에이전트 모델 경쟁을 볼 때 가장 쉬운 축은 파라미터 수다.
더 큰 모델, 더 긴 context, 더 많은 test-time compute가 강한 에이전트를 만든다는 설명은 직관적이다.
그런데 실제 에이전트 업무에서는 모델 내부 지식만큼이나 중요한 것이 있다.
검색하고, 도구를 호출하고, 실패한 실행 로그를 읽고, 중간 결과를 검증하고, 제약을 끝까지 유지하는 긴 상호작용 과정이다.
Scaling the Horizon, Not the Parameters: Reaching Trillion-Parameter Performance with a 35B Agent는 이 지점을 정면으로 겨냥한다.
논문과 공식 릴리스의 핵심 주장은 Agents-A1이라는 35B MoE agentic model이 단순 parameter scaling이 아니라 agent horizon scaling으로 일부 1T급 모델과 경쟁할 수 있다는 것이다.
여기서 horizon은 단순히 context length만 뜻하지 않는다.
외부 지식, action, observation, verifier outcome이 연결된 장기 trajectory 자체를 학습 대상으로 만든다는 의미에 가깝다.
이 글에서 Agents-A1은 “또 하나의 큰 오픈 모델”이라기보다 장기 에이전트 행동을 어떻게 데이터와 증류 문제로 바꿀 것인가를 보여 주는 model-training release로 읽는 편이 정확하다.
공개 bundle은 arXiv/HF Papers, 공식 프로젝트 페이지, GitHub 저장소, Hugging Face 모델과 FP8 variant, ModelScope 링크로 구성되어 있다.
무엇을 해결하려는가
논문의 문제의식은 두 가지 scaling route의 차이에서 출발한다.
첫 번째는 익숙한 parameter scaling이다.
모델을 크게 만들면 더 많은 지식과 reasoning pattern, tool-use behavior를 내부화할 수 있다.
하지만 frontier-scale parameter, data, compute를 전제로 하기 때문에 공개 연구나 실무 팀이 재현하기 어렵다.
두 번째가 Agents-A1이 강조하는 horizon scaling이다.
에이전트가 장기 작업을 수행할 때 실제로 거치는 중간 과정을 학습 가능한 supervision으로 바꾼다.
정보 획득, 도구 호출, 코드 실행, 관찰 해석, verifier 통과 여부, 실패 후 복구 같은 과정을 모두 trajectory 안에 남긴다.
즉 “정답을 맞혔는가”만이 아니라, 정답에 도달하기까지의 환경 상호작용을 모델이 보게 만든다.
이 접근에는 두 병목이 있다.
| 병목 | 논문이 보는 문제 | Agents-A1의 대응 |
|---|---|---|
| Knowledge infrastructure | 장기 작업에는 외부 지식, action, observation, verifier outcome이 함께 필요하다 | Knowledge-Action Graph로 evidence, action, observation, verifier를 한 구조에 기록한다 |
| Heterogeneous ability integration | 검색, 코드 실행, 과학 추론, instruction following, tool calling은 서로 다른 reasoning pattern을 요구한다 | domain-specific teacher를 만든 뒤 domain-routed OPD와 salient vocabulary alignment로 하나의 student에 통합한다 |
이 관점에서 Agents-A1의 목표는 “35B가 1T를 항상 이긴다”가 아니다.
더 정확히는 35B 모델이라도 장기 trajectory와 이질적 에이전트 능력을 체계적으로 학습시키면, 일부 long-horizon benchmark에서 훨씬 큰 모델의 영역에 접근할 수 있다는 주장이다.
Knowledge-Action Graph와 세 단계 학습
Agents-A1의 중심에는 Long-Horizon Knowledge-Action Infrastructure가 있다.
논문은 이를 domain별 Knowledge-Action Graph, 줄여서 KAG로 정의한다.
KAG는 domain corpus, action space, observation space, verifier space를 함께 담는 구조다.
여기서 corpus는 evidence chunk, entity, fact, constraint를 포함하고, action은 retrieval query, tool call, code edit, execution, reasoning step을 포함한다. observation은 tool return, retrieved evidence, execution state, intermediate artifact이고, verifier는 결과가 요구 조건을 만족하는지 판단하는 신호다.
논문은 장기 에이전트 능력을 다섯 가지 atomic ability로 쪼갠다.
| Atomic ability | 에이전트 행동으로 보면 |
|---|---|
| Information acquisition | 필요한 외부 지식과 증거를 찾는다 |
| Tool calling | 검색, API, code interpreter, task environment를 호출한다 |
| Executable iteration | 코드를 쓰고 실행하고 실패 로그를 읽은 뒤 수정한다 |
| Evidence verification | 중간 결과와 최종 답을 verifier로 확인한다 |
| Constraint tracking | 긴 context 속에서도 세부 조건과 목표를 잃지 않는다 |
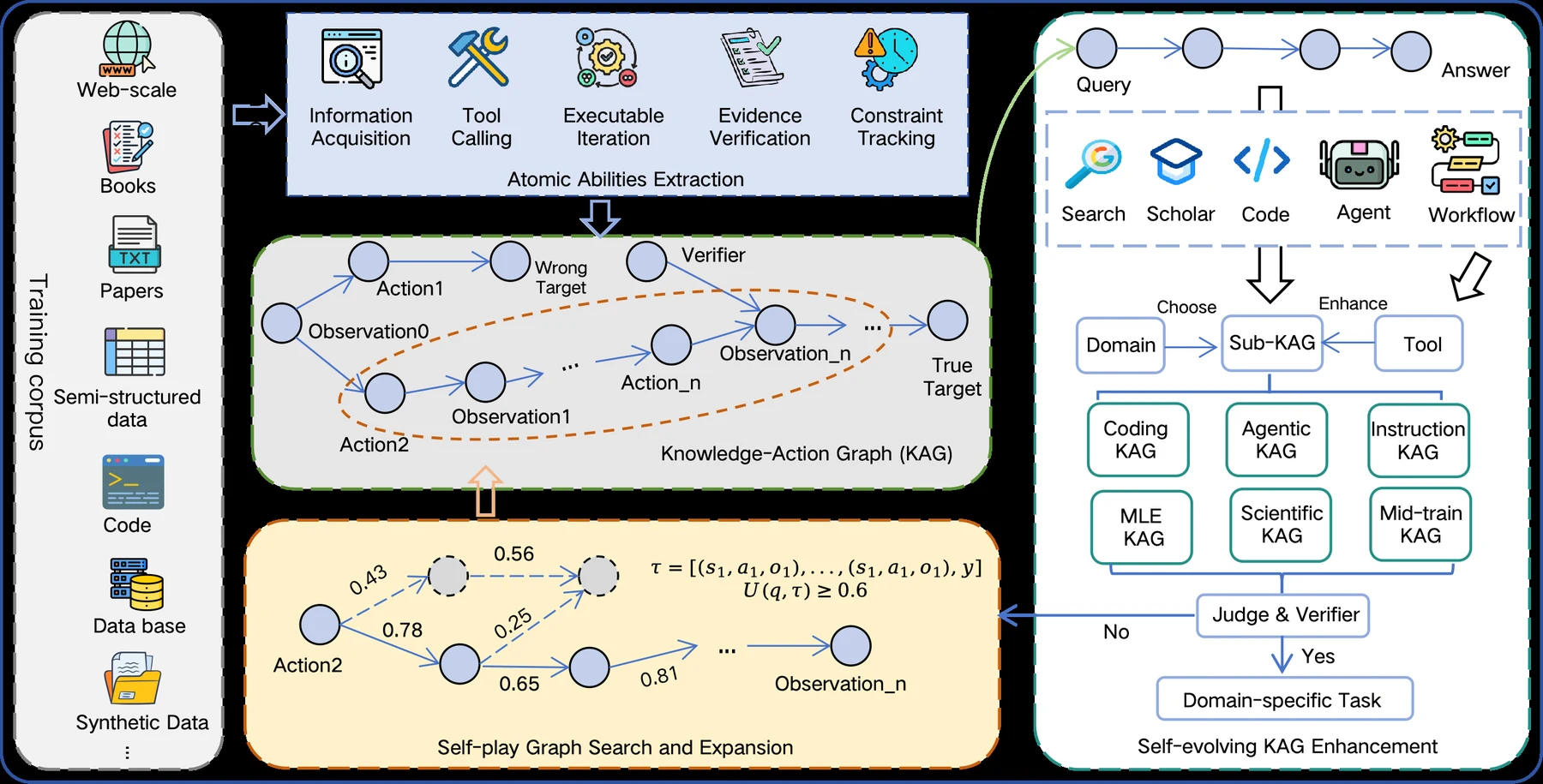
학습 절차는 세 단계다.
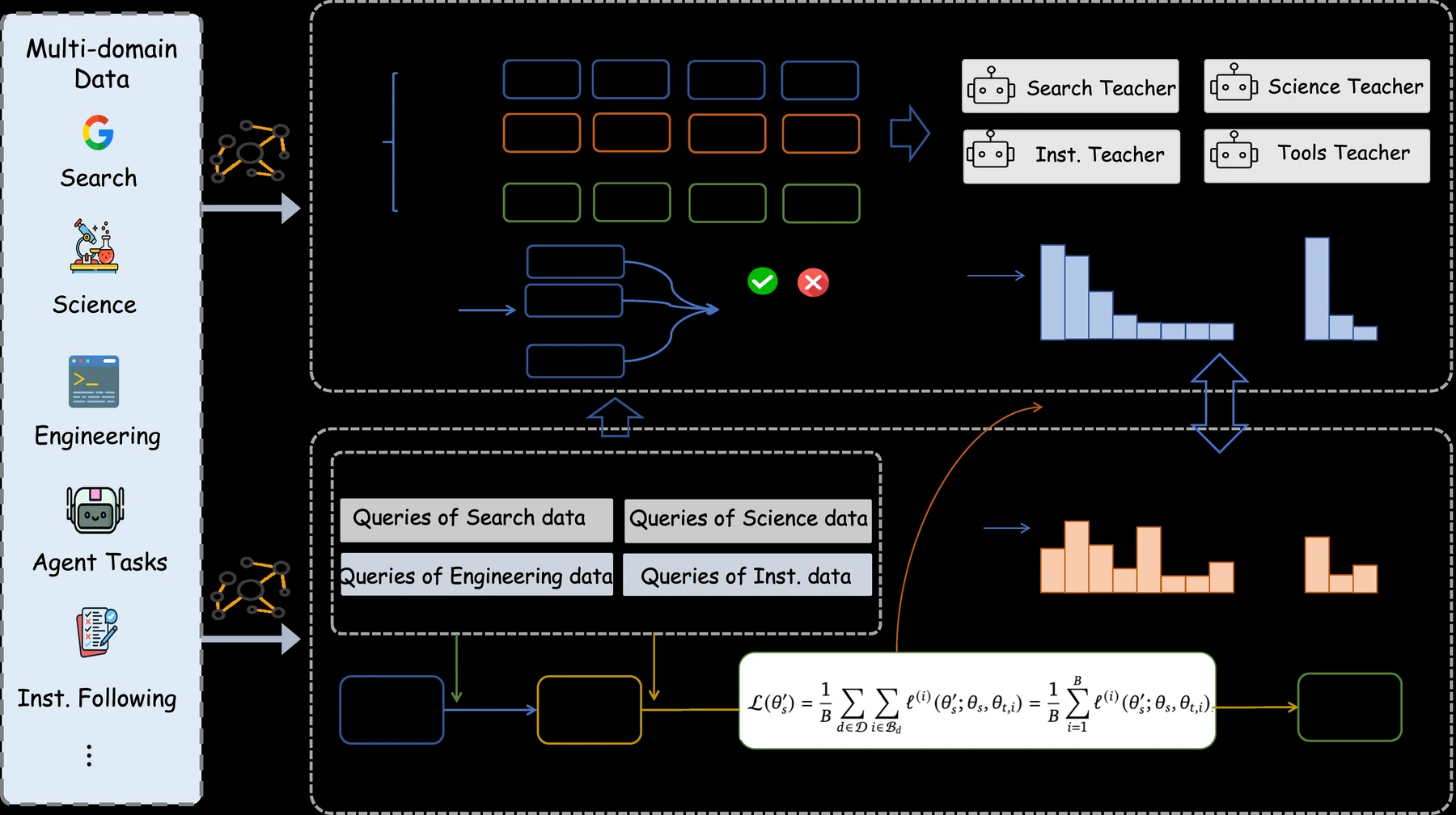
1단계는 full-domain supervised fine-tuning이다.
시작점은 Qwen3.5-35B-A3B이며, 약 100K trajectory를 사용한다.
논문 Table 2 기준 전체 평균 trajectory 길이는 45K tokens이고, domain별로 deep research 44K, coding and engineering 48K, scientific reasoning/problem-solving 37K, instruction following 3K, general agentic tasks 39K로 구성된다.
SFT 설정은 learning rate 1e-5, batch size 16, 1 epoch, max sequence length 131,072, AdamW, weight decay 0.1이다.
2단계는 domain-level teacher training이다.
한 모델에 모든 능력을 한 번에 밀어 넣기보다, long-horizon search, scientific reasoning, instruction following, tool calling 같은 domain별 teacher를 따로 강화한다.
어떤 domain은 SFT만 쓰고, 어떤 domain은 RL을 결합한다.
3단계는 multi-teacher on-policy distillation이다.
학생 모델이 직접 만든 rollout 위에서 teacher의 신호를 받되, domain routing을 통해 어떤 teacher를 참조할지 나누고, salient vocabulary alignment로 중요한 token subset의 분포를 맞춘다.
논문의 의도는 서로 다른 domain의 reasoning pattern이 충돌하지 않도록, teacher ensemble을 무작정 평균내지 않고 domain-normalized objective로 통합하는 것이다.
공개된 근거에서 확인되는 점
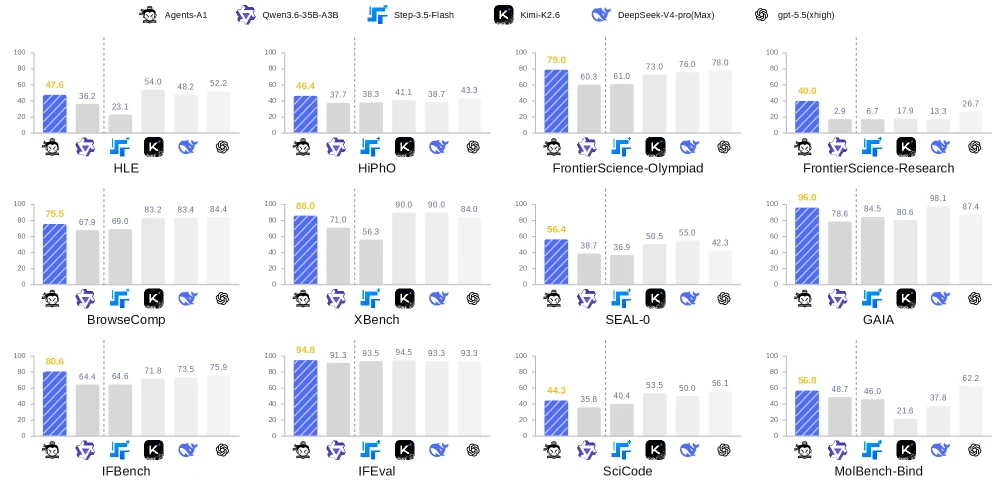
가장 눈에 띄는 결과는 Agents-A1이 일부 long-horizon benchmark에서 1T급 비교 모델보다 높게 보고된다는 점이다.
특히 Seal-0, HiPhO, FrontierScience-Olympiad, FrontierScience-Research, IFBench에서 강한 headline을 만든다.
| Benchmark | Agents-A1 | 논문 표에서의 비교 포인트 | 해석 |
|---|---|---|---|
| Seal-0 | 56.4 | Kimi-K2.6 50.5, DeepSeek-V4-Pro 55.0, GPT-5.5 42.3 | long-horizon search에서 가장 강한 headline 중 하나 |
| IFBench | 80.6 | Kimi-K2.6 71.8, DeepSeek-V4-Pro 73.5, GPT-5.5 75.9 | strict instruction following에서 크게 앞선다고 보고 |
| HiPhO | 46.4 | Kimi-K2.6 41.1, DeepSeek-V4-Pro 38.7, GPT-5.5 43.3 | scientific research 계열의 강한 신호 |
| FrontierScience-Olympiad | 79.0 | Kimi-K2.6 73.0, DeepSeek-V4-Pro 76.0, GPT-5.5 78.0 | 과학 올림피아드형 문제에서 근소 우위 |
| FrontierScience-Research | 40.0 | Kimi-K2.6 17.9, DeepSeek-V4-Pro 13.3, GPT-5.5 26.7 | 연구형 과학 task에서 큰 차이로 보고 |
| BrowseComp | 75.5 | Kimi-K2.6 83.2, DeepSeek-V4-Pro 83.4, GPT-5.5 84.4 | 35B open 비교군 안에서는 강하지만 1T급 모델이 앞선다 |
| SciCode | 44.3 | Kimi-K2.6 53.5, DeepSeek-V4-Pro 50.0, GPT-5.5 56.1 | engineering benchmark에서는 frontier 모델과 격차가 있다 |
| MolBench-Bind | 56.8 | Qwen3.6-35B 48.7, Nex-N2-mini 51.4, GPT-5.5 62.2 | 35B 비교군과 일부 1T 모델보다 높지만 GPT-5.5가 더 높다 |
따라서 이 결과를 읽을 때는 균형이 필요하다.
Agents-A1은 “35B가 모든 1T 모델을 압도했다”가 아니라, 장기 검색·과학 연구·instruction following처럼 horizon supervision이 잘 맞는 영역에서 매우 강한 author-reported 결과를 냈다고 보는 편이 안전하다.
BrowseComp, SciCode, MLE-Bench-Lite, HLE w/ tools처럼 여전히 더 큰 모델이 앞서는 항목도 있다.
논문 내부 ablation도 중요하다.
Table 4에서 Qwen3.5-35B-A3B base, Agents-A1-SFT, 최종 Agents-A1을 비교하면 SFT만으로도 큰 폭의 개선이 나오고, 최종 distillation이 일부 항목을 더 끌어올린다.
예를 들어 BrowseComp는 61.0 → 74.6 → 75.5, Seal-0은 41.4 → 52.3 → 56.4, SciCode는 37.1 → 42.3 → 44.3으로 간다.
반대로 XBench-DS-2510은 SFT 88.0에서 최종 86.0으로 내려간다.
즉 multi-domain 통합은 모든 benchmark를 동시에 단조 증가시키는 마법이 아니라, 서로 다른 domain 능력을 trade-off 속에서 합치는 과정이다.
MLE harness는 장기 에이전트 학습을 꽤 구체적으로 보여준다
Agents-A1 논문에서 특히 실무적으로 흥미로운 부분은 Machine Learning Engineering domain이다.
저자들은 MLE task를 단순 code generation benchmark로 다루지 않고, 코드 작성·패치·실행·tree navigation·answer management·persistent memory·delegated analysis를 가진 harness로 정의한다.
Table 1의 tool interface에는 write_full_code, patch_code, execute_code, execute_bash, list_nodes, select_answer, memorize, analyze 같은 action이 포함된다.
이것은 실제 coding agent가 하는 행동과 꽤 닮아 있다.
새 root node를 열어 다른 접근을 시도하고, patch가 child node를 만들고, 실행 결과와 validation metric이 observation으로 붙고, 실패한 node도 negative evidence로 남는다.
이 부분은 Agents-A1의 메시지를 잘 보여 준다.
에이전트 학습 데이터는 “정답 코드”만으로 충분하지 않다.
어떤 실험을 했고, 어디서 실패했고, 어떤 로그를 보고 어떤 patch를 했고, 어느 답을 commit했는지가 모두 학습 신호가 된다.
이 관점은 coding agent, research agent, AutoML agent를 만드는 팀에게 특히 직접적이다.
공개 릴리스 상태
공개 artifact는 논문만 있는 상태가 아니다.
Hugging Face collection에는 InternScience/Agents-A1, InternScience/Agents-A1-FP8-dynamic, 그리고 arXiv paper가 묶여 있다.
모델 API 조회 시점 기준 InternScience/Agents-A1은 public, ungated, Apache-2.0 tag/cardData를 갖고 있으며, downloads 92, likes 79로 표시됐다.
API 카운터는 변동값이므로 “현재 API 값”으로만 보는 것이 맞다.
모델 패키징도 확인할 만하다.
| 표면 | 확인한 내용 | 실무적 의미 |
|---|---|---|
| Hugging Face model | qwen3_5_moe, Transformers, safetensors, Apache-2.0, ungated |
weight는 공개되어 있고 표준 런타임 연결을 목표로 한다 |
| Weight files | 14개 safetensors shard, index metadata total size 70.216GB | BF16 기준 약 35.1B parameter 규모와 일치한다 |
| Config | 40 layers, 256 experts, token당 8 experts, max_position_embeddings: 262144 |
공식 페이지의 256K served context length와 맞다 |
| Serving docs | SGLang과 vLLM OpenAI-compatible endpoint 예시 제공 | 자가 서빙 경로는 있지만 35B MoE와 256K context를 감당할 인프라가 필요하다 |
| GitHub repo | Apache-2.0, Python 중심, evaluation/Search·MLE·Science·IF·Tools 디렉터리 포함 | 단순 모델 카드가 아니라 평가/사용 문서가 있는 연구 repo다 |
| Release maturity | GitHub tags/releases는 비어 있음 | versioned package라기보다는 초기 연구 릴리스로 보는 편이 안전하다 |
GitHub API 기준 저장소는 2026년 6월 23일 생성됐고, 조회 시점 stars 84, forks 5, default branch main, 최근 push는 2026년 6월 30일이다.
즉 릴리스는 실제 code/model 표면을 갖고 있지만, 아직 semantic versioning이나 release tag로 안정화된 라이브러리라고 보기는 어렵다.
공식 프로젝트 페이지는 Agents-A1을 long-horizon search, engineering, scientific research, instruction following, tool calling을 겨냥한 35B MoE agentic model로 설명한다.
또 SGLang/vLLM 서빙 예시에서 --context-length 262144, --reasoning-parser qwen3, --tool-call-parser qwen3_coder를 사용한다.
이것은 Agents-A1이 일반 chat model만이 아니라 reasoning parser와 tool-call parser를 전제로 한 agent runtime 경로를 염두에 둔 릴리스라는 신호다.
실무 관점에서의 해석
Agents-A1의 가장 큰 의미는 에이전트 성능을 모델 크기 하나로 설명하지 않는 언어를 제공한다는 점이다.
장기 에이전트는 큰 모델을 붙인다고 자동으로 안정적이 되지 않는다.
필요한 것은 외부 지식과 도구, 관찰, 검증 결과가 연결된 trajectory이고, 그 trajectory 안에서 어떤 domain skill이 어떤 방식으로 발현되는지 기록하는 infrastructure다.
특히 세 가지 메시지가 중요하다.
첫째, 장기 trajectory는 단순히 context를 길게 채운 데이터가 아니다.
Agents-A1에서 평균 45K token trajectory는 evidence, action, observation, verifier outcome을 포함한다.
따라서 “long context SFT”라기보다 검증 가능한 agent process supervision에 가깝다.
둘째, domain teacher는 단순 ensemble이 아니다.
검색, 과학 추론, instruction following, tool calling은 좋은 행동 분포가 다르다.
Agents-A1은 domain-routed OPD와 SVA로 이질적인 teacher 신호를 하나의 student에 통합하려 한다.
이 설계는 앞으로 agentic distillation에서 꽤 중요한 패턴이 될 수 있다.
강한 teacher 하나를 고르는 문제보다, 서로 다른 domain teacher를 어떻게 충돌 없이 합칠지가 더 중요해질 수 있기 때문이다.
셋째, benchmark headline은 반드시 항목별로 읽어야 한다.
Agents-A1은 Seal-0, IFBench, HiPhO, FrontierScience 계열에서 강하지만, BrowseComp나 SciCode처럼 1T급 모델이 여전히 앞서는 항목도 있다.
따라서 실무 팀이 이 모델을 검토한다면 “35B로 1T를 대체한다”가 아니라, 장기 agent trajectory 학습이 어떤 task family에서 가장 큰 효용을 내는지를 확인하는 관점이 더 낫다.
한계도 분명하다.
논문 결과는 주로 author-reported benchmark와 자체 평가 protocol에 의존한다.
공개 repo와 모델은 유용하지만 tags/releases가 없어 아직 안정화된 제품형 package는 아니다.
또한 35B MoE와 256K context self-hosting은 여전히 큰 GPU·메모리·서빙 비용을 요구한다.
마지막으로, 에이전트 모델은 도구와 외부 환경에 직접 행동하므로 실제 배포에서는 sandboxing, 권한 제한, human approval, audit log가 필수다.
그래도 방향은 흥미롭다.
에이전트가 점점 더 긴 작업을 맡게 될수록, 단순히 더 큰 모델을 호출하는 것만으로는 부족하다.
어떤 evidence를 봤고, 어떤 action을 했고, 어떤 observation을 받았고, 어떤 verifier가 통과/실패를 말했는지를 데이터 구조로 남기는 능력이 중요해진다.
Agents-A1은 그 과정을 35B 공개 모델과 연결했다는 점에서, agentic model training의 다음 기준선을 꽤 선명하게 제시한다.