작은 언어모델에서 reasoning capability를 끌어내는 문제는 보통 두 가지 가정에 갇힌다.
하나는 reasoning은 충분히 큰 모델에서만 본격적으로 나타난다는 가정이고, 다른 하나는 설령 작은 모델에서도 가능하더라도 수십 조 token 규모의 pretraining corpus가 필요하다는 가정이다.
Qwen3-0.6B나 DeepSeek distillation 계열은 첫 번째 가정을 이미 흔들었지만, 두 번째 가정은 여전히 강하게 남아 있었다.
MobileLLM-R1: Exploring the Limits of Sub-Billion Language Model Reasoners with Open Training Recipes는 이 두 번째 질문을 정면으로 다룬다.
Meta 연구진은 140M, 360M, 950M 규모의 MobileLLM-R1 계열을 만들고, 논문·GitHub 코드·Hugging Face collection을 함께 공개했다.
핵심 주장은 “reasoning을 위해 반드시 36T token급 proprietary corpus가 필요한가?”
에 가깝다.
저자들은 약 2T token 규모의 고품질 데이터 풀을 능력별로 선별하고 재샘플링한 뒤, 총 4.2T token 수준의 pretraining·mid-training을 거치면 sub-billion model에서도 꽤 강한 reasoning 성능이 나온다고 보고한다.
무엇을 해결하려는가
논문의 문제의식은 “작은 reasoning model을 만들 수 있는가”보다 더 구체적이다.
이미 0.6B~1B대 모델에서도 chain-of-thought 성능이 어느 정도 나타난다는 사실은 여러 공개 모델로 확인됐다.
더 중요한 질문은 그 성능이 거대한 비공개 데이터와 비공개 학습 recipe 없이는 재현 불가능한가이다.
MobileLLM-R1은 여기에 대해 데이터 규모 자체보다 데이터가 어떤 능력에 어떤 영향을 주는지 측정하고, 그 영향에 맞춰 재혼합하는 과정을 강조한다.
일반 web text, math, code, knowledge corpus를 단순히 많이 넣는 것이 아니라, 각 데이터 source가 math, code, knowledge, general reasoning 같은 capability-probing set의 loss를 얼마나 낮추는지 추적한다.
그 다음 이 영향도를 기반으로 pretraining data mix를 다시 잡는다.
이 접근은 작은 모델에서 특히 중요하다.
7B나 70B 모델은 대규모 corpus의 잡음과 중복을 어느 정도 흡수할 수 있지만, 140M~950M 모델은 capacity가 작다.
잘못 섞인 데이터는 단순히 비효율적인 정도가 아니라, 한 능력을 키우는 대신 다른 능력을 압박할 수 있다.
MobileLLM-R1은 작은 모델의 capacity budget을 “어떤 token을 더 넣을 것인가”보다 “어떤 token이 지금 모델 상태에서 여전히 양의 영향을 주는가”로 본다.
핵심 아이디어 / 구조 / 동작 방식
학습 pipeline은 세 단계로 나뉜다.

첫 번째는 pre-training: balance of capabilities다.
저자들은 StarCoder, OpenWebMath, FineWeb-Edu, Wiki, arXiv, StackExchange, Algebraic Stack 같은 대표 corpus를 놓고 capability-probing dataset을 구성한다.
이후 hierarchical rejection sampling, group impact via loss delta, leave-one-out ablation을 사용해 각 data source가 능력별로 얼마나 유익한지 측정한다.
이때 목적은 “좋은 데이터 목록”을 만드는 데 그치지 않고, 학습이 진행되며 어떤 source의 marginal utility가 줄어드는지도 본다.
두 번째는 mid-training: knowledge compression이다. pretraining 후에는 더 길어진 sequence와 teacher distribution을 활용해 지식을 압축한다.
README 기준 mid-training은 Llama-3.1-8B-Instruct를 teacher로 두고 KL divergence를 최소화하는 distillation 형태를 포함한다.
논문은 influence score 분포가 학습이 진행되며 점차 0 또는 음수로 이동한다고 해석한다.
데이터가 모델 개선에 주는 양의 영향이 소진되는 지점을 찾아, 더 작은 subset과 teacher signal로 지식을 압축하려는 설계다.
세 번째는 post-training이다.
General SFT에는 Tulu3-SFT 866K sample을 쓰고, reasoning SFT에는 OpenMathReasoning, OpenScienceReasoning-2, OpenCodeReasoning-2를 합친 6.2M sample을 쓴다.
중요한 점은 post-training도 “reasoning SFT 하나면 끝”이 아니라는 것이다.
논문 Table 1에서는 Tulu-3 general SFT를 거친 뒤 math, science, code reasoning 데이터를 함께 쓰는 설정이 전반적으로 가장 안정적인 조합으로 제시된다.
모델 구조 자체는 복잡한 새 architecture라기보다 작은 LLM family를 체계적으로 구성한 쪽에 가깝다.
| 모델 | Layers | Attention heads | KV heads | Dim | Hidden dim | Params |
|---|---|---|---|---|---|---|
| MobileLLM-R1-140M | 15 | 9 | 3 | 576 | 2048 | 140.2M |
| MobileLLM-R1-360M | 15 | 16 | 4 | 1024 | 4096 | 359.4M |
| MobileLLM-R1-950M | 22 | 24 | 6 | 1536 | 6144 | 949.2M |
README와 Hugging Face metadata 기준 공개 family는 base checkpoint와 post-trained checkpoint로 나뉜다.
Base 모델은 4k context를, post-trained 모델은 32k context를 전제로 설명된다.
모두 text-to-text 모델이고 vocabulary size는 128k, shared embedding을 사용한다.
공개된 근거에서 확인되는 점
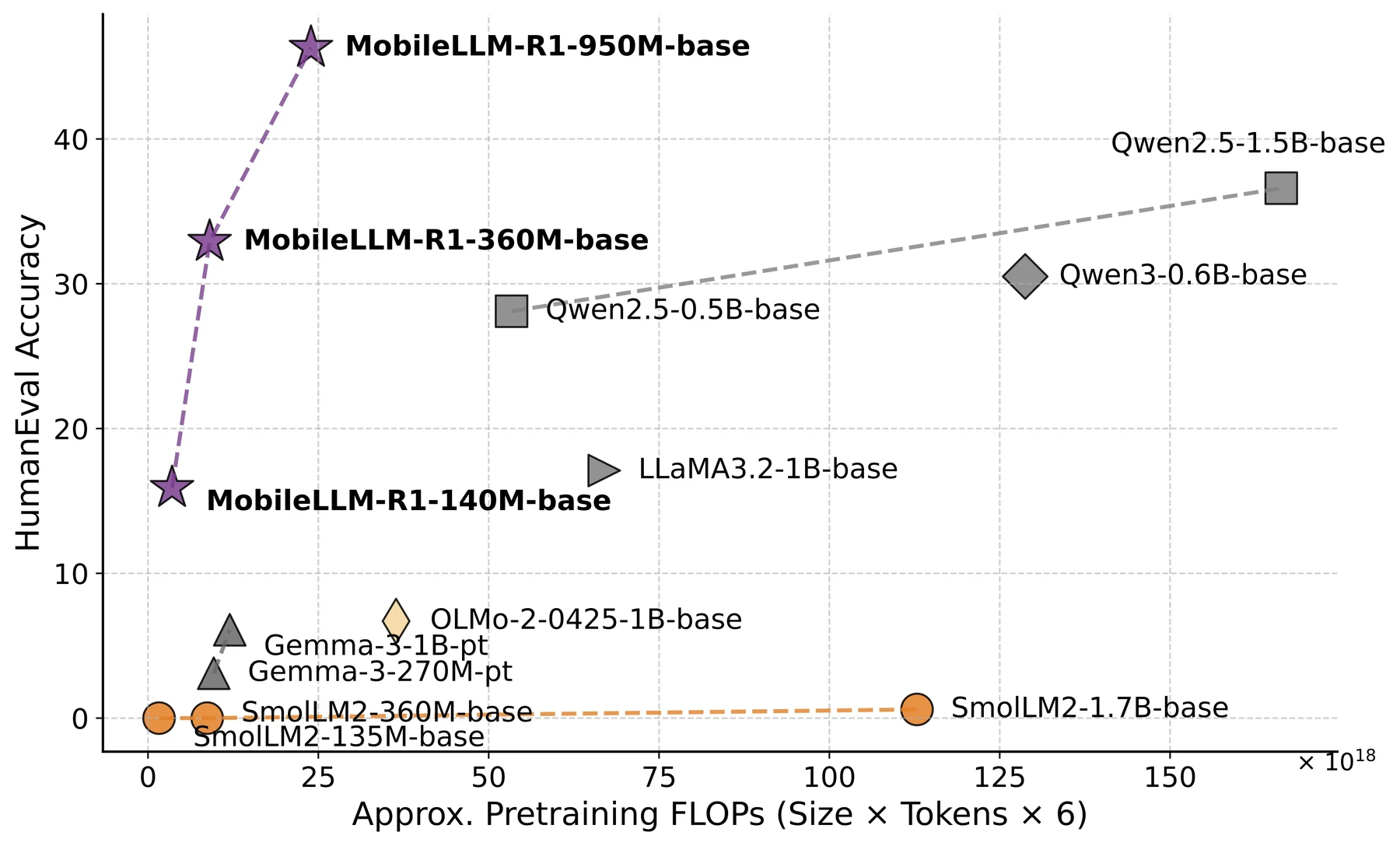
가장 강한 headline은 950M 모델이다.
논문 abstract는 MobileLLM-R1-950M이 AIME에서 15.5를 기록해 OLMo-2-1.48B의 0.6, SmolLM2-1.7B의 0.3보다 크게 높다고 쓴다.
더 중요한 비교는 Qwen3-0.6B다.
Qwen3는 36T token 규모의 proprietary pretraining corpus를 쓴 것으로 알려져 있는데, MobileLLM-R1은 그 11.7% 수준의 pretraining token budget으로 여러 reasoning benchmark에서 비슷하거나 일부 더 나은 결과를 낸다.
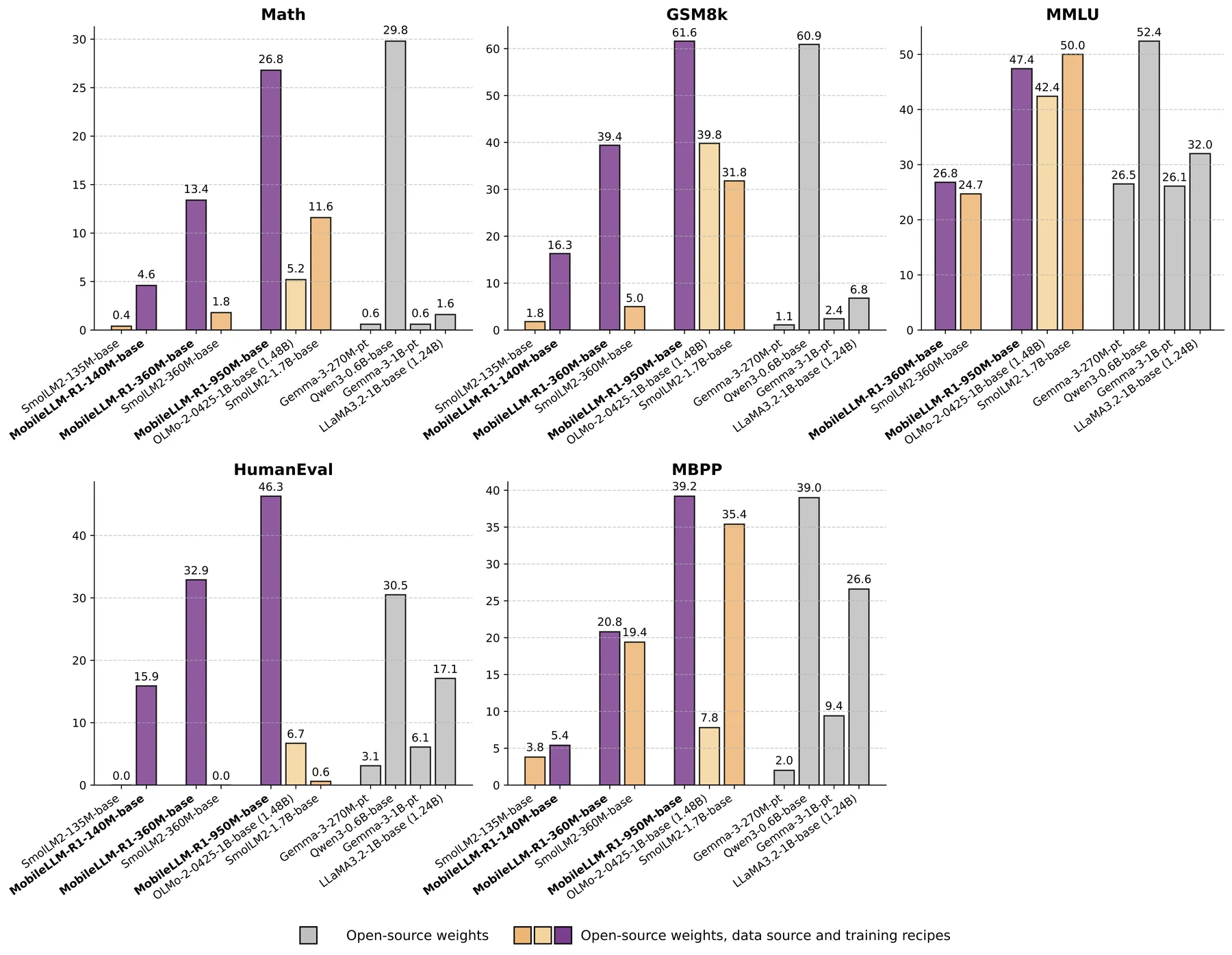
Base model 결과를 보면 MobileLLM-R1-950M-base는 GSM8K 61.6, HumanEval 46.3, CommonSense 평균 58.6을 기록한다.
Qwen3-0.6B-Base는 GSM8K 60.9, HumanEval 30.5, MMLU 52.4다.
즉 Qwen3가 MMLU에서는 앞서지만, MobileLLM-R1은 coding 쪽에서 강하고 GSM8K는 비슷하다.
OLMo-2-0425-1B와 SmolLM2-1.7B 같은 fully open-source baseline과 비교하면 math/code 쪽 차이가 더 커진다.
| Base model | Size | MATH500 | GSM8K | HumanEval | CommonSense avg. | MMLU |
|---|---|---|---|---|---|---|
| Qwen3-0.6B-Base | 596M | 29.8 | 60.9 | 30.5 | 55.3 | 52.4 |
| MobileLLM-R1-950M-base | 949M | 26.8 | 61.6 | 46.3 | 58.6 | 47.4 |
| OLMo-2-0425-1B | 1.48B | 5.2 | 39.8 | 6.7 | 61.0 | 42.4 |
| SmolLM2-1.7B | 1.71B | 11.6 | 31.8 | 0.6 | 62.9 | 50.0 |
Post-training 후에는 패턴이 조금 달라진다.
MobileLLM-R1-950M은 MATH500 74.0, AIME’24 15.5, AIME’25 16.3, LiveCodeBench-v6 19.9를 기록한다.
Qwen3-0.6B는 MATH500 73.0, AIME’24 11.3, AIME’25 17.0, LCBv6 14.9다.
따라서 “모든 지표에서 Qwen3를 압도한다”가 아니라, MATH500·AIME’24·LCBv6에서는 앞서고, GSM8K·AIME’25에서는 Qwen3가 여전히 강하다고 읽는 편이 정확하다.
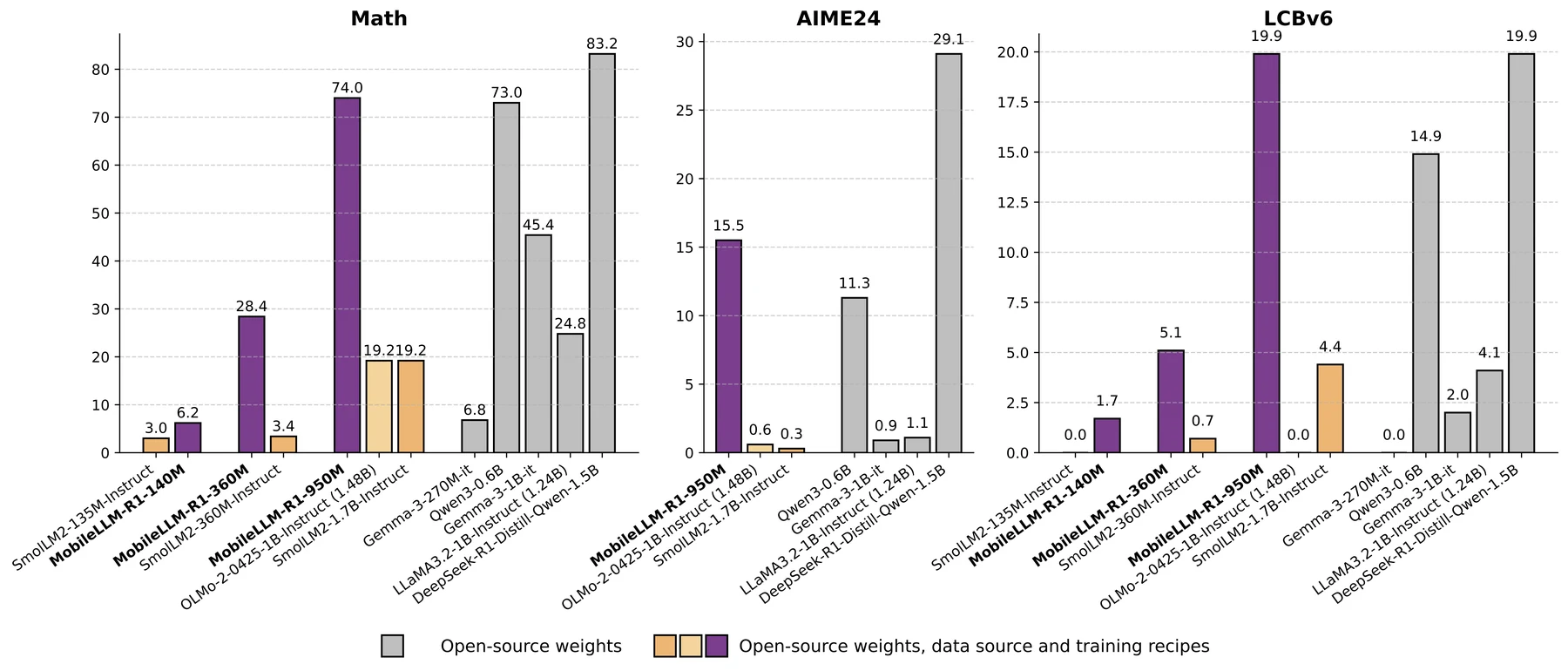
| Post-trained model | Size | MATH500 | GSM8K | AIME’24 | AIME’25 | LCBv6 |
|---|---|---|---|---|---|---|
| Qwen3-0.6B | 596M | 73.0 | 79.2 | 11.3 | 17.0 | 14.9 |
| MobileLLM-R1-950M | 949M | 74.0 | 67.5 | 15.5 | 16.3 | 19.9 |
| OLMo-2-0425-1B-Instruct | 1.48B | 19.2 | 69.7 | 0.6 | 0.1 | 0.0 |
| SmolLM2-1.7B-Instruct | 1.71B | 19.2 | 41.8 | 0.3 | 0.1 | 4.4 |
작은 모델도 완전히 장식은 아니다.
360M 모델은 post-training 후 MATH500 28.4, GSM8K 24.5, LCBv6 5.1을 기록한다.
AIME처럼 높은 난도의 competition math에서는 400M 미만 모델의 score를 신뢰하기 어렵다고 논문은 표시하지만, 360M에서도 일반 math/coding signal은 분명히 생긴다.
흥미로운 부분은 RL에 대한 절제된 결론이다.
Appendix Figure 10은 MobileLLM-R1-950M-base에는 RL fine-tuning이 reasoning gain을 줄 수 있지만, 이미 SFT로 최적화한 작은 final model에 추가 RL을 얹으면 성능이 악화될 수도 있음을 보여준다.
작은 모델에서 RL은 “무조건 더하면 좋은 마지막 단계”가 아니라, base corpus와 SFT 상태에 따라 이득과 손실이 갈리는 도구에 가깝다.
Release surface도 확인할 가치가 있다.
GitHub 저장소 facebookresearch/MobileLLM-R1은 pretrain, sft, evaluation 디렉터리를 포함하고, README에는 pretraining/mid-training/SFT 절차와 데이터 mix가 정리되어 있다.
GitHub API 조회 기준 저장소는 2025년 9월 23일 생성됐고, 현재 stars 83, forks 14, open issues 2, releases/tags는 비어 있다.
즉 논문을 따라갈 수 있는 demonstration code와 recipe는 공개되어 있지만, versioned package release라기보다는 연구 artifact에 가깝다.
Hugging Face collection은 facebook/MobileLLM-R1-140M/360M/950M 및 base checkpoint들을 담고 있으며, API 기준 gated 상태가 manual로 표시된다.
라이선스도 GitHub의 FAIR Noncommercial Research License 및 Hub의 license:other 신호를 함께 봐야 한다.
따라서 “오픈 레시피”라는 표현은 재현 절차와 모델 family 공개 측면에서는 맞지만, 상업적 사용까지 자유로운 permissive open-weight release로 오해하면 안 된다.
실무 관점에서의 해석
MobileLLM-R1의 가장 중요한 메시지는 작은 모델 학습에서 데이터 효율성은 token 수가 아니라 capability별 marginal utility 문제라는 점이다.
큰 모델 학습에서는 “좋은 web corpus를 많이 넣는다”는 전략이 어느 정도 통하지만, sub-billion model에서는 어떤 데이터가 어느 능력을 실제로 끌어올리는지 훨씬 세밀하게 봐야 한다.
FineWeb-Edu처럼 넓은 지식과 언어 다양성을 주는 corpus, OpenWebMath처럼 수학 reasoning을 밀어주는 corpus, StarCoder처럼 code 능력을 보강하는 corpus는 같은 token이라도 모델 상태와 학습 단계에 따라 가치가 달라진다.
이 점은 제품 팀에도 의미가 있다.
모든 서비스가 7B 이상 모델을 edge나 on-device에 올릴 수는 없다. latency, memory, privacy, cost 때문에 1B 이하 모델이 필요한 영역은 계속 남는다.
MobileLLM-R1은 그런 모델을 단순히 큰 모델의 축소판으로 보지 말고, 작은 capacity에 맞춘 데이터 선별·재혼합·지식 압축 recipe를 별도로 설계해야 한다고 말한다.
다만 비용이 작은 것은 아니다.
Table 4 기준 pretraining은 phase당 2T token, 16×8 GPU 구성을 4~5일씩 사용한다.
Mid-training도 100B token phase 두 개와 teacher distillation을 포함한다.
즉 이 논문은 “개인 GPU로 쉽게 재현 가능한 초소형 recipe”라기보다, 대형 연구 조직이 sub-billion model family를 만들 때 token budget을 어떻게 줄이고 공개 recipe를 어떻게 구성할 수 있는가에 가깝다.
On-device 관점에서도 숫자를 조심해서 읽어야 한다.
논문 Table 10의 profiling에서는 MobileLLM-R1-140M이 1k context에서 129.67 token/s, 32k context에서 79.71 token/s를 보인다.
950M은 1k에서 31.05 token/s, 8k에서 25.36 token/s지만 16k와 32k에서는 OOM으로 표시된다.
32k context를 지원하는 checkpoint라고 해서 모든 edge 환경에서 긴 context가 바로 실용적이라는 뜻은 아니다.
결론적으로 MobileLLM-R1은 “작은 reasoning model도 된다”는 단순한 낙관론보다 더 유용하다.
이 논문이 보여주는 것은 작은 모델의 reasoning은 데이터 규모 하나로 설명되지 않으며, capability-aware data curation, staged training, knowledge compression, post-training 조합이 함께 맞아야 한다는 점이다.
공개된 GitHub/Hugging Face bundle은 noncommercial/gated caveat가 있지만, 적어도 연구자와 엔지니어가 작은 reasoning model의 학습 레시피를 비교·분해·재구성할 수 있는 기준점을 하나 더 제공한다.