비디오 모델링에서 샷 경계 검출은 오래된 문제처럼 보이지만, 실제 제품 파이프라인에서는 여전히 꽤 중요한 병목이다.
긴 원본 영상을 학습용 클립으로 자르거나, 비디오 생성 학습용 연속 구간을 정제하거나, 편집 구조를 이해하려면 어디서 한 샷이 끝나고 다음 샷이 시작되는지 안정적으로 알아야 한다.
그런데 기존 Shot Boundary Detection(SBD) 모델 다수는 단지 경계 프레임을 맞히는 데 집중해, 그 컷이 hard cut인지 dissolve인지, 혹은 겉보기에 비슷하지만 다운스트림에는 치명적인 sudden jump인지까지는 잘 드러내지 못한다.
OmniShotCut은 이 문제를 다시 정의한다.
버지니아대와 UMass Amherst 연구진이 제안한 이 작업은 SBD를 단순한 boundary timestamp 탐지가 아니라, 샷 범위와 함께 intra-shot relation과 inter-shot relation을 공동 예측하는 구조적 비디오 이해 문제로 바꾼다.
여기에 더해 수작업 라벨의 한계를 피하기 위해 fully synthetic transition synthesis pipeline을 만들고, 현대 인터넷 영상 편집 스타일을 반영한 OmniShotCutBench까지 함께 제시한다.
즉 이 논문의 가치는 새 모델 하나보다, 문제 정의·학습 데이터·평가 기준을 한 번에 갈아엎으려는 설계에 더 가깝다.
왜 이 방향이 중요하냐면, 오늘날의 비디오 시스템은 더 이상 TV 방송 컷 분할만 다루지 않기 때문이다.
TikTok, Shorts, Bilibili, 게임 캡처, 튜토리얼, 애니메이션, 스포츠 하이라이트처럼 전환이 복잡하고 편집 스타일이 공격적인 데이터가 늘어났고, 여기서는 “대충 컷을 찾는 것”보다 “무슨 종류의 전환이 일어났는지와 그 연속성이 어떤지”가 훨씬 중요해진다.

무엇을 해결하려는가
OmniShotCut이 겨냥하는 첫 번째 문제는 해석 불가능한 SBD 출력이다.
기존 모델은 대개 특정 프레임 주변에 경계가 있다는 사실만 알려 준다.
하지만 실제 다운스트림에서는 그 경계가 일반 shot split인지, dissolve 같은 transition인지, 아니면 다음 프레임과의 시각적 연속성이 무너진 sudden jump인지가 중요하다.
예를 들어 비디오 생성이나 latent video compression에서는 단순한 컷보다 sudden jump가 훨씬 더 유해할 수 있다.
두 번째 문제는 수작업 라벨의 정밀도 한계다. fade나 dissolve처럼 서서히 바뀌는 전환은 사람이 시작 프레임과 종료 프레임을 정확히 찍기 어렵다.
논문은 이 점을 직접 지적하며, 편집 소프트웨어가 원래 전환을 만드는 주체라면 나중에 사람이 거꾸로 경계를 추정하는 것보다, 전환 효과를 programmatically 재합성하는 편이 더 정확하고 더 큰 규모로 데이터를 만들 수 있다고 본다.
세 번째는 벤치마크의 시대착오성이다.
기존 BBC, RAI, IACC3 같은 데이터셋은 오래된 방송 영상에 치우쳐 있고, 전환 유형의 다양성이나 modern internet editing style을 충분히 반영하지 못한다는 것이 저자들의 주장이다.
결국 OmniShotCut이 푸는 핵심 과제는 단순한 컷 탐지가 아니라, 현대 비디오 파이프라인에 맞는 더 풍부하고 더 진단적인 shot structure understanding이다.
핵심 아이디어 / 구조 / 동작 방식
OmniShotCut의 설계는 크게 세 층으로 읽을 수 있다.
첫째는 관계가 포함된 문제 재정의다.
이 모델은 각 샷에 대해 단순 temporal range만 예측하지 않는다.
대신 샷 내부가 vanilla segment인지 특정 transition인지 나타내는 intra-shot relation, 그리고 이전 샷과의 관계가 hard cut, sudden jump, new-start 등 무엇인지를 나타내는 inter-shot relation까지 함께 예측한다.
즉 출력은 “여기서 잘라라”가 아니라 “어떤 종류의 구조적 단절이 있었는가”에 더 가깝다.
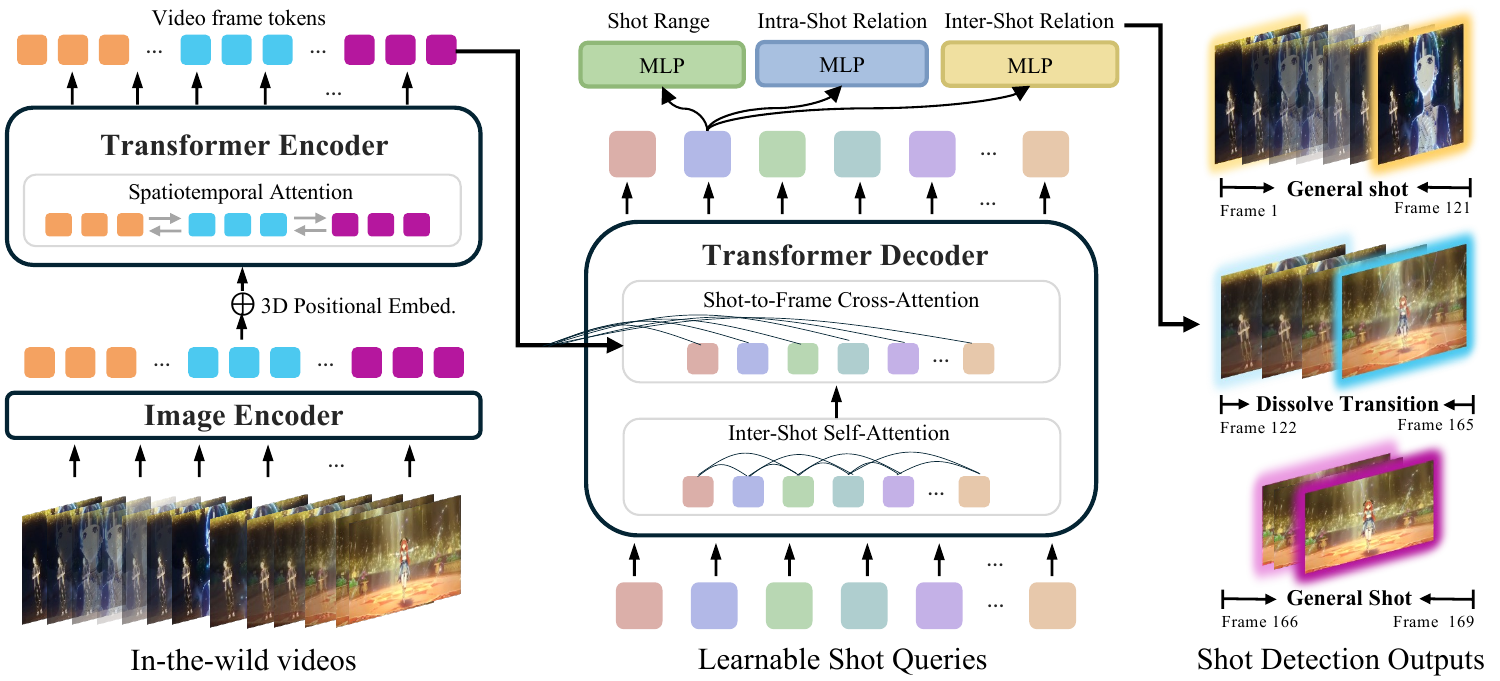
둘째는 shot query-based dense video Transformer다.
논문과 프로젝트 페이지에 따르면 아키텍처는 image encoder, 3D positional embedding을 쓰는 spatiotemporal Transformer encoder, 그리고 Transformer decoder로 구성된다.
여기서 learnable shot query가 샷 예측 슬롯처럼 동작하며, cross-attention을 통해 비디오 토큰에서 shot-specific evidence를 모은다.
최종적으로 range head, intra-relation head, inter-relation head가 동시에 예측을 낸다.
특히 샷 범위 예측을 회귀가 아니라 frame index에 대한 discrete classification으로 다루는 점은 localization precision을 높이려는 선택으로 보인다.
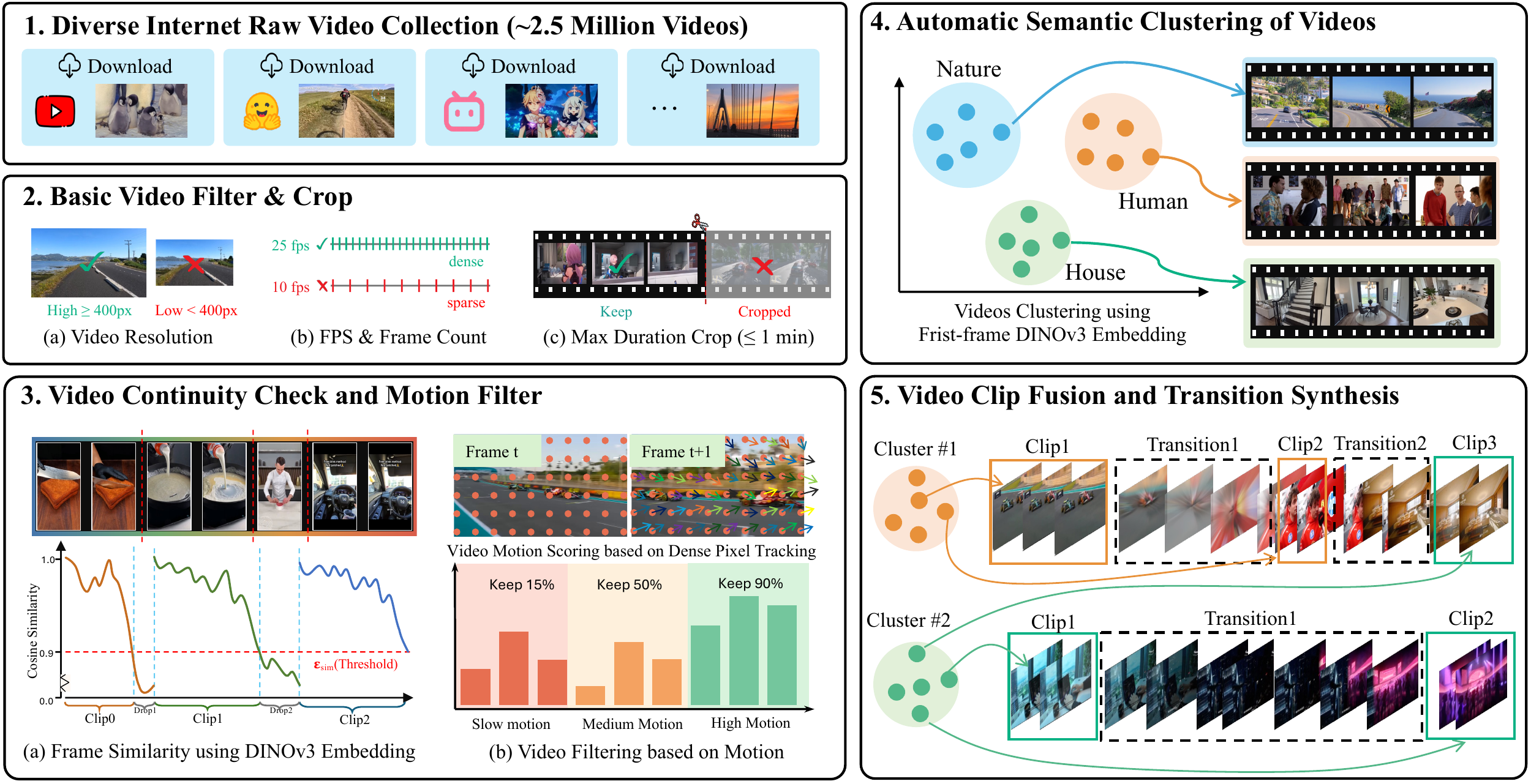
셋째는 합성 데이터 파이프라인이다.
OmniShotCut은 약 250만 개의 raw internet video를 수집한 뒤, 해상도·fps·길이 필터링과 frame-level DINOv3 cosine similarity, dense tracking 기반 motion strength 확인을 거쳐 약 150만 개의 curated clip source를 남긴다.
그 후 SSL 기반 hierarchical K-means로 2만 7천 개 의미 클러스터를 만들고, 같은 클러스터 75%, 다른 클러스터 25%를 섞어 현실적인 전환 문맥을 시뮬레이션한다.
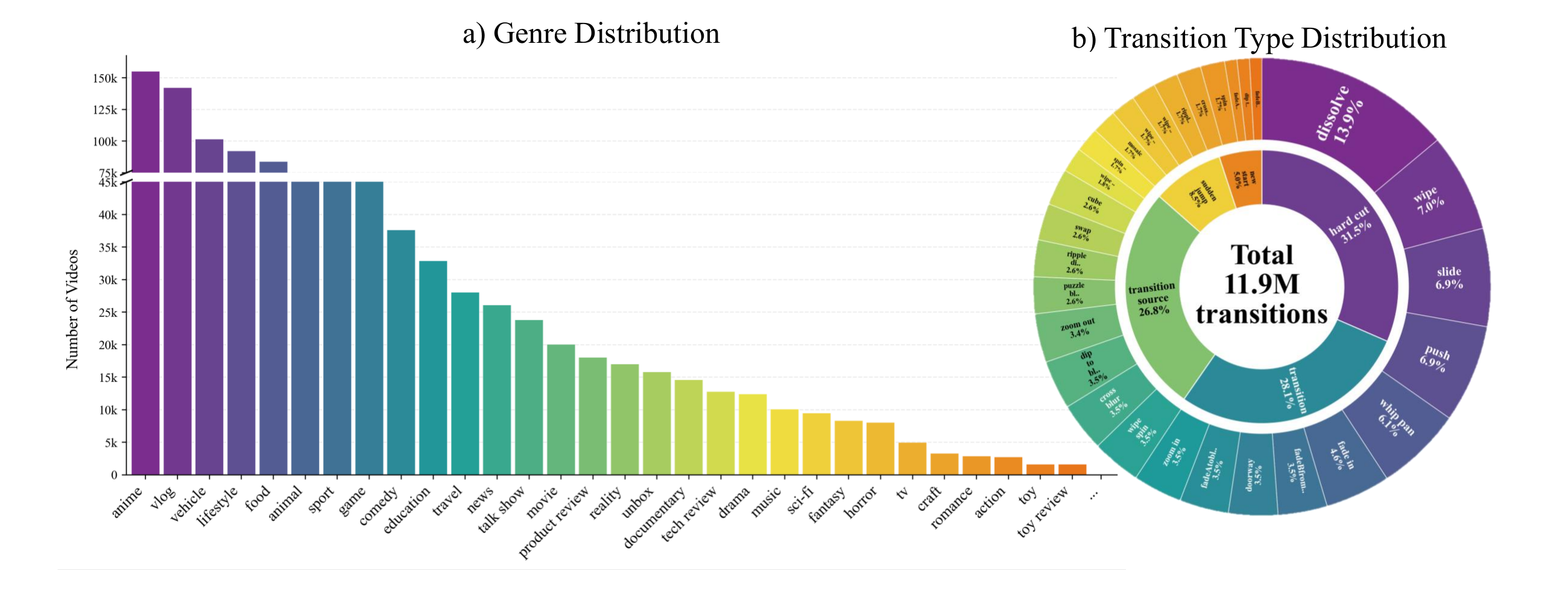
여기에 짧고 촘촘한 hard cut을 추가 배정해 최종적으로 30만 개 학습 비디오와 1,190만 개의 labeled transition을 만든다.
| 구성 축 | 공개 자료에서 확인되는 내용 | 의미 |
|---|---|---|
| 문제 정의 | shot range + intra-shot relation + inter-shot relation | 컷 위치만이 아니라 전환 의미와 연속성까지 모델링 |
| 핵심 아키텍처 | shot query-based dense video Transformer | 하나의 hidden state 위에서 범위와 관계 예측을 공동 최적화 |
| 범위 예측 방식 | frame index discrete classification | 회귀보다 더 정밀한 경계 위치 추정 지향 |
| 학습 데이터 | 합성 전환 데이터 30만 비디오, 1,190만 transition | 대규모·정밀 라벨 확보와 희귀 전환 커버리지 강화 |
| 전환 카탈로그 | 9개 main type, 30개 subtype | dissolve·fade·wipe·slide·doorway·zoom·sudden jump 등 현대 편집 패턴 포괄 |
| 평가 세트 | OmniShotCutBench | 현대 인터넷 영상 기반의 진단형 benchmark 제공 |
공개된 근거에서 확인되는 점
논문 본문 Table 1은 이 접근이 단지 해석 가능성을 위한 설계가 아니라, 기본적인 SBD 성능도 실제로 끌어올렸다고 주장한다.
OmniShotCut은 기존 PySceneDetect, TransNet V2, AutoShot과 비교해 Transition IoU 0.632, Sudden Jump Acc.
0.761, Range Precision 0.898, Range Recall 0.858, Range F1 0.883를 기록한다.
같은 표에서 AutoShot은 Transition IoU 0.252, Sudden Jump Acc.
0.455, Range F1 0.814 수준이므로, 특히 transition localization과 sudden jump detection에서 격차가 크다.
여기에 OmniShotCut만이 Intra Acc.
0.959, Inter Acc.
0.836를 추가로 제시해, 기존 모델이 아예 다루지 못한 관계 예측 축까지 열었다.
프로젝트 페이지가 제시하는 데이터 규모도 눈에 띈다. curated source는 약 150만 개 clip, synthetic corpus는 1,190만 transition, 벤치마크는 YouTube·TikTok·Bilibili 기반 103개 비디오와 약 100분 길이, 480p 30FPS 표준화 구성이다.
이는 단순히 학습 세트만 키운 것이 아니라, 현대 숏폼/인터넷 편집 생태계에 맞춰 벤치마크 표면을 다시 깔았다는 뜻이다.
오픈소스 공개 범위는 꽤 실용적이지만 완전하지는 않다.
GitHub 저장소는 2026-04-24 생성, 조회 시점 기준 stars 140, forks 18, default branch는 main이다.
README는 inference weights와 Gradio demo 공개를 완료했다고 적고 있으며, Hugging Face에는 uva-cv-lab/OmniShotCut 모델과 uva-cv-lab/OmniShotCut Space 데모가 연결돼 있다.
반면 GitHub API 기준 releases와 tags는 비어 있고, README의 업데이트 섹션은 benchmark와 training code/curation은 아직 미공개로 표시한다.
즉 지금 시점의 OmniShotCut은 inference-ready research artifact에는 가깝지만, 전체 데이터/학습 재현 스택까지 다 공개된 상태는 아니다.
라이선스 신호도 약간 갈린다.
GitHub API에서는 저장소 license 필드가 비어 있는 반면, Hugging Face model card frontmatter는 apache-2.0을 명시한다.
사용자는 코드 저장소와 모델 배포물의 라이선스 문맥을 분리해서 확인하는 편이 안전하다.
| 항목 | 확인된 내용 | 해석 |
|---|---|---|
| 본문 Table 1 성능 | Transition IoU 0.632, Sudden Jump Acc. 0.761, Range F1 0.883 | 기존 SBD 대비 transition localization과 sudden jump 검출에서 큰 개선 |
| 관계 예측 축 | Intra Acc. 0.959, Inter Acc. 0.836 | 단순 컷 탐지를 넘어 shot semantics까지 평가 가능 |
| 데이터 규모 | 2.5M raw videos → 1.5M curated clips → 11.9M transitions | 희귀 전환과 다양한 편집 패턴을 대규모 합성으로 커버 |
| 벤치마크 구성 | 103 videos, ~100 minutes, YouTube/TikTok/Bilibili, 480p@30FPS | 현대 인터넷 편집 스타일에 맞춘 진단형 평가 세트 |
| 공개 상태 | inference weights·HF demo 공개, benchmark와 training code는 아직 TODO | 사용은 가능하지만 완전 재현형 오픈소스라고 보긴 이름 |
| 버저닝 신호 | GitHub releases 404, tags 없음 | 빠르게 공개된 연구 코드 단계의 성숙도 신호 |

실무 관점에서의 해석
내가 보기에 OmniShotCut의 핵심은 SBD를 더 잘 푸는 데서 끝나지 않는다.
더 중요한 것은 비디오 파이프라인에서 샷 분할을 단순 전처리 유틸리티가 아니라, 다운스트림을 좌우하는 구조적 이해 계층으로 격상시켰다는 점이다.
비디오 생성, 모션 추적, 비디오 세그멘테이션, latent compression 같은 작업은 모두 나쁜 컷 하나에 민감하다.
OmniShotCut은 특히 sudden jump를 별도 관계 축으로 끌어내며, “경계는 맞췄지만 실제로는 나쁜 분할”인 경우를 더 직접적으로 다루려 한다.
또 하나 흥미로운 점은 synthetic data를 단순한 데이터 증강이 아니라 정밀 라벨링 시스템으로 사용했다는 것이다.
많은 비전 문제에서 합성 데이터는 domain gap 때문에 보조 수단으로 취급된다.
하지만 SBD처럼 편집 효과 자체가 본질적으로 합성 가능한 문제에서는, 오히려 합성이 사람보다 더 정확한 supervisor가 될 수 있다. fade 시작점이나 dissolve 종료점을 사람이 손으로 찍는 것보다, 그 효과를 생성한 파이프라인이 정답을 알고 있는 편이 낫기 때문이다.
OmniShotCut이 설득력 있는 이유도 여기에 있다.
다만 현실적인 제약은 남는다.
첫째, benchmark와 training curation이 아직 완전 공개되지 않았기 때문에 외부 재현성은 부분적으로만 검증 가능하다.
둘째, GitHub의 release/tag 부재는 패키징 성숙도가 아직 낮다는 신호다.
셋째, synthetic transition 중심 학습이 실제 편집 도구의 장기적 변화나 극단적 사용자 편집 스타일까지 얼마나 잘 일반화하는지는 후속 검증이 더 필요하다.
그럼에도 방향성은 분명하다.
앞으로 비디오 파이프라인에서 shot boundary detection은 단순 컷 검출기가 아니라, 전환 의미·연속성·데이터 정제 품질을 함께 책임지는 구조 해석 모듈로 진화할 가능성이 크다.
그런 관점에서 OmniShotCut은 오래된 태스크를 다시 끌어올린 논문이라기보다, 현대 인터넷 비디오 시대에 맞춰 SBD의 문제 정의 자체를 업데이트한 작업으로 보는 편이 더 정확하다.