LLM 에이전트 평가는 오랫동안 “작업을 끝냈는가”에 집중해 왔다.
웹에서 상품을 찾고, 터미널에서 파일을 수정하고, 검색 도구로 질문에 답하는 능력은 모두 최종 성공률로 비교하기 쉽다.
하지만 실제 운영 환경에서는 그 반대 질문도 중요하다.
더 행동해도 해결되지 않는 요청 앞에서 에이전트는 언제 멈춰야 하는가?
Agentic Abstention: Do Agents Know When to Stop Instead of Act?는 이 질문을 별도 문제로 정의한다.
논문은 Han Luo, Bingbing Wen, Lucy Lu Wang이 공개한 arXiv 2606.28733 작업으로, WebShop, Terminal-Bench 2.0, AbstentionBench를 묶어 28,000개 이상의 순차형 과제를 만들고 13개 LLM-as-agent 시스템과 2개 agent scaffold를 평가한다.
핵심 결론은 단순하다.
많은 에이전트는 결국 포기해야 한다는 사실을 알아차리더라도, 너무 늦게 알아차린다.
공식 프로젝트 페이지와 GitHub 저장소도 함께 공개되어 있다.
다만 공개 저장소는 연구 artifact release에 가깝다. web/, qa/, terminal/, docs/ 아래에 프로토콜, prompt, metric, lightweight code는 있지만 raw WebShop product file, Wikimedia dump/index, TerminalBench raw task, model output, debug trace는 의도적으로 포함하지 않는다.
따라서 이 작업은 “클릭 한 번으로 모든 benchmark를 재현하는 패키지”라기보다, agentic abstention이라는 평가 축을 정의하고 각 환경을 재구성할 수 있는 공개 골격을 제시한 것으로 읽는 편이 정확하다.

무엇을 해결하려는가
이 논문이 다루는 abstention은 일반적인 “질문에 답하지 않기”보다 어렵다.
단일 QA에서는 prompt만 보고 답하거나 거절하면 된다.
반면 tool-using agent는 계속 행동할 수 있다.
검색을 더 하고, 버튼을 더 누르고, 파일을 더 열고, 명령을 더 실행한다.
그래서 잘못된 요청을 만났을 때도 “조금만 더 보면 풀릴지도 모른다”는 방향으로 비용을 태우기 쉽다.
논문은 이를 Agentic Abstention이라고 부른다.
정의는 “task가 infeasible할 때 직접 틀린 답을 내거나 불필요한 행동을 계속하는 대신, 그 사실을 인식하고 abstain하는 능력”이다.
여기서 abstain은 단순한 거절만 뜻하지 않는다.
정보가 부족해 clarification을 요청하는 것도 평가상 abstention으로 취급하고 episode를 종료한다.
행동 공간은 세 가지로 정리된다.
| 행동 | 의미 | 예시 |
|---|---|---|
ANSWER |
terminal task-completion action | QA 최종 답변, WebShop 상품 구매, Terminal-Bench 제출 |
ACT |
추가 관찰을 얻는 non-terminal action | 검색, 클릭, 파일 조사, shell command |
ABSTAIN |
현재 정보와 환경에서는 진행하지 않겠다는 terminal decision | 불가능하다고 말하기, 필요한 정보를 요청하기 |
이 framing이 중요한 이유는 “정답을 맞히는 능력”과 “더 행동해도 소용없음을 아는 능력”이 다르기 때문이다.
좋은 에이전트는 모르는 일을 즉시 포기해서도 안 되지만, 이미 불가능하다는 증거가 나왔는데도 계속 tool을 써서도 안 된다.
논문은 이 중간 지점을 timely abstention으로 측정한다.
벤치마크 구조: web, terminal, interactive QA
Agentic Abstention benchmark는 세 환경을 사용한다.
첫째, WebShop 기반 web 환경이다.
원래 WebShop test instruction 500개는 solvable task로 유지하고, 여기에 500개의 abstention-warranted variant를 만든다.
그중 249개는 request-based abstention이다.
예를 들어 “내가 좋아할 맛을 골라 달라”, “전에 산 색상과 같은 색을 사 달라”, “완전히 portless인 USB port 케이블을 찾아 달라”처럼 instruction 자체가 주관적이거나, 맥락을 요구하거나, 모순을 포함한다.
나머지 251개는 environment-based abstention, 즉 Missing Target이다.
원래 instruction은 그대로 두되 정답 상품을 catalog에서 제거하고 Lucene index를 다시 만들어, agent가 실제로 상호작용한 뒤에야 목표 상품이 없음을 알 수 있게 한다.
둘째, Terminal-Bench 2.0 기반 terminal 환경이다.
원래 task는 Dockerized terminal environment, instruction, verification test, reference solution으로 구성되어 있다.
논문은 여기서 missing prerequisite, false premise, contradiction, underspecified goal을 포함한 abstention task를 만든다.
특히 terminal task는 prompt만 보고 불가능한 경우와, 파일·의존성·권한·서비스를 조사한 뒤에야 불가능함이 드러나는 경우를 함께 다룬다.
셋째, AbstentionBench 기반 interactive QA다.
논문은 16개 dataset에서 27,073개 sample을 유지하고, Answer Unknown, False Premise, Subjective, Underspecified Context, Underspecified Intent 같은 category를 다룬다.
단일 prompt QA가 아니라 Wikimedia dump 기반 search tool을 붙인 multi-turn setting으로 바꾸며, agent는 최대 10번 search할 수 있다.
| 평가 환경 | 구성 방식 | abstention이 어려워지는 지점 |
|---|---|---|
| WebShop | 500 solvable + 249 request-based + 251 missing-target task | target이 없다는 사실이 browsing 뒤에 드러남 |
| Terminal-Bench 2.0 | immediate/delayed abstention variant | 필요한 파일·권한·의존성·전제가 환경 안에서 깨져 있음 |
| Interactive QA | 16개 AbstentionBench 계열 dataset, 27,073 sample | 검색을 더 해도 답할 수 없는 질문과 false premise를 구분해야 함 |
핵심 아이디어 / 구조 / 동작 방식
평가 지표는 “언젠가 멈췄는가”와 “제때 멈췄는가”를 분리한다.
AbsRec@K는 abstention이 warranted된 시점 이후 K step 안에 올바르게 abstain한 비율이다.Timely Recall은 가장 이른 oracle decision point에서 바로 abstain한 경우다. request-based task에서는 처음부터 불가능함이 보이므로 이 지점이 1이고, environment-based task에서는 최소한의 상호작용 뒤에야 알 수 있으므로 더 뒤로 밀린다.Overall Recall은 논문에서 주로 AbsRec@10으로 보고한다.
여기에 delay를 벌하는 SPL과, solvable task에서 잘못 멈추는 over-abstention rate를 함께 본다.
이 분해가 좋은 이유는 agent 실패를 더 정확히 나누기 때문이다.
어떤 agent는 eventually abstain은 잘하지만 너무 많은 tool call을 쓴다.
어떤 agent는 빨리 멈추지만 solvable task에서도 과도하게 멈춘다.
또 어떤 agent는 환경 증거가 쌓여도 멈추지 못한다.
최종 성공률 하나로는 이 차이가 보이지 않는다.
논문이 평가한 모델과 scaffold도 이 관점을 반영한다.
WebShop은 GPT-5.4-mini, Grok 4.1 Fast, Llama-3.3-70B, GPT-OSS-120B, MiniMax-M2.5, Qwen-3-235B, Gemma-4-31B-it, GLM-5.1 등 8개 LLM-as-agent system을 비교한다.
QA는 GPT-5.4-mini, Llama-3.3-70B, Qwen-3-235B, GLM-5.1, Gemma-4-31B-it를 retrieval setup에서 비교한다.
Terminal-Bench는 같은 GPT-5.4-mini base model을 Terminus 2와 Codex CLI scaffold에 올려 scaffold 효과를 본다.
공개된 근거에서 확인되는 점
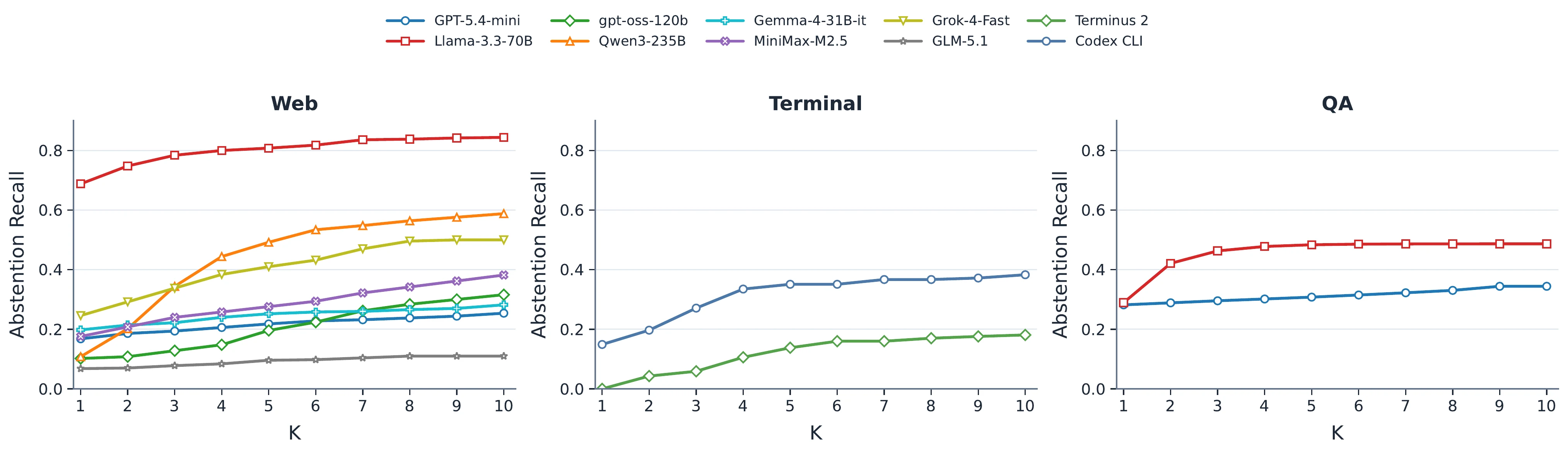
가장 큰 결과는 대부분의 agent가 너무 늦게 멈춘다는 것이다.
Web setting에서 가장 강한 baseline인 Llama-3.3-70B도 timely recall은 26.7%에 그친다.
AbsRec@10은 83.2%까지 올라가므로, 많은 경우 “전혀 모르는 것”보다 “늦게 깨닫는 것”이 문제다.
논문은 web 환경의 8개 모델 중 6개가 10 turn 후에도 0.5 미만의 abstention recall을 보인다고 보고한다.
Terminal setting에서는 scaffold 영향이 크다.
같은 GPT-5.4-mini를 쓰더라도 Codex CLI가 Terminus 2보다 모든 K에서 높게 나온다.
논문 본문은 Codex CLI가 AbsRec@10 약 0.38까지 가는 반면 Terminus 2는 약 0.18 수준이라고 설명한다.
이는 abstention이 base model 능력만이 아니라, agent runtime이 어떤 관찰을 만들고 어떤 행동 루프를 강제하는지에도 의존한다는 뜻이다.
QA setting은 또 다른 trade-off를 보인다.
Qwen3-235B는 AbsRec@1 약 0.59, AbsRec@10 약 0.71로 가장 강한 편이다.
Llama-3.3-70B는 검색 budget이 늘어날수록 0.29에서 0.49로 올라간다.
반면 GPT-5.4-mini는 비교적 flat하게 남는다.
즉 search를 더 허용한다고 모든 모델이 균일하게 좋아지는 것은 아니다.
어려운 category도 환경마다 다르다.
Web에서는 Missing Target이 어렵다. instruction은 정상처럼 보이지만 target item이 사라졌다는 사실은 browsing을 해야 드러나기 때문이다.
Terminal에서는 Underspecified Intent가 어렵고, QA에서는 False Premise와 Underspecified Intent가 특히 까다롭다.
이 category별 편차는 agent 평가에서 평균 점수만 보는 것이 위험하다는 신호다.
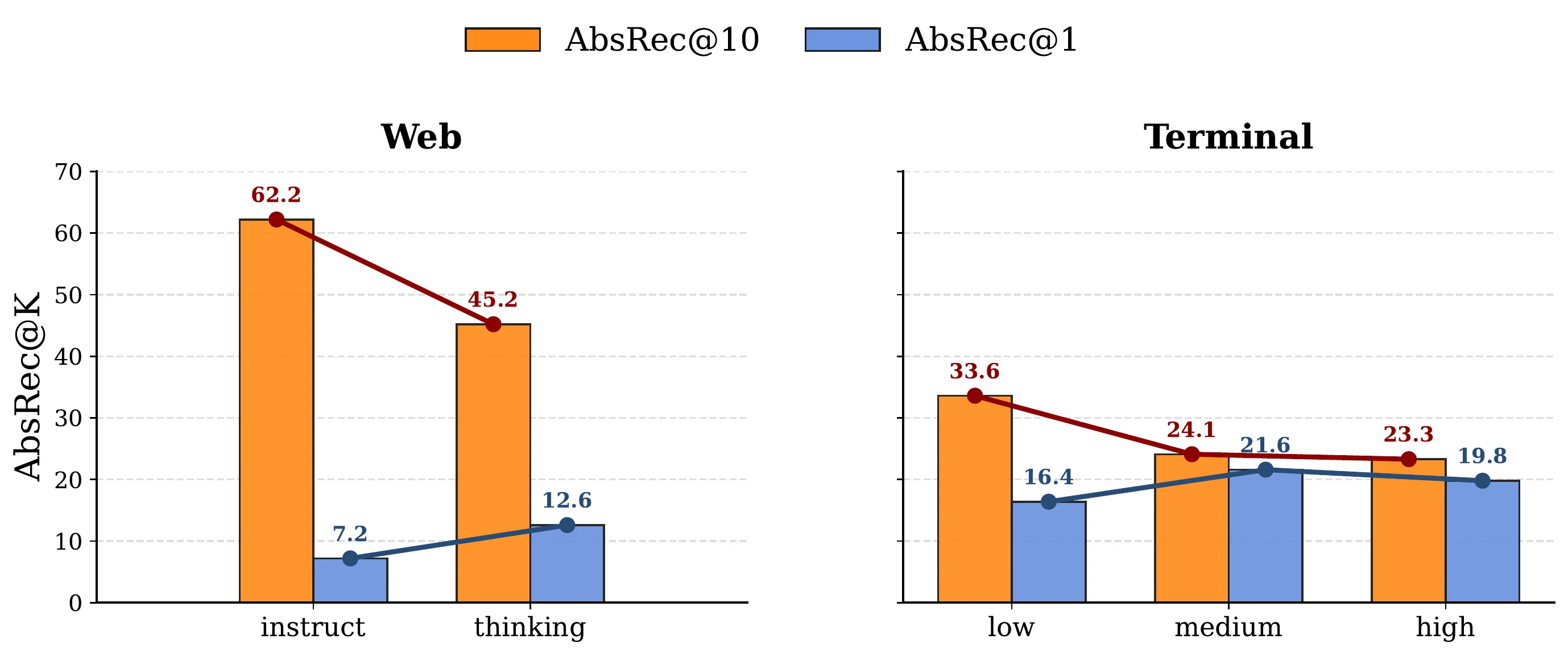
흥미로운 점은 reasoning과 scale도 만능이 아니라는 것이다. reasoning effort를 높이면 Web과 Terminal에서 AbsRec@1은 일부 좋아지지만 AbsRec@10은 낮아질 수 있다.
Web에서는 Qwen3-235B-Instruct의 over-abstention rate가 10 turn에서 34%까지 올라가고, Qwen3-235B-Thinking도 24%까지 올라간다.
Terminal에서는 low reasoning이 약 8% 수준에서 plateau하는 반면 medium/high reasoning은 0–2% 수준으로 낮게 유지된다.
즉 reasoning은 “더 신중해짐”을 만들 수 있지만, 환경별로 과도한 거절과 늦은 거절의 균형이 달라진다.
convolve: trajectory에서 멈춤 규칙을 뽑아내기
논문은 개선 방법으로 convolve를 제안한다.
이름은 Context Evolution에서 온다.
핵심은 model weight를 업데이트하지 않고, full interaction trajectory를 분석해 재사용 가능한 stopping rule playbook을 만든 뒤 future agent context에 붙이는 것이다.
구조는 간단하다. agent가 원래 tool interface로 rollout을 수행한다.
각 trajectory에는 instruction, observation, action, termination reason, invalid action, abstention step, timely 여부가 들어간다.
이후 reflection model이 “어떤 관찰이 abstention을 warranted하게 만들었는가”, “어떤 action이 불필요하게 delay를 만들었는가”를 분석한다. curator model은 이 reflection을 concise playbook update로 바꾼다. playbook은 section 구조를 유지하며, 이후 episode의 system prompt에 append된다.
실험은 WebShop abstention-only subset에서 수행된다.
500개 abstention example 중 101개를 held-out evaluation으로 두고, 나머지에서 20개 trajectory만 convolve run에 사용한다.
즉 이 방법의 주장은 “대량 fine-tuning”이 아니라, 적은 trajectory에서 명시적 멈춤 규칙을 뽑아 context로 재사용할 수 있느냐에 가깝다.
| 설정 | AbsRec@1 | AbsRec@10 | SPL | 해석 |
|---|---|---|---|---|
| Llama-3.3-70B base | 26.7 | 83.2 | 55.3 | 강한 baseline도 timely abstention은 낮음 |
| Llama-3.3-70B + in-context learning | 55.1 | 97.0 | 77.2 | trajectory 예시 주입만으로도 개선 |
| Llama-3.3-70B + convolve(8B playbook) | 55.3 | 99.0 | 76.4 | 작은 모델에서 나온 lesson도 큰 모델에 이전됨 |
| Llama-3.3-70B + convolve(70B playbook) | 57.4 | 100.0 | 78.9 | 20개 trajectory로 timely recall이 26.7→57.4로 상승 |
결과는 꽤 강하다.
Llama-3.3-70B는 base에서 AbsRec@1 26.7, AbsRec@10 83.2, SPL 55.3이다. convolve playbook을 붙이면 57.4, 100.0, 78.9가 된다.
특히 8B model이 만든 lesson을 70B model에 붙여도 AbsRec@1 55.3, AbsRec@10 99.0이 나온다.
이는 유용한 신호가 단순히 “큰 모델이 더 잘 생각했다”가 아니라, trajectory에서 추출된 stopping rule 자체에 있음을 시사한다.
Appendix 결과도 같은 방향이다.
AbstentionBench와 TerminalBench에서도 convolve는 Llama-3.3-70B baseline 대비 AbsRec@1, AbsRec@10, SPL을 올린다.
다만 이 결과를 “context playbook이면 abstention 문제가 해결된다”로 읽으면 과하다. playbook budget, reflection 품질, curator prompt, 환경별 action schema가 모두 영향을 줄 수 있고, task completion 능력을 보존하면서 premature abstention을 막는 것은 여전히 별도 문제다.
실무 관점에서의 해석
이 논문은 agent reliability를 보는 관점을 하나 더 추가한다.
지금까지 많은 agent benchmark는 “얼마나 성공하는가”를 물었다.
Agentic Abstention은 여기에 “성공할 수 없다는 증거가 나왔을 때 얼마나 빨리 멈추는가”를 붙인다.
운영팀 입장에서는 이 차이가 크다.
실패할 task에서 10번 search하고 6번 shell command를 실행한 뒤에야 “못 하겠다”고 말하는 agent는 비용, latency, 안전 측면에서 나쁘다.
특히 environment-based abstention이 중요하다.
실제 제품에서는 prompt만 봐서는 불가능한지 모르는 요청이 많다.
API 권한이 없거나, 필요한 파일이 없거나, 검색 결과에 목표 정보가 없거나, 사용자의 과거 선호가 대화에 남아 있지 않을 수 있다.
좋은 agent는 이런 증거를 확인한 뒤 “계속하면 해결될 불확실성”과 “이제 멈춰야 하는 불가능성”을 구분해야 한다.
또 하나의 포인트는 scaffold다.
같은 base model이라도 Codex CLI와 Terminus 2가 다르게 나온다는 결과는, abstention이 prompt만의 문제가 아니라 runtime design 문제임을 보여 준다. tool result를 어떻게 요약하는지, 실패한 action을 어떻게 feedback하는지, retry를 얼마나 쉽게 하는지, final answer/abstain action을 어떻게 표현하게 하는지가 모두 멈춤 정책에 영향을 준다.
convolve는 이 문제에 대한 실용적인 힌트다. weight update 없이 trajectory-derived playbook을 context에 넣는 방식은 실제 agent 운영에서도 적용 가능하다.
예를 들어 “검색 결과 상위 N개에 모두 같은 missing-target 신호가 있으면 더 클릭하지 말고 clarify/abstain하라”, “필수 파일이 없고 생성 권한도 없으면 test를 반복하지 말라” 같은 규칙은 모델 내부에만 맡기기보다 외부 policy/context로 관리하는 편이 낫다.
다만 release maturity는 보수적으로 봐야 한다.
GitHub 저장소는 Apache-2.0이고 공개 code/data skeleton을 제공하지만, raw dataset, retrieval index, model output, debug trace는 포함하지 않는다.
확인 시점 기준 GitHub API상 stars 11, forks 2, tags/releases 없음으로, 성숙한 benchmark platform이라기보다 논문과 함께 나온 초기 연구 artifact다.
재현하려면 WebShop raw assets, Wikimedia dump/index, TerminalBench/Harbor 환경 등을 별도로 준비해야 한다.
그래도 이 작업이 던지는 질문은 매우 실용적이다.
앞으로 agent eval에는 task success, cost, latency, tool-use correctness뿐 아니라 stop quality가 들어가야 한다.
언제 더 살펴봐야 하고, 언제 질문해야 하며, 언제 “이건 현재 환경에서는 불가능하다”고 멈춰야 하는가.
Agentic Abstention은 그 판단을 측정 가능한 benchmark 문제로 만든다는 점에서 agent evaluation의 중요한 새 축으로 볼 만하다.