대규모 모델 학습에서 learning rate는 여전히 가장 비싼 하이퍼파라미터 중 하나다.
작은 모델에서 grid search를 해서 좋은 learning rate를 찾았더라도, width, depth, training tokens가 바뀌면 같은 값이 더 이상 최적이 아닐 수 있다.
문제는 큰 모델에서 다시 sweep하는 비용이 바로 학습 비용 그 자체라는 점이다.
Learning Rate Transfer in Normalized Transformers는 이 문제를 nGPT, 즉 Normalized Transformer 설정에서 다시 본다. nGPT는 weight와 activation norm을 강하게 정규화하고 trainable scale parameter를 붙이는 방식으로, weight decay나 learning-rate warmup 없이 빠른 학습을 보였던 architecture다.
그런데 저자들은 nGPT가 모델 크기에 맞춘 하이퍼파라미터 스케일을 이미 갖고 있음에도, 실제로는 width와 token horizon을 키울 때 learning rate transfer가 잘 되지 않는다고 보고한다.
논문의 핵심 기여는 이 틈을 νGPT라는 새 parameterization으로 메우는 것이다. μP(maximal update parametrization)를 그대로 가져오는 대신, normalized model에서 실제 weight-activation alignment가 어떻게 스케일되는지 측정하고, 그 alignment exponent에 맞춰 learning rate와 scale parameter를 다시 조정한다.
결과적으로 νGPT는 width, depth, token count가 함께 커져도 작은 설정에서 찾은 learning rate를 훨씬 안정적으로 옮길 수 있음을 보인다.
무엇을 해결하려는가
하이퍼파라미터 transfer의 이상적인 그림은 단순하다.
작은 base model에서 learning rate sweep을 한 번 하고, 모델을 넓히거나 깊게 만들거나 training token 수를 늘릴 때는 이 값을 규칙적으로 변환해 쓰고 싶다.
이 목표가 성립하면 큰 모델 학습 전에 비싼 탐색을 반복하지 않아도 된다.
μP는 이런 문제를 다루는 대표적 틀이다. width가 커질 때 feature learning이 사라지지 않도록 initialization과 learning rate를 조정해, 작은 모델에서 찾은 하이퍼파라미터를 큰 모델로 옮기려 한다.
하지만 normalized Transformer는 일반적인 Transformer와 다른 점이 많다. weight matrix와 activation을 계속 normalize하고, attention/MLP 쪽에는 LERP 계열의 trainable scale parameter가 들어가며, weight decay와 warmup도 제거된다.
기존 μP 가정이 그대로 맞는지 확인이 필요하다.
논문은 먼저 부정적 관찰에서 출발한다. original nGPT는 이미 모델 크기에 맞춘 하이퍼파라미터 스케일링을 갖고 있지만, width를 키우거나 compute-optimal token horizon으로 옮기면 최적 learning rate가 일정하게 유지되지 않는다.
즉 “normalized라서 학습이 안정적이다”와 “작은 모델의 learning rate가 큰 모델에도 transfer된다”는 서로 다른 주장이다.
이 논문의 질문은 그래서 꽤 실무적이다. nGPT의 안정성과 속도 이점을 유지하면서, learning rate sweep 비용을 작은 모델 쪽으로 밀어 넣을 수 있는가?
저자들은 답을 alignment exponent 측정에서 찾는다.
핵심 아이디어 / 구조 / 동작 방식
νGPT는 nGPT를 새 architecture로 갈아엎는 제안이라기보다, nGPT를 scale-up할 때 어떤 learning rate와 scale parameter를 써야 하는지 다시 쓰는 parameterization이다.
저자들은 data, width, depth가 base 설정 대비 얼마나 커졌는지를 각각 m_data, m_width, m_depth로 두고, learning rate와 LERP scale 초기값/학습률을 다음처럼 조정한다.
| 조정 축 | νGPT에서의 규칙 | 해석 |
|---|---|---|
| token horizon | global/base learning rate에 m_data^-1/3 적용 |
더 오래 학습할수록 최적 peak LR이 낮아지는 경험적 power law 반영 |
| input embedding | η_input에 m_width^-1/2 적용 |
embedding 쪽 update 크기를 width 증가에 맞춰 보정 |
| hidden/output weights | η_hidden, η_output에 m_width^-3/4 적용 |
full alignment나 no-alignment가 아닌 중간 alignment 가정 반영 |
| LERP scale learning rate | 기존 nGPT의 depth-dependent scaling을 그대로 따르지 않고 상수 계열로 둠 | trainable scale parameter가 normalized model에서 별도 동역학을 갖는다는 관찰 반영 |
| LERP 초기 scale | depth 증가에 더 강한 보정 적용 | 깊은 모델에서 초기 convex-combination scale이 커지는 것을 억제 |
여기서 가장 중요한 수치는 3/4다.
전통적 μP류 사고에서는 특정 alignment 가정이 사실상 learning rate scaling을 결정한다.
하지만 저자들이 νGPT run에서 alignment exponent를 직접 재면, 완전 정렬(full alignment)도 아니고 무정렬(no alignment)도 아닌 중간 상태가 나온다.
특히 α와 ν 계열 exponent는 학습 초반과 후반에 크게 변하지만, loss decrease로 가중해 보면 중간값에 가까워지고, ω_hidden과 ω_output은 1/2이라는 신호가 강하게 나온다.
즉 νGPT는 “μP가 틀렸다”는 단순한 반박이 아니다. normalized Transformer에서는 update와 activation의 정렬 정도가 기존 μP가 암묵적으로 두는 보수적 가정과 다르며, 그 차이를 수치적으로 재서 width scaling을 다시 잡자는 제안에 가깝다.
공개된 근거에서 확인되는 점
실험은 FineWeb-Edu 데이터, sequence length 4096, batch size 64, OLMo 2 tokenizer를 사용해 수행된다. fixed-iteration 실험은 80,000 step, 약 21B tokens에 해당한다.
저자들은 자체 nGPT 구현을 TorchTitan fork 위에서 사용했다고 적지만, arXiv abstract와 HTML 기준으로 별도 공식 GitHub repo나 checkpoint 링크는 보이지 않는다.
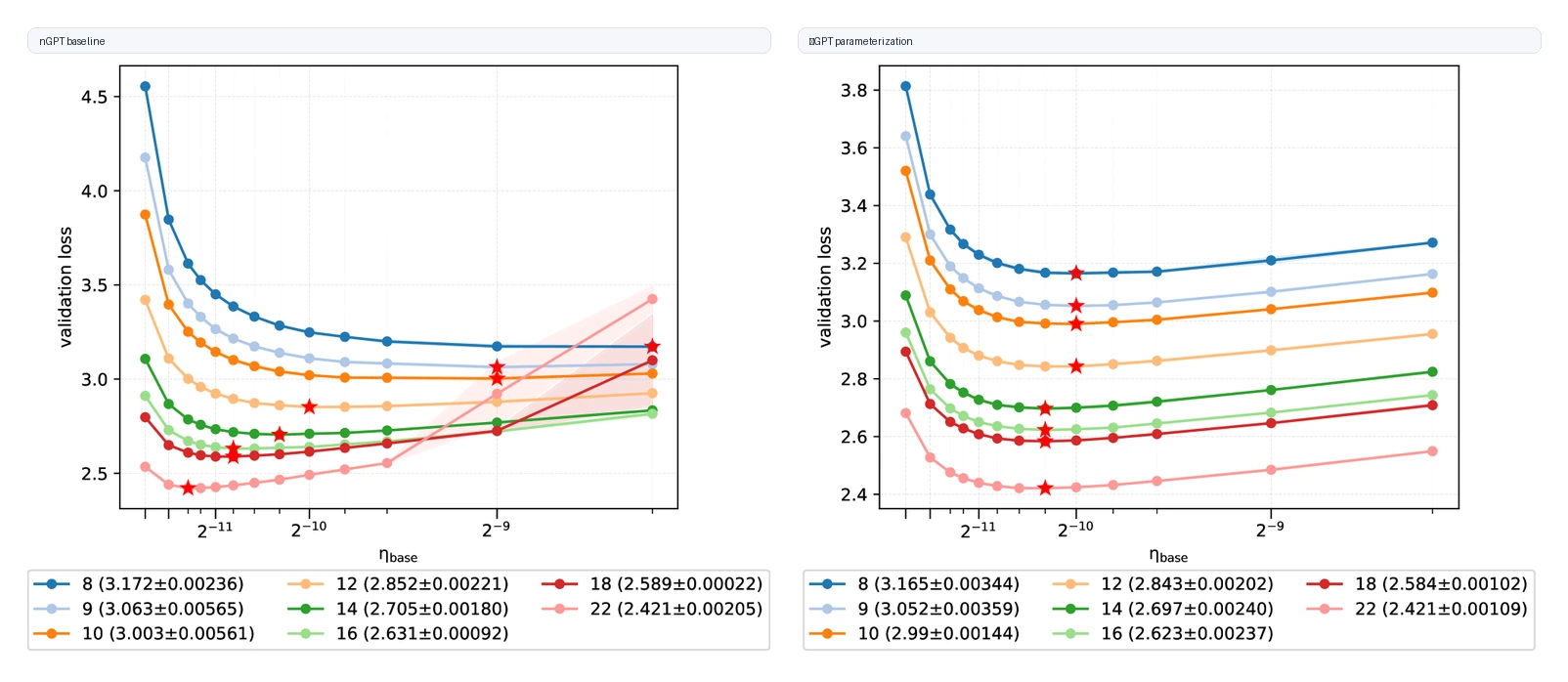
첫 번째 근거는 width transfer다. head dimension과 depth를 고정하고 n_heads를 8에서 40으로 키우면, parameter 수는 약 0.26B에서 3.22B까지 늘어난다. baseline nGPT에서는 validation loss 곡선의 최적 learning rate가 모델 크기별로 움직인다.
반면 νGPT에서는 최적점이 거의 같은 learning rate 근처에 정렬된다.
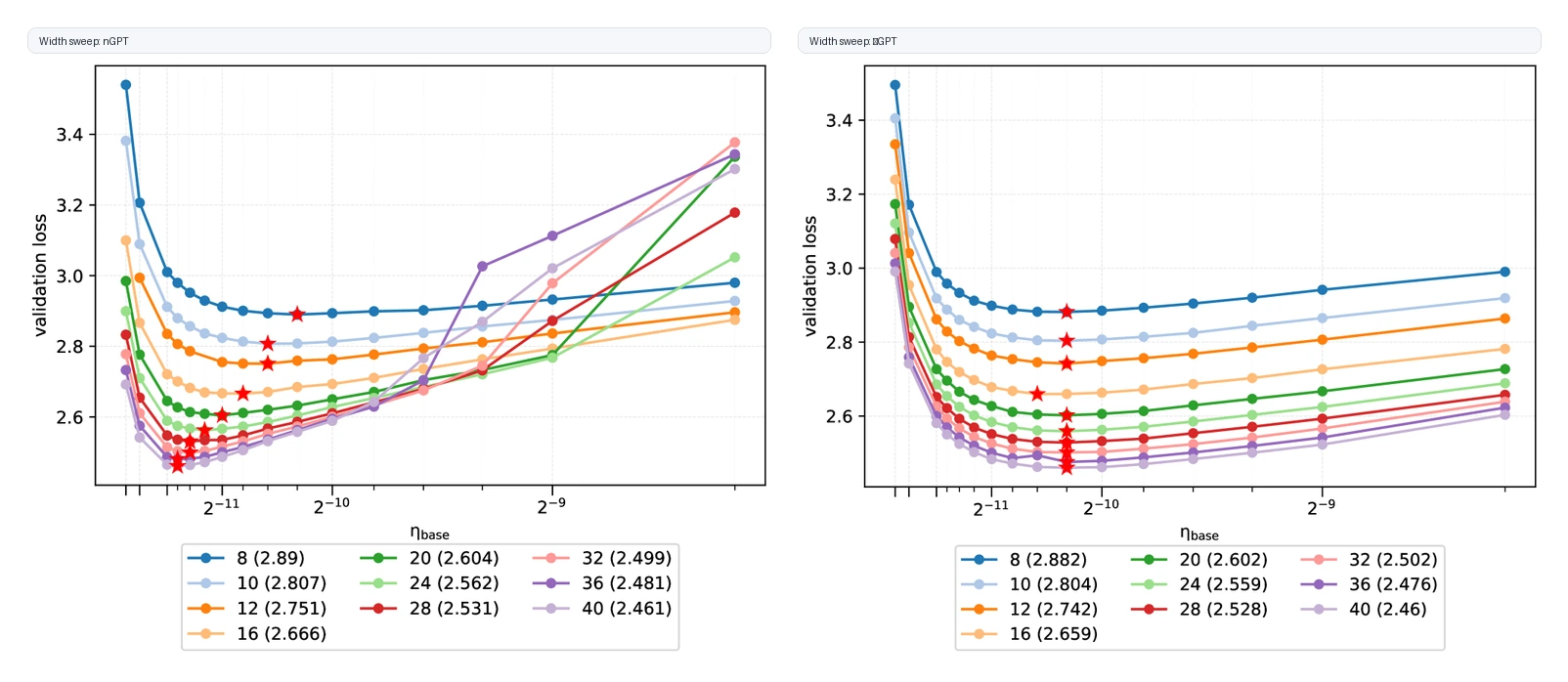
두 번째 근거는 depth transfer다. head dimension 102, n_heads=12를 고정하고 layer 수를 8에서 128까지 늘리면 모델은 약 0.39B에서 2.55B parameter로 커진다.
흥미롭게도 depth만 키우는 경우에는 baseline nGPT도 어느 정도 transfer를 보인다.
다만 가장 깊은 모델에서 불안정성이 커지고, νGPT 쪽이 큰 depth에서 learning rate sensitivity가 낮은 패턴을 보인다.
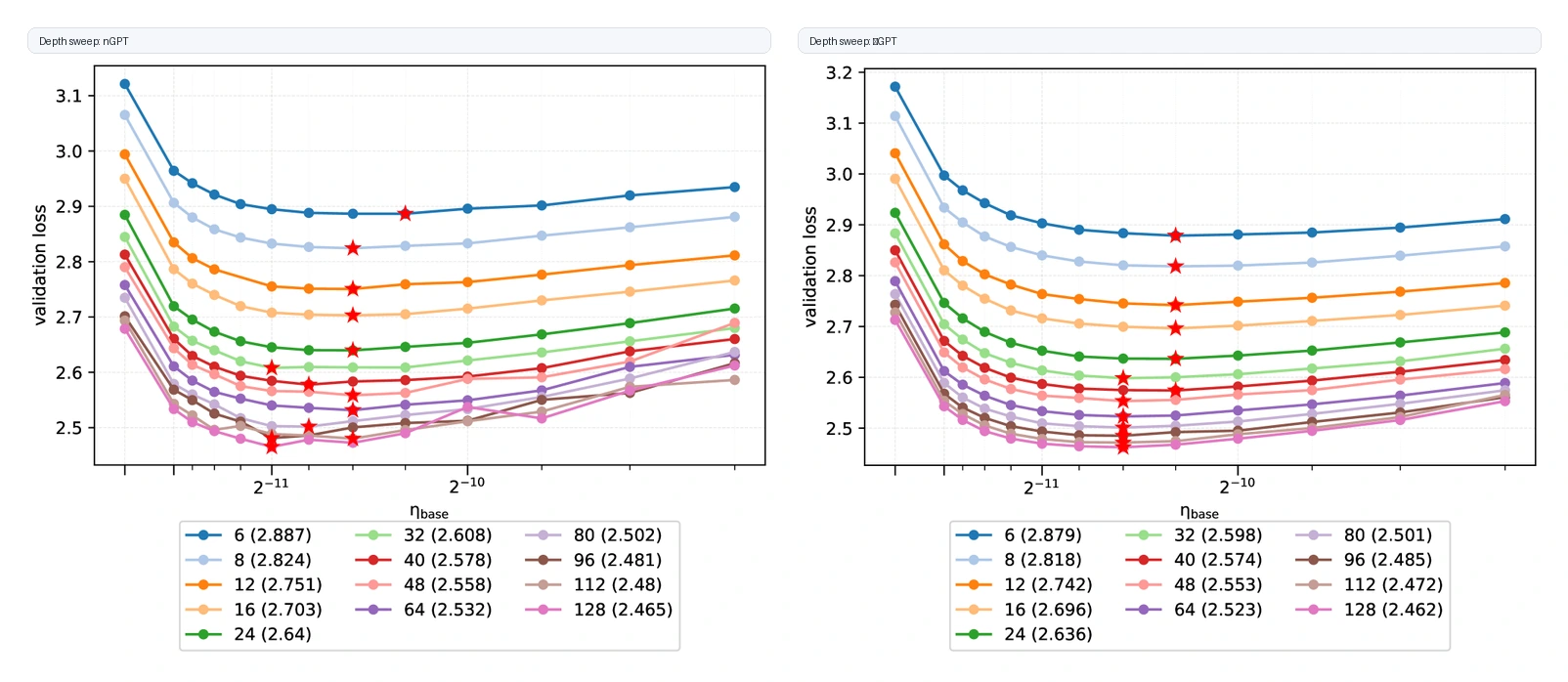
세 번째 근거는 μP-style correction과의 비교다.
논문은 nGPT에 μP-style width correction을 붙인 CompleteP류 설정도 비교한다.
이 설정도 어느 정도 transfer를 하지만, learning rate optimum이 약간 오른쪽으로 drift한다. νGPT는 alignment exponent 측정을 반영해 η_hidden과 η_output의 width exponent를 더 다르게 잡고, width sweep에서 더 잘 정렬된 곡선을 만든다.
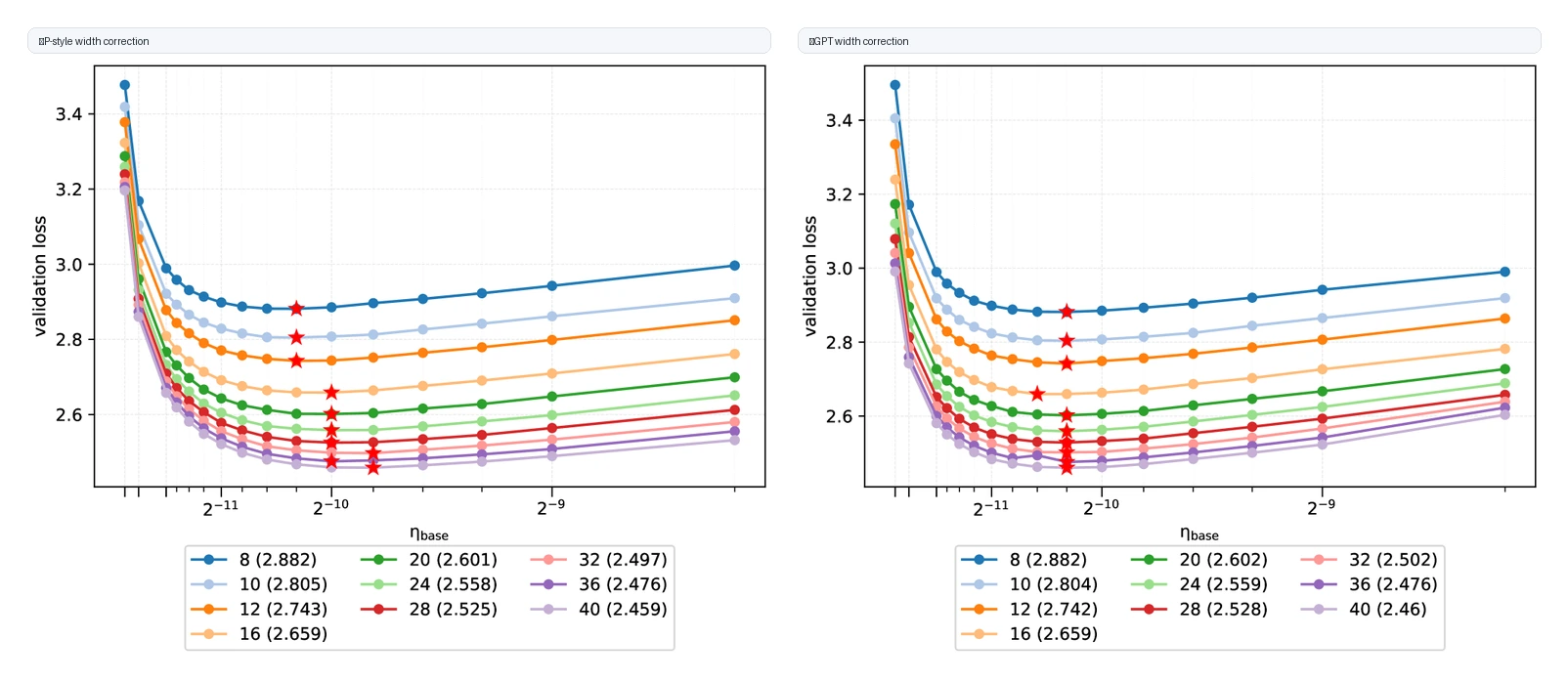
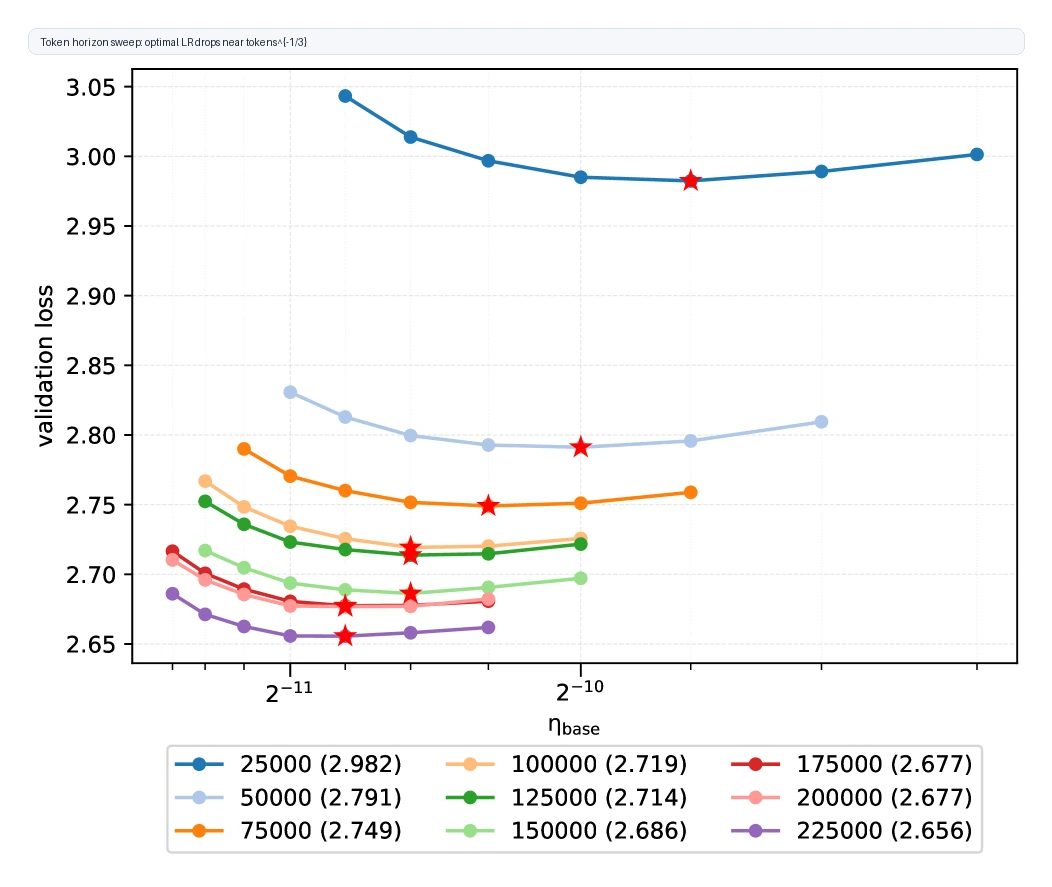
마지막으로 token horizon correction이 있다.
같은 νGPT model에서 token count correction을 제거한 뒤 iteration count를 바꿔 sweep하면, 최적 peak learning rate가 대략 (iteration count)^-1/3로 감소한다.
그래서 νGPT는 m_data^-1/3을 global learning rate에 곱한다.
이는 normalized architecture가 아닌 Transformer에서 보고된 token horizon scaling과도 방향이 맞는다고 논문은 해석한다.
실무 관점에서의 해석
이 논문을 “νGPT라는 새 모델이 나왔다”로 읽으면 핵심을 조금 놓친다.
더 중요한 메시지는 normalized architecture에서도 hyperparameter transfer는 자동으로 생기지 않으며, 실제 update geometry를 측정해 parameterization을 다시 맞춰야 한다는 점이다.
실무적으로는 세 가지 의미가 있다.
첫째, 작은 모델에서 찾은 learning rate를 큰 모델로 옮기는 규칙은 모델 family마다 달라질 수 있다. nGPT처럼 normalization이 강한 구조는 weight decay와 warmup을 없애는 데는 유리하지만, width·depth·token horizon 전체의 transfer 규칙은 별도로 검증해야 한다.
둘째, μP는 여전히 강한 기준선이지만, “한 번 정한 μP recipe를 모든 Transformer-like architecture에 그대로 적용한다”는 접근은 위험할 수 있다.
논문에서 μP-style correction은 완전히 실패하지 않는다.
다만 normalized Transformer의 alignment exponent를 재보면 더 좋은 exponent 선택지가 있고, 그 차이가 큰 sweep 비용을 줄이는 데 의미 있는 차이를 만든다.
셋째, token horizon scaling은 모델 크기 scaling만큼 중요하다.
실제 foundation model training에서는 width나 depth를 키우는 것과 동시에 token budget도 바뀐다. νGPT가 m_data^-1/3을 명시적으로 넣는 것은, learning rate transfer를 model parameter count만의 문제가 아니라 training horizon까지 포함한 compute allocation 문제로 다루게 만든다.
| 관점 | 논문에서 보이는 신호 | 실무적 해석 |
|---|---|---|
| width scaling | nGPT baseline은 n_heads 증가 시 최적 LR이 이동 |
normalized architecture라도 width transfer는 별도 보정이 필요 |
| depth scaling | baseline도 어느 정도 transfer되지만 깊은 모델에서 sensitivity 증가 | depth correction은 유망하지만 architecture-specific 동역학이 큼 |
| μP와의 관계 | μP-style correction은 decent하지만 νGPT가 더 잘 정렬 | μP를 출발점으로 삼되 alignment 측정으로 보정할 여지 |
| token horizon | 최적 LR이 iteration count의 약 -1/3 power로 감소 |
작은-token sweep 결과를 긴 학습으로 옮길 때 data horizon correction이 필요 |
| 공개 아티팩트 | 논문은 TorchTitan fork 구현을 언급하지만 공식 repo 링크는 없음 | 현재는 재현 가능한 release bundle보다 paper-grounded recipe에 가깝다 |
한계도 분명하다. νGPT의 근거는 nGPT, FineWeb-Edu, 특정 optimizer/schedule, 특정 구현과 sweep 범위에 묶여 있다. alignment exponent도 학습 step, layer, token position에 따라 변하고, 논문이 선택한 3/4는 이 복잡한 동역학을 다루기 위한 경험적 중간값이다.
따라서 이것을 모든 normalized model에 바로 꽂는 보편 법칙으로 보기보다는, large-scale training 전에 작은 모델에서 transfer geometry를 측정하고 parameterization을 맞추는 방법론으로 읽는 편이 안전하다.
그래도 방향은 중요하다.
모델이 커질수록 하이퍼파라미터 탐색 비용은 곧 pretraining 비용이 된다. νGPT는 normalized Transformer가 제공하는 안정성을 유지하면서, 작은 sweep을 큰 학습으로 옮기는 더 체계적인 길을 제안한다.
앞으로 nGPT류 architecture가 실제 대형 모델 학습 레시피에 더 들어간다면, 이런 learning-rate transfer 규칙은 architecture 자체만큼이나 중요한 운영 지식이 될 가능성이 크다.