고해상도 이미지에서 작은 객체를 잘 잡는 가장 직관적인 방법은 입력 해상도를 키우는 것이다.
드론 영상, 해안가 사람 탐지, 파노라마 카메라처럼 객체가 몇 픽셀 크기로만 보이는 장면에서는 해상도를 올리면 작은 물체의 시각 정보가 늘어난다.
문제는 그만큼 전체 이미지에 대한 backbone, neck, head 계산도 같이 커진다는 점이다.
실제로 관심 객체가 화면 일부에만 몰려 있는데도, detector는 넓은 배경 영역까지 동일한 밀도로 훑는다.
ESOD: Efficient Small Object Detection on High-Resolution Images는 이 낭비를 정면으로 겨냥한다.
핵심 가정은 단순하다.
작은 객체는 대개 희소하게 분포하고, 국소적으로 군집한다.
따라서 고해상도 이미지를 전부 같은 비용으로 처리하기보다, detector의 초기 feature를 재사용해 객체가 있을 법한 영역을 먼저 찾고, 그 feature patch만 후속 detector로 보내는 편이 효율적이다.
이 논문은 그 아이디어를 ObjSeeker, AdaSlicer, SparseHead 세 구성 요소로 묶어 ESOD라는 범용 프레임워크로 제안한다. arXiv v2와 공개 GitHub 저장소 기준으로 YOLOv5 계열을 중심으로 구현되어 있고, README는 RetinaNet, RTMDet, YOLOv8, GPViT까지 확장 가능한 형태를 설명한다.
즉 “작은 객체 detector 하나”라기보다, 고해상도 입력에서 detector가 어디에 계산을 써야 하는지 재배치하는 구조에 가깝다.

무엇을 해결하려는가
작은 객체 탐지는 일반 객체 탐지보다 해상도 의존성이 강하다.
COCO식 정의로 32×32 픽셀보다 작은 객체는 feature pyramid와 augmentation을 써도 표현 정보가 부족하기 쉽다.
해상도를 키우면 작은 객체가 상대적으로 커져 성능은 올라갈 수 있지만, FLOPs와 GPU 메모리가 빠르게 증가한다.
특히 UAV나 감시 카메라처럼 배경이 넓고 객체가 드문 영상에서는 계산의 큰 부분이 실제 관심 영역이 아닌 배경에 쓰인다.
논문이 제시한 데이터 통계는 이 문제를 잘 보여 준다.
| 데이터셋 | 평균 객체 수 | 객체가 차지하는 픽셀 비율 | 균일 8×8 패치 기준 빈 패치 비율 |
|---|---|---|---|
| VisDrone | 54개 | 8.1% | 70% 초과 |
| UAVDT | 18개 | 4.9% | 약 84% |
| TinyPerson | 25개 | 0.87% | 최대 89% |
이 수치가 의미하는 바는 명확하다.
고해상도 이미지 전체를 더 크게 넣는 전략은 작은 객체의 정보량을 늘리지만, 동시에 객체가 전혀 없는 영역까지 비싸게 처리한다.
기존 filter-then-detect 방식은 별도 네트워크로 객체 후보 영역을 찾은 뒤 원본 이미지를 잘라 detector를 다시 적용하는 경우가 많았다.
하지만 이 접근은 추가 네트워크 비용과 중복 feature extraction을 만든다.
ESOD는 필터링을 원본 이미지 crop이 아니라 feature-level routing 문제로 바꾼다.
이미 detector가 초반에 계산한 feature를 버리지 않고, 그 feature 위에서 객체 후보 패치를 고르고, 배경 patch를 제거한 다음, 남은 patch에만 후속 계산을 집중한다.
핵심 아이디어 / 구조 / 동작 방식
ESOD의 파이프라인은 기존 detector 앞뒤에 큰 별도 모델을 붙이는 방식이 아니다. detector의 stem 이후 초기 feature에서 objectness를 예측하고, 그 결과로 feature map을 자른 다음, detection head 쪽에서도 sparse convolution을 사용한다.
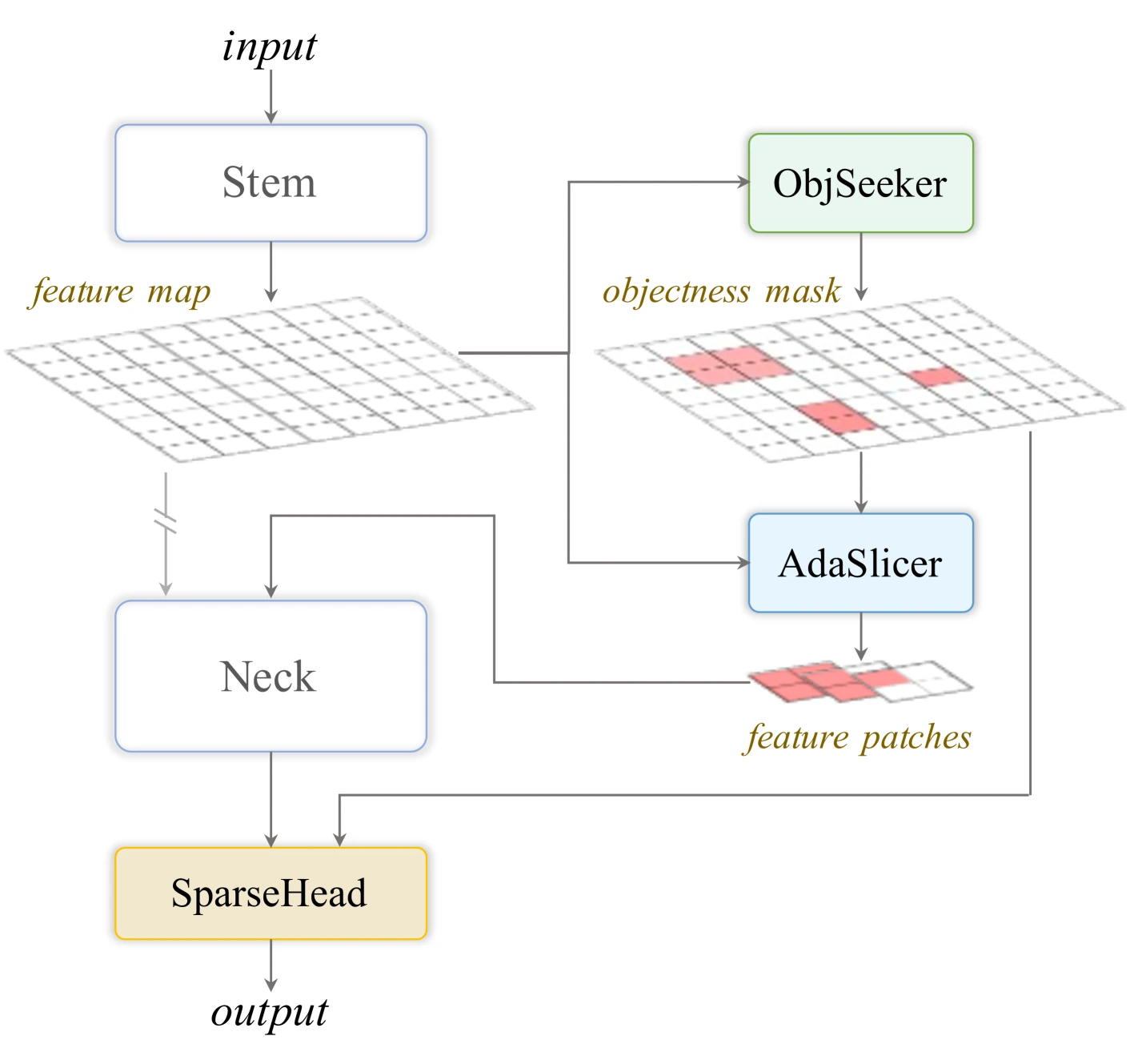
| 구성 요소 | 역할 | 실무적으로 읽히는 의미 |
|---|---|---|
| ObjSeeker | 초기 feature에서 class-agnostic objectness mask를 예측 | “어떤 종류의 객체인가”보다 “어딘가에 객체가 있는가”를 먼저 가볍게 본다. |
| AdaSlicer | objectness 결과를 바탕으로 feature map을 고정 크기 patch로 적응적으로 자름 | 원본 이미지를 다시 crop하지 않고, 이미 계산된 feature를 필요한 영역 중심으로 라우팅한다. |
| SparseHead | 남은 patch의 후보 위치에서 sparse convolution 기반 detection을 수행 | head 단계에서도 배경 위치에 대한 dense prediction 낭비를 줄인다. |
ObjSeeker의 학습도 흥미롭다.
논문은 bounding box annotation만으로 objectness mask를 만들기 위해 Gaussian mask와 SAM 기반 mask를 결합한 hybrid pseudo-labeling 전략을 사용한다.
이 설계는 세부 segmentation을 완벽히 맞추려는 목적이 아니라, 후속 detector가 놓치지 않을 정도로 객체 후보 영역을 넉넉하게 찾는 데 초점을 둔다.
AdaSlicer는 단순 균일 slicing과 다르다.
균일하게 자르면 작은 객체가 patch 경계에서 잘리거나, 객체가 적은데도 많은 patch를 처리하게 된다.
ESOD는 object center 근처에서 patch를 시작하고, 더 많은 객체를 포함하도록 위치를 조정한다.
그 결과 후속 neck/head는 전체 고해상도 feature map이 아니라 객체가 있을 가능성이 큰 feature patch 묶음을 처리한다.
SparseHead는 마지막 단계의 밀집 예측 비용을 더 줄인다. small object detection에서는 입력 해상도만 아니라 head의 위치별 예측 비용도 커진다.
ESOD는 objectness mask를 detection head에도 재사용해, 객체 중심 가능성이 있는 위치 중심으로 sparse detection을 적용한다.
공개된 근거에서 확인되는 점
메인 결과에서 ESOD는 VisDrone, UAVDT, TinyPerson 세 벤치마크를 중심으로 비교된다.
논문은 AP/AP50 같은 탐지 성능과 함께 GFLOPs, FPS를 같이 보고해 “성능을 올렸지만 계산을 더 쓴 것인지”를 분리해 볼 수 있게 한다.
| 설정 | 대표 비교 | AP / AP50 | GFLOPs | FPS | 해석 |
|---|---|---|---|---|---|
| VisDrone | QueryDet | 28.3 / 48.1 | 888.4 | 8.6 | 고해상도 small object detector지만 계산량이 매우 큼 |
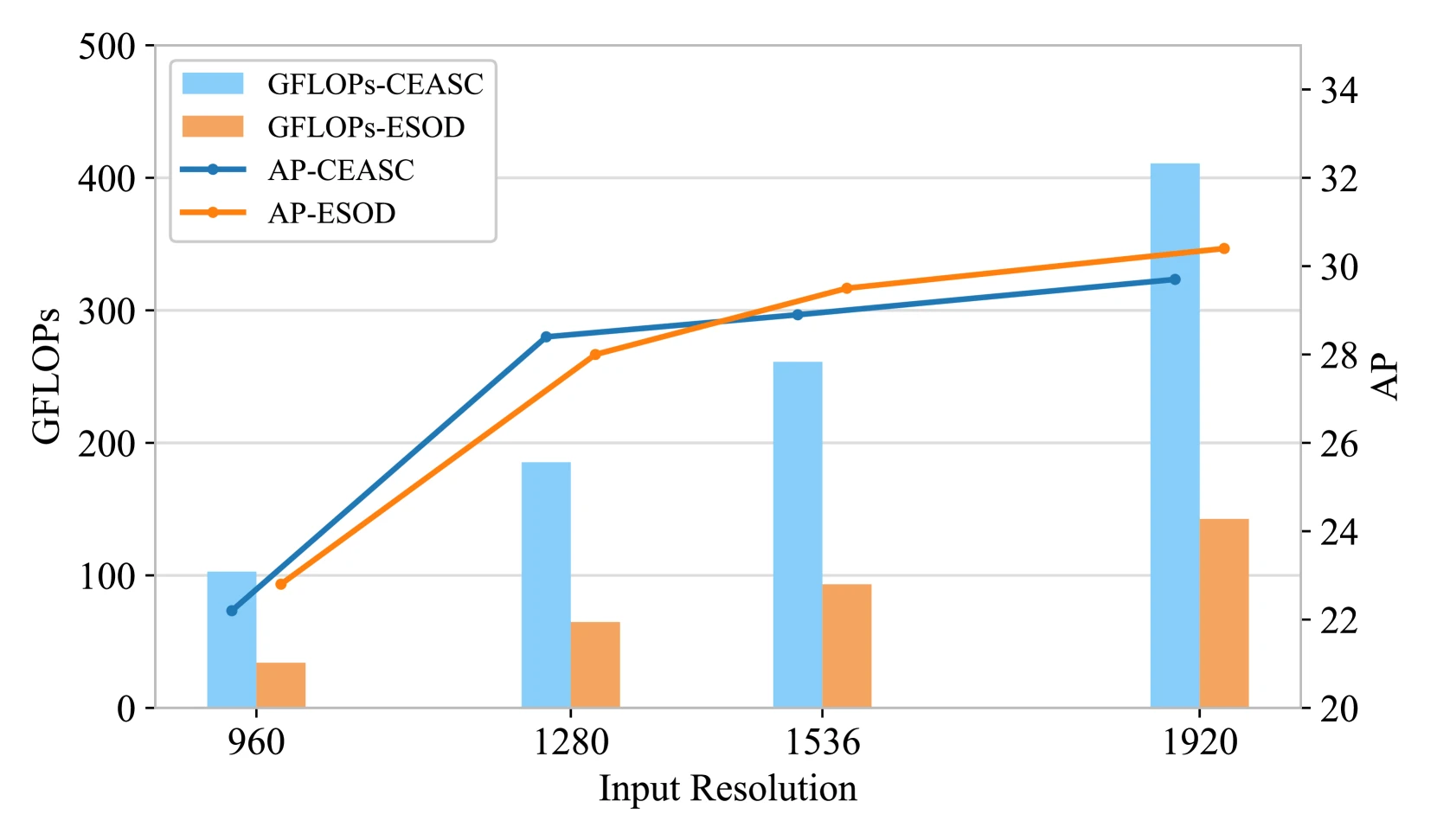
| VisDrone | CEASC | 28.7 / 50.7 | 150.2 | 26.9 | ESOD보다 계산량은 높고 AP는 낮음 |
| VisDrone | ESOD | 36.0 / 59.7 | 119.5 | 36.4 | 낮은 GFLOPs와 높은 FPS를 함께 달성 |
| VisDrone | ESOD† | 37.9 / 62.3 | 180.6 | 28.6 | 입력을 1.25배 키운 고성능 설정 |
| UAVDT | CEASC | 17.1 / 30.9 | 64.1 | 35.6 | 기존 효율 지향 비교점 |
| UAVDT | ESOD | 22.5 / 40.7 | 43.7 | 41.1 | 더 낮은 GFLOPs에서 AP와 FPS가 모두 개선 |
| UAVDT | ESOD† | 23.6 / 47.6 | 68.6 | 36.7 | 계산을 조금 더 쓰며 성능 상한을 높인 설정 |
| TinyPerson | ScaleMatch+ | 52.6 / 67.4 | 486.7 | 18.3 | TinyPerson 계열 strong baseline |
| TinyPerson | ESOD | 61.3 / 74.4 | 148.3 | 32.8 | AP50과 FPS를 함께 끌어올림 |
† 표시는 논문에서 입력 폭과 높이를 각각 1.25배 확대한 설정이다.
중요한 점은 ESOD의 기본 설정이 단순히 “더 큰 입력을 썼기 때문에” 좋은 것이 아니라는 점이다.
VisDrone에서 ESOD는 QueryDet보다 AP가 높으면서 GFLOPs는 크게 낮고, UAVDT에서는 CEASC보다 AP와 FPS가 모두 높으면서 GFLOPs도 낮다.
TinyPerson에서도 ScaleMatch+ 대비 AP50 지표와 속도 측면에서 강한 이점을 보인다.
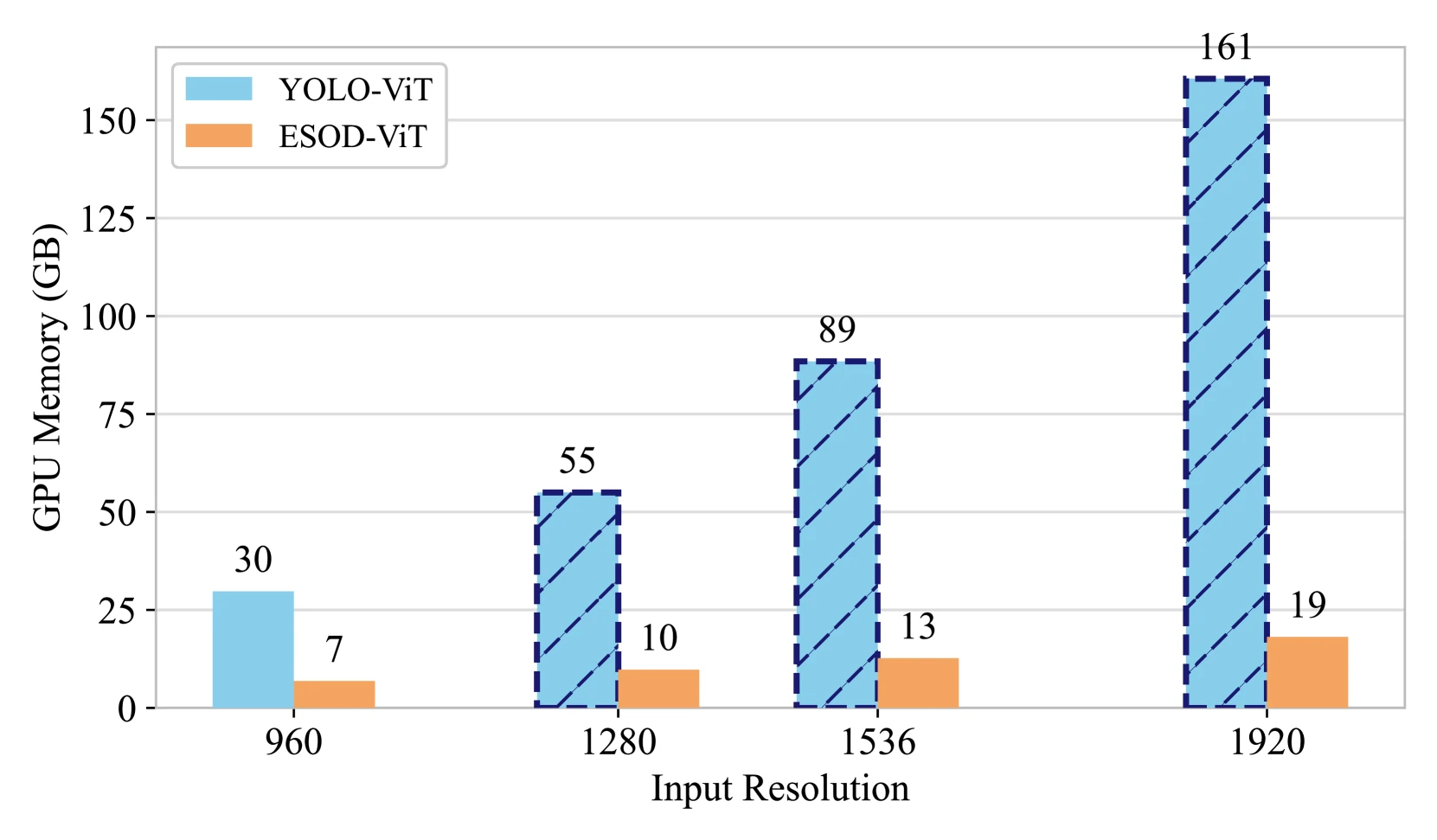
ViT 기반 detector에 대한 실험도 실무적으로 중요하다.
고해상도 입력에서 self-attention 계열 backbone은 메모리 비용이 급격히 커진다.
논문은 1,920×1,920 입력에서 일반 ViT detector가 batch size 1 기준 161GB 메모리를 요구하는 반면, ESOD는 ObjSeeker와 AdaSlicer의 도움으로 이를 19GB 수준까지 줄인다고 보고한다.
이 수치는 “더 좋은 backbone을 쓰면 된다”가 고해상도 small object detection에서는 쉽게 성립하지 않는다는 것을 보여 준다.
공개 구현 측면에서는 GitHub 저장소 alibaba/esod가 제공되어 있다.
저장소는 GPL-3.0 라이선스이며, README 기준 Python 3.6+, PyTorch 1.7+ 환경과 YOLOv5 계열 pretrained weight를 중심으로 설치·학습·평가 명령을 제공한다.
VisDrone, UAVDT, TinyPerson 데이터 준비 스크립트와 detect.py inference 경로도 문서화되어 있고, pretrained weights는 Google Drive 링크로 안내된다.
다만 GitHub API 확인 기준 별도 Release와 tag는 비어 있어, 패키지화된 라이브러리라기보다 논문 재현용 연구 코드에 가깝게 보는 편이 안전하다.

실무 관점에서의 해석
ESOD의 가장 큰 가치는 small object detection을 “더 큰 입력, 더 큰 모델” 문제에서 “어디에 계산을 쓸 것인가” 문제로 옮긴다는 데 있다.
드론, 교통, 감시, 해양, 위성 이미지처럼 객체가 작고 배경이 넓은 도메인에서는 이 관점이 중요하다.
전체 프레임을 무차별적으로 고해상도 처리하는 것은 단순하지만, 운영 비용과 지연 시간 예산을 금방 초과한다.
실무자가 이 논문을 읽을 때 봐야 할 포인트는 세 가지다.
첫째, ESOD는 별도 pre-filter 네트워크로 이미지를 다시 자르는 방식이 아니라 detector 내부 feature를 재사용한다.
따라서 기존 filter-then-detect의 중복 feature extraction 문제를 줄인다.
둘째, objectness prediction을 class-agnostic하게 두어 “놓치면 안 되는 후보 영역”을 먼저 찾고, 세부 분류·회귀는 후속 detector가 담당하게 한다.
셋째, sparse routing이 feature slicing과 head prediction 양쪽에 걸쳐 들어간다.
반대로 제한도 분명하다.
공개 저장소는 연구 코드 성격이 강하고, tags/releases가 없는 상태다.
README도 일부 세부 지침은 “coming soon”이라고 표시한다.
또한 논문 결과는 VisDrone, UAVDT, TinyPerson이라는 small object 중심 벤치마크에 강하게 맞춰져 있다.
객체가 이미지 전체에 고르게 퍼진 도메인이나, 큰 객체가 많은 일반 detection 워크로드에서는 ESOD의 routing 이득이 줄어들 수 있다.
그럼에도 ESOD는 고해상도 perception 시스템을 설계할 때 꽤 실용적인 질문을 던진다.
“작은 객체가 어렵다”는 이유로 무조건 입력 해상도와 detector 크기를 키우기 전에, 실제 운영 데이터에서 객체가 얼마나 희소한지, patch empty rate가 어느 정도인지, feature-level gating으로 배경 계산을 얼마나 줄일 수 있는지를 먼저 측정해야 한다.
ESOD는 그 측정이 충분히 크다면, detector의 계산 경로 자체를 sparse하게 바꾸는 것이 성능과 비용을 동시에 개선할 수 있음을 보여 주는 사례다.