비디오 이해 벤치마크에서 모델이 높은 점수를 받았다고 해서 곧바로 “시간을 따라 추론한다”고 말하기는 어렵다.
어떤 문제는 여러 프레임을 훑어 보며 물체를 인식하면 풀리고, 어떤 문제는 장면 전체의 분위기나 언어적 prior만으로도 맞출 수 있다.
하지만 컵 속 공이 여러 번 섞일 때 마지막 위치를 추적하거나, 순서대로 점등된 키보드 글자를 복원하거나, 움직이는 궤적의 교차점을 세는 일은 다르다.
모델은 보이는 상태를 기억하고, 그 상태를 매 순간 갱신하고, 여러 조각의 시간 증거를 합쳐야 한다.
Video-MME-Logical: A Controlled Diagnostic Benchmark for Video Temporal-Logical Reasoning은 이 좁은 능력을 따로 떼어 평가하려는 논문이다.
핵심은 자연 비디오의 복잡성을 더하는 것이 아니라, 절차적으로 생성한 통제된 비디오에서 시간-논리 연산 자체를 분해해 보는 것이다.
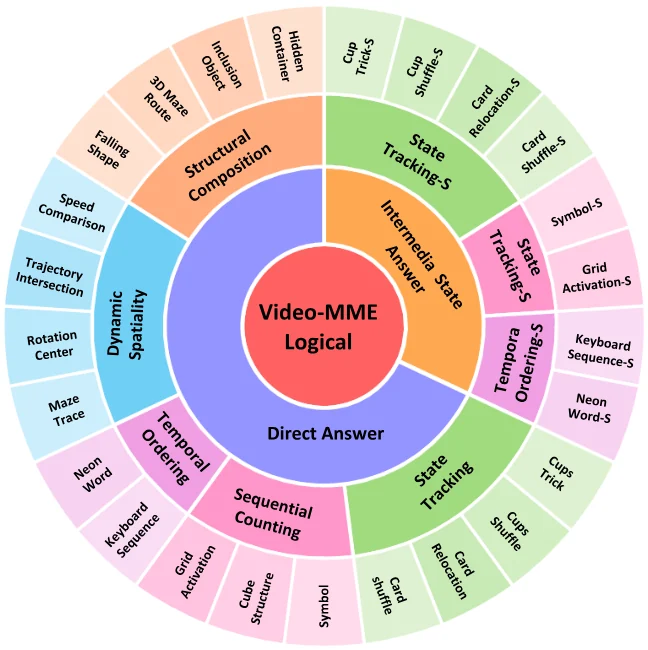
논문은 5개 operation group, 25개 fine-grained task, easy/medium/hard 난이도, 그리고 8개 중간 상태 진단 subset을 묶어 Video-MME-Logical을 만든다.
가장 눈에 띄는 결과는 단순하다.
사람은 전체 test에서 95.9%를 맞췄지만, 가장 강한 평가 모델인 Gemini-3.1 Pro는 28.6%에 머물렀다.
격차는 67.3%p다.
더 엄격한 중간 상태 subset인 Video-MME-Logical-S에서는 GPT-5.4가 17.4%로 가장 높았지만, 사람 96.1%와의 격차는 78.7%p다.
즉 현재 MLLM은 “비디오를 볼 수 있다”와 “시간에 따라 상태를 추적하며 논리적으로 업데이트할 수 있다” 사이에서 아직 큰 간극을 보인다.
무엇을 해결하려는가
논문이 겨냥하는 문제는 기존 video benchmark가 시간 추론을 너무 넓게 섞어 측정한다는 점이다.
자연 비디오는 현실적이지만, 모델이 틀렸을 때 이유를 분해하기 어렵다.
장면이 복잡해서 틀렸는지, 물체를 못 봐서 틀렸는지, 질문 문장이 애매했는지, 아니면 정말로 시간에 따른 상태 업데이트를 못 했는지가 한 점수 안에 섞인다.
Video-MME-Logical은 이 문제를 세 가지 진단 축으로 정리한다.
| 기존 평가의 빈틈 | Video-MME-Logical의 설계 | 왜 중요한가 |
|---|---|---|
| reasoning category가 모호함 | 5개 temporal-logical operation으로 task를 분류 | 실패가 “어떤 시간 연산”에서 났는지 볼 수 있음 |
| 난이도가 장면 복잡도와 같이 움직임 | temporal horizon과 reasoning complexity를 절차적으로 조절 | easy/medium/hard 차이를 해석 가능하게 만듦 |
| 최종 답만 평가함 | Video-MME-Logical-S에서 중간 상태 trace를 exact match로 평가 | 정답을 맞혀도 잘못된 과정을 거쳤는지 드러냄 |
저자들이 드는 직관적인 예시는 shell game이다.
사람은 컵이 몇 번 섞여도 공의 hidden state를 계속 갱신한다.
반면 현재 MLLM은 각 프레임에서 보이는 물체나 움직임을 인식하는 데는 강해졌지만, “공이 마지막으로 어느 컵 아래에 있어야 하는가”처럼 보이지 않는 상태를 장기적으로 유지하는 능력은 아직 약하다.
논문의 표현을 빌리면, multi-frame input을 모으는 것과 시간에 따른 논리를 실행하는 것은 같지 않다.
핵심 아이디어 / 구조 / 동작 방식
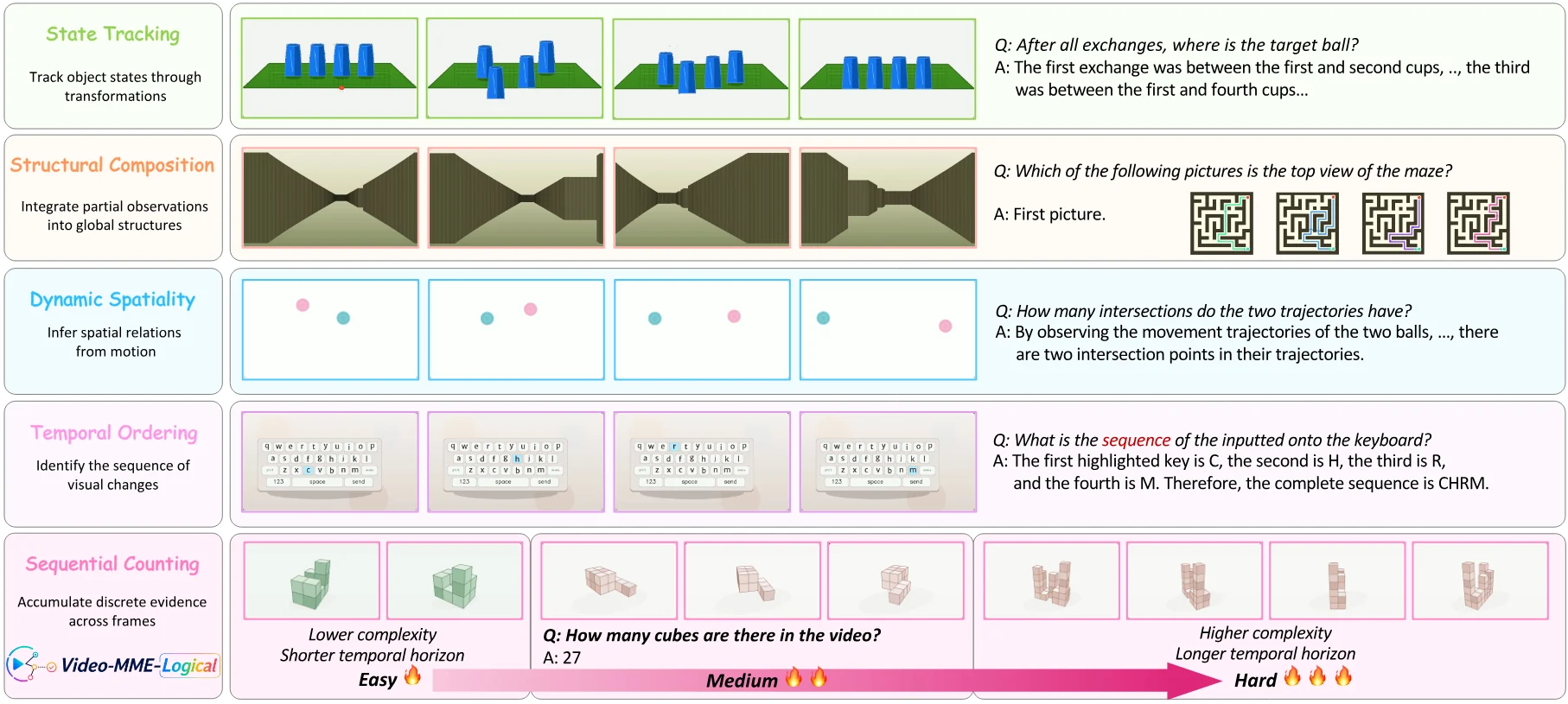
벤치마크는 25개 task category를 5개 operation group 아래에 둔다.
각 task는 executable program으로 정의되고, 프로그램은 temporal transition, scene configuration, metadata construction, video rendering을 생성한다.
이 metadata가 핵심이다.
모델에게는 비디오와 질문만 주지만, 평가자는 프로그램이 기록한 정답·중간 상태·난이도 정보를 갖고 있기 때문에 final answer와 reasoning trace를 재현 가능하게 채점할 수 있다.
다섯 operation group은 다음처럼 읽으면 된다.
| Operation group | 평가하려는 능력 | 예시 task |
|---|---|---|
| State Tracking | 가려진 대상이나 latent state를 시간에 따라 유지·갱신 | Cup Trick, Cup Shuffle, Card Relocation |
| Sequential Counting | 여러 시점에 흩어진 discrete evidence를 누적 | Symbol count, Grid Activation, Cube Structure Count |
| Temporal Ordering | 순서대로 드러나는 이벤트·글자·상태 변화를 복원 | Keyboard Sequence, Neon Word |
| Dynamic Spatiality | 움직임과 공간 관계를 함께 추론 | Maze Trace, Rotation Center, Trajectory Intersection, Speed Comparison |
| Structural Composition | 시점·가림·부분 관찰을 합쳐 구조를 재구성 | Falling Shape Count, 3D Maze Route, Occlusion Object Count |
전체 규모는 503,750개 비디오다.
그중 500K는 training split이고, test는 3,750개다. test set은 25개 category × 3개 difficulty로 구성되며, 8개 category는 중간 상태를 따로 검사하는 Video-MME-Logical-S subset을 제공한다.
Hugging Face dataset 공개본은 평가용 3,750개 sample, 3,750개 video, 900개 image를 담은 video_mme_logical.zip 형태로 올라와 있다.
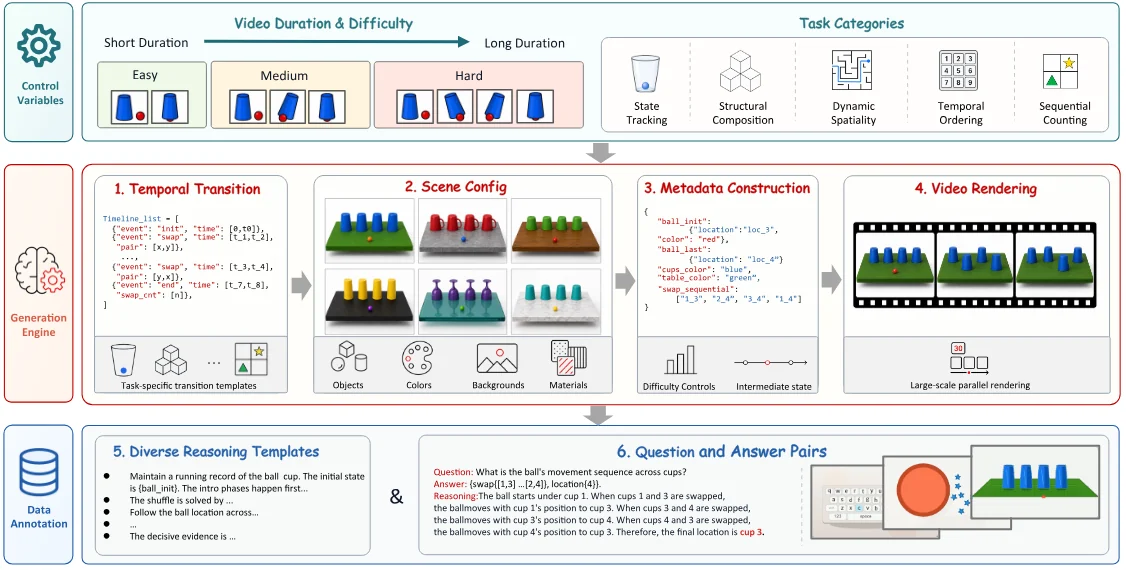
난이도는 category마다 temporal horizon과 reasoning complexity를 늘리는 방식으로 조절된다.
예를 들어 cup tracking에서는 easy video가 10초, hard video가 20초이고, swap 수는 4회에서 8회로 늘어난다.
이런 설정은 “hard가 왜 hard인지”를 설명할 수 있게 한다.
자연 비디오 benchmark에서는 hard sample이 더 지저분한 배경, 더 어려운 언어, 더 작은 물체 때문에 어려울 수 있지만, 여기서는 시간 길이와 논리 단계 수가 직접 증가한다.
평가 metric은 exact-match accuracy다.
Multiple-choice는 answer tag에서 선택지를 뽑아 정답과 맞는지 보고, fill-in은 숫자·문자열·JSON 스타일 답이 exact match인지 본다.
Video-MME-Logical-S에서는 모델이 출력한 중간 정보도 canonicalize한 뒤 program-recorded state와 exact match로 비교한다.
이것은 꽤 엄격하지만, 이 논문의 목적이 “그럴듯한 설명”보다 “정확한 temporal state trace”를 진단하는 데 있기 때문에 일관된 선택이다.
공개된 근거에서 확인되는 점
공개 표면은 논문, 프로젝트 페이지, GitHub 저장소, Hugging Face dataset으로 나뉜다.
논문은 arXiv 2606.27828v1로 2026년 6월 26일 제출됐고, 프로젝트 페이지는 overview/taxonomy/pipeline/leaderboard/예시 비디오 gallery를 제공한다.
GitHub 저장소는 Mrakas/video-mme-logical이며 README와 eval.py, 프로젝트 페이지 자료를 포함한다.
README에는 “code, dataset release instructions, evaluation scripts are being organized”라고 되어 있어, 현 시점의 저장소는 완성형 training/evaluation suite라기보다 공식 공개 entry와 lightweight evaluation entrypoint에 가깝다.
| 공개 표면 | 확인한 내용 | 해석 |
|---|---|---|
| arXiv | 2606.27828v1, cs.CV, 2026-06-26 제출 |
논문 identity와 표/그림의 기준 |
| 프로젝트 페이지 | overview, taxonomy, construction pipeline, leaderboard, sample video gallery 제공 | paper-only가 아니라 interactive release page가 있음 |
| GitHub | Mrakas/video-mme-logical, MIT license, README.md, eval.py, docs/, CITATION.cff |
공식 entry는 공개됐지만 model checkpoint는 TODO로 남아 있음 |
| Hugging Face Dataset | marcuskwan/video-mme-logical, CC-BY-4.0 tag, 3,750 sample / 3,750 video / 900 image |
test benchmark package가 공개돼 있음 |
GitHub API 조회 기준 저장소는 public이고, created_at은 2026-06-19, pushed_at은 2026-06-30, stars 2, forks 0, open issues 1이었다.
HF dataset API 기준 dataset은 gated가 아니며, SHA는 e4efe750e224432d7af88e653ff447b38a14d0f9, lastModified는 2026-06-29다.
즉 논문과 함께 벤치마크 데이터는 공개됐지만, README의 release TODO에는 model checkpoint가 아직 coming soon으로 남아 있다.
결과: 사람은 풀지만 모델은 거의 못 푼다
메인 테이블에서 가장 강한 final-answer 모델은 Gemini-3.1 Pro다.
전체 정확도는 28.6%, easy 33.1%, medium 24.1%, hard 20.6%다.
GPT-5.4는 전체 22.7%다. open-source 모델 중에서는 Qwen2.5-VL-72B-Instruct가 12.5%, InternVL3.5-8B-Instruct가 12.1%, Qwen3-VL-8B-Instruct가 11.9% 정도다.
사람 95.9%와 비교하면 벤치마크가 사람에게는 풀리는 반면 모델에게는 매우 어렵다는 뜻이다.
| 모델 / 그룹 | Overall | Easy | Medium | Hard | 관찰 포인트 |
|---|---|---|---|---|---|
| Human Level | 95.9 | 98.4 | 95.9 | 93.4 | 사람 기준으로는 solvable한 task |
| Gemini-3.1 Pro | 28.6 | 33.1 | 24.1 | 20.6 | final-answer 기준 최고 모델 |
| GPT-5.4 | 22.7 | 31.7 | 20.3 | 16.1 | hard에서 16.1%까지 하락 |
| Qwen2.5-VL-72B-Instruct | 12.5 | 15.2 | 13.1 | 9.1 | 공개 instruct 모델 중 상위권 |
| InternVL3.5-8B-Instruct | 12.1 | 13.8 | 13.5 | 8.9 | hard에서 한 자릿수 |
| Qwen3-VL-30B-A3B-Think | 10.3 | 16.0 | 8.7 | 6.1 | thinking variant가 항상 좋아지지 않음 |
특히 난이도 증가에 따른 하락이 중요하다.
GPT-5.4는 easy 31.7%에서 hard 16.1%로 15.6%p 떨어지고, Gemini-3.1 Pro도 easy 33.1%에서 hard 20.6%로 12.5%p 떨어진다.
절대 점수가 이미 낮은 상황에서 hard 성능이 더 낮아지는 것은, temporal horizon과 reasoning complexity가 길어질수록 상태 유지·갱신이 불안정해진다는 해석과 잘 맞는다.
또 하나 흥미로운 점은 “thinking” label이 만능이 아니라는 점이다.
KimiVL-16B-A3B는 instruct 2.9%에서 thinking 7.6%로 오르지만, Qwen3-VL-8B는 instruct 11.9%에서 think 6.6%로 내려간다.
Qwen3-VL-30B-A3B도 instruct 11.8%에서 think 10.3%로 낮아진다.
논문의 해석은 명확하다. reasoning trace를 길게 생성하는 것만으로는 부족하고, 그 trace가 실제 visual evidence에 grounding되어야 한다.
중간 상태 진단이 보여 주는 것
Video-MME-Logical-S는 final answer만으로는 보이지 않는 실패를 드러낸다.
GPT-5.4와 Gemini-3.1 Pro의 final-answer 점수만 보면 Gemini가 더 강해 보이지만, 중간 상태 subset에서는 GPT-5.4가 overall 17.4%로 Gemini-3.1 Pro의 10.8%보다 높다. strongest open-source 모델인 Qwen3-VL-30B-A3B-Think는 3.6%다.
GPT-5.4의 17.4%는 이 공개 모델 대비 약 4.83배지만, 여전히 사람 96.1%와는 큰 차이가 난다.
| 모델 / 그룹 | Video-MME-Logical-S Overall | Easy | Medium | Hard | 관찰 포인트 |
|---|---|---|---|---|---|
| Human Level | 96.1 | 98.5 | 96.0 | 93.8 | 중간 상태도 사람이 안정적으로 복원 |
| GPT-5.4 | 17.4 | 30.8 | 13.7 | 7.7 | 중간 상태 기준 최고 모델 |
| Gemini-3.1 Pro | 10.8 | 18.7 | 8.5 | 5.2 | final-answer보다 trace 진단에서 약함 |
| Qwen3-VL-30B-A3B-Think | 3.6 | 9.0 | 1.3 | 0.3 | open-source thinking 모델 중 최고 |
| Qwen3-VL-8B-Think | 0.6 | 1.3 | 0.3 | 0.0 | process-level exact match에서는 거의 실패 |

이 그림이 중요한 이유는 final answer accuracy의 한계를 보여 주기 때문이다.
모델이 마지막 컵 위치를 맞혔다고 해도, 실제로 모든 swap을 추적했는지 아니면 일부 local cue나 추측으로 맞혔는지는 다르다.
Video-MME-Logical-S는 이 차이를 program metadata로 검증한다.
제품 관점에서 보면, 이것은 “정답률 높은 비디오 모델”과 “과정을 감사할 수 있는 시간 추론 모델”을 구분하는 장치다.
SFT scaling: 데이터는 도움이 되지만 충분하지 않다
논문은 Qwen3-VL-8B를 기반으로 25K, 125K, 250K, 375K, 500K training sample을 사용한 SFT scaling도 실험한다. training data는 easy-level instance에서 구성하고, medium/hard evaluation으로 더 긴 horizon과 높은 complexity에 일반화되는지 본다.
결과는 “효과는 있지만 포화된다”에 가깝다.
Qwen3-VL-8B-Instruct base는 11.9%인데, Ours-375K-Thinking은 39.2%까지 오른다.
개선 폭은 27.3%p다.
하지만 500K-Thinking은 37.7%로 오히려 1.5%p 낮아진다.
사람 95.9%와 비교하면 supervised data를 많이 넣어도 gap은 여전히 크다.
| 설정 | Overall | Easy | Medium | Hard | 해석 |
|---|---|---|---|---|---|
| Qwen3-VL-8B-Instruct base | 11.9 | 13.4 | 12.8 | 9.6 | 출발점 |
| Ours-25K-Thinking | 36.8 | 46.7 | 35.2 | 28.4 | 적은 데이터로도 큰 상승 |
| Ours-375K-Thinking | 39.2 | 54.8 | 34.7 | 28.1 | 전체 최고 SFT 결과 |
| Ours-500K-Thinking | 37.7 | 52.0 | 34.0 | 27.0 | 추가 데이터가 지속 개선으로 이어지지 않음 |
| Human Level | 95.9 | 98.4 | 95.9 | 93.4 | 여전히 매우 큰 gap |
여기서 조심할 점은 학습 데이터가 easy-level에서 만들어졌다는 것이다.
Ours-375K-Thinking은 easy에서 54.8%까지 올라가지만, medium 34.7%, hard 28.1%로 내려간다.
쉬운 절차 추론 패턴을 배워도 더 긴 시간 범위와 복잡한 조합으로 안정적으로 확장되지는 않는다.
이 결과는 video temporal reasoning을 단순 SFT data scaling만으로 해결하기 어렵다는 논문의 결론을 뒷받침한다.
실무 관점에서의 해석
첫째, 비디오 모델 평가에서 “긴 비디오를 넣었다”는 사실과 “시간 상태를 추적했다”는 사실을 분리해야 한다.
모델이 많은 frame을 입력받더라도, hidden state를 유지하고 transition마다 업데이트하지 않으면 shell game류 문제를 풀 수 없다.
Video-MME-Logical은 바로 이 유지·갱신·조합 능력을 작은 operation들로 쪼개기 때문에, 모델 개발팀이 어디서 무너지는지 보기 좋다.
둘째, final answer만 보는 leaderboard는 너무 관대할 수 있다.
제품에서 필요한 것은 종종 정답뿐 아니라 설명 가능한 과정이다.
예를 들어 medical video, robotics, surveillance, sports analysis처럼 시간에 따른 상태 변화가 중요한 영역에서는 “맞혔다”보다 “어떤 이벤트를 어떤 순서로 추적해서 맞혔는가”가 더 중요할 수 있다.
Video-MME-Logical-S는 중간 상태를 exact match로 검사한다는 점에서 이런 process-level evaluation의 방향을 보여 준다.
셋째, thinking model이나 CoT-style output을 별도 능력으로 착각하면 안 된다.
이 논문에서 일부 thinking variant는 instruct variant보다 낮다.
이유는 간단하다.
언어 trace가 길어도 영상 evidence trace가 틀리면 추론이 아니다.
비디오 모델의 reasoning improvement는 더 긴 답변 template보다 visual grounding, state memory, transition update, temporal attention 또는 external state tracker 같은 구조적 개선과 연결될 가능성이 크다.
넷째, synthetic benchmark라는 한계도 같이 읽어야 한다.
Video-MME-Logical은 절차 생성 비디오라서 자연 비디오의 복잡한 질감, camera motion, scene diversity와는 거리가 있다.
하지만 바로 그 통제성 덕분에 task category, difficulty, intermediate state를 정확히 알 수 있다.
따라서 이 benchmark는 “현실 비디오 이해 전체 성능”을 대표한다기보다, 현실 벤치마크에서 잘 보이지 않던 temporal-logical core를 따로 떼어 보는 diagnostic lens로 쓰는 편이 맞다.
한계와 다음 질문
논문도 몇 가지 한계를 명시한다.
절차 생성 비디오는 scalable하고 정확한 state annotation을 제공하지만, 자연 비디오와의 domain gap이 있다.
또한 SFT 실험은 8B MLLM 중심이라 72B급 모델이나 더 큰 proprietary model에서 같은 scaling 양상이 유지되는지는 추가 검증이 필요하다.
중간 상태 exact-match scoring도 reproducibility에는 좋지만, 표현이 다르지만 의미상 같은 trace를 벌점 처리할 수 있다.
그럼에도 Video-MME-Logical의 메시지는 꽤 선명하다.
현재 비디오 MLLM은 프레임을 보고 설명하는 능력과 시간에 따른 논리 상태를 유지하는 능력 사이에 큰 간극이 있다.
“멀티모달 모델이 영상을 이해한다”는 주장이 더 강해지려면, 이제는 객체 인식·장면 설명·일반 QA를 넘어 state tracking, sequential counting, temporal ordering, dynamic spatiality, structural composition 같은 operation별 실패를 줄여야 한다.
실제로 장기 비디오 agent나 robotics agent를 만든다면, 이 논문은 평가 checklist로 바로 쓸 만하다.
모델이 마지막 답을 맞히는지뿐 아니라, 중간 상태를 구조화해 출력할 수 있는지, 난이도 증가에 따라 어떤 operation이 먼저 무너지는지, SFT 데이터가 easy pattern 암기에 머물지 않고 hard horizon으로 일반화되는지를 따로 봐야 한다.
Video-MME-Logical은 그 질문을 깔끔하게 제기한 benchmark다.
참고 링크
- Hugging Face Papers: 2606.27828
- arXiv: Video-MME-Logical: A Controlled Diagnostic Benchmark for Video Temporal-Logical Reasoning
- arXiv HTML: 2606.27828v1
- 공식 프로젝트 페이지: mrakas.github.io/video-mme-logical
- GitHub: Mrakas/video-mme-logical
- Hugging Face Dataset: marcuskwan/video-mme-logical