자율주행용 비전-언어-액션 모델(VLA)에서 Chain-of-Thought는 성능을 올리는 데 꽤 강력한 도구로 자리 잡았다. 문제는 그 대가가 너무 크다는 점이다. 장면을 해석하고, 주변 객체의 의도를 추론하고, 최종 trajectory를 산출하기까지 reasoning token을 길게 생성해야 하다 보니, explicit CoT는 실시간 제약이 강한 주행 시스템에서는 지연 비용이 치명적일 수 있다.
OneVL은 이 병목을 정면으로 건드린다. Xiaomi Embodied Intelligence Team이 공개한 이 기술 보고서는 latent CoT를 단순히 “텍스트 reasoning을 압축한 hidden state”로 보지 않고, 미래 장면 변화까지 담는 world-model latent로 재설계한다. 핵심 메시지는 분명하다. 자율주행에서 필요한 것은 언어적 설명의 압축이 아니라, 도로 기하와 에이전트 움직임, 환경 변화를 포함한 인과 구조의 압축이라는 것이다.
흥미로운 점은 이 접근이 단지 해석 가능한 보조 출력 하나를 더 붙인 수준이 아니라는 데 있다. OneVL은 language auxiliary decoder와 visual world model decoder를 함께 두고 학습 단계에서만 latent를 강하게 감독한 뒤, 추론 시에는 이 보조 디코더를 버리고 latent token을 한 번에 prefill한다. 즉 학습 때는 설명 가능성과 세계모델 압축을 밀어 넣고, 추론 때는 answer-only 수준 속도를 유지하는 식이다.
무엇을 해결하려는가
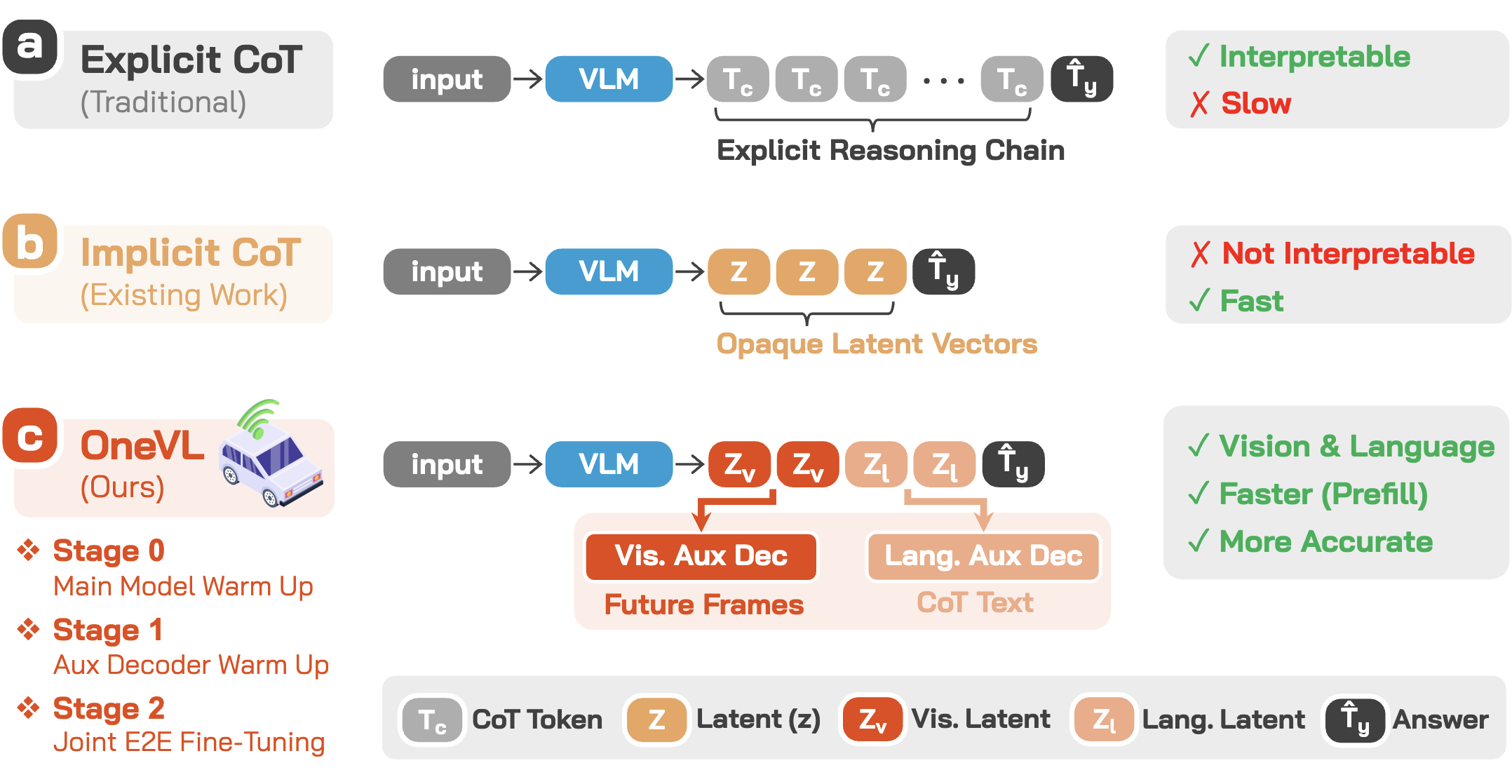
OneVL이 겨냥하는 문제는 기존 latent CoT가 자율주행에서는 생각보다 잘 먹히지 않는다는 점이다. 논문과 프로젝트 페이지가 반복해서 강조하는 바에 따르면, 기존 latent CoT 계열은 텍스트 reasoning을 hidden state에 압축해 latency를 줄이지만, driving task에서는 explicit CoT보다 오히려 성능이 떨어지는 경우가 많았다. 그 이유에 대해 저자들은 꽤 설득력 있는 가설을 제시한다. 순수 언어 latent는 세계의 상징적 요약만 담을 뿐, 실제 주행을 좌우하는 causal dynamics를 충분히 담지 못한다는 것이다.
자율주행 trajectory prediction은 단순한 답 생성이 아니다. 차선 구조, 신호, 주변 차량의 상대 운동, 공사 구간이나 예측 불가능한 object behavior를 모두 고려해야 한다. 이런 문제에서는 설명 문장을 압축하는 것만으로는 부족하고, 앞으로 scene이 어떻게 변할지를 내재화한 표현이 필요하다. OneVL은 바로 그 점에서 latent CoT를 world-model supervision으로 다시 묶는다.
또 하나의 문제는 운영 지연이다. explicit CoT는 해석 가능하지만 느리고, answer-only는 빠르지만 reasoning benefit이 제한적이다. OneVL의 목표는 이 둘을 절충하는 것이 아니라, explicit CoT급 혹은 그 이상 정확도를 answer-only latency에 가깝게 가져오는 것이다.
핵심 아이디어 / 구조 / 동작 방식
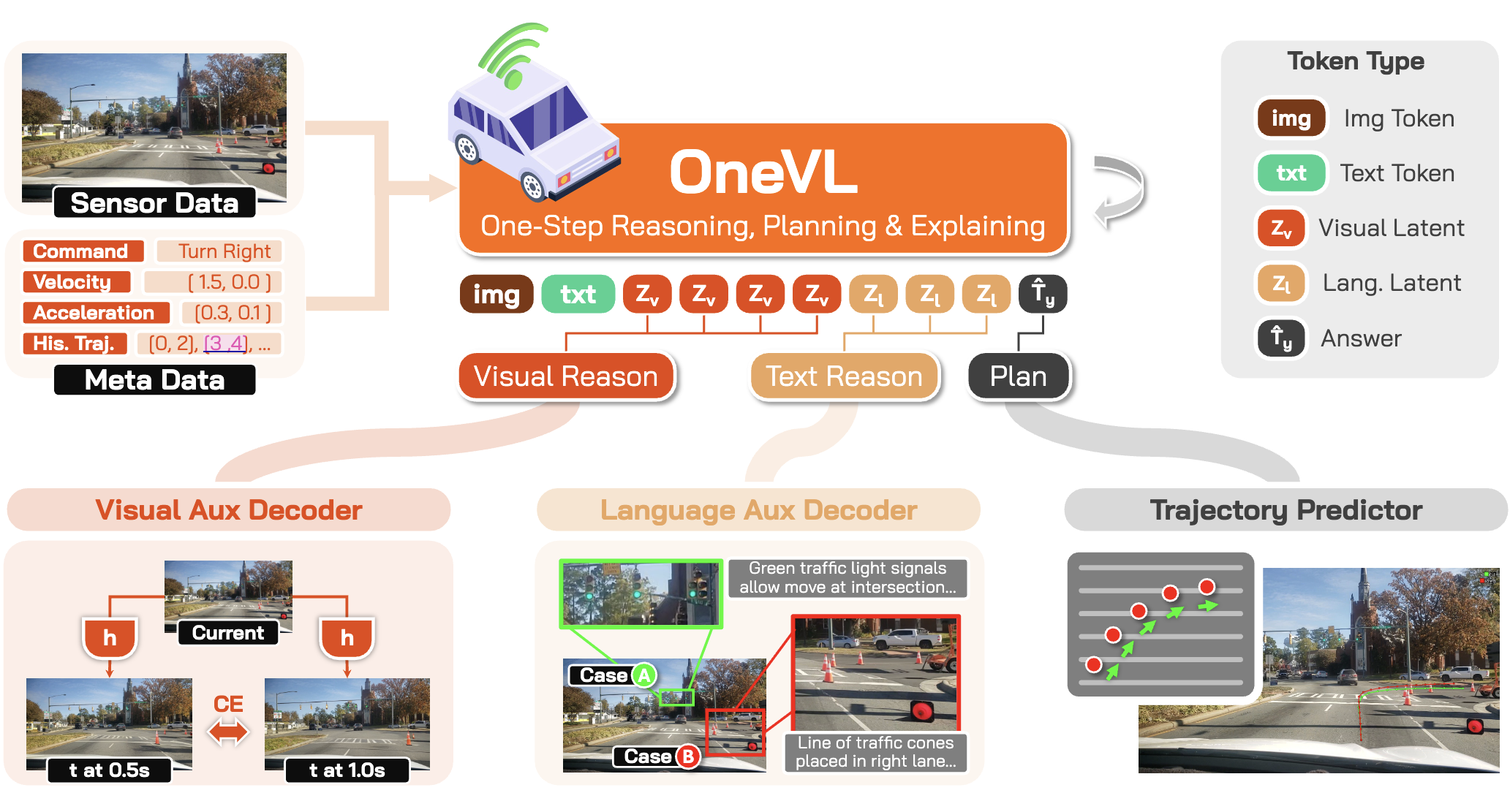
OneVL의 구조는 pretrained VLM 위에 compact latent interface와 두 개의 auxiliary decoder를 얹는 방식으로 요약할 수 있다. 공식 README 기준으로 메인 백본은 Qwen3-VL-4B-Instruct이고, 이 위에 4개의 visual latent token과 2개의 language latent token을 둔다. 중요한 것은 이 latent가 학습 중에 각각 다른 감독 신호를 받는다는 점이다.
- Language Auxiliary Decoder: language latent에서 사람이 읽을 수 있는 CoT 텍스트를 복원한다.
- Visual Auxiliary Decoder: visual latent에서 미래 프레임 토큰을 예측한다. README는 이를
t+0.5s,t+1.0s시점의 visual token prediction으로 설명한다. - Prefill Inference: 추론 시에는 두 decoder를 버리고 latent token만 prompt에 병렬로 prefill해 trajectory만 autoregressive하게 생성한다.
즉 OneVL의 latent는 텍스트 설명을 숨겨놓은 벡터가 아니라, 언어 reasoning + 미래 장면 변화를 함께 압축한 bottleneck이다. 이 점이 기존 latent CoT와 가장 큰 차이다.
훈련도 단계적으로 진행된다. arXiv HTML과 프로젝트 페이지는 이를 three-stage training pipeline으로 설명한다.
- Stage 0: Main Model Warmup — latent token이 포함된 상태로 trajectory prediction을 먼저 학습해 main VLM이 latent routing을 익히게 한다.
- Stage 1: Auxiliary Decoder Warmup — main model을 고정한 채 language/visual auxiliary decoder를 latent 표현에 정렬시킨다.
- Stage 2: Joint End-to-End Fine-tuning — 세 구성요소를 함께 미세조정해 latent bottleneck을 양쪽 decoder의 gradient로 동시에 조인다.
이 staged training은 단순한 학습 요령이 아니라 핵심 구성요소로 보인다. 논문 ablation에서 staged training을 제거하면 NAVSIM PDM-score가 88.84 → 67.13으로 크게 무너진다. 즉 OneVL의 성과는 world-model decoder를 붙였다는 사실만이 아니라, latent를 안정적으로 정렬하는 학습 절차까지 포함한 결과라고 보는 편이 맞다.
| 구성 요소 | 공개 자료에서 확인되는 내용 | 역할 |
|---|---|---|
| Main VLM | Qwen3-VL-4B-Instruct 기반 | scene understanding과 trajectory generation의 중심 백본 |
| Visual latent tokens | 4개 latent token | 미래 장면 변화와 물리적 dynamics 압축 |
| Language latent tokens | 2개 latent token | CoT reasoning 압축 |
| Language auxiliary decoder | text CoT reconstruction | latent를 semantic intent와 연결 |
| Visual auxiliary decoder | t+0.5s, t+1.0s future-frame token prediction |
latent를 world model supervision에 연결 |
| Inference path | auxiliary decoder 제거 후 prefill | answer-only 수준 latency 유지 |
공개된 근거에서 확인되는 점
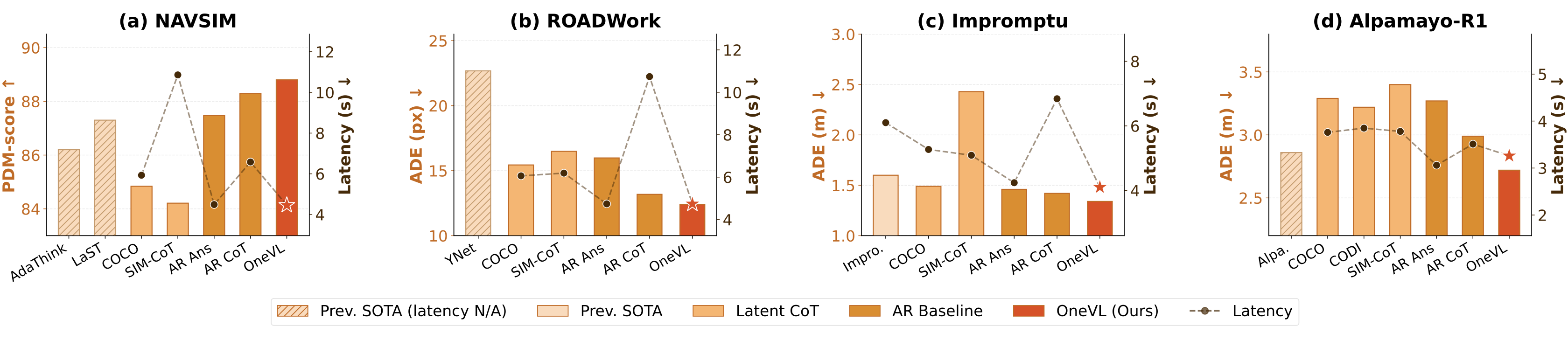
성능 측면에서 OneVL은 최소한 저자들이 설정한 비교 프레임 안에서는 꽤 강한 메시지를 낸다. 프로젝트 페이지와 arXiv HTML에 따르면 OneVL은 NAVSIM, ROADWork, Impromptu, APR1 네 벤치마크에서 기존 latent CoT 방법을 모두 넘고, 여러 경우 explicit CoT까지 앞선다. 특히 NAVSIM에서는 PDM-score 88.84, latency 4.46s로 AR Answer의 4.49s와 사실상 같은 지연에서 AR CoT+Answer의 88.29를 넘는다.
ROADWork에서도 같은 패턴이 보인다. OneVL은 ADE 12.49 / FDE 28.80 / latency 4.71s를 기록해, AR Answer보다 정확하고 AR CoT+Answer보다 훨씬 빠르다. Impromptu에서는 ADE 1.34 / FDE 3.70 / latency 4.02s, APR1에서는 ADE 2.62 / FDE 7.53 / latency 3.26s가 제시된다. 요지는 간단하다. OneVL은 “빠른 latent CoT” 정도가 아니라, 자율주행 VLA에서 latent CoT가 explicit CoT를 처음으로 실질적으로 넘어선 사례로 포지셔닝된다.
| 벤치마크 | OneVL | 비교 포인트 | 해석 |
|---|---|---|---|
| NAVSIM | PDM-score 88.84 / 4.46s | AR Answer 87.47 / 4.49s, AR CoT+Answer 88.29 / 6.58s | explicit CoT급 이상 정확도를 answer-only 지연에서 달성 |
| ROADWork | ADE 12.49 / FDE 28.80 / 4.71s | AR CoT+Answer 13.18 / 29.98 / 10.74s | 공사구간 trajectory 예측에서도 속도-정확도 동시 개선 |
| Impromptu | ADE 1.34 / FDE 3.70 / 4.02s | AR Answer 1.46 / 4.03 / 4.24s | 소형 4B 백본으로 이전 3B/4B 계열 대비 개선 |
| APR1 | ADE 2.62 / FDE 7.53 / 3.26s | AR Answer 3.27 / 9.59 / 3.06s, Cosmos-Reason 2.86 / 7.42 | FDE 최고는 아니지만 overall latent-CoT 경쟁력은 강함 |
설명 품질도 일부 유지된다. NAVSIM text CoT quality 비교에서 OneVL의 language auxiliary decoder 버전은 평균 76.13을 기록해 explicit CoT의 78.27에 근접하며, latency는 4.46s로 더 짧다. 즉 OneVL은 해석 가능성을 완전히 버리지 않고 상당 부분 회수하려는 구조다.
공개 범위도 확인할 필요가 있다. GitHub README 기준 상태는 다음과 같다.
- Technical report: 공개
- Model weights: 공개
- Inference code: 공개
- Training code: coming soon
이 점은 실무적으로 중요하다. 결과를 바로 재현하거나 학습 파이프라인을 그대로 확장하려는 팀에게는 아직 inference 중심 공개에 가깝다. GitHub API 기준으로도 저장소는 2026-04-30 생성, stars 8, forks 0이며, /releases/latest는 404, tags는 비어 있음 상태다. 즉 논문·프로젝트·가중치는 빠르게 공개됐지만, 전통적인 의미의 안정 릴리스 태그나 버저닝은 아직 약하다.
또 하나 눈에 띄는 신호는 Hugging Face 쪽 배포 형태다. paper page와 API 검색 결과를 보면 OneVL_NAVSIM, OneVL_ROADWork, OneVL_Impromptu, OneVL_AlpamayoR1 같은 벤치마크별 모델 가중치가 따로 공개돼 있다. 이는 “범용 단일 체크포인트 하나”보다, benchmark-targeted packaging 성격이 강하다는 뜻으로 읽힌다.
실무 관점에서의 해석
내가 보기에 OneVL의 진짜 의미는 latent CoT 자체보다, latent compression target을 바꿨다는 데 있다. 기존 latent CoT는 주로 reasoning text를 짧은 hidden state로 접는 방향이었다. 하지만 자율주행에서는 reasoning이 텍스트로만 존재하지 않는다. 미래 프레임, agent motion, scene evolution 같은 물리적 구조가 reasoning의 핵심이다. OneVL은 그래서 latent bottleneck을 언어와 world model의 이중 감독으로 묶고, 이 latent가 실제 causal dynamics를 담도록 강제한다.
이 접근은 자율주행 외의 embodied AI에도 꽤 중요한 시사점을 준다. 로봇 제어, 멀티스텝 manipulation, navigation처럼 환경 변화 예측이 필요한 문제에서는, reasoning compression이 단순한 sentence compression이 아니라 state transition compression에 가까워져야 할 가능성이 높다. 그런 의미에서 OneVL은 “자율주행용 VLA 하나 더 나왔다”보다, world-supervised latent reasoning이 실시간 embodied inference의 유력한 경로가 될 수 있다는 신호에 가깝다.
물론 한계도 있다. 첫째, 지금 공개 자료의 강한 성능 서사는 대부분 저자 공식 자료 기반이다. 둘째, training code가 아직 공개되지 않아 full reproduction 관점에서는 미완이다. 셋째, benchmark별 체크포인트 배포 구조는 실제 production adaptation 때 운영 표면이 생각보다 복잡할 수 있음을 암시한다. 넷째, repository release/tag 부재는 아직 패키징 성숙도가 높지 않다는 신호다.
그럼에도 방향성은 꽤 분명하다. OneVL은 explicit CoT와 latent CoT의 단순 속도-정확도 tradeoff를 넘어서, “무엇을 latent에 압축할 것인가”를 다시 묻는다. 그리고 그 답을 언어 설명 + 세계모델 supervision으로 제시한다. 만약 이 아이디어가 다른 embodied domain에서도 재현된다면, 앞으로의 실시간 agent는 긴 설명을 토큰으로 늘어놓기보다, 더 작은 latent 안에 실제 세계의 변화를 압축하는 쪽으로 진화할 가능성이 크다.