고해상도 항공 사진이나 감시 카메라 영상에서 작은 객체를 찾는 일은 모델 크기만의 문제가 아니다.
원본 이미지는 크지만, 사람·차량·선박 같은 관심 객체는 몇 픽셀짜리 단서로만 남아 있다.
전체 이미지를 detector 입력 크기에 맞춰 줄이면 그 작은 단서는 더 작아지고, 반대로 입력 해상도를 무작정 키우면 GPU 메모리와 계산량이 빠르게 터진다.
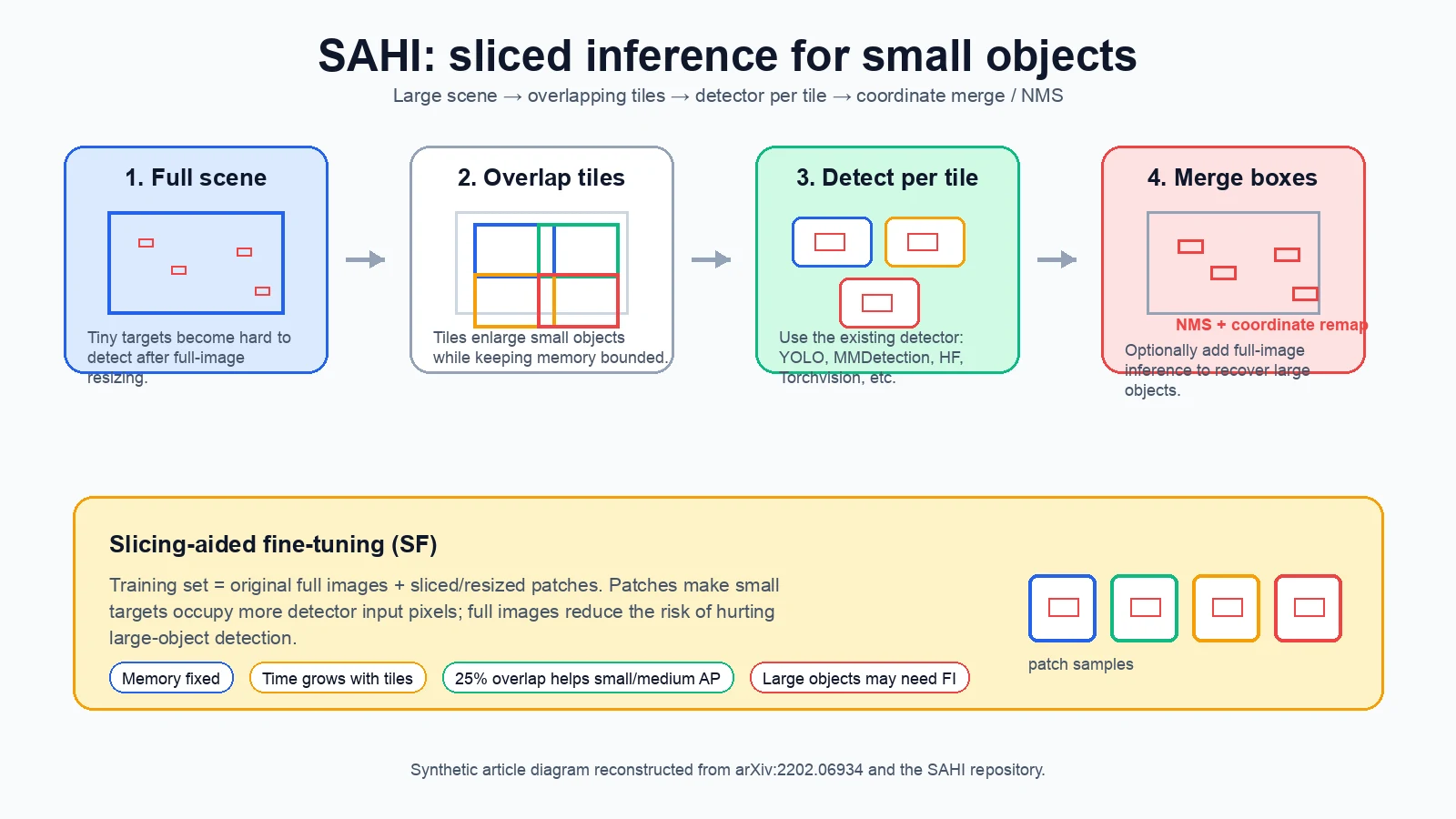
Slicing Aided Hyper Inference and Fine-tuning for Small Object Detection는 이 병목을 단순하지만 강한 방향으로 푼다.
큰 이미지를 여러 개의 겹치는 패치로 자르고, 각 패치에서 detector를 돌린 뒤, 예측 박스를 다시 원본 좌표계로 합쳐 NMS로 정리한다.
중요한 점은 이것이 새 detector architecture를 요구하는 방식이 아니라는 점이다.
논문은 이 기법을 SAHI, 즉 Slicing Aided Hyper Inference라고 부르고, FCOS·VFNet·TOOD 같은 기존 detector 위에 얹어 VisDrone과 xView에서 성능 향상을 보인다.
무엇을 해결하려는가
일반 object detector는 MS COCO나 ImageNet 계열처럼 비교적 낮은 해상도, 비교적 큰 객체가 포함된 데이터에서 잘 학습된다.
하지만 드론·위성·감시 카메라 장면은 다르다.
논문은 VisDrone2019-Detection이 8,599장, 54만 개 이상의 bounding box와 10개 카테고리를 포함하고, xView는 60개 class와 100만 개 이상의 object instance를 포함한다고 설명한다.
두 데이터셋 모두 객체 폭이 이미지 폭의 1%보다 작은 장면을 많이 포함한다.
이 상황에서 전체 이미지만 보고 추론하면 작은 객체는 detector feature 위에서 희미해진다.
그렇다고 전체 이미지를 크게 넣는 것은 메모리 비용이 크다.
SAHI의 접근은 중간 지점이다.
작은 객체가 있는 영역을 더 큰 상대 크기로 보여 주기 위해 이미지를 타일로 나누되, detector 자체는 기존 모델을 그대로 쓴다.
그래서 이 논문의 가치는 “새 detector를 하나 더 제안했다”보다 기존 detector를 작은 객체 도메인에 맞게 실행하는 inference wrapper를 제안했다에 가깝다.
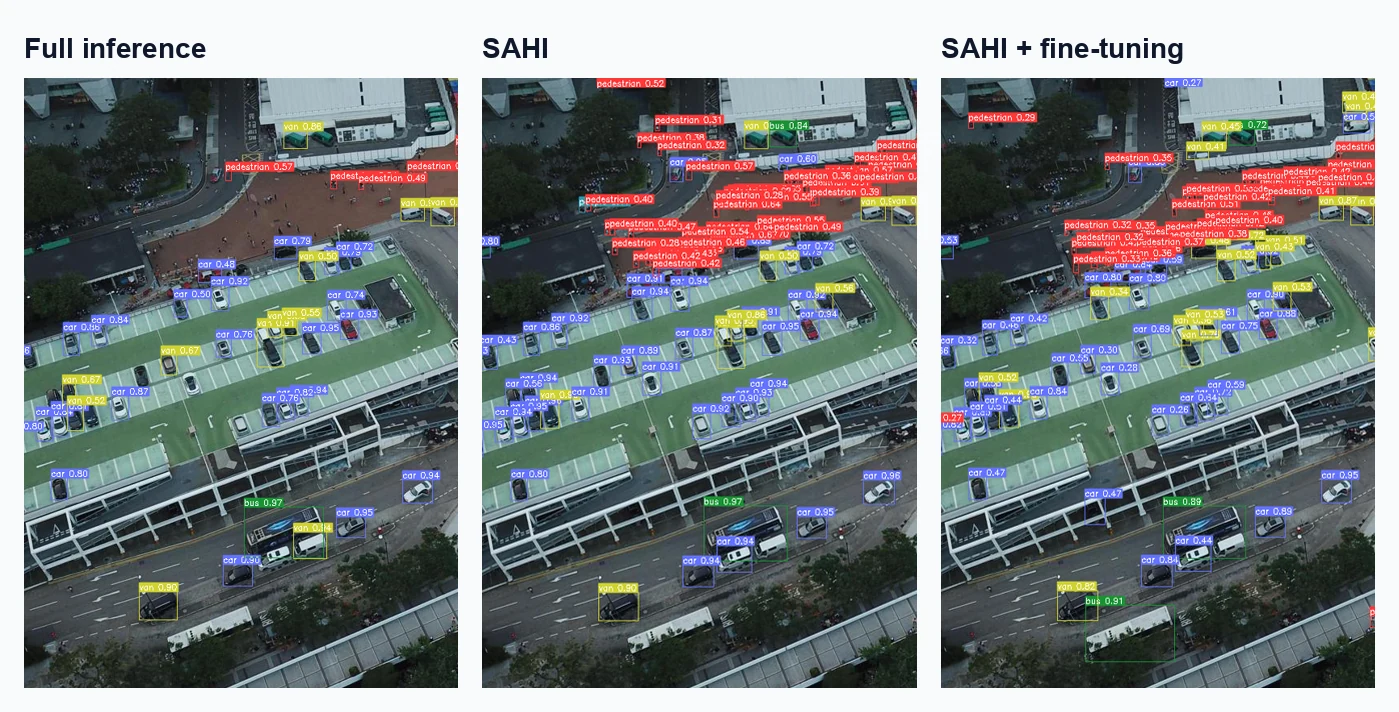
논문 Figure 1은 이 차이를 직관적으로 보여 준다.
같은 VisDrone 장면에서 일반 TOOD 추론보다 SAHI를 붙인 추론이 더 많은 작은 객체 박스를 회수하고, slicing-aided fine-tuning까지 더하면 결과가 더 촘촘해진다.
핵심 아이디어: 자르고, 키워 보고, 다시 합친다
SAHI는 두 단계로 읽으면 쉽다.
하나는 추론 시점의 Slicing Aided Hyper Inference, 다른 하나는 학습 시점의 Slicing Aided Fine-tuning이다.
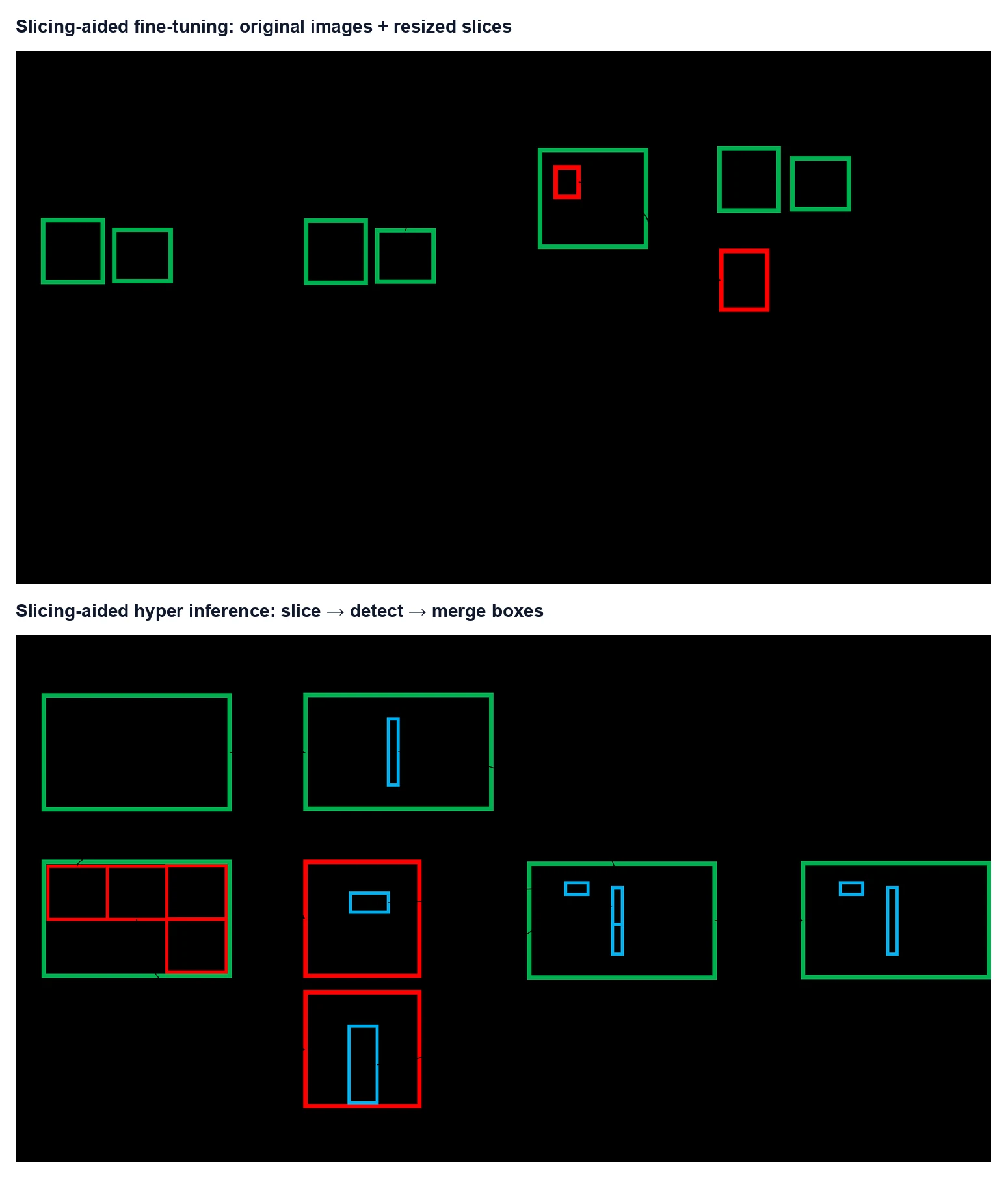
Slicing-aided fine-tuning은 학습 데이터를 원본 이미지와 sliced/resized patch의 조합으로 만든다.
논문에서는 fine-tuning 이미지에서 겹치는 패치를 뽑고, 이 패치를 aspect ratio를 보존하면서 폭 800~1333 범위로 resize해 augmentation 이미지로 사용한다.
이렇게 하면 작은 객체가 detector 입력에서 더 큰 픽셀 영역을 차지한다.
동시에 원본 이미지도 학습에 남겨 큰 객체 성능이 무너지는 것을 줄인다.
Slicing-aided hyper inference는 실제 배포 흐름에 더 직접적이다.
원본 query image를 M×N 크기의 겹치는 패치로 자르고, 각 패치를 detector에 넣어 예측한다.
그다음 patch 좌표계의 박스를 원본 이미지 좌표계로 되돌리고, IoU 기반 matching과 NMS로 중복 박스를 제거한다.
큰 객체는 작은 patch 안에 완전히 들어오지 않을 수 있으므로, 논문은 optional full-image inference(FI)를 함께 쓰는 경로도 둔다.
논문에서 쓰는 약어를 실무 관점으로 풀면 다음과 같다.
| 약어 | 의미 | 실무적 해석 |
|---|---|---|
| FI | Full Inference | 원본 이미지를 그대로 한 번 추론한다. 큰 객체 회수에 유리하다. |
| SAHI | Slicing Aided Hyper Inference | 이미지를 타일로 잘라 각 타일에서 추론한 뒤 박스를 합친다. 작은 객체 회수에 유리하다. |
| SF | Slicing Aided Fine-tuning | 학습 데이터에 sliced/resized patch를 추가한다. 작은 객체가 더 큰 입력 픽셀을 차지하게 한다. |
| PO | Patch Overlap | 실험에서는 25% overlap을 사용한다. 경계에 걸린 작은 객체를 더 잘 살릴 수 있다. |
여기서 trade-off도 중요하다.
논문은 25% overlap이 small/medium object AP와 overall AP를 올리지만, large object AP를 약간 낮출 수 있다고 설명한다.
작은 slice에서 큰 객체의 일부만 보고 생긴 false positive가 큰 객체 ground truth와 겹치기 때문이다.
따라서 SAHI를 제품에 붙일 때는 “항상 sliced-only가 최고”라고 보기보다, 데이터의 객체 크기 분포에 따라 sliced inference, full inference, overlap, postprocess threshold를 같이 조정해야 한다.
숫자로 보면: 작은 객체 회수율이 크게 오른다
논문은 MMDetection 기반 FCOS, VFNet, TOOD에 SAHI를 통합해 VisDrone과 xView에서 평가한다.
Abstract는 inference-only SAHI가 FCOS, VFNet, TOOD의 AP를 각각 6.8%, 5.1%, 5.3% 올리고, slicing-aided fine-tuning까지 더하면 누적 12.7%, 13.4%, 14.5% AP 향상을 만든다고 요약한다.
본문 표는 AP50 및 객체 크기별 AP50 형태로 결과를 제시한다.
VisDrone19-Detection test-dev 기준 핵심 숫자는 다음과 같다.
| Detector / 설정 | AP50 | Small AP50 | Medium AP50 | Large AP50 |
|---|---|---|---|---|
| FCOS + FI | 25.8 | 14.2 | 39.6 | 45.1 |
| FCOS + SAHI + FI + PO | 31.0 | 19.8 | 44.6 | 49.0 |
| FCOS + SF + SAHI + FI + PO | 38.5 | 25.9 | 55.4 | 59.8 |
| VFNet + FI | 28.8 | 16.8 | 44.0 | 47.5 |
| VFNet + SAHI + FI + PO | 33.9 | 22.4 | 49.1 | 49.4 |
| VFNet + SF + SAHI + FI + PO | 42.2 | 29.6 | 59.2 | 63.3 |
| TOOD + FI | 29.4 | 18.1 | 44.1 | 50.0 |
| TOOD + SAHI + FI + PO | 34.7 | 23.8 | 48.9 | 50.3 |
| TOOD + SF + SAHI + FI + PO | 43.5 | 31.7 | 59.8 | 65.4 |
xView validation split에서는 원본 full inference가 특히 약하게 나오고, SF+SAHI 계열이 크게 오른다.
예를 들어 TOOD+FI는 AP50 2.10인데, TOOD+SF+SAHI는 19.4, TOOD+SF+SAHI+PO는 20.6까지 오른다. xView 대상이 매우 작고 class imbalance가 큰 데이터셋이라는 점을 감안하면, SAHI의 효과는 “일반 detector가 작은 객체를 처음부터 잘 못 보는 장면”에서 더 뚜렷하게 드러난다.
논문의 결론도 이 trade-off를 정직하게 말한다.
SAHI는 메모리 요구량을 고정한 채 계산 시간을 slice 수에 따라 선형적으로 늘리는 구조다.
즉 GPU 메모리를 폭발시키지 않고 작은 객체 성능을 올릴 수 있지만, 타일 수가 많아질수록 latency는 늘어난다.
실제 시스템에서는 slice 크기, overlap, standard prediction 병행 여부, confidence threshold, NMS 또는 matching 방식을 latency budget에 맞춰 잡아야 한다.
2026년 현재 공개 구현으로 보면
공식 저장소 obss/sahi는 논문 코드 이상의 라이브러리로 발전해 있다.
GitHub API와 공식 문서 확인 시점 기준으로 MIT license, 최신 릴리스 0.12.1, PyPI 패키지 sahi==0.12.1이 제공되어 있고, 저장소는 약 5.3k stars와 751 forks를 갖고 있다.
공식 문서는 SAHI를 “large scale object detection & instance segmentation”을 위한 lightweight vision library로 설명한다.
현재 문서상 지원 범위도 넓다.
논문 당시에는 Detectron2, MMDetection, YOLOv5 integration이 강조되었지만, 현재 README와 docs는 Ultralytics, MMDetection, Hugging Face object detection models, TorchVision, YOLOv5, YOLOX, RT-DETR, GroundingDINO, Roboflow/RF-DETR 같은 여러 모델 생태계를 언급한다.
즉 SAHI는 논문 아이디어가 아니라, object detection inference wrapper와 dataset utility를 포함한 실사용 라이브러리로 보는 편이 맞다.
CLI도 이 방향을 잘 보여 준다.
예를 들어 sliced inference는 다음처럼 slice 크기와 overlap을 직접 조정할 수 있다.
sahi predict --source image/file/or/folder \
--model_type ultralytics \
--model_path path/to/model.pt \
--slice_width 512 \
--slice_height 512 \
--overlap_height_ratio 0.1 \
--overlap_width_ratio 0.1 \
--model_confidence_threshold 0.25
또한 --postprocess_type GREEDYNMM 또는 NMS, --postprocess_match_metric IOS 또는 IOU, --postprocess_match_threshold 0.5 같은 옵션을 통해 slice별 중복 박스 병합 방식을 조정할 수 있다.
기본적으로 standard prediction과 sliced prediction을 함께 수행하는 multi-stage inference 흐름도 제공하고, 필요하면 --no_sliced_prediction 또는 --no_standard_prediction으로 모드를 제한할 수 있다.
Python API에서는 get_sliced_prediction이 핵심이다.
from sahi import AutoDetectionModel
from sahi.predict import get_sliced_prediction
model = AutoDetectionModel.from_pretrained(
model_type="ultralytics",
model_path="yolo11n.pt",
confidence_threshold=0.25,
device="cuda:0",
)
result = get_sliced_prediction(
image,
model,
slice_height=512,
slice_width=512,
overlap_height_ratio=0.2,
overlap_width_ratio=0.2,
)
이 API 형태는 SAHI의 가장 큰 실용성을 보여 준다.
모델을 새로 학습하지 않아도, 기존 detector를 타일 기반 실행 계획으로 감쌀 수 있다.
실무에서는 먼저 validation set 일부에서 full inference와 sliced inference를 나란히 돌려보고, small-object recall 증가가 latency 증가를 정당화하는지 확인하는 흐름이 자연스럽다.
실무적으로 어떻게 읽어야 하나
SAHI가 잘 맞는 조건은 비교적 명확하다.
첫째, 원본 이미지가 크고 관심 객체가 작다.
둘째, 객체가 타일 경계에 걸릴 수 있어 overlap이 필요하다.
셋째, GPU 메모리 때문에 full-resolution inference를 크게 키우기 어렵다.
드론, 위성, 항만, 교통, 원거리 CCTV, 산업 검사처럼 작은 객체가 넓은 배경에 흩어져 있는 워크로드가 여기에 들어간다.
반대로 주의할 점도 있다.
객체가 대부분 큰 일반 detection 데이터에서는 sliced inference가 큰 이득 없이 중복 예측과 latency만 늘릴 수 있다.
큰 객체가 slice에 잘려 들어오면 false positive가 늘거나 large-object AP가 낮아질 수 있으므로, full-image inference를 병행하거나 slice size를 키우는 식의 보정이 필요하다.
또한 overlap을 늘리면 경계 객체는 더 잘 살지만, 같은 영역을 여러 번 추론하므로 비용이 늘어난다.
그래서 SAHI는 “small object detection을 해결하는 마법 버튼”이라기보다, 작은 객체가 입력 리사이즈에서 사라지는 문제를 inference scheduling 문제로 바꾸는 도구로 보는 것이 정확하다.
새 모델을 찾기 전에, 현재 detector가 고해상도 이미지를 어떻게 보고 있는지, 작은 객체 recall이 full inference에서 얼마나 낮은지, slice 크기와 overlap을 바꾸면 latency 대비 recall이 얼마나 개선되는지 먼저 측정하게 만드는 프레임워크다.
그 점에서 SAHI는 오래된 논문이지만 여전히 실용적이다.
최신 foundation model이나 end-to-end detector가 나오더라도, 운영 데이터가 크고 객체가 작다면 “어떤 해상도로, 어떤 tile로, 어떤 postprocess로 모델을 실행할 것인가”는 계속 남는다.
SAHI는 이 질문을 라이브러리와 CLI, COCO slicing/evaluation utility, FiftyOne visualization까지 묶어 제품팀이 바로 실험할 수 있는 형태로 만든 사례다.