작은 LLM 에이전트의 문제를 설명할 때 우리는 보통 모델 크기부터 본다.
8B라서 안 되는가, 33B면 되는가, 아니면 GPT-4o나 Claude급 frontier model이 필요할까. **Three Roles, One Model**은 이 질문을 조금 다르게 놓는다.
같은 8B 모델이라도, 한 번에 모든 것을 하게 만들지 않고 역할을 나눠 호출하면 얼마나 달라질까?
논문이 다루는 환경은 AppWorld다.
AppWorld는 9개 앱과 457개 API endpoint로 구성된 현실적인 소프트웨어 작업 벤치마크이며, 에이전트는 인증 토큰, API schema, 중간 응답, 오류 복구, 긴 상호작용 이력을 다뤄야 한다.
저자들은 단일 24GB GPU라는 제약 아래 Qwen3-8B를 평가하고, 추가 학습 없이 inference-time scaffolding만으로 작은 모델의 agent 성능을 끌어올릴 수 있는지 실험한다.
핵심 결과는 단순하지만 흥미롭다. raw Qwen3-8B는 AppWorld test_normal에서 FP16 5.4%, 4-bit AWQ 3.0% task goal completion에 머문다.
그런데 같은 frozen weights를 요약기, 메인 에이전트, 독립 교정기 세 역할로 나눠 쓰면 FP16은 8.9%, AWQ는 5.9%까지 오른다.
절대 수치로는 여전히 낮지만, 작은 모델의 실패 중 상당 부분이 순수 추론 부족이 아니라 인증·API schema·context 관리 같은 기계적 실패에서 온다는 점을 보여준다.
무엇을 해결하려는가
논문의 문제의식은 “작은 모델은 AppWorld를 못 푼다”에서 멈추지 않는다.
왜 못 푸는지를 trajectory 단위로 보면, 실패는 종종 고차원 추론 부족보다 훨씬 운영적인 곳에서 시작된다.
저자들은 baseline 실패를 GPT-4o evaluator로 분류했다.
FP16 baseline의 163개 실패에서 가장 큰 세 범주는 다음과 같다.
| 실패 범주 | Count | Confidence-weighted |
|---|---|---|
| Authentication / credential issue | 46 | 39.45 |
| Reasoning / planning error | 43 | 35.30 |
| Wrong API params / schema mismatch | 29 | 25.05 |
| Other | 24 | 20.05 |
| Missing API call / wrong API name | 13 | 11.45 |
이 분포가 중요한 이유는 실패들이 서로 독립적이지 않기 때문이다.
논문은 많은 trajectory에서 모델이 API 문서를 먼저 확인하지 않고 endpoint를 호출하고, parameter 이름이나 타입을 틀리고, 오류 응답을 받은 뒤에도 문서를 보지 않은 채 trial-and-error로 맞추려 한다고 설명한다.
그 과정에서 turn과 context budget을 쓰고, 이미 얻은 authentication token을 잃어버리며, 다시 credential을 추출하는 반복 루프에 빠진다.
즉 AppWorld에서 작은 모델은 “정답 계획을 못 세워서”만 실패하는 것이 아니다.
문서 확인, schema 준수, state 보존, 오류 후 루프 탈출 같은 런타임 운영 능력이 약해서 실패한다.
이 논문은 그 부분을 모델 학습이 아니라 inference pipeline 설계로 보완하려 한다.
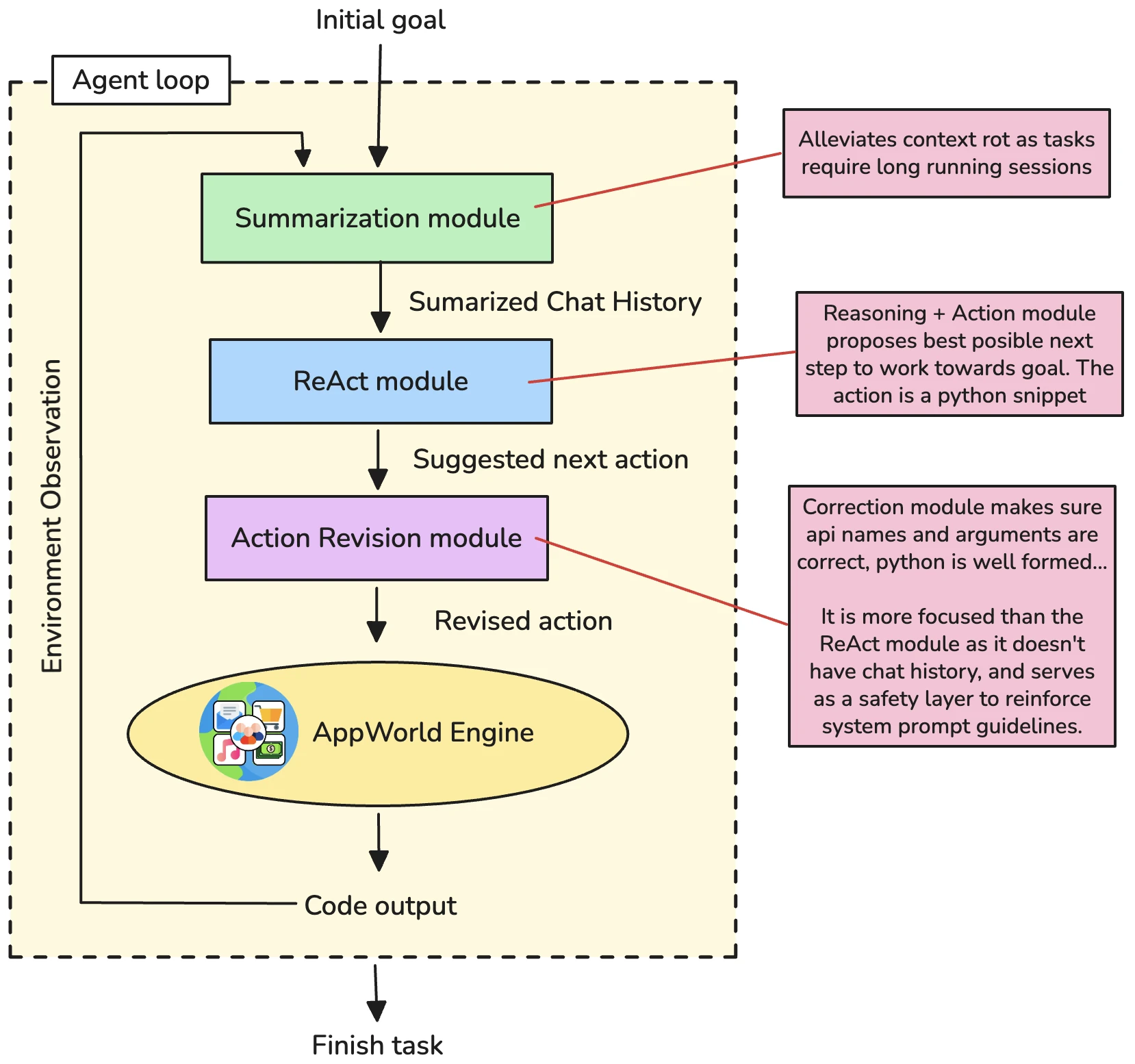
핵심 아이디어 / 구조 / 동작 방식
논문은 AppWorld agent task를 POMDP로 두고, frozen LLM policy πθ를 직접 학습하지 않는다.
대신 같은 모델을 서로 다른 conditioning과 관찰 범위로 세 번 호출해 scaffolded policy πscaf를 만든다.
한 turn의 흐름은 다음과 같다.
AppWorld observation
→ summarization model: history compression + critical artifact preservation
→ main agent model: compressed context에서 Python API-call action 생성
→ correction model: action과 API docs/error feedback만 보고 제출 전 수정
→ AppWorld execution
세 역할은 같은 Qwen3-8B weights를 사용하지만, 입력과 책임이 다르다.
| 역할 | 입력/관찰 범위 | 해결하려는 실패 |
|---|---|---|
| Main Agent | 현재 observation + 요약된 history | ReAct-style로 다음 Python code/API call 생성 |
| Summarization Model | 긴 대화 이력, 이전 artifact | context truncation으로 token, credential, API response, pagination state를 잃는 문제 |
| Correction Model | 제안된 action, 실행 feedback, 관련 API documentation | 잘못된 argument, schema mismatch, 반복적 code repair loop |
요약기는 history가 24,000 characters 또는 6,000 tokens를 넘으면 작동한다.
첫 26개 메시지와 마지막 6개 메시지는 그대로 유지하고, 중간 이력을 압축하되 authentication token, API output, error pattern, pagination state, task status indicator 같은 critical artifact는 verbatim으로 보존하도록 요구한다.
교정기는 더 흥미롭다.
이 모델은 전체 대화 이력을 보지 않는다.
메인 에이전트가 만든 action, 실행 오류, 관련 API documentation만 본다.
이 제한은 일부러 둔 것이다. baseline agent가 잘못된 trajectory history에 끌려가며 같은 수정을 반복하는 문제를 끊기 위해, correction model을 history-noise에서 격리된 reviewer로 만든다.
이 구조는 “self-correction을 한 번 더 시킨다”보다 구체적이다.
요약기는 부분 관측성을 줄이고, 메인 에이전트는 계획과 action 생성을 담당하며, 교정기는 action-space shaping처럼 실행 전 유효하지 않은 호출을 줄인다.
같은 모델을 세 번 부르지만, 각각이 보는 state와 최적화 대상이 다르다.
공개된 근거에서 확인되는 점
실험은 Qwen3-8B를 단일 NVIDIA 24GB VRAM GPU에서 돌리는 설정이다.
두 구성이 비교된다.
- FP16: vLLM, 12K context,
max_num_seqs=4,gpu_memory_utilization=0.95 - AWQ 4-bit: 32,768-token context를 유지하기 위한 quantized configuration
- 공통: greedy decoding,
temperature=0, fixed random seed 100, max 3,000 completion tokens, AppWorldtest_normal, pass@1 single trial
주요 결과는 Table 3에 정리되어 있다.
| Difficulty | FP16 Baseline | FP16 Scaffold | AWQ Baseline | AWQ Scaffold |
|---|---|---|---|---|
| Aggregate | 5.4 [2.8, 9.9] | 8.9 [5.5, 14.2] | 3.0 [1.3, 6.8] | 5.9 [3.3, 10.6] |
| Difficulty 1 | 15.8 | 26.3 | 5.3 | 14.0 |
| Difficulty 2 | 0.0 | 0.0 | 2.1 | 4.2 |
| Difficulty 3 | 0.0 | 0.0 | 1.6 | 0.0 |
가장 큰 개선은 difficulty-1에서 나온다.
FP16은 15.8%에서 26.3%로, AWQ는 5.3%에서 14.0%로 오른다.
난도가 낮은 작업일수록 schema mismatch나 단발성 코드 수정처럼 correction model이 처리할 수 있는 실패가 많기 때문이다.
동시에 한계도 선명하다. difficulty-3에서는 scaffolding이 거의 효과가 없거나, AWQ에서는 1.6%에서 0.0%로 내려간다. history를 일부러 보지 않는 correction model이 긴 의존성이 필요한 작업에서는 placeholder token이나 user id를 hallucinate할 수 있기 때문이다.
논문은 이를 robustness와 state awareness 사이의 trade-off로 해석한다.
더 큰 모델과의 비교도 제시된다.
| Model | Parameters | AppWorld test_normal task goal completion |
|---|---|---|
| GPT-4o | — | 48.8 |
| Claude 3.5 Sonnet | — | 33.2 |
| LLaMA-3-70B-Instruct | 70B | 20.8 |
| Qwen3-8B + Scaffold (FP16) | 8B | 8.9 [5.5, 14.2] |
| DeepSeek-Coder 33B Instruct | 33B | 7.1 [4.1, 12.0] |
| Qwen3-8B Baseline (FP16) | 8B | 5.4 [2.8, 9.9] |
| Qwen3-8B + Scaffold (AWQ) | 8B | 5.9 [3.3, 10.6] |
| Qwen3-8B Baseline (AWQ) | 8B | 3.0 [1.3, 6.8] |
여기서 조심할 점이 있다.
논문은 scaffolded 8B FP16이 DeepSeek-Coder 33B Instruct의 7.1%를 수치상 넘는다고 말하지만, 95% confidence interval 기준으로 통계적으로 유의한 차이는 아니라고 명시한다.
따라서 “8B가 33B를 이겼다”보다는 “작은 모델의 일부 기계적 실패를 scaffolding으로 줄이면 33B급 약한 baseline에 근접하거나 넘어서는 구간이 있다” 정도가 정확하다.
ablation도 구조를 이해하는 데 중요하다.
AWQ 32K context에서 correction node만 켜면 aggregate가 3.0%에서 4.8%로 오르고, full scaffold는 5.9%까지 간다.
| Difficulty | Baseline | Correction Only | Full Scaffold |
|---|---|---|---|
| Aggregate | 3.0 | 4.8 | 5.9 |
| Difficulty 1 | 5.3 | 12.3 | 14.0 |
| Difficulty 2 | 2.1 | 2.1 | 4.2 |
| Difficulty 3 | 1.6 | 0.0 | 0.0 |
이 표는 교정기가 가장 큰 단기 개선을 만들고, 요약기는 difficulty-2처럼 조금 더 긴 상태 보존이 필요한 작업에서 추가 이득을 준다는 해석을 가능하게 한다.
반대로 difficulty-3에서는 history isolation이 오히려 손해가 될 수 있다.
마지막으로 재현성 측면의 caveat가 있다. paper의 Data Availability는 inference scaffolding pipeline code가 https://github.com/Aimpoint-Digital/appworld-agent에 있다고 적는다.
하지만 글 작성 시점에 GitHub REST API와 브라우저형 HEAD 요청 모두 이 repository를 public하게 확인하지 못했고 404를 반환했다.
따라서 이 글은 arXiv HTML/PDF와 paper 안의 표·그림에 근거한 분석이며, 공개 GitHub code release의 패키징·라이선스·실행 절차는 별도로 검증하지 못했다.
실무 관점에서의 해석
내가 보기에 이 논문의 가장 좋은 포인트는 “작은 모델도 역할을 잘 나누면 좋아진다”가 아니라, 에이전트 실패를 먼저 분류한 뒤 그 실패에 맞는 런타임 구조를 설계했다는 점이다.
인증 토큰을 잃는다면 context 요약기가 artifact를 보존해야 하고, API schema mismatch가 반복된다면 action 제출 전 문서 기반 교정기가 있어야 하며, 반복 루프가 문제라면 교정기를 history에서 격리해야 한다.
이건 agent product를 만드는 팀에게 꽤 실용적인 메시지다.
모델을 바꾸기 전에 trajectory log를 보고 실패를 다음처럼 나눠볼 수 있다.
| 관찰되는 실패 | 모델 교체 전 점검할 runtime 개입 |
|---|---|
| token, session id, API response를 잃어버림 | artifact-aware summarization, structured memory, state slot 보존 |
| API argument 이름·타입을 반복해서 틀림 | docs retrieval, schema validator, pre-execution correction |
| 같은 수정 시도를 반복함 | isolated reviewer, loop detector, action history monitor |
| 난도 높은 multi-step plan 자체가 틀림 | 더 강한 model, RL/fine-tuning, planner 개선 필요 |
다만 “training-free”라는 표현은 비용이 없다는 뜻이 아니다.
이 구조는 같은 모델을 여러 역할로 호출하므로 inference latency와 orchestration complexity가 늘어난다.
또한 논문은 cost/latency overhead를 상세히 벤치마크하지 않는다.
실제 서비스에서는 8B 모델을 세 번 호출하는 비용이 더 큰 모델을 한 번 호출하는 비용보다 항상 유리한지 별도로 봐야 한다.
또 하나 흥미로운 점은 FP16과 AWQ의 trade-off다.
AWQ는 32K context를 유지하지만, FP16 12K가 전반적으로 더 좋은 결과를 낸다.
저자들은 이 설정에서는 더 긴 context보다 per-step policy quality, 즉 numerical precision 쪽이 더 중요했을 수 있다고 해석한다.
이는 “에이전트는 무조건 긴 context가 이긴다”는 직관에 제동을 건다. artifact-aware summarization이 있으면, 품질 좋은 짧은 context가 긴 quantized context보다 나을 수 있다.
한계는 분명하다.
평가 split은 test_normal뿐이고, test_challenge는 compute budget과 작은 모델의 near-zero 성능 때문에 시도하지 않았다.
모든 결과는 pass@1 greedy decoding이라 pass@4나 Avg@4 프로토콜과 직접 비교하면 안 된다.
실패 분류도 GPT-4o evaluator에 의존하므로 taxonomy bias가 있을 수 있다.
무엇보다 frontier model과의 격차는 여전히 크다.
GPT-4o 48.8%, Claude 3.5 Sonnet 33.2%와 비교하면 8.9%는 “실용적 완성”이라기보다 “작은 모델 실패의 일부가 런타임 구조로 줄어든다”는 실험적 신호에 가깝다.
그래도 이 논문은 작은 에이전트 시스템을 바라보는 관점을 잘 바꾼다.
모델을 하나의 monolithic actor로 보지 말고, 같은 weights라도 state compression, action generation, isolated correction이라는 서로 다른 역할로 호출할 수 있다.
그리고 남은 실패 분포가 reasoning/planning 쪽으로 이동한다면, 그때 비로소 모델 학습이나 더 큰 모델 투입이 필요한 영역이 선명해진다.
좋은 에이전트 엔지니어링은 “모델이 못한다”에서 끝나는 것이 아니라, 어떤 실패는 런타임이 흡수하고 어떤 실패는 모델 능력으로 남겨야 하는지를 분해하는 일에 가깝다.