이미지와 비디오 생성에서는 diffusion과 flow matching이 사실상 표준적인 생성 패러다임이 됐다.
그런데 언어 모델링으로 오면 상황이 다르다.
텍스트는 본질적으로 discrete token sequence이고, 최근 성능이 좋은 diffusion language model(DLM)들도 대부분 token space에서 mask·denoise·resample을 반복하는 discrete formulation에 가깝다.
ELF: Embedded Language Flows는 이 흐름에 대한 반례를 만들려는 논문이다.
저자들은 continuous DLM이 약했던 이유가 “언어가 원래 discrete라서”라기보다, continuous space에서 끝까지 denoising하고 마지막에만 token으로 돌아오는 설계가 충분히 탐색되지 않았기 때문일 수 있다고 본다.
그래서 ELF는 텍스트를 먼저 continuous embedding으로 올리고, generation trajectory 대부분을 embedding space 안의 Flow Matching 문제로 처리한다.
핵심은 단순히 “토큰을 embedding으로 바꾼다”가 아니다.
ELF는 discretization을 매 step마다 하지 않고, 마지막 time step에서만 shared-weight network로 token을 복원한다.
이 덕분에 이미지 diffusion 쪽에서 이미 강하게 검증된 classifier-free guidance(CFG), self-conditioning, ODE/SDE sampler 같은 도구를 언어 모델링에 비교적 자연스럽게 이식할 수 있다.
무엇을 해결하려는가
확산형 언어 모델의 큰 장점은 autoregressive model과 다른 generation path를 열 수 있다는 점이다.
모든 토큰을 왼쪽에서 오른쪽으로 하나씩 생성하지 않고, 여러 위치를 병렬적으로 갱신하거나 few-step denoising으로 문장을 만들 수 있다면 latency와 controllability에서 다른 trade-off가 생긴다.
하지만 실제 연구 성과는 discrete DLM 쪽에 더 많이 쌓였다. token을 직접 mask하거나 discrete transition으로 다루는 방식이 성능 면에서 앞서 있었기 때문이다.
Continuous DLM은 오래된 아이디어지만, 지금까지는 두 가지 문제가 있었다.
첫째, token을 continuous vector로 올린 뒤 다시 token으로 내려오는 bridge가 불안정했다.
둘째, intermediate state를 매번 token distribution으로 해석하려 하면, 결국 continuous diffusion의 장점을 잃고 discrete decoding 문제로 돌아가기 쉽다.
ELF가 겨냥하는 병목은 바로 이 지점이다.
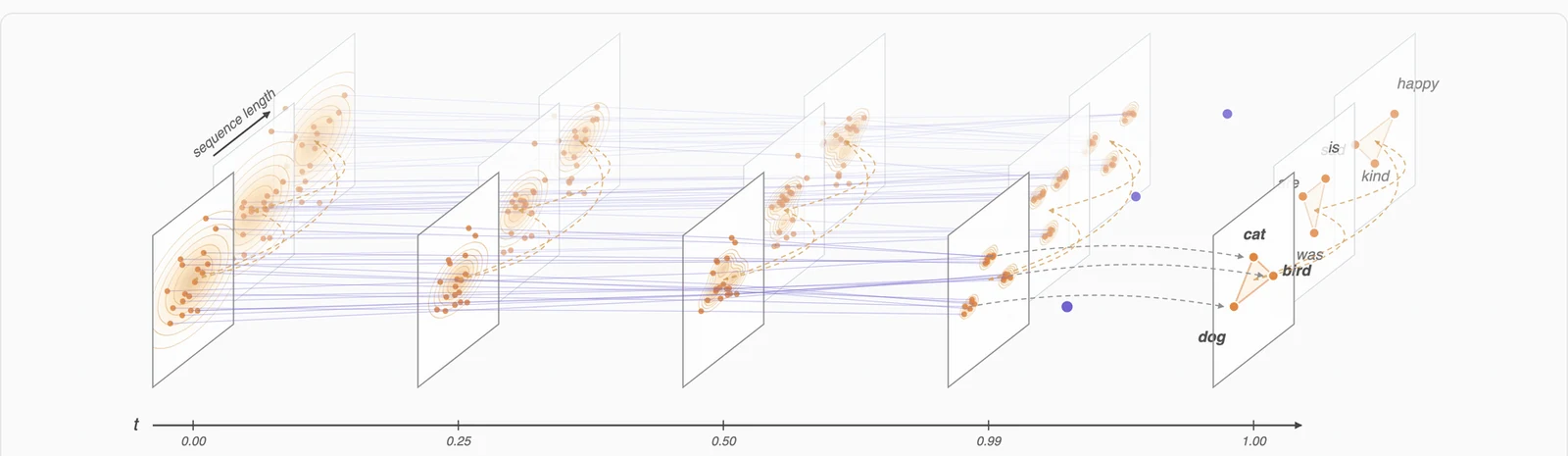
언어를 생성하는 동안 모델이 계속 token을 “맞히려고” 하지 말고, 대부분의 시간에는 clean embedding을 향해 움직이게 만들자는 것이다. discrete token은 최종 결과일 뿐, denoising trajectory의 주된 상태 공간은 continuous embedding으로 남긴다.
이 관점은 언어 모델링을 이미지 생성 쪽의 latent diffusion과 더 가깝게 만든다.
이미지 diffusion이 pixel 또는 latent space에서 noise를 점진적으로 제거하듯, ELF는 T5 encoder가 만든 contextual embedding space에서 Gaussian noise를 clean language embedding으로 흐르게 한다.
문제는 이것이 실제 텍스트 품질과 benchmark에서 통하느냐다.
핵심 아이디어 / 구조 / 동작 방식
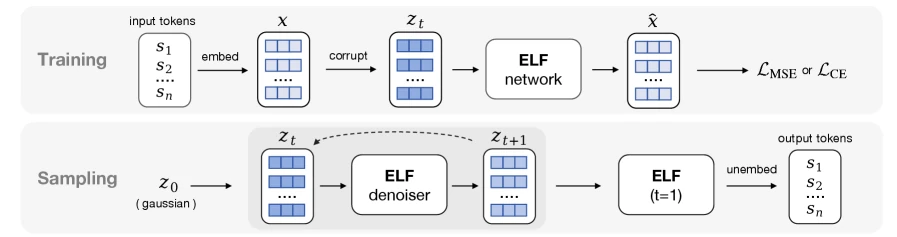
ELF의 기본 pipeline은 세 단계로 볼 수 있다.
먼저 문장을 token sequence로 만든 뒤, frozen T5-small encoder를 사용해 contextual embedding으로 변환한다.
논문 기본 설정에서 embedding dimension은 512이고, 모델 내부에는 128차 bottleneck projection을 둔다.
중요한 점은 이 encoder가 학습 때 clean embedding을 만들기 위해 쓰이고, inference 때 별도 모듈로 추가되지 않는다는 것이다.
그다음 Flow Matching을 embedding space 위에서 정의한다. clean embedding을 x, Gaussian noise를 ε라고 하면, 중간 상태는 z_t = t x + (1 - t) ε로 놓는다.
모델은 velocity를 직접 예측하기보다 clean embedding x를 예측하는 x-prediction parameterization을 쓴다.
논문은 이 선택이 고차원 token embedding에서 더 안정적이고, 마지막 token decoding objective와 weight sharing하기에도 자연스럽다고 설명한다.
마지막으로 t=1 근처에서 clean embedding을 token으로 복원한다.
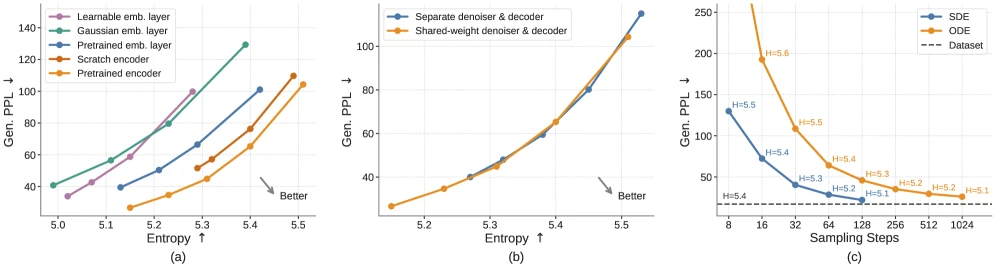
여기서 ELF는 별도 decoder를 두기보다 denoiser와 decoder를 공유하는 network를 쓴다.
학습 중에는 denoising mode에서 MSE loss를, decoding mode에서 token-wise cross-entropy loss를 사용한다.
기본 설정은 denoising 80%, decoding 20%다.
구조를 압축하면 다음과 같다.
| 구성 요소 | ELF에서의 설계 | 왜 중요한가 |
|---|---|---|
| Embedding space | frozen T5-small contextual embedding 사용 | 언어를 continuous state로 올리되 문맥 정보를 보존 |
| Flow path | z_t = t x + (1 - t) ε 형태의 continuous-time Flow Matching |
이미지·비디오 diffusion에서 쓰인 연속 생성 기법을 언어에 적용 |
| Prediction target | velocity가 아니라 clean embedding x 예측 |
final token decoding과 objective를 맞추기 쉬움 |
| Decoder | denoiser와 weight를 공유하는 final-step unembedding | 별도 decoder 없이 continuous-to-discrete bridge 구성 |
| Guidance | self-conditioning 기반 CFG와 training-time CFG | inference step마다 extra forward pass를 늘리지 않으면서 guidance 활용 |
Self-conditioning도 핵심이다.
모델은 한 번 예측한 clean embedding을 다음 denoising step의 condition으로 다시 넣는다.
이 condition을 CFG의 conditioning signal로 삼으면, discrete token distribution을 억지로 guidance하지 않고 continuous velocity/embedding prediction 위에서 quality-diversity trade-off를 조절할 수 있다.
논문은 discrete counterpart에서는 CFG가 덜 탐색되었거나 효과가 제한적이었지만, ELF의 continuous formulation에서는 이 기법이 훨씬 자연스럽게 들어간다고 본다.
공개된 근거에서 확인되는 점
실험은 크게 unconditional generation과 conditional generation으로 나뉜다.
Unconditional generation은 OpenWebText(OWT)에서 sequence length 1024로 학습하고, 1,000개 sample을 생성한 뒤 GPT-2 Large 기준 generative perplexity(Gen.
PPL)와 unigram entropy를 본다.
논문은 likelihood 평가 대신 생성 sample의 quality-diversity frontier를 보겠다는 입장이다.
모델 규모는 ELF-B 105M, ELF-M 342M, ELF-L 652M 세 가지다.
기본 ablation은 ELF-B로 진행하고, OWT에서는 Muon optimizer, batch size 512, 5 epochs, 약 95K steps를 사용한다. appendix 기준 ELF-B 기본 학습은 TPU v5p 64개에서 epoch당 약 1.5시간이 걸린다.
가장 강한 숫자는 few-step unconditional generation에서 나온다.
ELF-B는 SDE sampling과 self-conditioning CFG scale 3 설정에서 32 sampling steps만으로 Gen.
PPL 24.08 ± 0.16, entropy 5.15 ± 0.002를 기록한다.
16 steps에서도 Gen.
PPL 33.66 ± 1.09, 8 steps에서는 67.32 ± 2.25다.
논문 Figure 7은 ELF가 MDLM, Duo, FLM, LangFlow 같은 discrete/continuous DLM baseline보다 fewer sampling steps에서 낮은 Gen.
PPL을 보이고, distillation을 붙인 baseline과 비교해도 few-step regime에서 강하다고 주장한다.
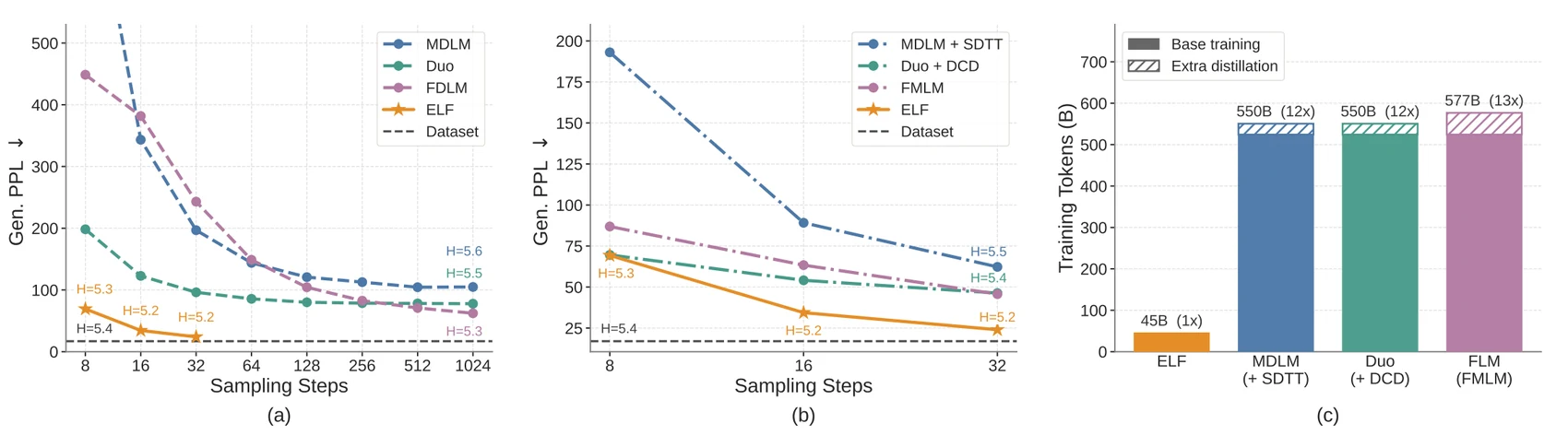
데이터 효율성도 중요한 주장이다.
논문은 system-level comparison에서 기존 DLM baseline들이 보통 524.3B 또는 distillation 포함 550.5B 이상의 effective training tokens를 쓰는 반면, ELF는 OWT 5 epochs 기준 45.2B tokens를 사용한다고 계산한다.
대략 11~12배 적은 training-token budget으로 비교 대상보다 좋은 frontier를 만든다는 메시지다.
Conditional generation에서는 WMT14 German-to-English translation과 XSum summarization을 사용한다.
ELF-B는 64-step ODE sampler, self-conditioning CFG scale 1, input-condition CFG scale 2 설정에서 다음 결과를 보고한다.
| 모델 | 크기 | WMT14 De-En BLEU | XSum ROUGE-1 | XSum ROUGE-2 | XSum ROUGE-L |
|---|---|---|---|---|---|
| AR | 99M | 25.2 | 30.5 | 10.2 | 24.4 |
| MDLM | 99M | 18.4 | 33.4 | 11.6 | 25.8 |
| Duo | 170M (+35M) | 21.3 | 31.4 | 10.1 | 25.0 |
| E2D2 | 99M | 24.8 | 28.4 | 8.3 | 22.0 |
| ELF-B | 105M (+35M) | 26.4 | 36.0 | 12.2 | 27.8 |
이 표만 보면 ELF-B는 translation BLEU와 summarization ROUGE 모두에서 동급 baseline보다 앞선다.
다만 이 결과는 100B~T-scale production LLM과의 경쟁이 아니라, 비슷한 규모의 diffusion/AR baseline을 통제한 연구 설정이라는 점을 분리해서 읽어야 한다.

공개 아티팩트는 논문만으로 끝나지 않는다. arXiv HTML에는 공식 code link로 lillian039/ELF가 연결되어 있고, GitHub 저장소 README는 이를 “official JAX implementation”이라고 밝힌다.
GitHub API 기준 저장소는 2026년 5월 11일 생성됐고, 확인 시점에 stars 498, forks 25, open issues 3, MIT license, default branch main을 갖는다. release와 tag는 아직 비어 있고, commit history도 초기 init commit 중심이라 연구 release 초기에 가깝다.
저장소 자체는 빈 placeholder는 아니다. src/train.py, src/eval.py, src/generation.py, model/layer/utils 모듈, training config YAML, sampling config YAML, README의 실행 예시가 포함되어 있다.
다만 README가 명시하듯 현재 코드는 JAX+TPU 환경에서 작성·테스트됐고, PyTorch 버전은 “soon”으로 예고되어 있다.
즉 공개 구현은 실질적이지만, 일반 GPU/PyTorch 사용자에게 바로 낮은 마찰의 패키지라고 보기는 어렵다.
Hugging Face 쪽도 함께 공개되어 있다. embedded-language-flows organization에는 ELF-B/M/L OWT checkpoint, ELF-B De-En checkpoint, ELF-B XSum checkpoint, t5_small_encoder_jax, 그리고 pre-tokenized OpenWebText/WMT14/XSum dataset repo들이 있다.
API 기준 모델 repo들은 gated가 아니며 checkpoint 파일과 config YAML을 포함한다.
다만 모델 card의 license metadata는 별도로 노출되지 않았고, GitHub code license가 MIT라는 점과 checkpoint/data license 표기는 구분해서 봐야 한다.
실무 관점에서의 해석
ELF의 가장 흥미로운 점은 “diffusion language model이 꼭 token-space algorithm이어야 하는가”라는 질문을 다시 열었다는 데 있다.
최근 DLM 논의는 masked diffusion, block diffusion, discrete denoising처럼 token 자체를 다루는 방향이 강했다.
ELF는 반대로, token은 최종 산출물이고 생성 dynamics는 continuous embedding에서 다루는 편이 diffusion/flow 생태계의 도구를 더 잘 활용할 수 있다고 보여 준다.
특히 CFG가 자연스럽게 들어간다는 점은 실용적으로 중요하다.
이미지 생성에서 CFG는 품질과 다양성의 knob로 사실상 표준이 됐다.
언어 생성에서도 비슷한 knob를 continuous representation 위에서 쓸 수 있다면, “더 deterministic한 답변”, “더 다양한 draft”, “조건을 더 강하게 따르는 요약” 같은 제어가 autoregressive decoding parameter와 다른 방식으로 열릴 수 있다.
물론 아직은 foundation model 대체재라기보다 연구적으로 잘 정리된 prototype에 가깝다.
평가 스케일은 105M~652M이고, 주요 unconditional metric은 GPT-2 Large가 생성 sample에 부여한 Gen.
PPL이다.
이는 유용한 비교 지표지만, 장문 추론·instruction following·tool use·chat alignment 같은 현대 LLM 제품 요구사항과는 거리가 있다.
또한 32-step generation이 빠르다고 해도 각 step의 network pass, SDE/ODE sampler overhead, hardware utilization을 실제 serving stack에서 따져야 한다.
그래도 공개 상태는 긍정적이다.
논문, arXiv HTML figure, 공식 GitHub, HF checkpoint/data bundle이 같은 시점에 나와 있어서 재현과 후속 실험의 출발점이 있다.
특히 config가 Hugging Face checkpoint와 pre-tokenized dataset을 직접 가리키는 구조라, TPU/JAX 환경을 갖춘 연구팀이라면 논문 수치를 다시 확인하거나 sampler/guidance 조합을 바꿔 실험하기 좋다.
내가 보기에 ELF의 실무적 의미는 “지금 당장 AR LLM을 대체한다”가 아니라, 언어 생성에서도 continuous latent/embedding space를 중심에 둔 generation stack이 다시 경쟁력이 생길 수 있다는 신호다.
만약 이 방식이 더 큰 model scale, 긴 context, instruction tuning, preference tuning까지 확장된다면 diffusion/flow 계열은 텍스트 생성에서도 단순한 대안 연구가 아니라 별도의 serving·control·editing 패러다임으로 자리를 잡을 수 있다.