AI 에이전트의 장기 메모리를 이야기할 때 흔한 기본값은 “중요한 정보를 저장하고, 나중에 비슷한 질문이 오면 검색한다”는 구조다.
벡터 DB, 요약된 대화 기록, 경험 로그, skill 문서가 모두 이 틀 안에 들어간다.
하지만 장기 실행 에이전트에서는 이 단순한 저장소 모델이 금방 흔들린다.
어떤 기억은 너무 넓고, 어떤 기억은 너무 좁다.
어떤 연결은 빠지고, 어떤 연결은 noise를 끌고 온다.
그리고 같은 유형의 과제를 반복해도 에이전트는 매번 비슷한 연결을 다시 만들어야 한다.
HF Papers에 올라온 Rethinking Memory as Continuously Evolving Connectivity는 이 문제를 정면으로 다시 정의한다.
논문이 제안하는 FluxMem의 핵심은 메모리를 “정적 repository”가 아니라 계속 진화하는 연결성(connectivity)으로 보는 것이다.
메모리 단위 자체도 바뀌고, 메모리 사이의 link도 feedback에 따라 생성·삭제·재구성된다.
반복적으로 성공한 실행 궤적은 procedural circuit으로 굳어지고, 충분히 성숙해진 연결은 다음 과제에서 더 빠르게 활성화된다.
이 글의 핵심 해석은 간단하다.
FluxMem은 “무엇을 기억할 것인가”보다 어떤 기억들이 지금 과제에서 서로 연결되어야 하는가를 중심 문제로 올린다. agent memory를 retrieval 문제에서 graph topology optimization 문제로 옮기는 시도다.
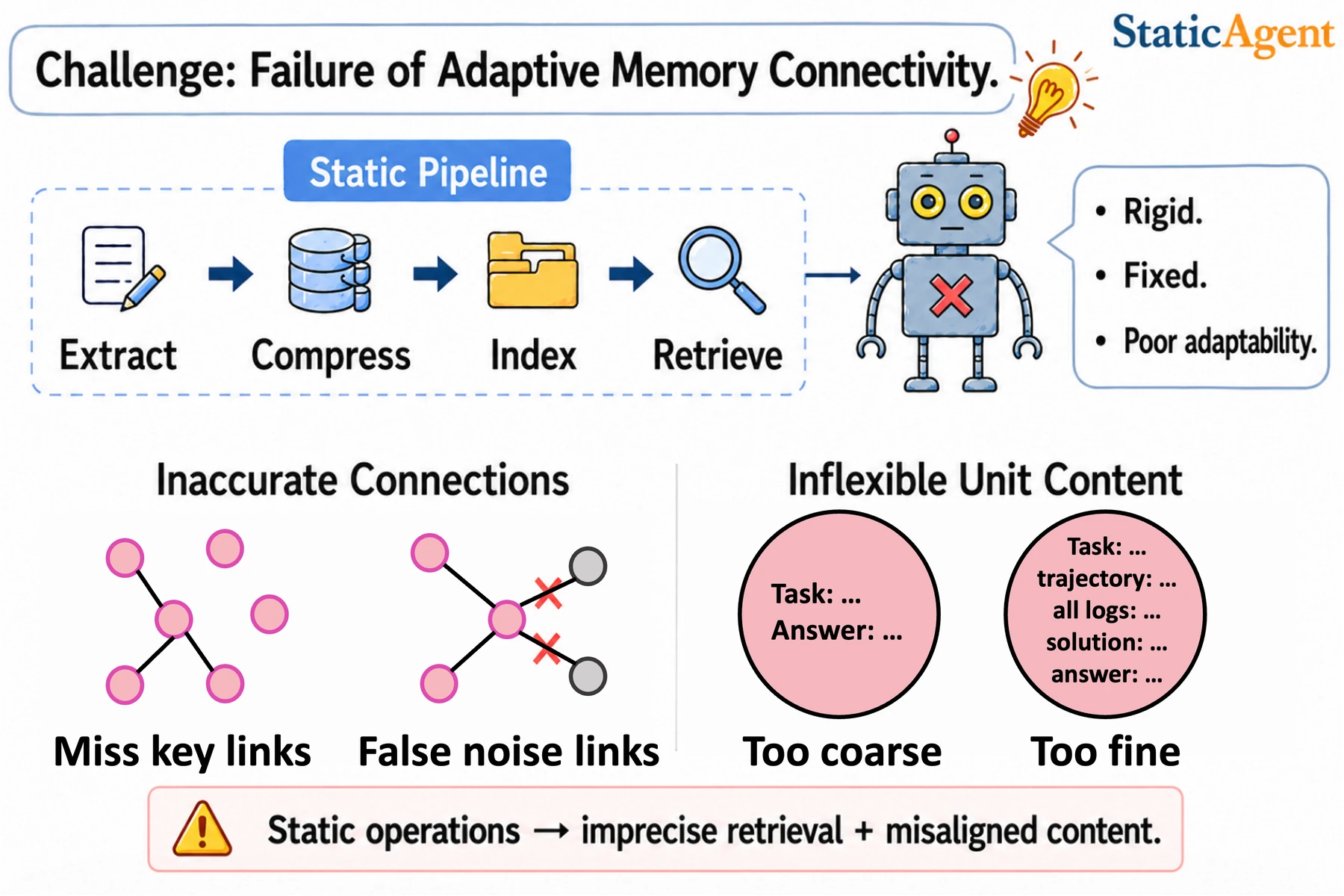
무엇을 해결하려는가
논문이 비판하는 대상은 고정된 memory pipeline이다.
많은 memory-augmented agent는 memory unit의 표현 방식과 retrieval 경로를 미리 정해 둔다.
예를 들어 과거 대화는 요약해서 저장하고, task trajectory는 embedding으로 검색하고, skill은 별도 문서로 붙이는 식이다.
이 구조는 시작하기 쉽지만, agent가 동적인 환경에서 feedback을 받으며 행동할 때는 세 가지 문제가 생긴다.
첫째는 under-connection이다.
현재 과제에 필요한 기억이 있는데도 연결이 형성되지 않아 agent가 핵심 context를 못 본다.
장기 대화 QA나 툴 사용 과제에서는 하나의 fact만으로는 부족하고, 여러 evidence와 과거 행동이 같이 활성화되어야 하는 경우가 많다.
둘째는 over-connection이다.
관련 없어 보이는 기억까지 한꺼번에 들어와 context가 noisy해진다.
에이전트 입장에서는 더 많은 memory가 항상 좋은 것이 아니다.
잘못 연결된 memory는 hallucination이나 잘못된 tool choice로 이어질 수 있다.
셋째는 granularity mismatch다. memory unit이 너무 coarse하면 실행에 필요한 세부가 빠지고, 너무 fine하면 재사용 가능한 절차 패턴이 보이지 않는다.
예를 들어 “표를 분석한다”는 skill은 너무 넓을 수 있고, 특정 CSV의 특정 column만 처리한 trajectory는 너무 좁을 수 있다.
과제에 맞게 memory unit의 추상화 수준을 바꾸는 일이 필요하다.
FluxMem은 이 세 문제를 모두 “연결의 진화”로 다룬다.
기억을 단순히 더 많이 넣는 것이 아니라, 실행 중 feedback을 보고 빠진 link를 추가하고, 방해되는 link를 끊고, unit 내용을 더 세밀하게 또는 더 추상적으로 reshape한다.
핵심 구조: 세 층짜리 heterogeneous memory graph
FluxMem의 memory는 heterogeneous graph G=(V,E)다.
노드는 세 층으로 나뉜다.
| 층 | 역할 | 예시 |
|---|---|---|
| Semantic Knowledge | factual evidence를 담는 정적 지식층 | 대화 기록, 문서 chunk, tool API 문서 |
| Episodic Experiences | 구체적인 과제 실행 궤적 | observation-action trajectory, tool-use sequence |
| Procedural Skills | 여러 episode에서 추출된 재사용 절차 | multi-step planning heuristic, table QA recipe |
이 중 episodic layer가 중간 허브처럼 동작한다.
과제를 수행하면서 semantic fact와 연결되고, 여러 episode가 반복되면 procedural skill로 증류된다.
즉 단순한 “knowledge → answer”가 아니라, knowledge → episode → skill이라는 bottom-up 연결이 생긴다.
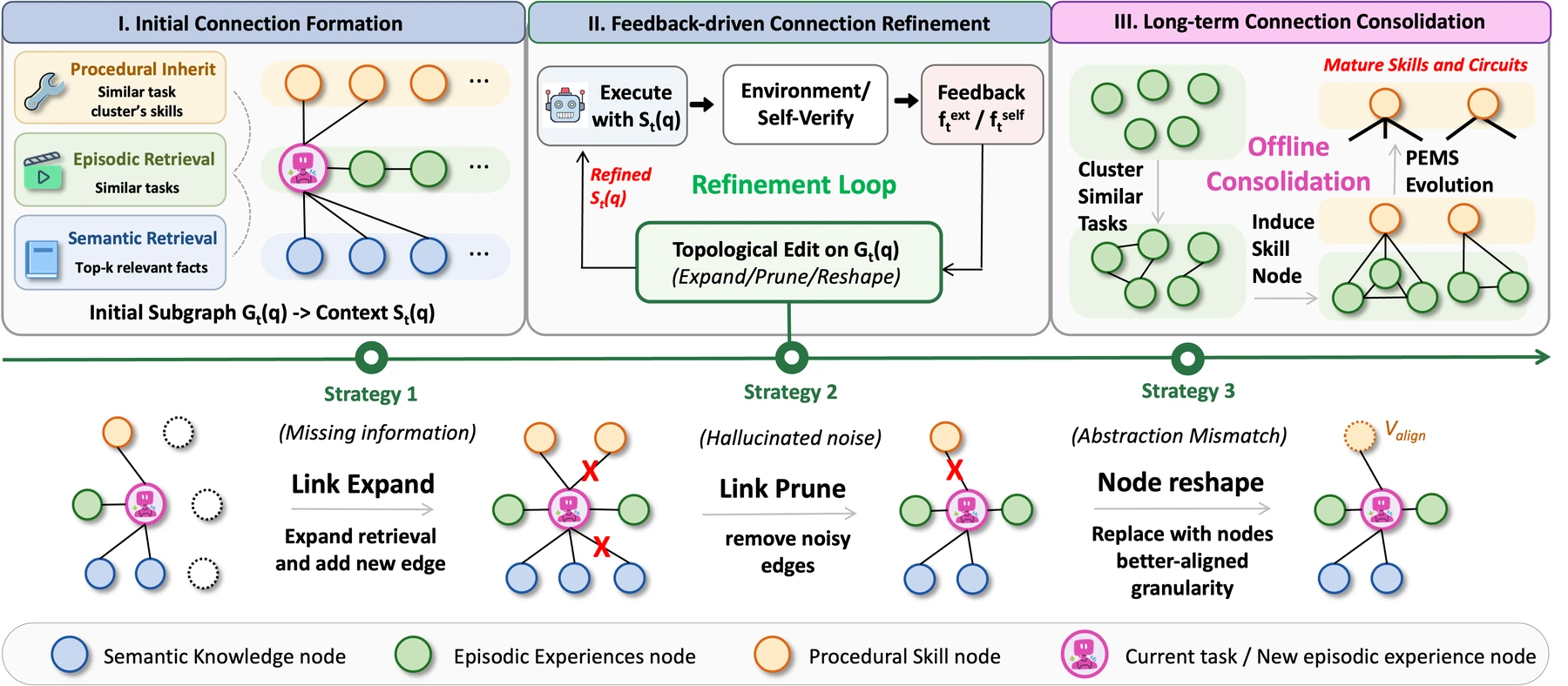
중요한 점은 context도 이 graph에서 유도된다는 것이다.
논문은 현재 step의 context를 task, observation, 활성화된 semantic node, episodic node, procedural node의 concat으로 본다.
따라서 context를 개선하는 일은 곧 현재 subgraph의 node와 edge를 고치는 일이다.
이 관점이 FluxMem을 일반적인 RAG memory와 다르게 만든다.
세 단계의 memory evolution
FluxMem의 동작은 세 stage로 정리된다.
Stage I. Initial Connection Formation
현재 observation을 기준으로 semantic knowledge를 찾고, 유사한 episodic trajectory를 검색하고, 그 episode와 연결된 procedural skill을 가져온다. semantic retrieval은 dense embedding similarity, BM25, LLM-based verification을 결합한 score로 계산된다. episodic retrieval은 embedding similarity를 쓰고, procedural skill은 retrieved episode에서 distillation edge를 따라 상속된다.
이 단계는 “일단 관련 있어 보이는 subgraph를 만든다”에 가깝다.
하지만 논문은 이 연결이 어디까지나 tentative하다고 본다.
처음 만든 연결은 충분히 정확하지 않을 수 있고, 다음 stage에서 feedback으로 수정된다.
Stage II. Feedback-Driven Connectivity Refinement
Stage II는 FluxMem에서 가장 실무적으로 흥미로운 부분이다.
실행 feedback이나 self-verification 결과를 보고 실패 원인을 connection-level 또는 unit-level 문제로 attribution한다.
- Link Expansion: 필요한 context가 빠졌다면 아직 활성화되지 않은 node를 찾아 새 edge를 만든다.
- Link Pruning: irrelevant memory가 hallucinated guidance를 만들면 noise edge를 제거한다.
- Content Reshaping: retrieval은 맞지만 memory unit의 추상화 수준이 안 맞으면 unit 내용을 더 자세히 펼치거나 더 추상화한다.
이 방식은 agent memory를 단발 검색이 아니라 closed-loop editing 문제로 바꾼다.
검색 결과가 틀렸으면 다시 검색하는 정도가 아니라, 왜 현재 subgraph가 실패했는지 보고 topology 자체를 수정한다.
Stage III. Long-Term Connection Consolidation
Stage III는 offline 단계다.
완료된 task trajectory를 episodic node로 저장하고, 비슷한 episode들을 clustering한 뒤, 공통 reasoning pattern을 procedural skill node로 추출한다.
여기까지는 많은 “experience replay” 또는 “procedural memory” 계열 방법과 비슷해 보인다.
FluxMem이 추가하는 것은 PEMS, Procedure Evolution Maturity Score다.
논문은 skill의 평균 성공률, skill text 길이, 이전 버전과의 embedding 변화량을 조합해 skill이 얼마나 유용하고 간결하며 안정적으로 수렴했는지를 본다.
직관적으로 쓰면 다음과 같다.
PEMS ≈ source episode 성공률 / log(skill 길이) × (1 - 이전 skill 버전과의 변화량)
즉 좋은 procedural memory는 단순히 성공률만 높으면 안 된다.
너무 길고 장황하면 penalty를 받고, 매 iteration마다 계속 크게 바뀌면 아직 성숙하지 않은 것으로 본다.
PEMS 개선폭이 threshold 아래로 떨어지면 consolidation을 멈출 수 있다.
이 부분은 agent memory의 “언제 충분히 배웠다고 볼 것인가”라는 운영 질문과 바로 연결된다.
공개된 실험 결과에서 보이는 신호
논문은 LoCoMo, Mind2Web, GAIA 세 benchmark로 FluxMem을 평가한다.
세 벤치마크는 성격이 꽤 다르다.
| 벤치마크 | 성격 | 논문이 보는 memory 요구 |
|---|---|---|
| LoCoMo | 긴 대화 기반 long-context reasoning | 필요한 fact와 시간/대화 context를 정확히 회수해야 함 |
| Mind2Web | 실제 웹 내비게이션 | noisy DOM과 과거 행동을 바탕으로 다음 action을 고르는 절차성이 중요 |
| GAIA | general assistant task | tool use, multi-step reasoning, multimodal/long-horizon 실행이 섞임 |
LoCoMo에서는 GPT-4.1-mini backbone 기준 FluxMem이 평균 LMJ 95.06을 기록한다.
같은 표에서 Full Context는 81.23, EverMemOS는 93.05다.
Qwen3-30B-A3B-2507-Instruct에서도 FluxMem은 평균 93.44를 기록하고, Full Context는 74.87에 머문다.
이 결과는 long-context reasoning에서 단순히 전체 context를 넣는 것보다, 관련 memory connection을 정교하게 만드는 편이 낫다는 논문의 주장을 뒷받침한다.
Mind2Web에서는 현실적인 setting이 중요하다.
논문은 manual element filtering이 있는 filtered setting과, 그런 pre-filtering 없이 모든 candidate element를 다루는 realistic setting을 구분한다.
GPT-4.1-mini의 realistic setting에서 FluxMem은 Cross-Task Success Rate 8.1을 기록해 AWM 3.6보다 높다.
Gemini-2.5-flash에서도 FluxMem은 Cross-Task SR 9.6으로 AWM 5.6보다 높다.
수치 자체는 낮지만, 웹 navigation에서 full-task success가 어려운 지표라는 점을 고려하면 의미 있는 차이다.
GAIA에서는 Flash-Searcher framework 위에서 memory augmentation 효과를 비교한다.
Kimi K2 기준 Flash-Searcher baseline 평균 성공률은 52.12이고, FluxMem은 64.85까지 올린다.
절대 개선폭은 +12.73%p다.
GPT-5-mini 기준으로도 69.09에서 76.36으로 올라가고, DeepSeek V3.2 기준으로는 60.61에서 70.30으로 올라간다.
| 영역 | 대표 결과 | 해석 |
|---|---|---|
| LoCoMo / GPT-4.1-mini | FluxMem 95.06 vs Full Context 81.23 vs EverMemOS 93.05 | 긴 대화 QA에서는 Stage II식 연결 refinement가 큰 역할 |
| LoCoMo / Qwen3-30B | FluxMem 93.44 vs Full Context 74.87 | 더 작은/open 계열 backbone에서도 연결 구조의 이득이 유지됨 |
| Mind2Web / GPT-4.1-mini realistic | Cross-Task SR 8.1 vs AWM 3.6 | noisy web action 환경에서는 procedural consolidation의 이득이 큼 |
| Mind2Web / Gemini-2.5-flash realistic | Cross-Task SR 9.6 vs AWM 5.6 | 다른 backbone에서도 같은 방향의 개선 |
| GAIA / Kimi K2 | 52.12 → 64.85 | general assistant task에서 Flash-Searcher baseline 대비 +12.73%p |
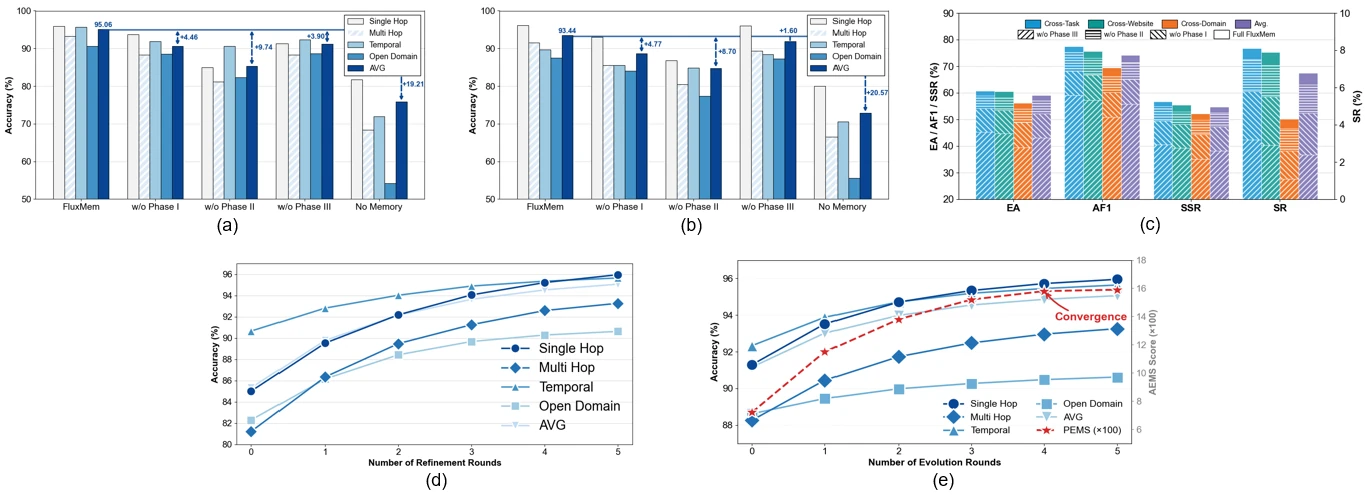
Ablation 결과는 task 성격에 따라 어떤 memory operation이 중요한지 보여 준다.
LoCoMo에서는 Stage II가 핵심이다.
GPT-4.1-mini에서 Stage II를 제거하면 평균 LMJ가 95.06에서 85.32로 내려가고, Qwen3-30B에서도 93.44에서 84.74로 내려간다.
대화 기반 memory QA는 결국 필요한 evidence를 정확히 연결하는 문제가 크기 때문에, 빠진 link를 보강하고 noise link를 제거하는 refinement가 크게 먹힌다.
반대로 Mind2Web에서는 Stage III가 더 중요하게 나타난다.
논문은 GPT-4.1-mini에서 Stage III를 제거하면 첫 sub-category의 success rate가 8.1에서 3.2로 떨어지는 예를 든다.
웹 navigation은 단순 fact recall보다 반복되는 절차, 행동 패턴, 실패 후 수정 전략이 중요하므로, episode에서 procedural skill을 뽑아내는 장기 consolidation이 더 큰 역할을 한다는 해석이다.
Case study가 보여 주는 practical workflow
논문 Figure 4의 case study는 GAIA의 tabular reasoning task다. agent는 CSV에서 “athlete당 평균 medal 수가 가장 높은 country”를 찾아야 한다.
처음에는 CSV parsing과 spreadsheet API 관련 semantic memory, tabular ranking에 대한 episodic memory, coarse table QA skill이 활성화된다.
하지만 실행 중 spreadsheet visualization API를 잘못 호출하면서 rendering limitation 때문에 실패한다.
FluxMem은 이를 connectivity mismatch로 보고, 해당 semantic connection을 prune한 뒤 Python data-analysis API 쪽으로 연결을 확장한다.
이후 aggregation은 성공하지만, self-verification에서 기존 procedural skill이 너무 coarse하다는 문제가 드러난다.
단순 ranking은 할 수 있지만 “medals per athlete”라는 새 metric을 구성하는 절차가 부족했던 것이다.
그래서 skill node를 더 fine-grained statistical aggregation procedure로 reshape한다.
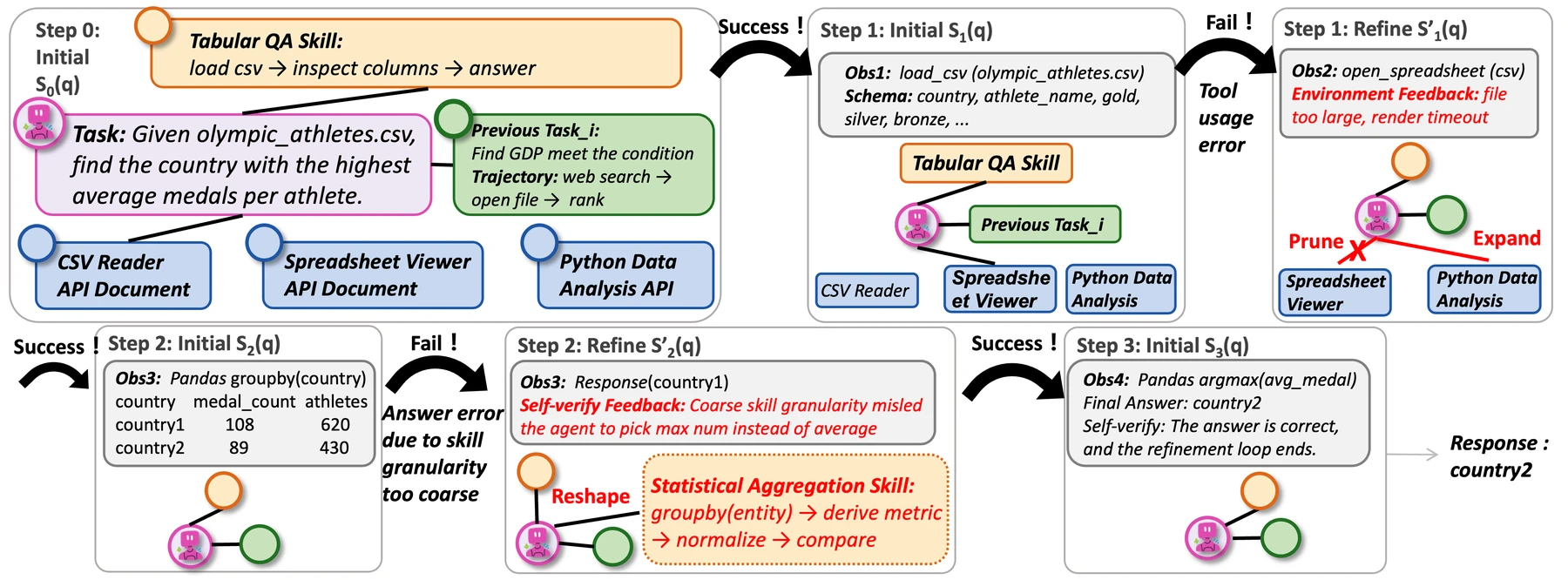
이 예시는 FluxMem의 장점을 잘 보여 준다.
실패를 단순히 “다시 시도”로 처리하는 것이 아니라, 어떤 memory connection이 잘못됐는지와 어떤 skill granularity가 부족했는지를 분리한다.
실무 agent에서도 비슷한 문제가 자주 생긴다.
예를 들어 repo 분석 agent가 시각화 도구를 호출해야 할지, pandas로 계산해야 할지, shell로 grep해야 할지 고르는 문제는 단순 retrieval보다 도구와 경험의 연결 구조에 가깝다.
companion source 상태: 공식 코드는 아직 FluxMem이 아니다
이번 자료에서 주의해야 할 점은 공개 구현 상태다. arXiv abstract와 HF Papers page는 code가 https://github.com/zjunlp/LightMem에 공개될 예정이라고 안내한다.
하지만 조회 시점 GitHub API tree와 README 기준으로는 zjunlp/LightMem의 main, StructMem, config branch 어디에도 FluxMem, PEMS, Mind2Web, GAIA 관련 파일명이나 README 언급이 확인되지 않았다.
현재 공개 repo는 이름 그대로 LightMem 중심이다.
GitHub metadata 기준 설명도 [ICLR 2026] LightMem: Lightweight and Efficient Memory-Augmented Generation이고, MIT license, Python 중심 코드베이스, LoCoMo/LongMemEval 관련 실험과 LightMem MCP server, StructMem 문서가 포함되어 있다.
README의 최근 news에는 LightMem, StructMem, MemBase가 언급되지만 FluxMem은 아직 들어 있지 않다. releases와 tags도 비어 있다.
따라서 현재 시점에서 FluxMem은 “논문과 공식 그림/표로 방법론을 검토할 수 있는 상태”에 가깝고, 바로 실행 가능한 FluxMem 구현을 clone해서 재현할 수 있는 상태는 아니다.
LightMem repo는 같은 연구 그룹의 memory framework 표면과 향후 공개 위치로 보는 편이 안전하다.
| 확인 항목 | 공개 상태 |
|---|---|
| HF Papers page | arXiv HTML/PDF로 연결, code는 LightMem repo 예정으로 표시 |
| arXiv metadata | v1, 2026-05-27 제출, comments는 “Ongoing work” |
| companion GitHub | zjunlp/LightMem 지정 |
| 현재 repo 내용 | LightMem/StructMem 중심, FluxMem 파일·README 언급 미확인 |
| license metadata | LightMem repo는 MIT license |
| tags/releases | GitHub API 기준 없음 |
실무 관점에서의 해석
FluxMem의 가장 큰 가치는 agent memory를 “저장과 검색”에서 “연결 구조의 지속적 편집”으로 끌어올린다는 점이다.
많은 agent memory 시스템은 기억을 어느 store에 넣을지, embedding을 어떻게 만들지, top-k를 얼마로 할지에 집중한다.
FluxMem은 그 다음 질문을 던진다.
검색된 기억들이 지금 과제에서 어떤 graph를 이루어야 하며, 실패 feedback을 받았을 때 그 graph를 어떻게 고칠 것인가.
이 관점은 최근 agent system의 여러 흐름과 잘 맞는다.
Arize Alyx 같은 context management 사례는 context window 밖에 큰 데이터를 두고 필요한 slice를 다시 가져오는 구조를 강조한다.
SkillOpt나 Autogenesis 같은 self-evolution 논문은 절차 지식을 외부 artifact나 versioned resource로 다루려 한다.
FluxMem은 이 둘 사이에서, semantic evidence, episodic trajectory, procedural skill이 어떻게 연결되고 성숙해지는지에 초점을 둔다.
특히 PEMS는 아직 거친 지표이지만 실무적으로 흥미롭다. agent memory는 계속 커질 수밖에 없고, 모든 경험을 무한히 반영하면 latency와 비용이 폭발한다.
따라서 어떤 skill이 충분히 유용하고 간결하며 안정적으로 수렴했는지를 판단하는 stop criterion이 필요하다.
FluxMem은 성공률, 길이, 변화량을 묶어 이 질문에 답하려 한다.
다만 논문 자체도 한계를 인정한다.
Stage II와 III는 추가 LLM call을 요구하므로 latency, token cost, API cost가 늘어난다.
실험은 task success와 convergence에 집중하고, 실제 운영 환경에서 비용 대비 이득을 체계적으로 측정하지는 않는다.
또한 LoCoMo, Mind2Web, GAIA는 다양하지만 여전히 static benchmark다. streaming environment, 모호한 task boundary, memory decay, privacy constraint가 있는 실제 장기 개인 비서 환경과는 차이가 있다.
또 하나의 주의점은 hyperparameter다. refinement round T, top-k, PEMS threshold ε, consolidation scheduling 같은 설정은 실제 시스템에서 품질과 비용을 크게 좌우한다.
논문 Figure 3은 refinement round가 늘수록 성능이 좋아지다가 포화되는 모습을 보여 주지만, 모든 domain에서 같은 budget이 맞는지는 별도 문제다.
그럼에도 FluxMem이 던지는 질문은 중요하다.
장기 실행 agent가 같은 실패를 반복하지 않으려면, 단순히 실패 로그를 저장하는 것만으로는 부족하다.
실패 로그가 어떤 memory link를 만들고, 어떤 link를 끊고, 어떤 skill을 더 세밀하게 만들지로 이어져야 한다.
FluxMem은 이 과정을 graph evolution으로 정식화한다.
정리
FluxMem은 memory-augmented agent의 다음 병목이 단순 저장 용량이나 retrieval top-k가 아니라 연결의 품질과 성숙도라고 본다.
Semantic knowledge, episodic experience, procedural skill을 세 층짜리 graph로 두고, online feedback으로 연결을 고치며, offline consolidation으로 반복 성공 궤적을 skill circuit으로 굳힌다.
논문 수치만 보면 LoCoMo, Mind2Web, GAIA에서 강한 개선을 보고한다.
특히 LoCoMo에서는 Stage II refinement가, Mind2Web에서는 Stage III procedural consolidation이 중요하게 나타난다는 점이 흥미롭다. task 성격에 따라 memory system이 강화해야 할 축이 다르다는 뜻이기 때문이다.
하지만 현재는 “ongoing work”이고, 공식 companion repo로 지정된 LightMem에는 아직 FluxMem 코드가 공개되지 않았다.
따라서 지금 당장 가져다 쓸 SDK라기보다는, agent memory architecture를 설계할 때 참고할 수 있는 강한 연구 신호로 읽는 편이 맞다.
핵심 takeaway는 이것이다.
에이전트 메모리는 더 큰 창고가 아니라, 계속 수정되고 수렴하는 연결망이어야 한다.