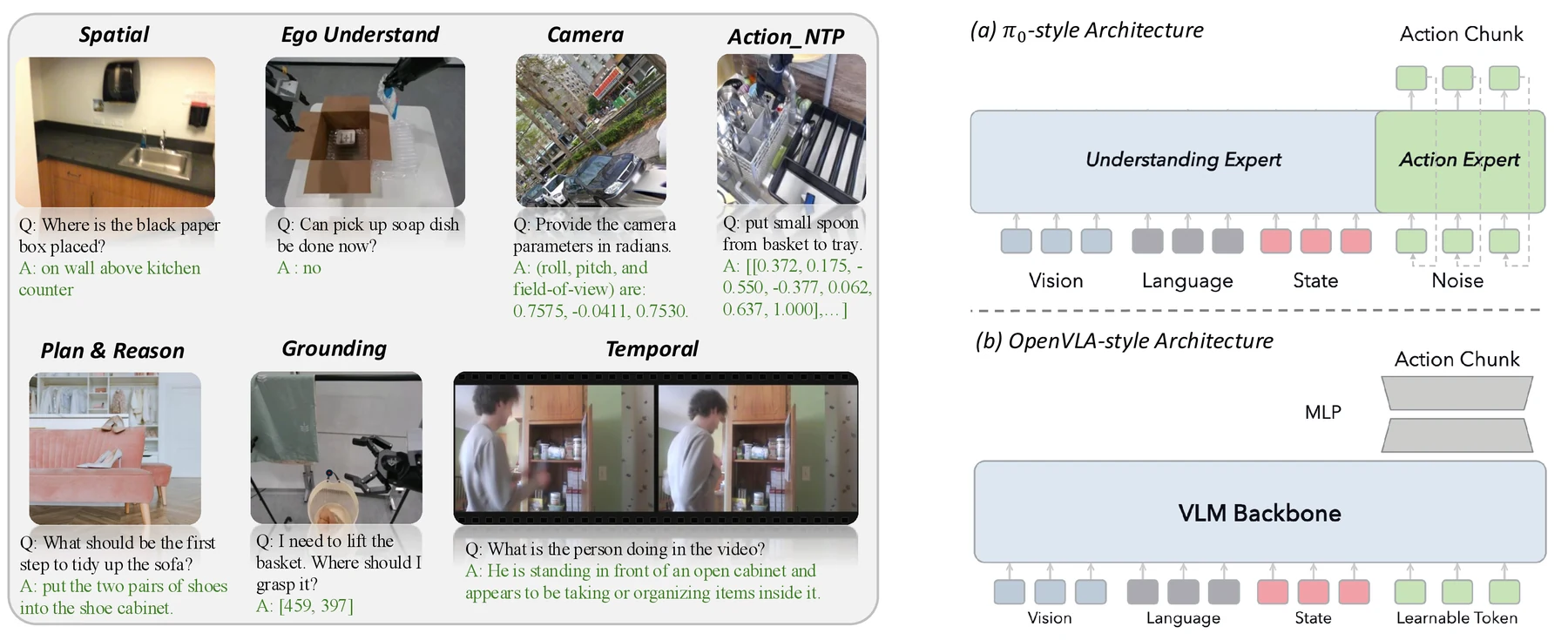
논문이 다루는 첫 번째 축은 embodied VQA 도메인이다.
저자들은 Stage-1 데이터를 Spatial, Grounding, Plan & Reasoning, Camera Prediction, Egocentric Understanding, Temporal Understanding, Action-NTP의 일곱 능력 도메인으로 나눈다.
여기서 Grounding은 언어가 가리키는 객체나 actionable region을 찾는 능력이고, Egocentric Understanding은 손·gripper 위치, 들고 있는 물체, reachable object처럼 자기중심 상태를 이해하는 능력이다.
Action-NTP는 action trajectory를 언어 token처럼 두고 다음 action token을 예측하게 하는 방식이다.
두 번째 축은 업데이트 전략이다.
LoRA는 adapter만 업데이트해 원래 VLM weight 대부분을 보존한다.
반면 Full Finetune은 전체 파라미터를 움직여 Stage-1 supervision에 더 강하게 특화할 수 있다.
이 비교는 단순한 parameter efficiency 비교가 아니다.
핵심은 VLA 초기화가 “embodied task에 더 잘 맞춘 표현”을 원하는지, 아니면 “원래 pretrained representation을 최대한 보존하면서 필요한 신호만 주입한 표현”을 원하는지다.
세 번째 축은 robot-data pretraining이다.
논문은 AgiBot-World-Beta를 action-side supervision으로 사용해 robot-only pretraining, robot-data와 VQA의 joint pretraining, 그리고 {Grounding + Egocentric Understanding}으로 먼저 적응한 뒤 AgiBot robot-data pretraining을 이어가는 staged pretraining을 비교한다.
이 설정은 perception-side 신호와 action-side 신호를 한 번에 섞는 것이 좋은지, 아니면 순차적으로 넣는 것이 좋은지 묻는다.
실험은 Qwen3-VL-4B를 중심으로 하고, 일부 분석에서는 Qwen3-VL-2B와 PaliGemma2-3B도 비교한다. downstream benchmark는 Libero-10, SimplerBridge, RoboCasa GR1 Tabletop이다. action head는 OpenVLA-OFT식 MLP head와 π0-style diffusion expert를 함께 본다.
관측은 single RGB image와 language instruction으로 제한하고 proprioception과 action history를 빼서, 초기 VLM 표현의 차이를 더 직접적으로 드러내려 한다.
공개된 근거에서 확인되는 점
가장 먼저 확인되는 것은 pretrained VLM 자체의 중요성이다. train-from-scratch 설정은 세 benchmark와 두 action head 전반에서 baseline pretrained VLM보다 크게 낮다.
예를 들어 MLP head에서 Libero-10은 66.6 대 92.4, RoboCasa는 20.3 대 49.5다.
Diffusion Expert에서도 Libero-10은 68.6 대 91.8, RoboCasa는 30.1 대 51.7이다.
논문은 scratch 정책이 전반적으로 20%p 이상 떨어진다고 요약한다.
즉 VLM pretraining은 단순한 warm start가 아니라 action 성능의 큰 원천이다.
다만 embodied VQA adaptation의 효과는 균일하지 않다.
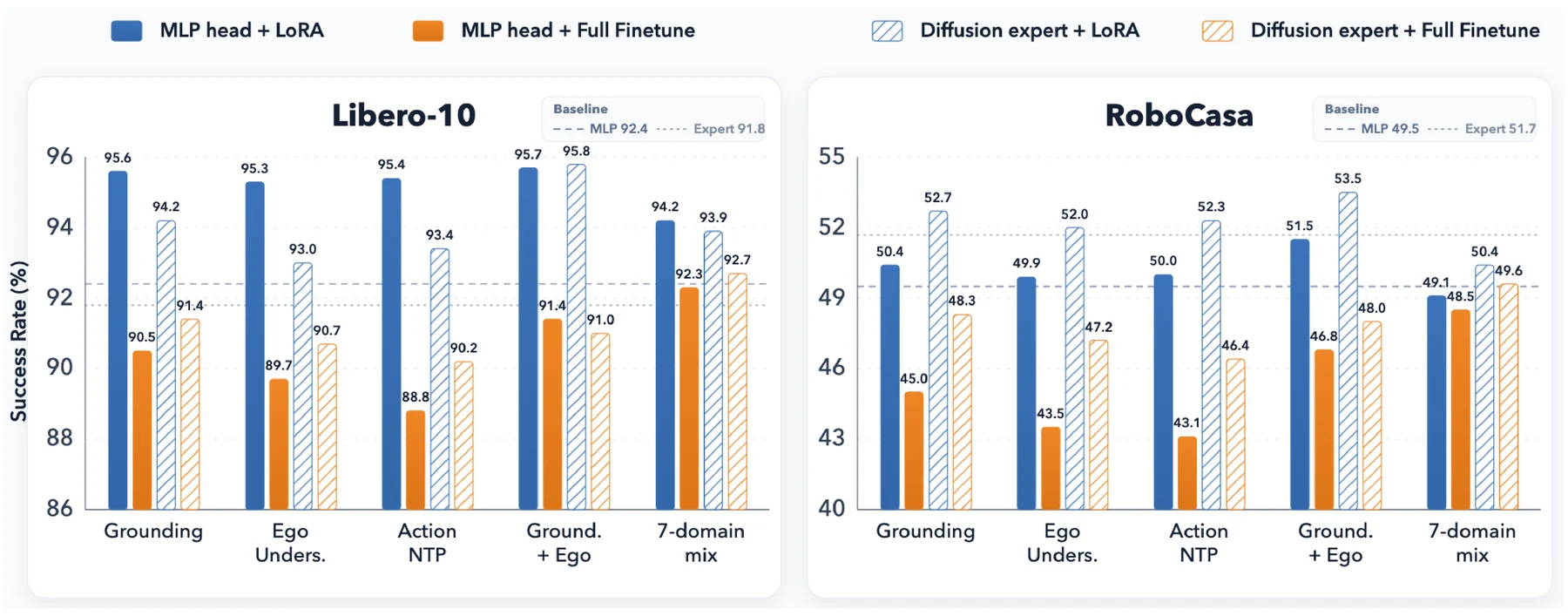
단일 도메인 적응에서 Grounding은 가장 일관적인 개선을 보인다.
MLP head 기준 Libero-10은 92.4에서 95.6으로, RoboCasa는 49.5에서 50.4로 오른다.
Diffusion Expert 기준으로도 Libero-10은 91.8에서 94.2, RoboCasa는 51.7에서 52.7이 된다.
반면 Plan & Reasoning이나 Temporal은 Libero-10에서는 좋아 보이지만 SimplerBridge에서는 크게 떨어지는 경우가 있다.
이 패턴은 “embodied VQA를 더 잘하면 VLA도 좋아진다”보다, downstream bottleneck과 맞는 신호를 넣어야 한다는 해석에 가깝다.
도메인 조합에서도 같은 결론이 나온다.
가장 좋은 조합은 {Grounding + Egocentric Understanding}이다.
MLP head에서는 RoboCasa 51.5, Diffusion Expert에서는 Libero-10 95.8과 RoboCasa 53.5를 기록한다.
그러나 여기에 Action-NTP나 Spatial을 더 넣거나, 일곱 도메인을 uniform하게 섞으면 오히려 성능이 내려간다.
넓은 coverage가 자동으로 좋은 representation을 만들지는 않는다.
도메인 간 compatibility와 목표 benchmark의 병목이 더 중요하다.
| 질문 | 논문에서 보이는 답 | 실무적 해석 |
|---|---|---|
| VLM pretraining은 얼마나 중요한가 | scratch VLA가 여러 설정에서 20%p 이상 낮아짐 | VLM은 단순 초기값이 아니라 policy 성능의 핵심 prior |
| 어떤 VQA 도메인이 유용한가 | Grounding, Ego, Action-NTP가 상대적으로 견고하지만 benchmark별 차이가 큼 | target task 병목에 맞춘 데이터 선택이 필요 |
| 여러 도메인을 많이 섞으면 좋은가 | {Grounding + Ego}가 가장 좋고, 더 넓은 조합은 자주 포화·하락 |
broad coverage보다 compatible composition이 중요 |
| LoRA와 Full Finetune 중 무엇이 유리한가 | LoRA가 더 안정적이며 Full Finetune은 표현을 과도하게 바꿀 수 있음 | 보존된 pretrained representation이 action learning에도 계속 필요 |
| robot-data pretraining은 어떻게 결합해야 하나 | G+E 후 AgiBot LoRA pretraining이 RoboCasa 55.2로 최고 | perception 신호와 action 신호를 순차적으로 넣는 staged route가 유망 |
업데이트 전략 비교는 논문의 중심 근거다.
LoRA와 Full Finetune을 비교하면, full finetuning은 auxiliary embodied VQA score를 더 높일 수 있지만 downstream VLA 초기화에는 더 나쁠 수 있다.
Appendix C의 retention diagnostic에서 Grounding과 Ego Understanding 모두 Full Finetune은 held-out embodied VQA 점수가 LoRA보다 높지만, MMBench/MMStar 평균이 base VLM 대비 약 18% 떨어지고 VLA 평균 성공률도 base보다 낮아진다.
반면 LoRA는 일반 VLM 성능을 더 잘 보존하면서 downstream VLA 성능을 올린다.
이 결과는 “로봇에 특화할수록 좋다”는 직관을 조심스럽게 만든다.
VLA 초기화에 필요한 것은 auxiliary task를 최대한 잘 맞춘 checkpoint가 아니라, action learning에 도움이 되는 신호를 넣으면서도 pretrained representation의 transferable structure를 유지한 checkpoint다.
Full Finetune은 Stage-1 task를 잘 맞추는 대신 표현 전체를 너무 많이 재배열해, Stage-2 action learning이 의존하던 시각-언어 prior를 약화시킬 수 있다.
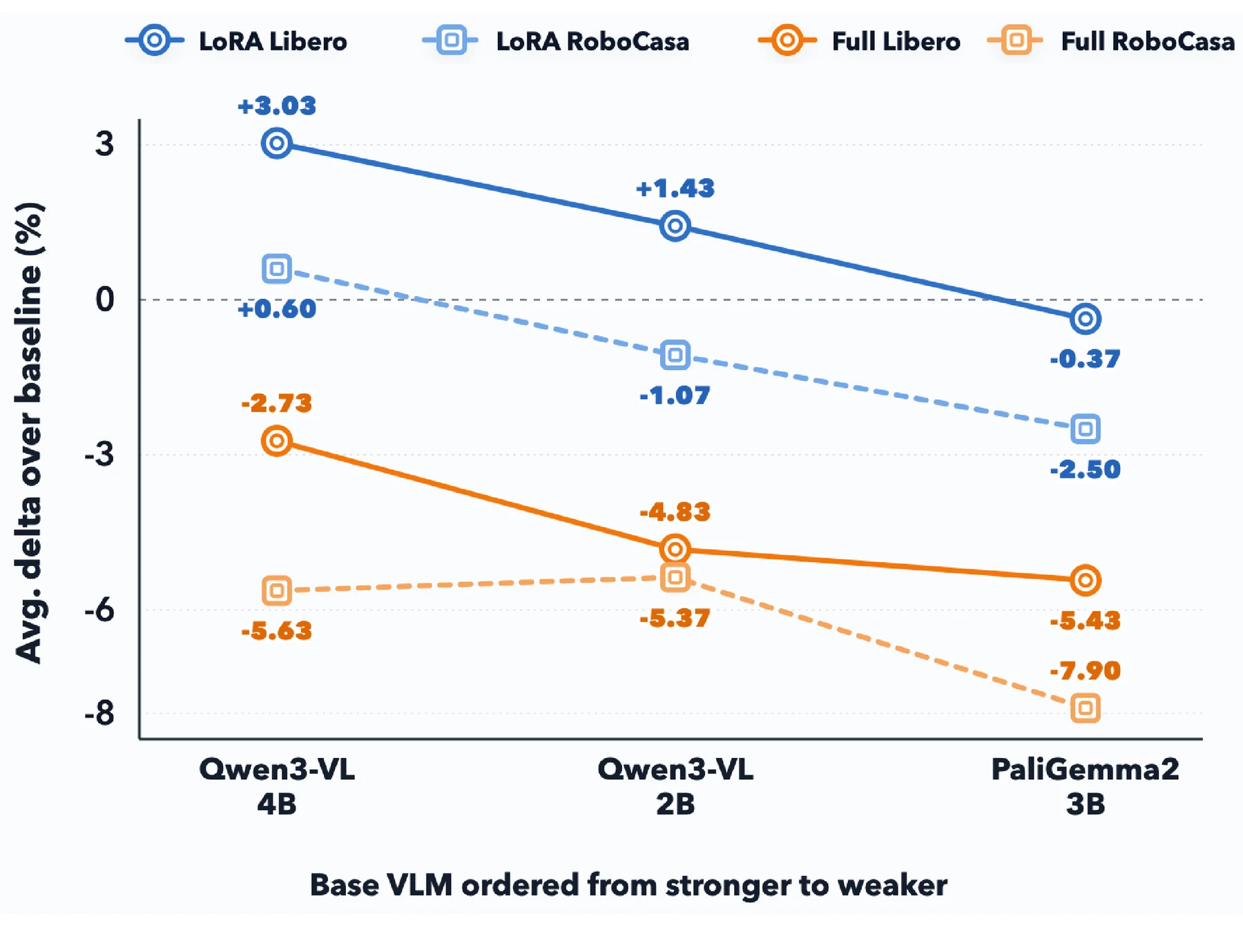
기본 VLM의 강도도 중요하다.
논문은 Qwen3-VL-4B, Qwen3-VL-2B, PaliGemma2-3B에서 Grounding, Egocentric Understanding, Action-NTP adaptation을 비교한다.
LoRA는 세 backbone 전반에서 Full Finetune보다 낫지만, base VLM이 약해질수록 LoRA gain도 줄어든다.
다시 말해 LoRA가 좋은 이유는 “작게 업데이트해서”만이 아니라, 보존할 만한 강한 pretrained representation이 있기 때문이다.
마지막으로 robot-data pretraining 결과는 staged route를 지지한다.
RoboCasa GR1에서 base는 49.5, {Grounding + Ego} adaptation만 한 경우는 51.5다.
AgiBot robot-data를 LoRA r64로 pretrain하면 54.0까지 오르고, {Grounding + Ego}로 먼저 적응한 뒤 AgiBot LoRA pretraining을 이어가면 55.2로 가장 높다.
반대로 robot-data와 VQA를 joint로 섞은 LoRA 설정은 52.4 또는 52.6에 머문다.
논문은 이를 perception-side VQA supervision과 action-side supervision이 adapter capacity를 두고 경쟁할 수 있다는 신호로 해석한다.
공개 release 관점에서는 아직 연구 아티팩트에 가깝다. arXiv HTML과 PDF, 공식 GitHub 저장소, README의 결과 테이블과 figs/framework.png는 확인된다.
GitHub API 기준 저장소는 2026년 5월 25일 생성, 5월 27일 push, MIT license, stars 6, forks 0, open issues 1, release/tag 없음 상태다.
루트에는 README.md, CITATION.cff, LICENSE, figs/가 있고 별도의 학습 코드나 checkpoint 배포는 확인되지 않았다.
README의 Quick Start도 이 저장소 자체의 runnable script라기보다 Qwen3-VL finetune 환경과 StarVLA 문서를 따라 재구현하는 high-level guide에 가깝다.
Hugging Face model/dataset API 검색에서도 이 논문명이나 arXiv ID에 해당하는 공식 checkpoint/data release는 찾지 못했다.
실무 관점에서의 해석
이 논문의 장점은 VLA 초기화를 “큰 VLM + 로봇 데이터”라는 모호한 조합에서 끌어내려, 더 구체적인 설계 변수로 나눈다는 데 있다.
실무 팀이 로봇 policy를 만들 때 흔히 선택하는 축은 model size, action head, robot dataset 규모다.
이 논문은 그 앞단에 하나를 더 둔다.
VLM representation을 어떤 신호로, 어느 정도만, 어떤 순서로 바꿀 것인가다.
가장 실용적인 교훈은 데이터 선택이다. embodied VQA 데이터가 많다는 사실만으로 좋은 초기화가 보장되지 않는다.
Grounding처럼 object-region-action 연결에 가까운 신호는 여러 설정에서 도움이 되지만, Plan & Reasoning이나 Temporal처럼 더 상위 또는 시간적 능력은 특정 benchmark에서 오히려 mismatch를 만들 수 있다.
실제 로봇 제품이나 연구 pipeline에서는 “로봇 관련 데이터”라는 큰 묶음보다, 목표 task가 실패하는 병목을 기준으로 Stage-1 supervision을 고르는 편이 맞다.
두 번째 교훈은 full finetuning에 대한 경계다. auxiliary VQA 성능을 올리는 checkpoint가 downstream policy에 좋은 checkpoint라는 보장은 없다.
특히 VLM이 이미 강한 representation을 갖고 있다면, 그것을 action task에 맞게 모두 재조정하는 것보다 LoRA처럼 제한된 경로로 필요한 신호를 주입하는 쪽이 더 낫다.
이는 로봇뿐 아니라 multimodal foundation model adaptation 전반에도 통하는 원리다. downstream 데이터가 좁고 실패 비용이 큰 영역에서는 representation drift 자체가 리스크가 된다.
세 번째 교훈은 staged adaptation이다. perception-side supervision과 action-side robot pretraining은 모두 유용하지만, 한 adapter 안에서 동시에 섞으면 목표가 충돌할 수 있다.
이 논문에서 가장 좋은 경로는 {Grounding + Ego}로 먼저 perception-side 병목을 맞춘 뒤, AgiBot action supervision을 LoRA로 이어 붙이는 방식이다.
물론 이 결과는 단일 robot-data source와 RoboCasa 중심 평가에 제한된다.
더 크고 이질적인 robot pretraining 데이터에서 같은 순서가 유지되는지는 추가 검증이 필요하다.
한계도 분명하다.
평가는 시뮬레이션 중심이며, 실제 로봇의 sensing noise, calibration error, hardware variance, dynamics mismatch까지 포함하지는 않는다.
VQA 도메인 분류도 일곱 개 coarse category라서 데이터 품질, prompt 형식, sampling ratio가 바뀌면 결과가 달라질 수 있다.
또한 공식 저장소는 현재 논문 요약과 그림, 재현 가이드 중심이라 바로 실행 가능한 release라고 보기는 어렵다.
그럼에도 이 논문은 VLM-to-VLA adaptation을 볼 때 좋은 기준선을 준다.
앞으로 로봇 VLA를 잘 초기화한다는 것은 pretrained VLM을 더 세게 덮어쓰는 일이 아니라, action-relevant 신호를 선택적으로 주입하면서도 pretrained representation의 쓸모 있는 구조를 얼마나 보존하느냐의 문제에 가까워질 가능성이 크다.
로봇 policy 학습에서 LoRA는 단순한 메모리 절약 기법이 아니라, representation drift를 제어하는 운영 장치로 읽을 필요가 있다.