LLM 에이전트 시스템에서 점점 더 중요한 질문은 “어떤 모델이 제일 강한가”가 아니다.
이미 실무 환경에는 GPT, Claude, Gemini, 오픈 모델, 검색, 코드 실행, 사내 도구가 함께 들어온다.
병목은 단일 모델의 순수 추론 능력만이 아니라, 이 서로 다른 지능을 어떤 순서와 역할로 묶을 것인가로 이동한다.
Sakana AI의 **Learning to Orchestrate Agents in Natural Language with the Conductor**는 이 문제를 꽤 직접적으로 다룬다.
논문은 7B Conductor 모델을 reinforcement learning으로 학습해, 문제를 직접 풀기보다 여러 worker LLM에게 줄 자연어 subtask, 모델 선택, 그리고 worker 간 communication topology를 설계하게 만든다.
OpenReview 기준 ICLR 2026 Poster로 공개되어 있고, arXiv v5는 2026년 5월 6일 개정판이다.
핵심은 단순한 router가 아니다.
Conductor는 “이 문제는 GPT-5에게”, “저 문제는 Claude에게”처럼 한 번 고르는 classifier가 아니라, 최대 5단계의 협업 workflow를 생성한다.
쉬운 지식 문제에는 한두 모델만 쓰고, 어려운 coding 문제에는 planner, coder, verifier에 가까운 역할을 여러 모델에 나눠 준다.
Sakana AI 공식 글의 표현을 빌리면, 사람이 하던 prompt engineering과 multi-agent workflow design을 모델이 자연어로 배우게 한 실험이다.

무엇을 해결하려는가
기존 multi-agent 시스템은 대체로 사람이 만든 workflow에 기대 왔다.
예를 들어 “planner가 계획을 세우고, coder가 구현하고, critic이 검토한다” 같은 구조를 사람이 고정하거나, router가 하나의 모델을 선택하거나, Mixture-of-Agents처럼 여러 답을 모아 aggregation한다.
이런 방식은 직관적이지만 두 가지 한계가 있다.
첫째, task별로 필요한 협업 구조가 다르다.
MMLU 같은 비교적 짧은 지식·이해 문제와 LiveCodeBench 같은 코드 생성 문제는 필요한 역할 분해가 완전히 다르다.
모든 문제에 같은 agent topology를 쓰면 쉬운 문제에서는 비용을 낭비하고, 어려운 문제에서는 검증·분해·전문화의 기회를 놓친다.
둘째, 모델별 강점은 고정된 이름만으로 알기 어렵다.
GPT-5가 어떤 benchmark에서는 강하지만, 다른 benchmark에서는 Gemini나 Claude가 더 나을 수 있다.
오픈 모델은 평균적으로 약해 보여도 특정 역할, 예컨대 번역·형식 확인·초기 탐색에는 유용할 수 있다.
결국 실무 시스템에서 중요한 것은 “최강 모델 하나”가 아니라, 주어진 모델 풀에서 각 모델을 언제 어떤 역할로 쓰는 정책이다.
RL Conductor는 이 정책을 사람이 손으로 짜는 대신 학습한다.
논문은 이를 “LLM을 meta-agent로 훈련하는 일”에 가깝게 본다.
Conductor 자체는 최종 답을 직접 쓰는 주인공이 아니라, worker LLM들의 잠재 능력을 끌어내는 지휘자다.
핵심 아이디어 / 구조 / 동작 방식
Conductor가 내는 출력은 자연어 설명만 있는 자유문이 아니다.
논문은 Conductor가 chain-of-thought 뒤에 세 개의 Python list를 내도록 포맷을 정한다.
| 구성요소 | 의미 | 왜 중요한가 |
|---|---|---|
subtasks |
각 worker에게 줄 자연어 instruction | 단순 모델 선택이 아니라 prompt engineering 자체를 학습하게 함 |
model_ids |
각 단계에 배정할 worker model 번호 | GPT-5, Gemini, Claude, 오픈 모델 등 이질적 pool을 선택 |
access_list |
이전 단계 중 어떤 응답을 현재 worker context에 넣을지 | chain, tree, parallel, debate, verifier 구조를 자연스럽게 표현 |
이 구조 덕분에 Conductor는 여러 topology를 만들 수 있다.
한 모델에게 바로 풀게 하는 1-shot, 여러 모델을 독립적으로 부른 뒤 최종 모델이 합치는 tree, planner가 먼저 방향을 잡고 coder가 구현한 뒤 verifier가 검토하는 chain, 또는 이전 응답 일부만 특정 worker에게 보이는 제한적 communication graph가 모두 같은 출력 포맷 안에 들어간다.
학습은 end-to-end RL이다.
논문은 Qwen2.5-7B를 base로 사용하고, MATH500, MMLU, RLPR, LiveCodeBench에서 뽑은 960개 문제로 Conductor를 훈련한다. worker pool에는 GPT-5, Gemini 2.5 Pro, Claude Sonnet 4 같은 closed frontier model과 DeepSeek-R1-Distill-Qwen-32B, Gemma3-27B-it, Qwen3-32B 계열 오픈 모델이 함께 들어간다.
Conductor는 최대 5단계 workflow를 설계할 수 있고, 각 worker는 지정된 subtask와 access list에 따라 이전 응답 일부를 context로 받는다.
보상은 단순하다.
먼저 Conductor 출력에서 세 list를 파싱할 수 없으면 format condition에서 실패한다.
포맷이 맞으면 실제 worker workflow를 실행하고, 최종 답이 정답과 맞는지로 correctness reward를 준다.
논문은 GRPO 계열 학습을 사용하며, 7B Conductor를 2개의 NVIDIA H100 80GB GPU에서 200 iteration 훈련했다고 설명한다.
여기서 중요한 점은 reward가 “좋은 협업 전략을 직접 가르치는” 방식이 아니라는 것이다.
사람이 planner-verifier 구조를 정답으로 라벨링하지 않는다.
최종 답이 맞도록 최적화하는 과정에서, 문제 분해, role assignment, verification, refinement, context sharing 같은 전략이 자연스럽게 나타났다는 것이 논문의 주장이다.
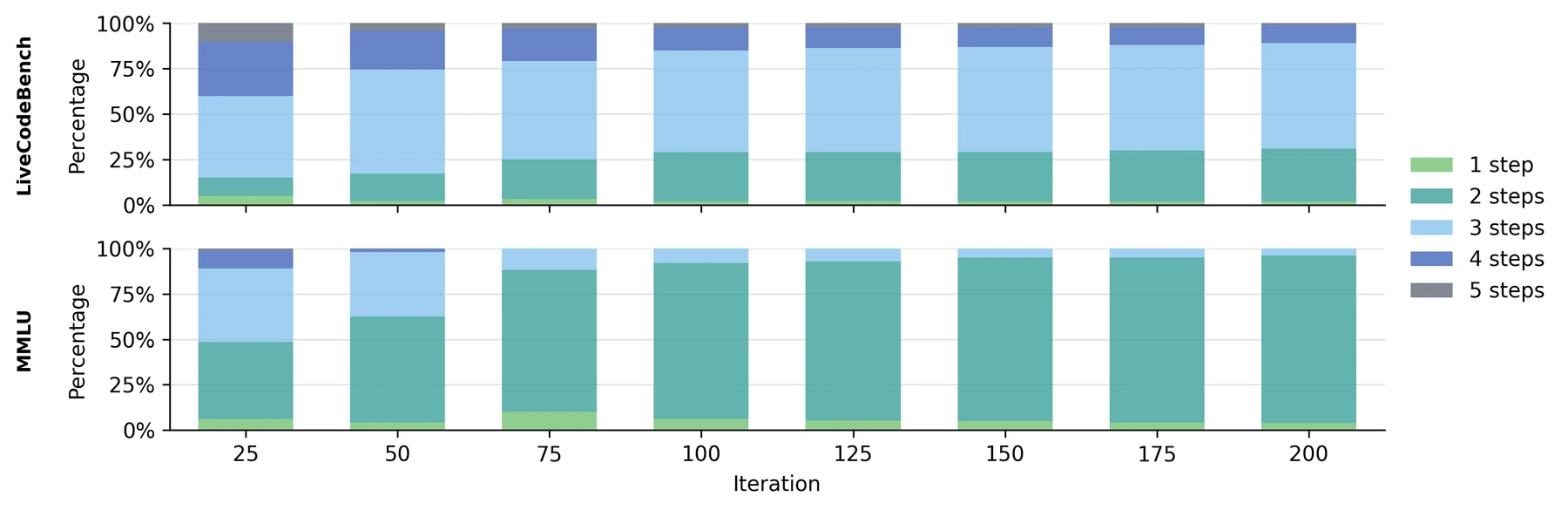
공개된 근거에서 확인되는 점
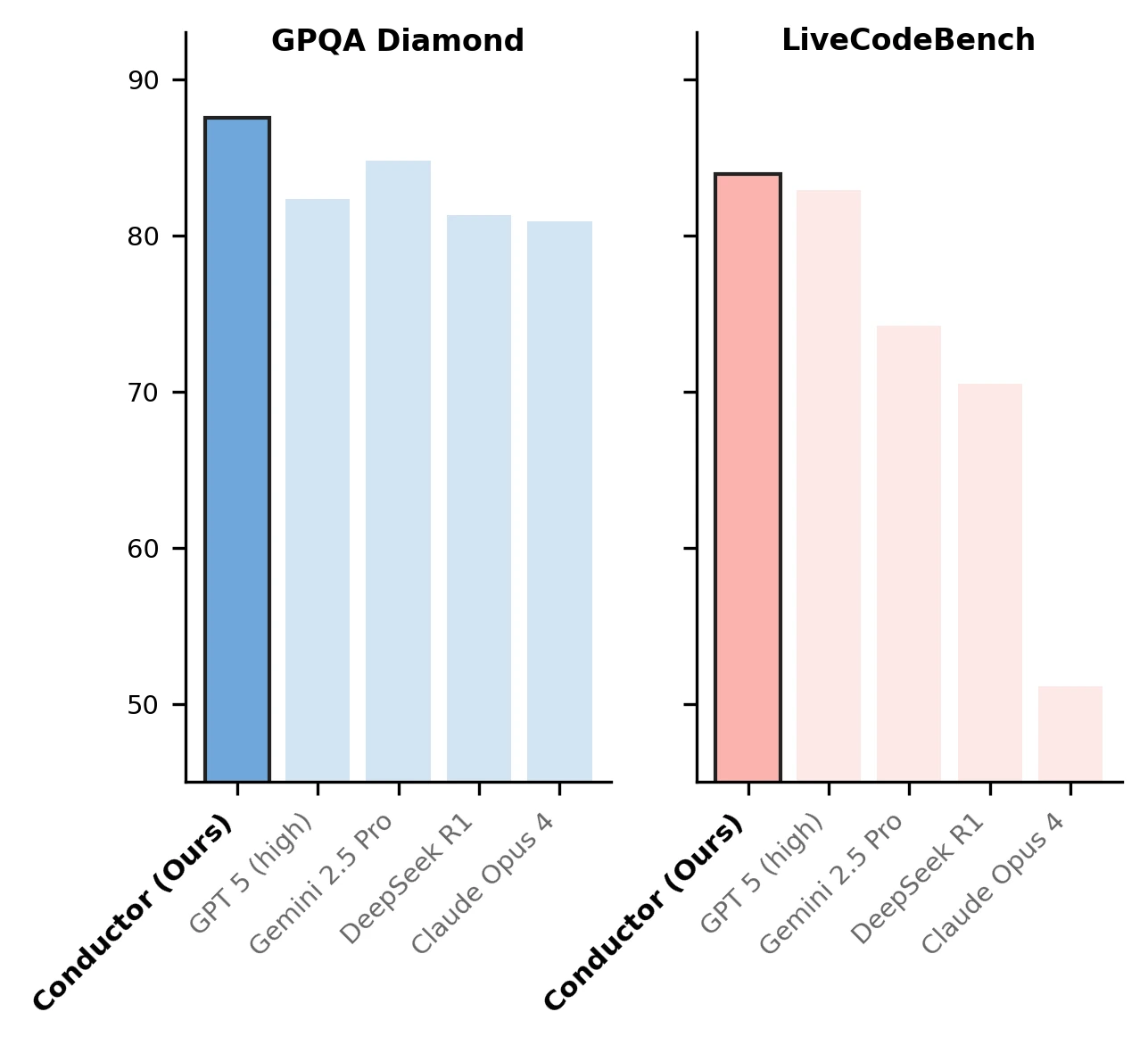
논문과 Sakana AI 공식 글이 가장 강하게 내세우는 수치는 LiveCodeBench와 GPQA-Diamond다. arXiv Table 1의 unconstrained setting에서 Conductor는 평균 77.27점을 기록해 GPT-5의 74.78, Gemini 2.5 Pro의 70.97을 넘는다.
세부적으로는 LiveCodeBench 83.93, GPQA-Diamond 87.5, AIME25 93.3을 보고한다.
핵심 수치를 요약하면 다음과 같다.
| 평가 설정 | 비교 기준 | Conductor 결과 | 읽을 포인트 |
|---|---|---|---|
| Table 1 unconstrained 평균 | GPT-5 74.78, Gemini 2.5 Pro 70.97 | 77.27 | 강한 단일 모델 최고값보다 높은 평균 |
| LiveCodeBench | GPT-5 82.90, Gemini 67.24 | 83.93 | 코드 생성에서 workflow 설계 이득이 가장 잘 드러남 |
| GPQA-Diamond | Gemini 84.8, GPT-5 82.3 | 87.5 | 자연과학 고난도 QA에서도 worker 조합이 이득 |
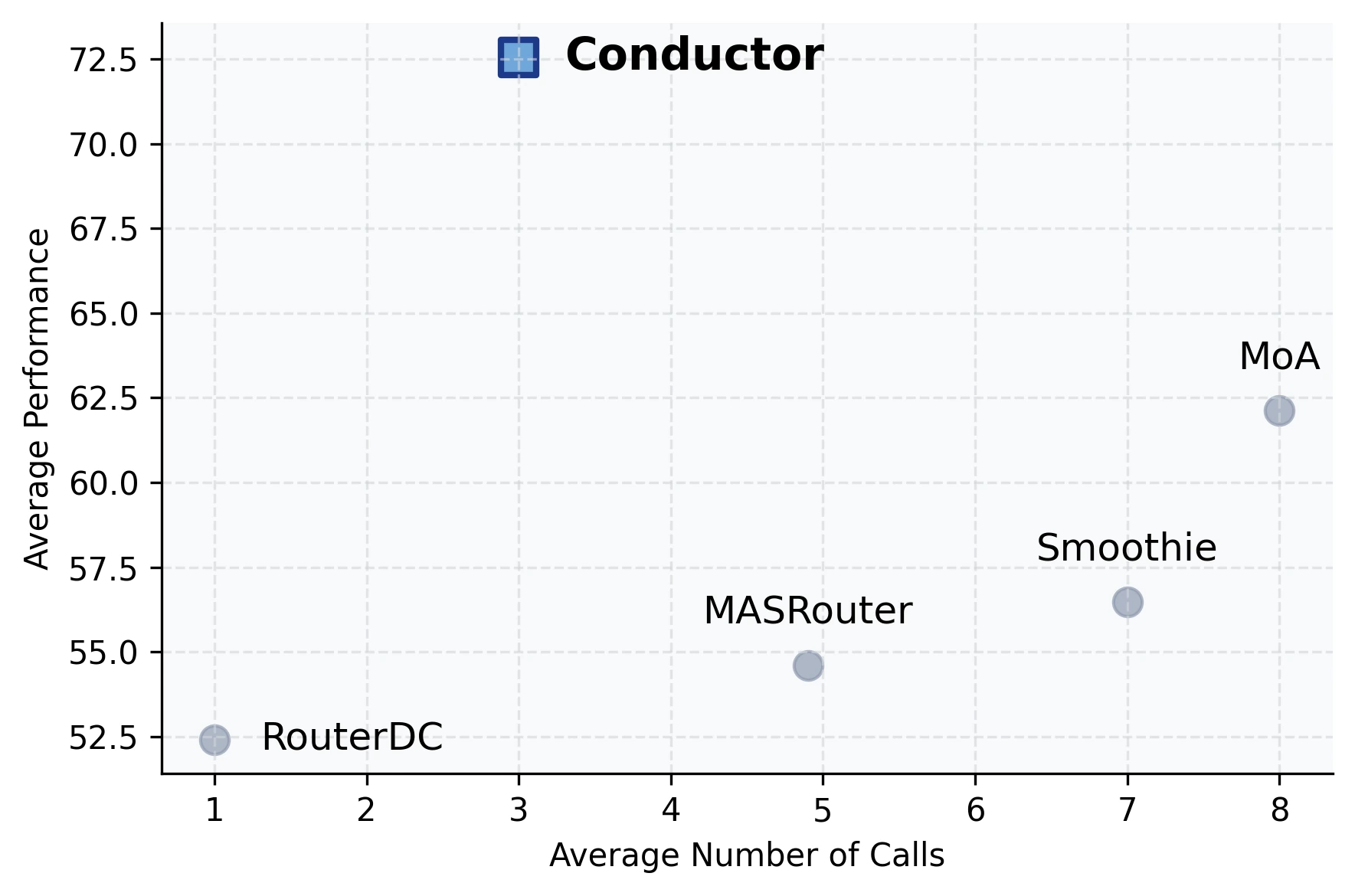
| Table 7 controlled 평균 | MoA 62.13, MASRouter 56.89, Smoothie 56.48 | 72.35 | 같은 worker pool을 둔 multi-agent baseline보다 높음 |
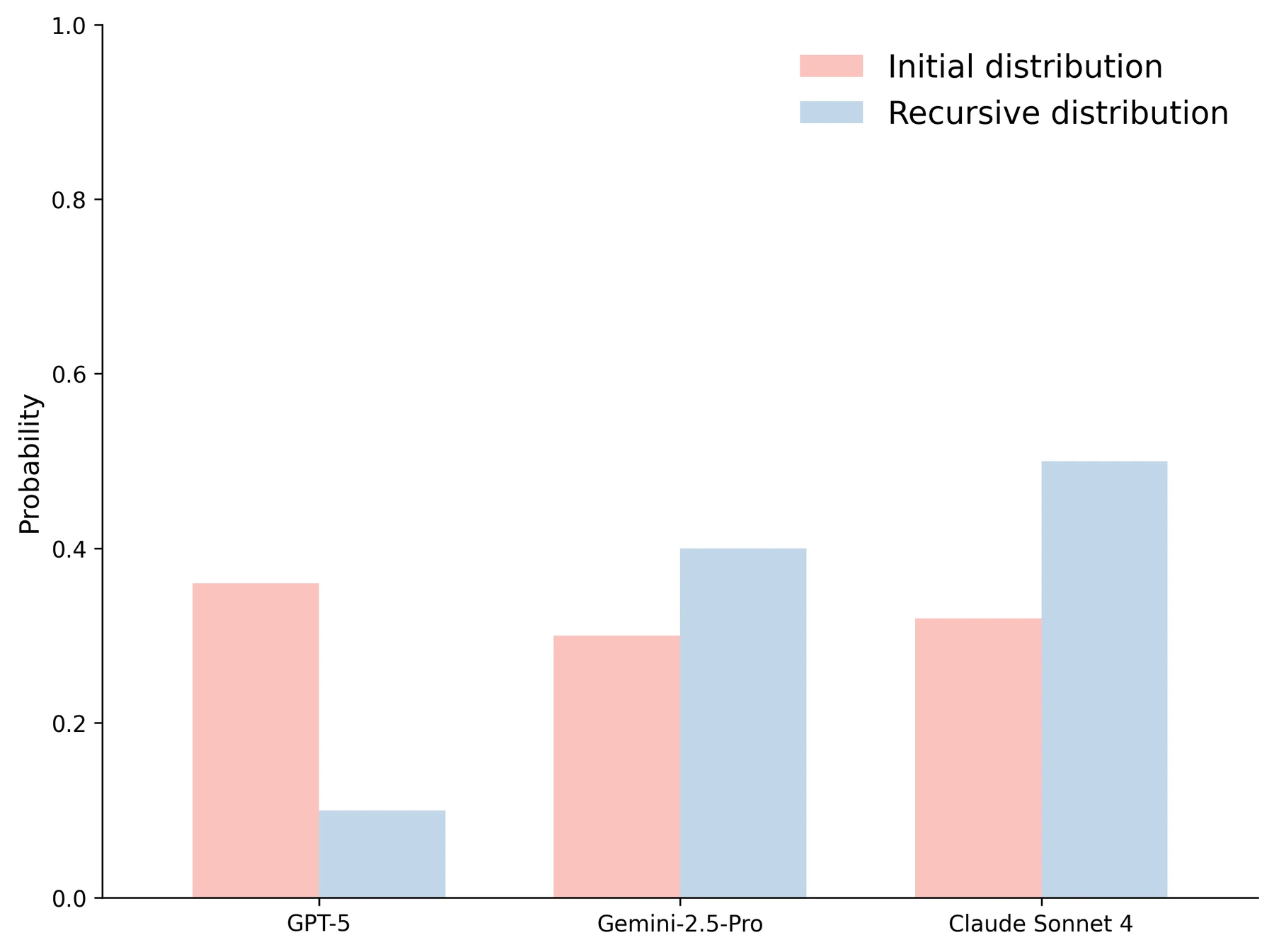
| Table 2 recursive 평균 | 일반 Conductor 61.93 | 63.00 | 자기 자신을 worker로 부르는 recursion이 OOD task에서 추가 이득 |
비용·호출 수 관점도 중요하다.
논문은 controlled large-scale evaluation에서 Conductor가 평균 약 3 step을 사용해, 더 많은 call을 쓰는 multi-agent baseline을 이겼다고 설명한다.
Appendix Table 6 기준 mixed training dataset 평균에서 Conductor는 72.35 performance, 1,820 token usage, cost 0.02384를 기록한다.
MoA는 performance 62.13, token usage 11,203, cost 0.04855다.
RouterDC는 cost가 더 낮지만 performance는 52.41에 머문다.
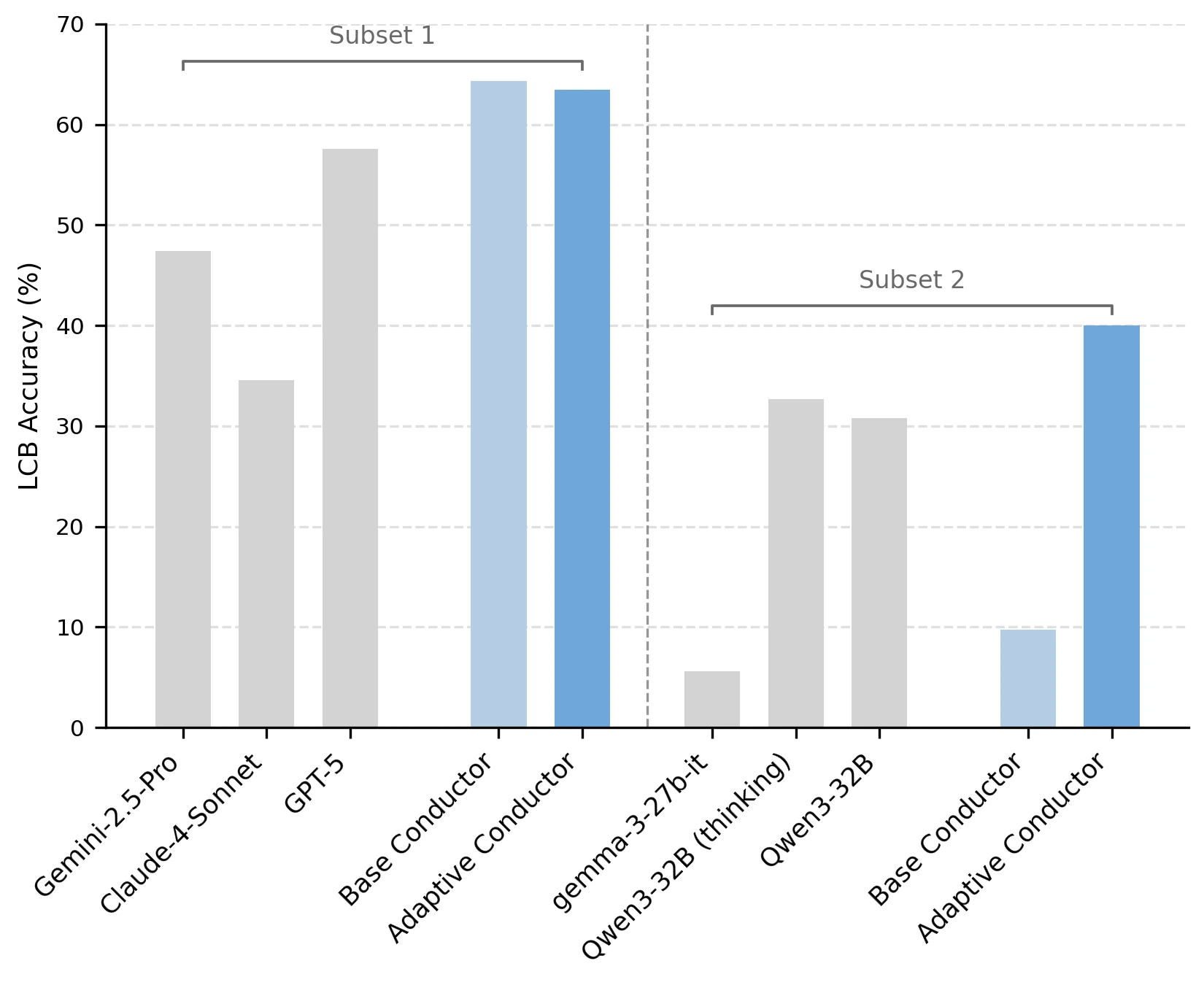
또 하나 눈에 띄는 실험은 adaptive worker selection이다.
논문은 pretrained Conductor를 짧게 finetuning하면서 매 질문마다 가능한 worker subset을 random하게 제한한다.
이 과정을 거치면 사용자가 closed model만 쓰거나 open model만 쓰고 싶어 하는 상황에도 적응할 수 있다는 것이다.
특히 open-only subset에서는 base Conductor가 기존에 잘 쓰지 않던 open model 조합을 제대로 활용하지 못하지만, adaptive Conductor는 훨씬 높은 LiveCodeBench 성능을 회복한다.
recursive topology도 흥미롭다.
Conductor가 자기 자신을 worker로 선택할 수 있게 하면, 처음 만든 workflow의 결과를 다시 보고 corrective workflow를 추가로 설계할 수 있다.
Table 2에서는 BigCodeBench가 37.8에서 40.0으로, GPQA-Diamond가 81.31에서 82.32로 오르며 평균도 61.93에서 63.00으로 오른다.
큰 폭은 아니지만, 모델 크기를 키우는 대신 coordination round를 늘리는 test-time scaling 축을 제시한다는 점이 더 중요하다.
공개 범위도 분명히 짚어야 한다. arXiv, Sakana AI 공식 글, OpenReview 페이지는 논문·공식 설명·심사 메타데이터를 제공하지만, 이 글을 작성하는 시점에 공식 GitHub repository나 Hugging Face checkpoint/model card는 확인되지 않는다.
GitHub와 Hugging Face에서 arXiv ID와 정확한 제목 키워드로 검색해도 명확한 공식 코드·모델 릴리스는 없었다.
따라서 이 작업은 현재로서는 “바로 내려받아 운영할 수 있는 오픈 모델 릴리스”라기보다, 논문과 공식 글로 공개된 연구 결과에 가깝다.
실무 관점에서의 해석
내가 보기에 RL Conductor의 핵심 메시지는 “7B 모델이 GPT-5를 이겼다”가 아니다.
그런 식의 제목은 눈에 띄지만, 실제로는 Conductor가 GPT-5 같은 worker를 호출해 얻은 결과이므로 단일 모델 대 단일 모델 비교로 읽으면 곤란하다.
더 중요한 포인트는 작은 controller가 큰 worker들의 사용법을 학습하면, 전체 시스템 성능이 단일 worker보다 좋아질 수 있다는 점이다.
이 관점은 agent product 설계에 꽤 직접적이다.
많은 팀은 이미 여러 모델을 섞어 쓴다. coding에는 Claude, general reasoning에는 GPT, 긴 문맥에는 Gemini, 비용이 낮은 반복 작업에는 오픈 모델을 쓰는 식이다.
그런데 이 조합은 대개 rule, prompt, routing heuristic, 사람의 경험에 의존한다.
RL Conductor는 그 위에 “모델 사용 정책 자체를 학습 가능한 layer로 둘 수 있다”는 방향을 제안한다.
특히 흥미로운 부분은 access list다.
단순히 여러 모델을 부르는 것보다, 어느 worker가 어떤 이전 응답을 볼 수 있는지 제어하는 것이 실제 협업 구조를 만든다.
모든 응답을 모두에게 보여 주면 context가 낭비되고 bias가 전파될 수 있다.
반대로 필요한 답만 다음 worker에게 넘기면, planner-coder-verifier 또는 독립 시도 후 aggregation 같은 구조를 더 세밀하게 만들 수 있다.
이건 에이전트 시스템에서 retrieval, memory, tool observation을 누구에게 보여 줄 것인가와도 연결된다.
다만 곧바로 production recipe로 받아들이기엔 제약이 크다.
| 제약 | 왜 중요한가 |
|---|---|
| worker pool이 closed frontier model을 포함 | 재현성과 비용이 API 상태, 모델 버전, reasoning budget에 강하게 묶임 |
| 코드·checkpoint 공개가 확인되지 않음 | 외부 연구자가 같은 Conductor를 바로 실행하거나 fine-tune하기 어려움 |
| benchmark 중심 결과 | 실제 장기 workflow, tool permission, 보안, 데이터 경계, 실패 복구까지 검증한 것은 아님 |
| coordination이 더 강해질수록 감사가 어려움 | 어떤 모델이 어떤 context를 봤는지, 어떤 subtask가 최종 답에 영향을 줬는지 추적해야 함 |
| 비용 최적화가 별도 제품 문제로 남음 | 정확도 reward만으로는 실제 API 단가, latency SLO, privacy policy를 자동 반영하기 어렵다 |
그래서 실무적으로는 RL Conductor를 “새로운 agent architecture의 완성본”보다 agent orchestration policy의 연구 방향으로 보는 편이 맞다.
앞으로 여러 모델과 도구를 쓰는 시스템에서는 prompt와 workflow를 사람이 고정하지 않고, 성공 로그와 비용 신호를 바탕으로 controller를 계속 학습시키는 방식이 더 중요해질 가능성이 높다.
Sakana AI 공식 글은 이 연구가 며칠 전 공개한 TRINITY 연구와 함께 새로운 multi-agent system인 Sakana Fugu의 기반이 된다고 설명한다.
즉 논문은 단순 benchmark paper를 넘어, multi-agent product stack에서 “오케스트레이션을 학습한다”는 전략적 방향을 보여준다.
아직 공개 릴리스는 제한적이지만, 에이전트 시스템을 만드는 팀이라면 이 논문을 model leaderboard보다 control plane 설계 논문으로 읽는 것이 더 유익하다.
결론적으로 RL Conductor는 agent 시대의 경쟁력이 어디로 이동하는지 잘 보여준다.
단일 LLM을 더 크게 만드는 경쟁은 계속되겠지만, 실제 제품에서는 여러 모델·도구·데이터 경계를 조율하는 계층이 별도의 지능이 된다.
그리고 그 지능은 단순 router가 아니라, task decomposition, prompt engineering, communication topology, recursive correction을 함께 설계하는 작은 “지휘자”일 수 있다.