개인 비서형 에이전트의 다음 병목은 “도구를 잘 고르는가”만으로는 설명되지 않는다.
실제 비서는 사용자가 명시적으로 요청하기 전부터 캘린더, 메일, 메신저, 파일, 휴대폰 알림, 업무 로그 사이의 신호를 계속 보고 있다가 적절한 순간에만 개입해야 한다.
즉 문제는 단순한 tool-use가 아니라 사용자의 디지털 세계를 얼마나 넓게 관찰하고, 그 위에서 얼마나 조심스럽게 행동할 수 있는가다.
Claw-Anything: Benchmarking Always-On Personal Assistants with Broader Access to User’s Digital World는 이 문제를 정면으로 벤치마크화한다.
논문과 공식 저장소는 Claw-Anything을 long-horizon event stream, 여러 상호 의존적인 backend service, CLI와 GUI를 포함한 cross-device interaction을 동시에 다루는 always-on personal assistant 평가 환경으로 설명한다.
공개된 벤치마크는 200개 human-verified evaluation task와 2,000개 규모의 training environment를 포함하며, Hugging Face 데이터셋 카드 기준으로는 benchmark split 200개와 train split 2,015개 row가 제공된다.
가장 중요한 신호는 성능표다.
논문 기준 GPT-5.5도 Pass@1 34.5%, Pass³ 20.0%에 그친다.
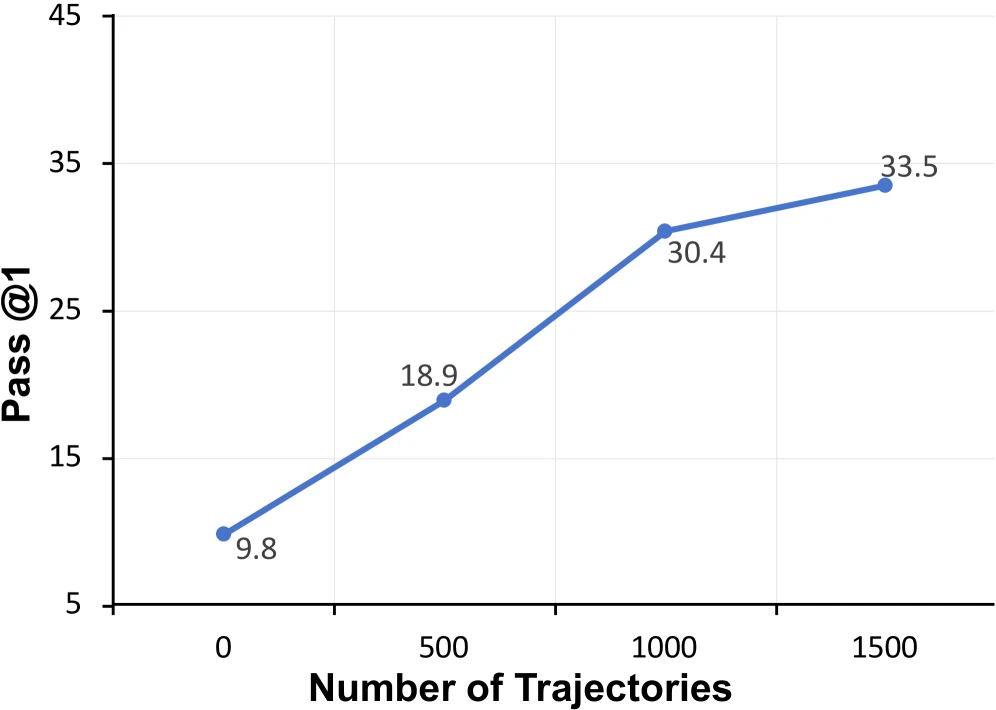
반대로 자동 생성 파이프라인에서 모은 1,500개 성공 trajectory로 Qwen3.5-27B를 후학습하면 Pass@1이 9.8%에서 33.5%로 오른다.
이 결과는 “항상 켜진 개인 비서”가 모델 하나의 추론력만으로 풀리는 문제가 아니라, 세계 상태를 만들고, 로그를 축적하고, 실패를 재현하고, 안전한 행동 경계를 평가하는 데이터 인프라 문제임을 보여 준다.
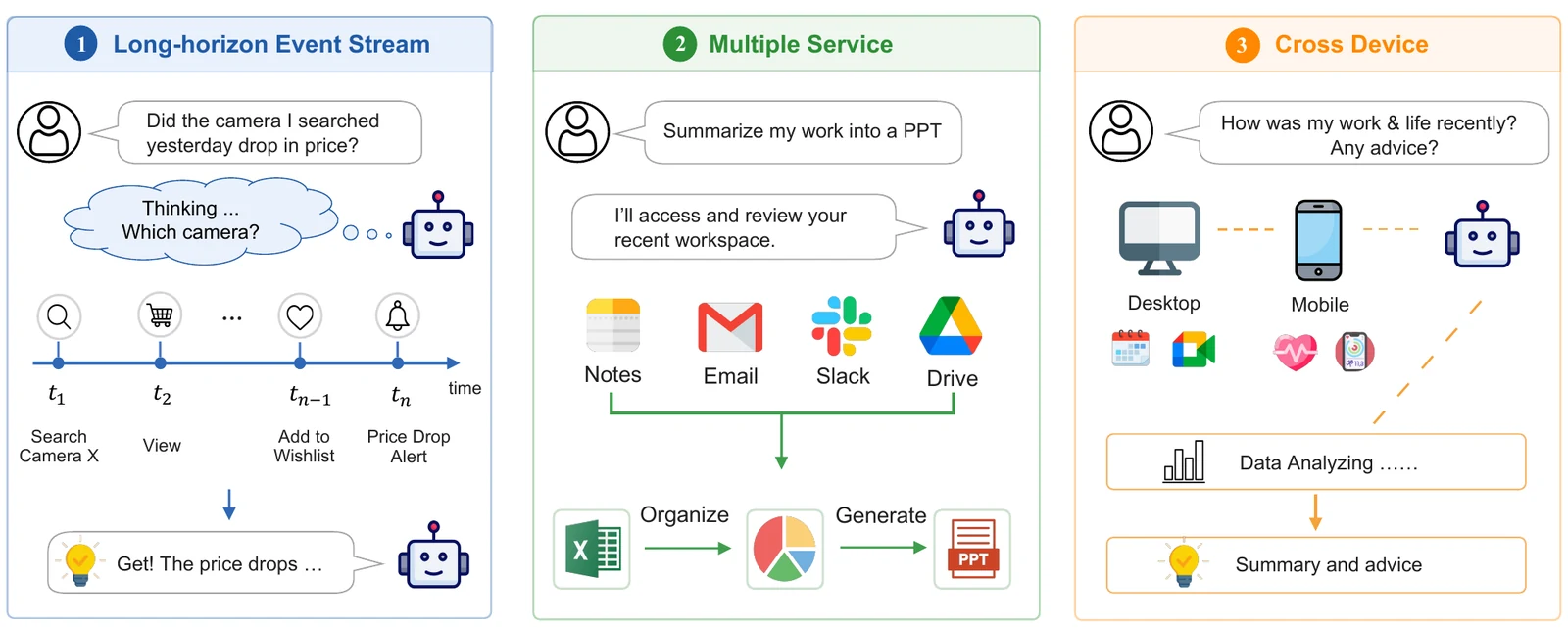
무엇을 해결하려는가
기존 에이전트 벤치마크는 대부분 좁은 상태를 준다.
단일 앱, 단일 CLI 환경, 짧은 task description, 정적 fixture, 혹은 이미 정리된 tool API를 모델에게 주고 성공 여부를 본다.
이런 설정은 도구 호출 정확도나 단기 계획 능력을 보기는 좋지만, 개인 비서가 실제로 마주치는 상황과는 거리가 있다.
사용자의 의도는 한 번의 지시문 안에 있지 않고, 수개월 전 검색 기록, 메일 쓰레드, 캘린더 변경, 메신저 알림, 파일 히스토리, 휴대폰 화면 사이에 흩어져 있다.
Claw-Anything이 겨냥하는 병목은 바로 이 operational scope다.
논문은 개인 비서의 효과가 “관찰할 수 있는 디지털 상태”와 “실행할 수 있는 행동”의 범위에 근본적으로 의존한다고 본다.
코딩 에이전트가 전체 코드베이스와 실행 환경을 가져야 현실적인 버그를 고칠 수 있고, 자율주행 시스템이 넓은 센서 범위를 가져야 안전하게 판단할 수 있듯, 개인 비서도 사용자의 실제 디지털 환경에 가까운 문맥을 가져야 한다는 주장이다.
이 설정에서 proactive assistance도 자연스럽게 평가 대상이 된다.
사용자가 “내일 회의 준비해 줘”라고 직접 말하는 reactive task만 보는 것이 아니라, 시스템이 heartbeat처럼 환경을 주기적으로 보고 있다가 “지금 이 자료를 정리해 두는 것이 좋다”거나 “이 일정 충돌을 먼저 알려야 한다”는 식의 추천을 만들 수 있는지 본다.
따라서 Claw-Anything의 질문은 “작업을 끝냈는가”에서 한 단계 더 나아가 어떤 신호를 보고, 언제 개입하고, 어디까지 행동했는가가 된다.
핵심 아이디어 / 구조 / 동작 방식
Claw-Anything의 각 환경은 논문에서 E = (P, D, F, L)로 정식화된다.P는 사용자 persona와 선호, D는 CLI 기반 컴퓨터와 GUI 기반 모바일 기기 같은 heterogeneous device, F는 여러 backend service의 persistent fixture, L은 장기 활동 로그다.
논문 본문은 fixture bank를 40개 이상 backend service로 설명하고, 공식 저장소 README는 공개 mock layer를 Gmail, Calendar, Slack, Notion, Feishu, WeChat, Zotero 등 35개 FastAPI mocked service로 설명한다.
즉 논문상의 개념은 “사용자 세계의 넓은 상태 공간”이고, 공개 구현은 이를 mock service와 Docker/Android 실행 환경으로 재현하는 형태다.
| 구성 요소 | Claw-Anything에서의 역할 | 평가상 의미 |
|---|---|---|
| Long-horizon event stream | 3개월 이상 system-level·service-specific 로그를 축적 | 과거와 현재를 연결해 사용자 맥락을 추론해야 함 |
| Backend fixtures | 여러 서비스의 persistent state와 service-specific history를 제공 | 단일 API가 아니라 서비스 간 의존성과 충돌을 풀어야 함 |
| CLI + GUI devices | Linux Docker 기반 CLI와 Android GUI 환경을 함께 사용 | 개인 비서가 컴퓨터와 모바일 사이의 정보 단절을 연결해야 함 |
| Task / verifier generation | LLM 기반 파이프라인이 query, reference solution, executable verifier를 생성 | 대규모 task 생성을 가능하게 하지만 자동 필터와 인간 검수가 필요 |
| Outcome-oriented grading | rule-based check와 LLM judge를 결합하고 최종 outcome에 높은 가중치를 둠 | 여러 valid path가 있는 개인 비서 task에서 단일 trajectory 정답의 한계를 줄임 |
데이터 생성 파이프라인은 네 단계로 구성된다.
먼저 seed persona에서 출발해 task template과 noise template을 여러 round에 걸쳐 주입하며 디지털 환경을 키운다.
이 과정에서 fixture, event log, persona update가 누적되고, 관련 없는 이벤트와 충돌 신호도 함께 섞인다.
다음으로 특정 temporal slice에서 사용자 query, executable verifier, reference solution을 함께 생성한다.
이후 rule-based check와 LLM-based filtering으로 잘못된 tool/service 참조나 verifier 불일치를 제거하고, 마지막으로 강한 agent가 reference solution을 실행해 보는 validation과 인간 검토를 거친다.
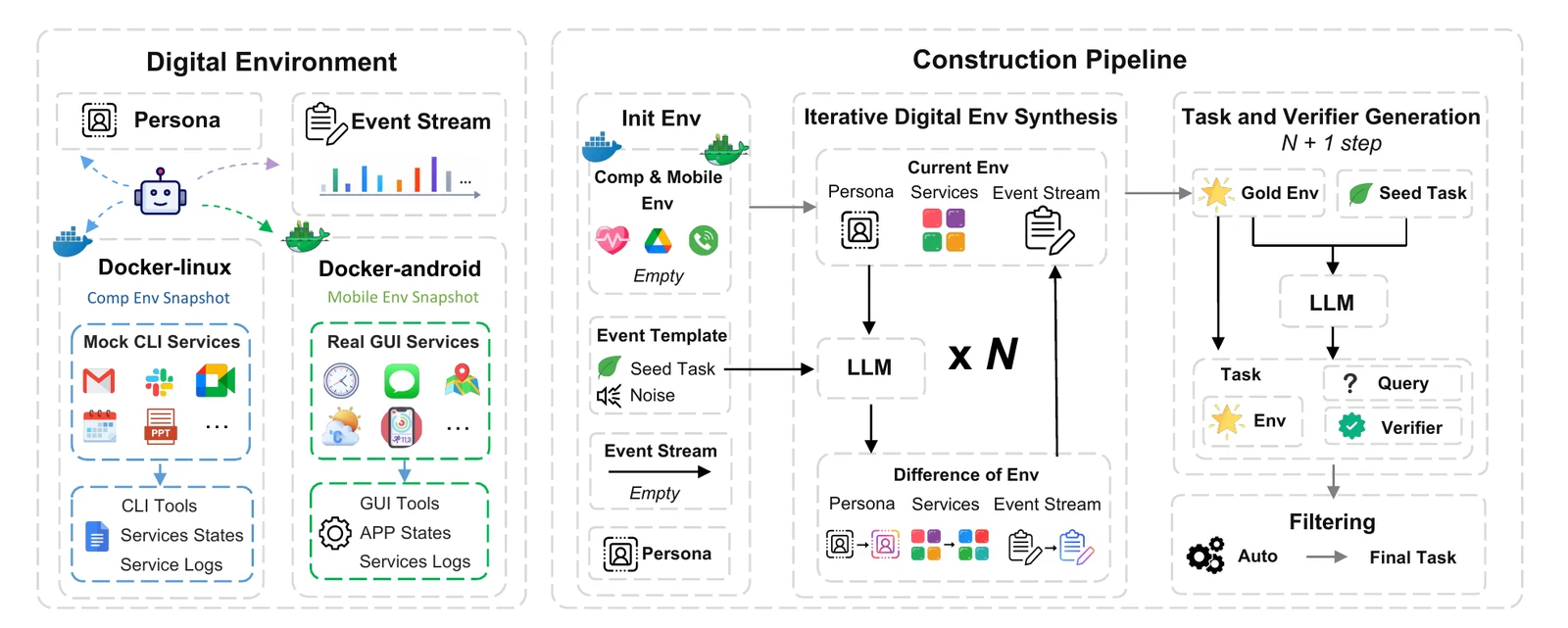
공개 저장소는 이 논문을 단순 paper-only proposal로 남기지 않는다. benchmark/에는 200개 평가 task가 skill 100개, tool 50개, gui 50개로 나뉘어 있고, src/claw_anything/runner/는 Think → Act → Observe 루프와 containerized trial 실행을 담당한다. mock_services/는 앱 backend를 모사하고, graders/는 completion, robustness, communication, safety 같은 다차원 scoring을 수행한다.
GUI task는 Android emulator와 openharness-ext를 요구하기 때문에, CLI-only 벤치마크보다 설치·실행 표면이 훨씬 무겁다.
공개된 근거에서 확인되는 점
먼저 벤치마크 크기와 문맥 규모가 기존 Claw 계열 평가와 크게 다르다.
Claw-Anything은 prior benchmark들이 대체로 CLI-only, event-stream 없음, 짧은 context로 구성된 것과 달리 event stream, CLI+GUI, proactive task, 191.7k words 수준의 context를 함께 제공한다고 보고한다.
| Benchmark | Event Stream | Device Interfaces | Services avg./max. | Proactive | Context words | Eval | Train |
|---|---|---|---|---|---|---|---|
| ClawBench | ✗ | CLI | 1.6 / 5 | ✗ | 2.2k | 313 | 0 |
| WildClawBench | ✗ | CLI | 0.5 / 3 | ✗ | 2.6k | 60 | 0 |
| Claw-Eval | ✗ | CLI | 1.3 / 6 | ✗ | 5.3k | 300 | 0 |
| Claw-Anything | ✓ | CLI + GUI | 10.1 / 18 | ✓ | 191.7k | 200 | 2000 |
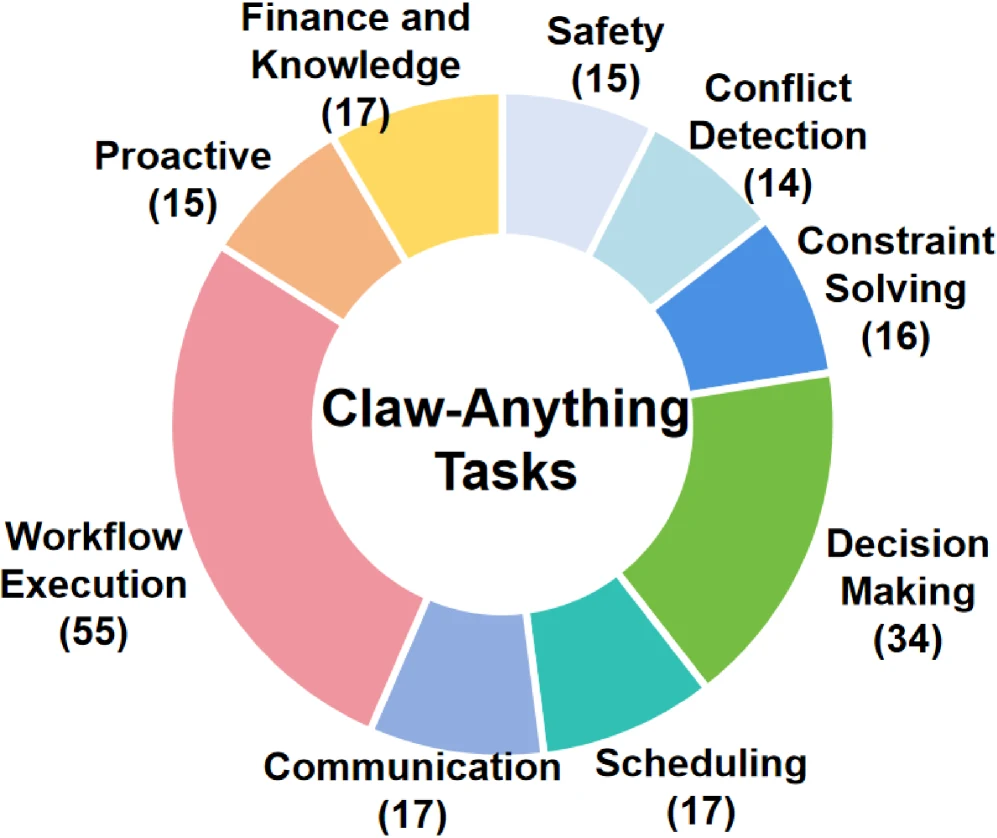
논문 Figure 4의 task distribution도 중요하다.
Claw-Anything은 workflow execution 55개, decision making 34개, scheduling 17개, communication 17개, finance and knowledge 17개, constraint solving 16개, proactive 15개, safety 15개, conflict detection 14개로 구성된다.
즉 단순한 정보 검색이나 CRUD 작업만 모은 것이 아니라, 의사결정·제약 해결·충돌 감지·안전까지 개인 비서가 실제로 마주칠 법한 category를 섞어 놓았다.
성능표는 더 냉정하다.
Pass@1 기준으로 GPT-5.5가 34.5%로 가장 높고, Claude Opus 4.7은 31.8%, Claude Sonnet 4.5는 28.0%다.
공개 모델 계열에서는 GLM-5.1이 31.7%, Kimi-K2.6이 22.8%, Qwen3.6-27B가 22.5%를 기록한다.
Claw-Anything 데이터로 후학습한 Qwen3.5-27B는 Pass@1 33.5%로 base Qwen3.5-27B의 9.8%보다 23.7 percentage point 높다.
| 모델 | 공개/폐쇄 | Pass@1 | Pass@3 | Pass³ | 해석 |
|---|---|---|---|---|---|
| Qwen3.5-27B | open | 9.8 | 19.0 | 2.0 | 기본 모델은 장기·다서비스 문맥에서 크게 흔들림 |
| Qwen3.6-27B | open | 22.5 | 42.0 | 6.0 | Pass@3와 Pass³ 간 차이가 커 반복 안정성이 약함 |
| GLM-5.1 | open | 31.7 | 47.0 | 17.0 | 공개 모델 중 강한 기준선 |
| Claw-Anything-Qwen3.5-27B | open, fine-tuned | 33.5 | 52.0 | 15.5 | 생성 pipeline trajectory가 benchmark 적합성을 크게 올림 |
| Claude Opus 4.7 | closed | 31.8 | 48.0 | 13.5 | Pass@1은 높지만 GPT-5.5보다 낮음 |
| GPT-5.5 | closed | 34.5 | 53.5 | 20.0 | 전체 최고지만 Pass³ 20.0%로 여전히 낮음 |
여기서 Pass³가 중요하다.
Pass@3는 세 번 중 한 번이라도 성공하면 올라갈 수 있지만, Pass³는 세 번 모두 성공해야 한다.
GPT-5.5도 Pass@3 53.5%에서 Pass³ 20.0%로 떨어진다.
개인 비서가 사용자의 실제 상태를 바꾸는 제품이라면 “가끔 한 번 맞힌다”보다 “반복 실행이 안정적이다”가 더 중요하다.
Claw-Anything은 이 간극을 의도적으로 드러낸다.
Ablation도 실무적으로 읽을 만하다.
논문 Table 3은 event stream을 제거하면 Pass@1이 21.0에서 0.0으로, cross-services를 제거하면 24.0에서 0.0으로 떨어지는 결과를 보고한다. cross-device interaction도 16.0에서 2.0으로 크게 낮아진다.
또한 reactive task Pass@1은 25.9인 반면 proactive task는 6.7에 머문다.
이는 모델이 명시적 지시를 처리하는 것보다, 환경을 보고 스스로 필요한 개입을 찾는 것이 훨씬 어렵다는 신호다.
릴리스 관점에서도 몇 가지 확인된다.
GitHub 저장소 LiberCoders/CLaw-Anything은 MIT 라이선스의 Python 프로젝트이며, pyproject.toml 기준 패키지 이름은 claw-anything, 버전은 1.0.0, Python 3.11+를 요구한다.
최신 GitHub API 확인 시점에는 release와 tag가 아직 비어 있어, 안정된 패키지 배포라기보다 main branch 중심의 초기 연구 artifact에 가깝다.
Hugging Face 데이터셋 LiberCoders/Claw-Anything은 gated가 아니며 Apache 2.0 라이선스 태그를 갖고, benchmark-00000-of-00001.parquet와 train-00000-of-00001.parquet 두 데이터 파일을 제공한다.
실무 관점에서의 해석
Claw-Anything의 가장 큰 의미는 개인 비서 평가의 단위를 바꾼다는 데 있다.
지금까지 많은 에이전트 평가는 “주어진 prompt를 읽고, 올바른 tool call을 해서, 마지막 상태를 맞혔는가”에 집중했다.
Claw-Anything은 여기에 사용자의 장기 로그, 서비스 간 state, 모바일 GUI, proactive trigger, permission-sensitive action을 넣는다.
그러면 평가 대상은 모델의 추론력만이 아니라 사용자 세계를 구성하는 운영 하네스 전체가 된다.
이 변화는 제품 설계와도 직접 연결된다. always-on assistant가 넓은 디지털 접근권을 갖는다면 privacy와 permission boundary가 핵심 제품 기능이 된다.
논문 Social Impact 섹션도 broad digital access가 민감한 개인 정보를 노출하거나 intrusive behavior, erroneous action, high-stakes misuse 위험을 키울 수 있다고 명시한다.
따라서 실무에서 이 벤치마크를 읽을 때는 “더 많은 권한을 주면 성능이 오른다”가 아니라, 넓은 관찰권을 어떤 감사 가능성, 사용자 제어, 승인 경계와 함께 설계할 것인가로 읽어야 한다.
또 하나의 메시지는 mock environment의 양면성이다.
Claw-Anything은 실제 Gmail·Slack·Notion 계정을 직접 조작하는 대신 mock service와 fixture/log를 통해 평가 가능한 세계를 만든다.
이는 재현성과 안전을 위해 필요하다.
동시에 현실 서비스의 인증 흐름, rate limit, UI 변경, 개인정보 동의, 조직 정책, notification fatigue는 여전히 빠져 있다.
논문 Limitations도 여러 backend service와 cross-service dependency가 있지만 많은 서비스가 controllable mock environment이고, 기기 생태계도 phone, laptop, tablet, wearable, smart-home까지 모두 포괄하지는 못한다고 인정한다.
그럼에도 방향은 분명하다.
개인 비서 에이전트가 진짜 제품이 되려면 평가도 “한 번의 요청을 잘 처리하는가”에서 “사용자 주변의 복잡한 디지털 상태를 오래 보고, 필요한 순간에만 개입하며, 승인된 범위 안에서 여러 서비스를 안전하게 바꾸는가”로 이동해야 한다.
Claw-Anything은 그 이동을 위한 꽤 구체적인 기준점을 제공한다.
특히 자동 data-generation pipeline과 benchmark를 같은 코드베이스에 묶은 점은 앞으로의 에이전트 개발에서 반복될 가능성이 높다.
좋은 모델보다 오래 남는 것은, 좋은 개인 비서 행동을 대량으로 만들고 검증하고 실패 모드를 축적하는 데이터·평가 공장일 수 있기 때문이다.
한 줄로 요약하면
Claw-Anything은 always-on 개인 비서 평가를 단기 tool-use에서 수개월치 사용자 로그, 여러 mock backend service, CLI·Android GUI 기기, proactive intervention, outcome-oriented verifier가 결합된 end-to-end 환경으로 확장한다.
현재 최고권 모델도 Pass@1 34.5%에 머문다는 점은, 개인 비서 에이전트의 난제가 모델 성능뿐 아니라 권한·문맥·안전·데이터 인프라 설계 문제임을 보여 준다.