이번 링크는 LinkedIn에 공유된 DeepSeek-OCR (Gundam) fully visualised 포스트에서 출발한다.
게시물 자체는 핵심 bullet만 요약하고 있고, 실제 원문은 Frederik vom Lehn의 Medium 글 DeepSeek-OCR fully visualised다.
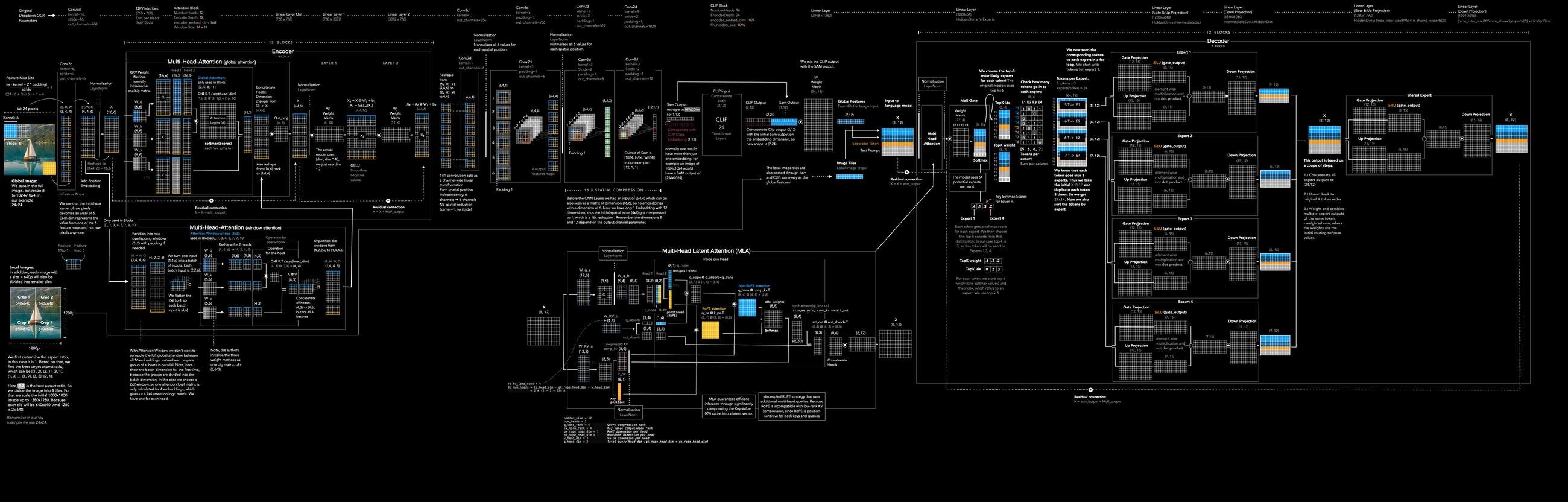
글의 가치는 단순한 “모델 소개”가 아니라, DeepSeek-OCR을 SAM, CNN token compression, CLIP, DeepSeek-MoE decoder, Multi-Head Latent Attention까지 이어지는 하나의 정보 흐름으로 펼쳐 보여 준다는 데 있다.
DeepSeek-OCR은 OCR 모델이지만, 더 정확히는 문서를 적은 vision token으로 압축한 뒤 다시 텍스트로 복원하는 실험이다.
공식 arXiv 초록은 이를 Contexts Optical Compression이라고 부른다.
텍스트를 그대로 긴 token sequence로 넣지 않고, 2D optical representation으로 압축해 vision encoder가 읽고, decoder가 OCR/Markdown을 복원한다.
그래서 이 모델은 “문자를 잘 읽는 OCR”이면서 동시에 “LLM long-context를 시각 압축으로 우회할 수 있는가”를 묻는 연구다.
무엇을 해결하려는가
문서 AI 파이프라인에서 비용을 크게 만드는 것은 이미지 크기 자체보다 문서가 텍스트 token으로 펼쳐졌을 때의 길이다.
긴 PDF, 스캔 문서, 표, 수식, 그림 설명, 복잡한 레이아웃을 모두 텍스트로 풀면 후속 LLM의 context와 KV cache가 빠르게 비싸진다.
반대로 단순 OCR로 텍스트만 뽑으면 레이아웃, 표 구조, 그림 주변 맥락 같은 정보가 사라지기 쉽다.
DeepSeek-OCR의 문제의식은 여기서 다르다.
“문서를 텍스트로 길게 펼쳐서 읽힐 것인가” 대신 “문서를 이미지로 유지하되, LLM이 다룰 수 있을 만큼 적은 vision token으로 압축할 수 있는가”를 본다.
공식 논문은 DeepEncoder와 DeepSeek3B-MoE-A570M decoder를 결합해, 고해상도 입력에서도 activation과 vision token 수를 관리 가능한 수준으로 유지하려 한다.
이 관점은 OCR을 단순 전처리가 아니라 context engineering layer로 올려놓는다.
문서의 모든 글자를 바로 LLM context에 넣는 대신, 시각 표현으로 압축하고, 필요할 때 decoder가 문자를 복원한다.
성공한다면 긴 문서 처리, 문서 기반 RAG, 에이전트 메모리, 데이터셋 생성 비용을 다른 형태로 재배치할 수 있다.
핵심 아이디어 / 구조 / 동작 방식
Frederik vom Lehn의 visualisation은 DeepSeek-OCR을 크게 세 구간으로 나눈다.
첫째는 입력 이미지를 global view와 local crops로 만드는 전처리다.
둘째는 SAM 기반 encoder와 CNN/CLIP을 거쳐 vision token을 압축하는 DeepEncoder다.
셋째는 global/local visual feature와 language token을 합쳐 MoE language decoder가 OCR 결과를 생성하는 구간이다.
첫 단계는 Gundam mode를 이해하는 것이다.
공식 README 기준 open-source model은 native resolution으로 Tiny 512×512, Small 640×640, Base 1024×1024, Large 1280×1280을 지원하고, dynamic resolution으로 n×640×640 + 1×1024×1024 형태의 Gundam 모드를 지원한다.
LinkedIn 요약이 강조한 것처럼 global view는 aspect ratio를 유지한 채 1024×1024 square로 pad되고, 동시에 입력이 충분히 크면 640×640 local crop 여러 장으로 나뉜다.
| 모드 | 입력 형태 | README 기준 vision token |
|---|---|---|
| Tiny | 512×512 native | 64 |
| Small | 640×640 native | 100 |
| Base | 1024×1024 native | 256 |
| Large | 1280×1280 native | 400 |
| Gundam | n×640×640 local crops + 1×1024×1024 global view | crop 수에 따라 동적 |
이 설계는 문서 처리에서 꽤 자연스럽다.
한 장 전체를 보는 global view는 레이아웃과 페이지 문맥을 잡고, local crops는 작은 글자·표 셀·세부 구조를 보존한다.
즉 “전체 지도”와 “확대 렌즈”를 동시에 넘기는 방식이다.
OCR 시스템이 흔히 겪는 문제는 전체 페이지를 줄이면 작은 글자를 잃고, 작은 영역만 보면 전체 구조를 잃는다는 점인데, Gundam mode는 이 trade-off를 multi-view로 풀려는 시도다.
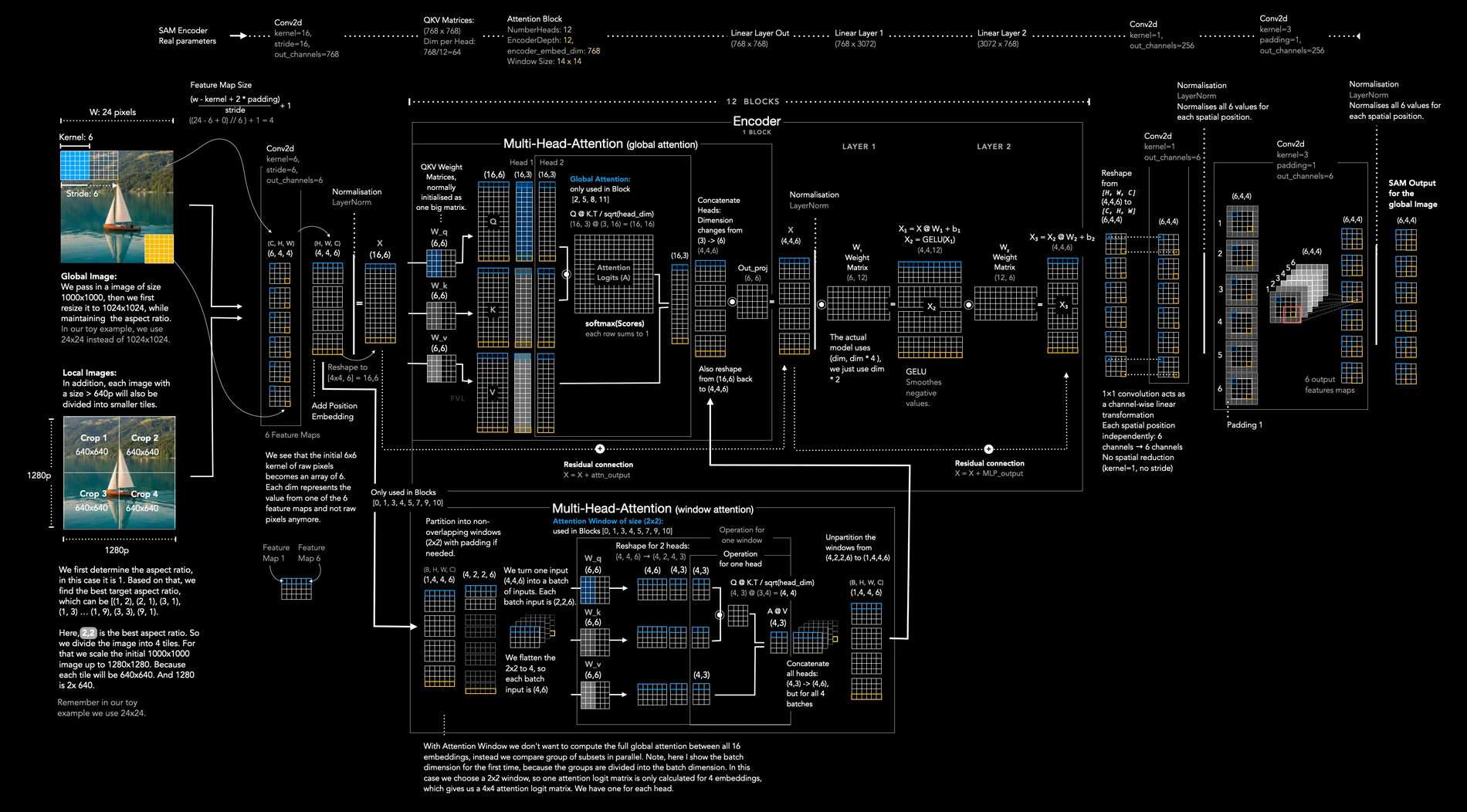
SAM encoder 구간에서 중요한 것은 attention의 범위를 계속 전역으로 두지 않는다는 점이다. visualisation은 12개 block 중 일부만 global attention을 쓰고, 나머지는 local window attention을 사용한다고 설명한다.
문서 이미지는 작은 글자와 국소 패턴이 중요하므로 local attention은 세부 인식에 유리하고, 몇몇 global attention block은 전체 페이지 구조를 다시 섞어 주는 역할을 한다.
다음으로 두 개의 CNN layer가 나온다.
Medium 글은 이 부분을 흔히 언급되는 16× down-compression mechanism으로 설명한다.
SAM이 뽑은 feature map을 그대로 decoder에 넘기면 vision token 수가 커지기 때문에, CNN을 통해 공간 차원을 더 줄이고 정보 밀도를 높인다.
이 지점이 DeepSeek-OCR의 핵심 cost lever다. token 수는 줄지만, 각 token이 더 많은 시각 정보를 품도록 만든다.
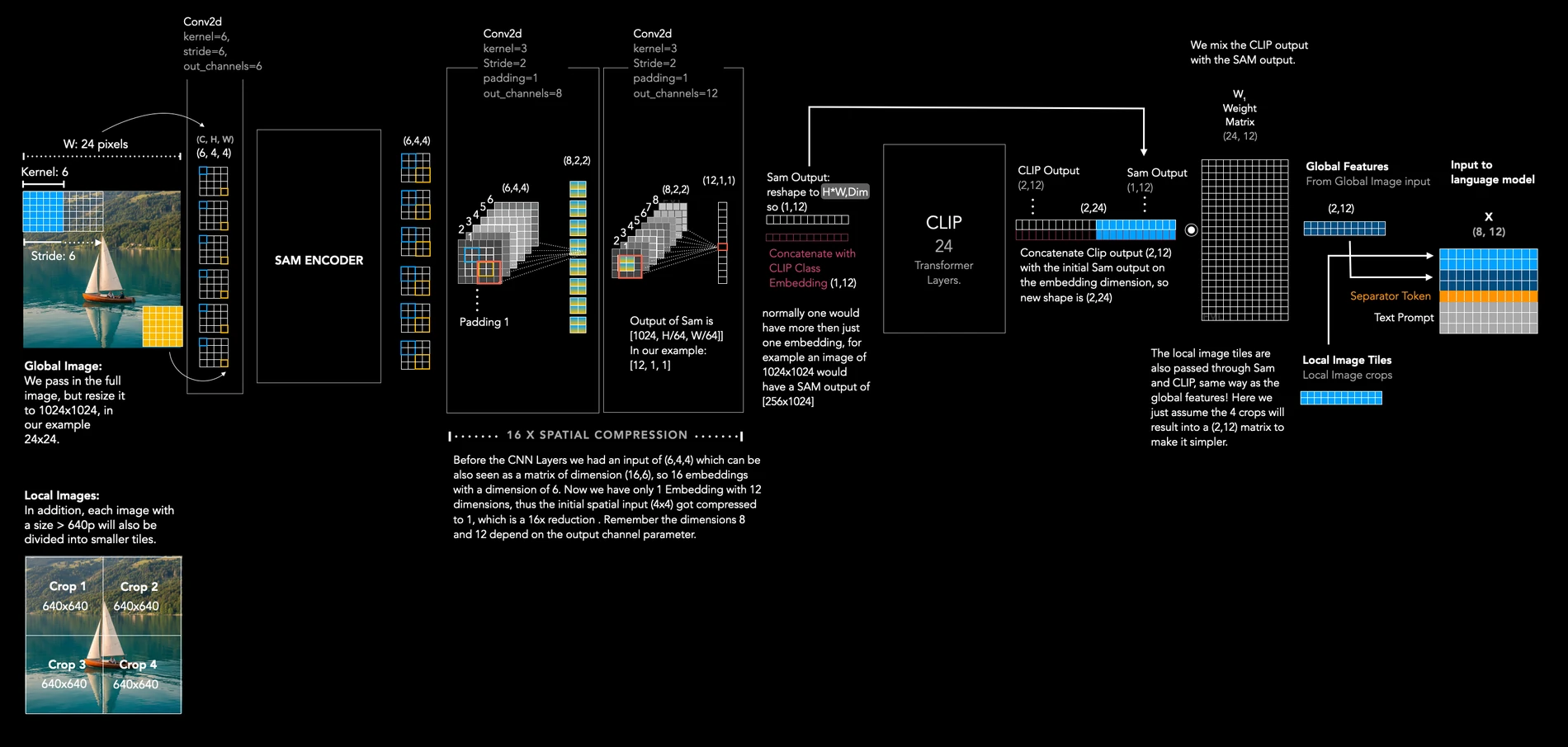
CLIP encoder는 global representation을 보강하는 축으로 읽을 수 있다.
시각화 글은 CLIP class embedding이 patch token과 상호작용하면서 global summary 역할을 한다고 설명한다.
이후 global image feature, local image feature, separator embedding, language embedding이 하나의 sequence로 결합되고 language decoder로 넘어간다.
Decoder 쪽은 DeepSeek 계열의 MoE transformer로 설명된다.
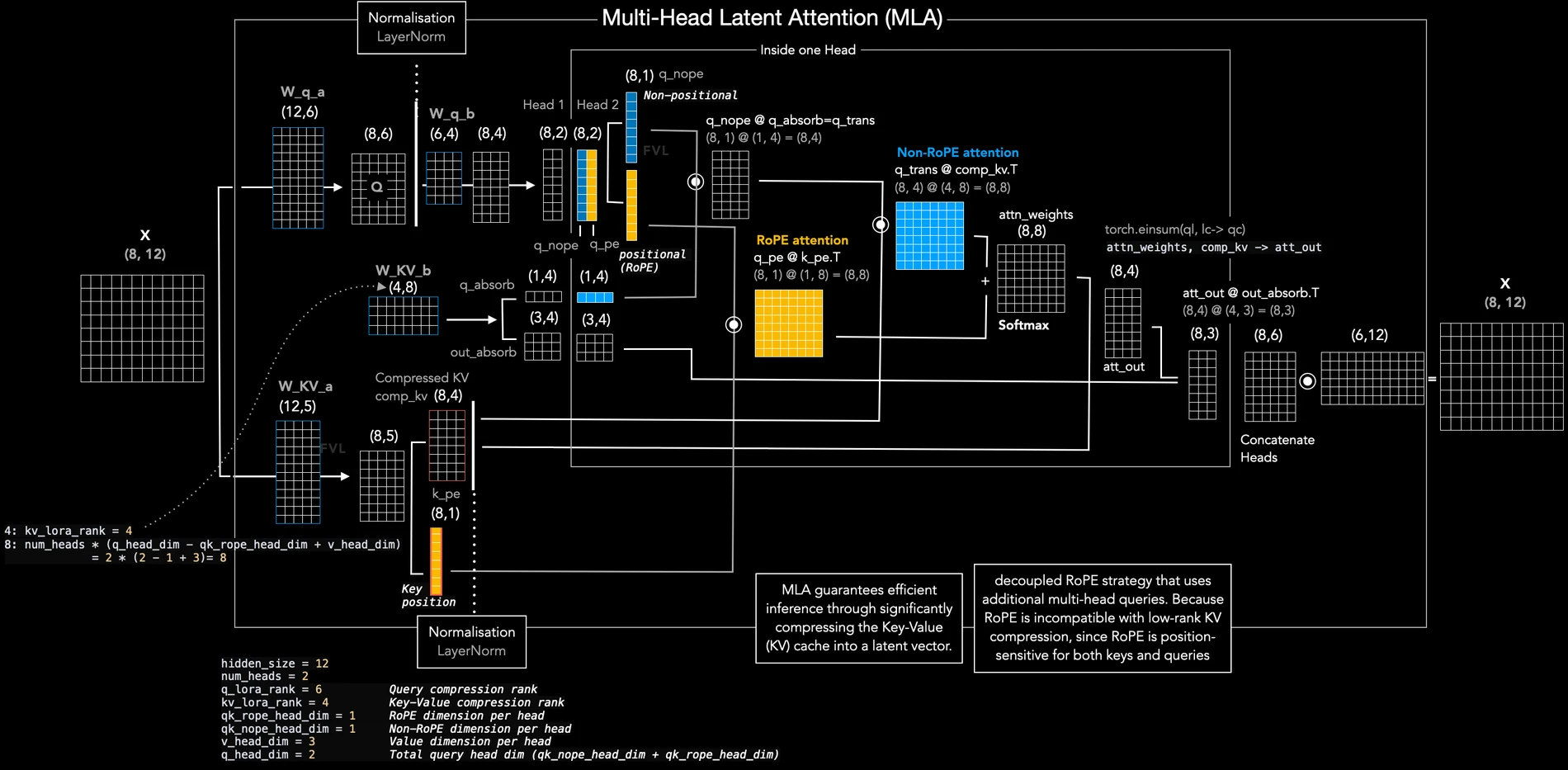
Medium 글 기준 language decoder는 30개 transformer block으로 구성되고, 각 block은 Multi-Head Latent Attention과 Mixture of Experts를 포함한다. toy diagram에서는 top-3 expert routing으로 그려져 있지만, real model에서는 top-6 expert를 사용한다고 설명한다.
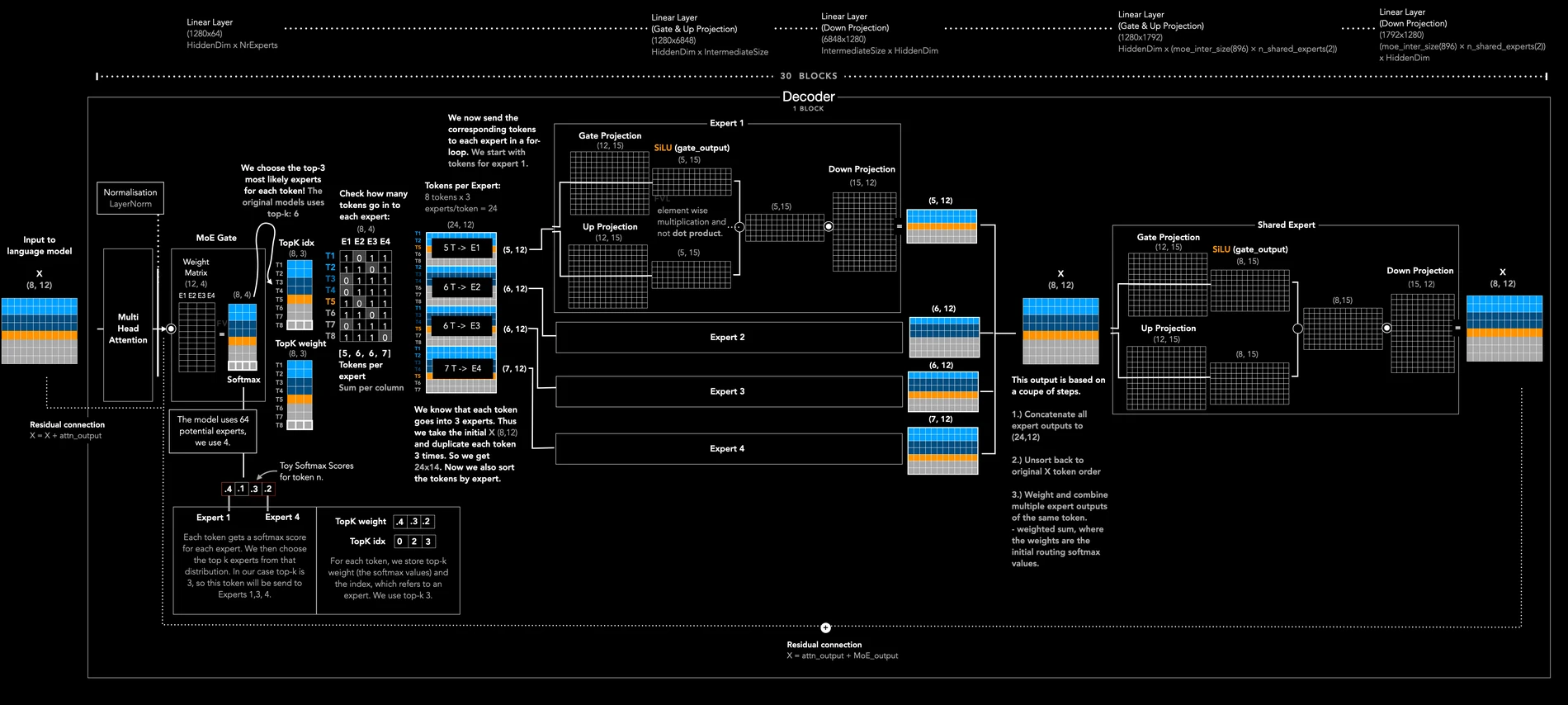
여기서 MLA는 OCR 모델과 직접 관련 없어 보일 수 있지만, 실제로는 중요하다.
문서 OCR은 긴 출력 sequence를 만들 수 있고, batch/PDF 처리에서는 decoder cache 비용도 무시할 수 없다.
Medium 글은 MLA가 full-dimensional K/V를 head별로 모두 보관하는 대신 low-rank latent vector로 압축하고, RoPE positional part와 non-RoPE content part를 나눠 attention을 계산한다고 설명한다.
즉 vision token compression만으로 끝나는 것이 아니라, decoder 쪽 attention/cache 비용도 줄이는 방향이다.
공개된 근거에서 확인되는 점
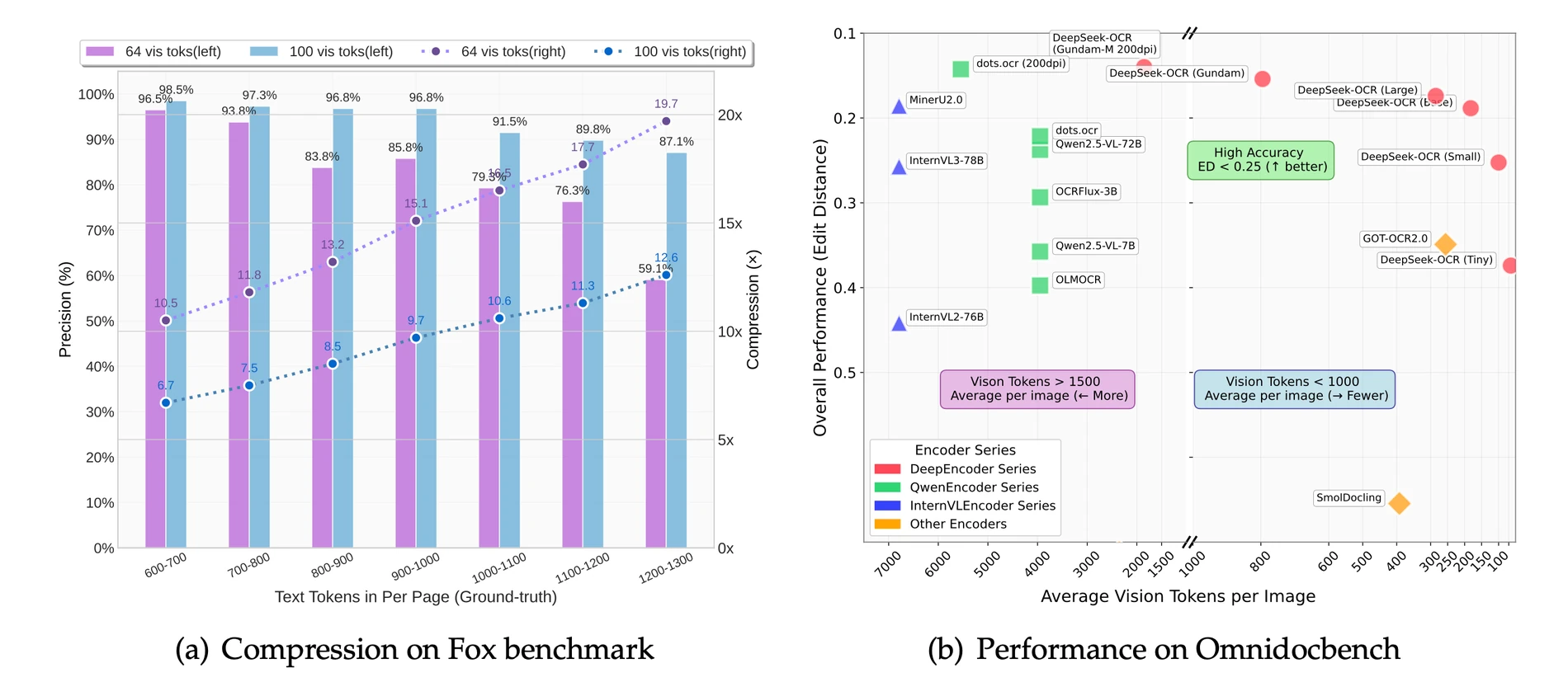
공식 arXiv 초록에서 가장 강한 메시지는 숫자다. text token 수가 vision token 수의 10배 이내일 때 OCR precision 97%를 달성하고, 20배 압축에서도 약 60% accuracy를 유지한다고 보고한다.
또한 OmniDocBench에서 100 vision token만으로 GOT-OCR2.0의 256 token/page 설정을 넘고, 800개 미만 vision token으로 평균 6000+ token/page를 쓰는 MinerU2.0을 앞선다고 주장한다.
| 공개 근거 | 확인되는 내용 | 해석 |
|---|---|---|
| arXiv 2510.18234 | DeepEncoder + DeepSeek3B-MoE-A570M 구조, 10× 이내 97% precision, 20×에서 약 60% accuracy | OCR을 token compression 문제로 제시 |
| GitHub README | Tiny/Small/Base/Large/Gundam mode, vLLM/Transformers inference, prompt 예시 | 실제 실행 표면과 resolution knob 제공 |
| Hugging Face model card | deepseek-ai/DeepSeek-OCR, BF16 safetensors, image-text-to-text 모델 |
weights 공개와 생태계 배포 표면 확인 |
| Medium visualisation | SAM, CNN compression, CLIP, MoE decoder, MLA를 연결한 그림 | architecture를 읽기 쉬운 operational map으로 변환 |
README의 inference 표면도 실무적으로 중요하다.
기본 prompt는 Free OCR.와 <|grounding|>Convert the document to markdown. 계열로 나뉘고, figure parsing, image description, recognition prompt도 예시로 제시된다.
즉 DeepSeek-OCR은 단순 문자 추출만이 아니라 document-to-Markdown, figure parsing, grounding까지 염두에 둔 VLM 인터페이스를 가진다.
배포 관점에서는 vLLM 지원이 큰 신호다.
공식 README는 2025년 10월 23일 upstream vLLM 지원을 공지하고, PDF inference에서 A100-40G 기준 약 2500 tokens/s concurrency를 언급한다. arXiv 초록도 production에서 단일 A100-40G로 하루 20만 페이지 이상의 LLM/VLM training data를 생성할 수 있다고 주장한다.
이 수치는 독립 벤치마크라기보다 DeepSeek 측 reported number지만, 모델이 연구 toy가 아니라 대량 문서 처리 파이프라인을 의식하고 설계됐다는 점은 분명하다.
실무 관점에서의 해석
내가 보기에 DeepSeek-OCR의 핵심은 “OCR 정확도”보다 문서 정보를 어떤 token budget으로 보존할 것인가에 있다.
기존 문서 파이프라인은 보통 PDF/image → OCR text → chunk → embedding/RAG로 흐른다.
이 구조에서는 OCR 단계가 한 번 텍스트를 펼치는 순간, 시각적 레이아웃은 별도 metadata가 되고 token 길이는 다시 LLM 비용으로 돌아온다.
DeepSeek-OCR은 이 순서를 조금 바꾼다.
문서를 가능한 한 오래 optical representation으로 유지하고, vision encoder가 압축한 표현을 decoder가 필요한 형태로 복원한다.
이 방식은 특히 표, 스캔 문서, 논문 PDF, 오래된 문서, UI screenshot, agent memory처럼 레이아웃과 텍스트가 동시에 중요한 곳에서 매력적이다.
실제로 최근 OCR-Memory 같은 agent memory 연구도 DeepSeek-OCR 3B를 기반 모델로 사용해 long-horizon trajectory를 시각적으로 저장하고 검색하는 방향을 실험한다.
동시에 과대해석은 피해야 한다.
20× compression에서 accuracy가 약 60%로 떨어진다는 사실은, optical compression이 무조건적인 무료 점심이 아니라는 뜻이다.
작은 글자, 복잡한 표, 법률·금융 문서처럼 한 글자 오류가 큰 비용으로 이어지는 업무에서는 Gundam/Large 같은 고해상도 설정, 후처리 검증, human review, 구조화 평가가 여전히 필요하다.
또한 Medium visualisation은 훌륭한 architecture tour지만, 그 자체가 공식 논문은 아니다.
실험 수치와 지원 모드는 arXiv, GitHub, Hugging Face로 다시 확인해야 한다.
그럼에도 이 시각화는 DeepSeek-OCR을 이해하는 데 매우 유용하다.
많은 모델 소개 글은 “3B OCR 모델이 문서를 잘 읽는다”에서 멈추지만, 실제 제품 설계자는 어디서 비용이 줄고 어디서 품질이 깨질 수 있는지를 봐야 한다.
Gundam mode는 입력 resolution과 crop 수의 knob이고, SAM/window attention은 visual feature extraction 비용의 knob이며, CNN compression은 vision token 수의 knob이고, MoE/MLA는 decoder compute와 cache 비용의 knob다.
이 축들을 분리해서 보면 DeepSeek-OCR은 단일 모델명이 아니라, 문서 AI 비용 구조를 다시 설계하는 reference architecture로 읽힌다.