오토리그레시브 LLM의 병목은 이제 “모델이 충분히 똑똑한가”보다 “토큰을 반드시 한 칸씩 생성해야 하는가”에 더 가까워지고 있다.
모델 호출 한 번의 비용을 줄이려는 하이브리드 어텐션, Mamba류 recurrent/linear attention, Gated DeltaNet 같은 흐름이 있고, 다른 한쪽에는 여러 토큰을 병렬로 복원하려는 diffusion language model(dLLM) 흐름이 있다.
문제는 이 둘을 동시에 잡기가 쉽지 않다는 점이다.
FLARE: Diffusion for Hybrid Language Model은 이 두 축을 합치려는 Adobe Research와 Georgia Tech의 논문이다.
저자들은 강한 하이브리드 어텐션 AR 체크포인트를 처음부터 다시 학습하지 않고, 비교적 작은 전이 예산으로 dLLM처럼 동작하도록 변환하는 레시피를 제안한다.
결과적으로 한 체크포인트가 두 방식으로 디코딩된다.
하나는 AR처럼 draft를 검증하는 AR-Trust 경로이고, 다른 하나는 블록을 병렬로 디노이징하는 Diffusion-Trust 경로다.
논문과 공식 프로젝트 페이지가 강조하는 메시지는 꽤 명확하다.
디퓨전 LM의 실용성은 샘플링 알고리즘 하나로 결정되지 않는다.
전이 데이터의 품질, AR 능력을 보존하는 학습 목표, 하이브리드 어텐션의 recurrent state를 다루는 커널, 그리고 서빙 경로가 같이 설계되어야 한다는 것이다.
무엇을 해결하려는가
AR LLM은 품질과 생태계 면에서 여전히 기본값이다.
하지만 토큰을 왼쪽에서 오른쪽으로 하나씩 만들기 때문에, 낮은 지연시간이나 낮은 동시성의 서빙에서는 GPU를 충분히 쓰지 못하는 구간이 생긴다.
반대로 dLLM은 마스크된 토큰을 반복적으로 복원하면서 한 번의 forward에서 여러 토큰 후보를 만들 수 있다.
이론적으로는 직렬 decoding step을 줄일 수 있지만, 실제 공개 dLLM은 AR 모델보다 품질 보존과 학습 효율에서 자주 흔들렸다.
하이브리드 어텐션 백본은 또 다른 축의 효율을 제공한다. softmax attention 일부를 linear/recurrent attention으로 바꾸면 long context나 serving cost를 줄일 수 있다.
FLARE가 다루는 Qwen3.5 계열도 이런 하이브리드 구조를 가진 것으로 설명된다.
그런데 이 구조를 dLLM으로 바꾸려면 단순히 attention mask만 바꾸면 끝나지 않는다. recurrent state가 어디까지 clean token을 봤고, noisy block이 어떤 boundary state에서 시작해야 하는지까지 맞춰야 한다.
그래서 FLARE의 문제 설정은 “디퓨전 디코딩을 붙이면 빨라진다”가 아니다.
더 정확히는 다음 질문이다.
| 질문 | FLARE의 답 |
|---|---|
| 강한 AR 체크포인트의 능력을 dLLM으로 옮길 수 있는가 | clean stream에 AR next-token supervision을 유지한다 |
| 디퓨전 병렬성을 학습할 수 있는가 | noisy stream에 block diffusion denoising을 학습시킨다 |
| 하이브리드 어텐션의 recurrent state를 어떻게 다루는가 | clean/noisy two-stream을 state scheduling과 fused kernel로 구현한다 |
| 한 모델을 어떻게 서빙할 것인가 | AR-Trust와 Diffusion-Trust 두 디코딩 경로를 같은 체크포인트에서 제공한다 |
핵심 아이디어 / 구조 / 동작 방식
FLARE의 핵심은 clean/noisy two-stream objective다.
응답을 블록으로 나누고, 각 블록을 한 번은 clean한 causal view로, 한 번은 noisy한 masked view로 본다. clean 쪽은 기존 AR next-token prediction을 유지하고, noisy 쪽은 마스크된 토큰을 복원하는 block diffusion objective를 학습한다.
중요한 점은 이 둘을 단순히 섞는 것이 아니라 token-balanced하게 만든다는 점이다.
논문은 마스크된 토큰과 마스크되지 않은 토큰이 블록 안에서 보완 집합을 이루도록 설계해, 모든 토큰이 AR signal과 diffusion signal에 각각 한 번씩 기여하도록 한다.
이 때문에 모델은 한쪽에서는 left-to-right prior를 잃지 않고, 다른 한쪽에서는 bidirectional block denoising 능력을 얻는다.
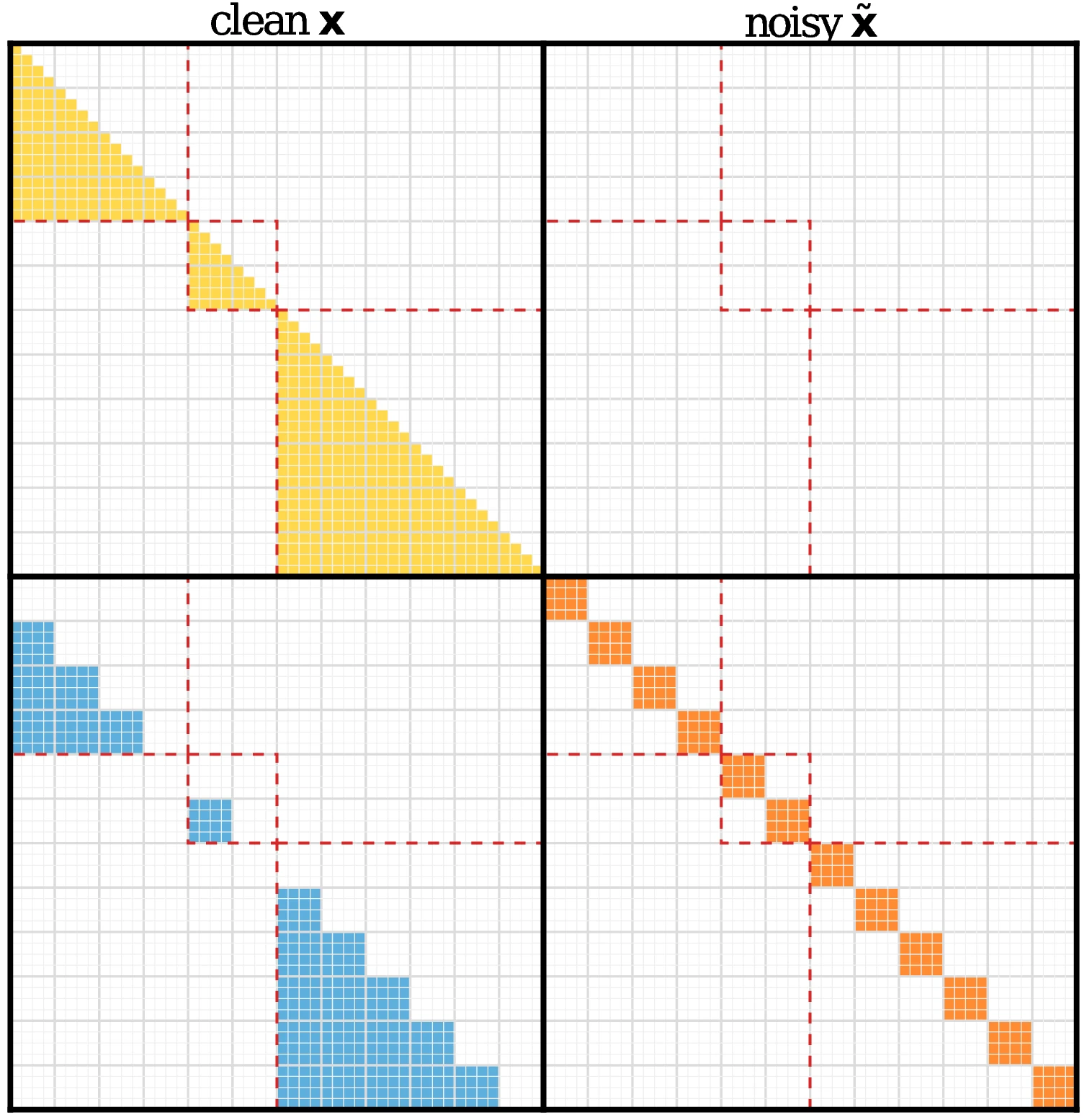
이 설계가 softmax attention만 있는 모델이라면 비교적 직관적인 mask 문제로 끝날 수 있다.
하지만 FLARE가 겨냥하는 하이브리드 어텐션 백본에서는 recurrent state가 핵심이다.
예를 들어 Gated DeltaNet 계열 layer에서는 noisy block이 잘못된 clean boundary state를 읽으면 문서 경계가 새거나, block 간 정보가 섞이거나, 디퓨전 학습 신호가 깨질 수 있다.
그래서 FLARE는 커널까지 포함한 시스템으로 제시된다.
단순 구현(Route I)은 clean stream의 block-boundary state를 모두 HBM에 저장한 뒤 noisy block을 다시 실행한다.
이 방식은 맞지만 diffusion에 필요한 작은 block size에서 메모리가 터진다.
FLARE의 Route II는 strided checkpoint만 남기고 boundary state를 register 안에서 재구성하며, noisy block을 즉시 소비하는 fused two-stream kernel을 쓴다.
프로젝트 페이지 기준 Gated Delta Rule microbenchmark에서 이 경로는 block size 1 조건으로 총 latency를 135.10ms에서 37.69ms로 줄이고, peak memory를 18.14GiB에서 0.45GiB로 낮춘다.
디코딩은 두 갈래다.
| 모드 | 동작 방식 | 의미 |
|---|---|---|
| AR-Trust | noisy stream이 block draft를 제안하고 clean stream이 left-to-right로 검증 | speculative decoding에 가깝고, 검증이 정확하면 FLARE 자신의 AR 분포를 보존한다 |
| Diffusion-Trust | masked block을 병렬로 복원하고 confidence에 따라 여러 토큰을 commit | 더 적은 serial step으로 throughput을 높이는 dLLM 경로다 |
이 구조 때문에 FLARE는 “AR 모델을 버리고 dLLM으로 갈아탄다”기보다, AR의 검증 가능성과 diffusion의 병렬성을 한 체크포인트 안에 함께 넣는 변환 프레임워크에 가깝다.
공개된 근거에서 확인되는 점
arXiv 메타데이터 기준 논문 제목은 FLARE: Diffusion for Hybrid Language Model이고, 2026년 6월 1일 제출된 cs.LG/cs.AI 논문이다.
저자는 Yuchen Zhu, Jing Shi, Chongjian Ge, Hao Tan, Yiran Xu, Wanrong Zhu, Jason Kuen, Koustava Goswami, Rajiv Jain, Yongxin Chen, Molei Tao, Jiuxiang Gu이며, affiliation은 Adobe Research와 Georgia Institute of Technology다.
논문 본문과 공식 프로젝트 페이지는 프로젝트 페이지 tokflare.github.io를 함께 제공한다.
릴리스 상태는 보수적으로 읽어야 한다.
공식 프로젝트 페이지에는 arXiv 버튼은 활성화되어 있지만, Code와 Models 버튼은 “coming soon” 상태로 비활성화되어 있다.
즉 지금 공개된 것은 논문, 프로젝트 페이지, arXiv 소스와 figure 중심의 연구 공개이며, 독자가 바로 clone해서 재현할 수 있는 코드/체크포인트 릴리스는 아직 확인되지 않는다.
성능 근거는 크게 세 층이다.
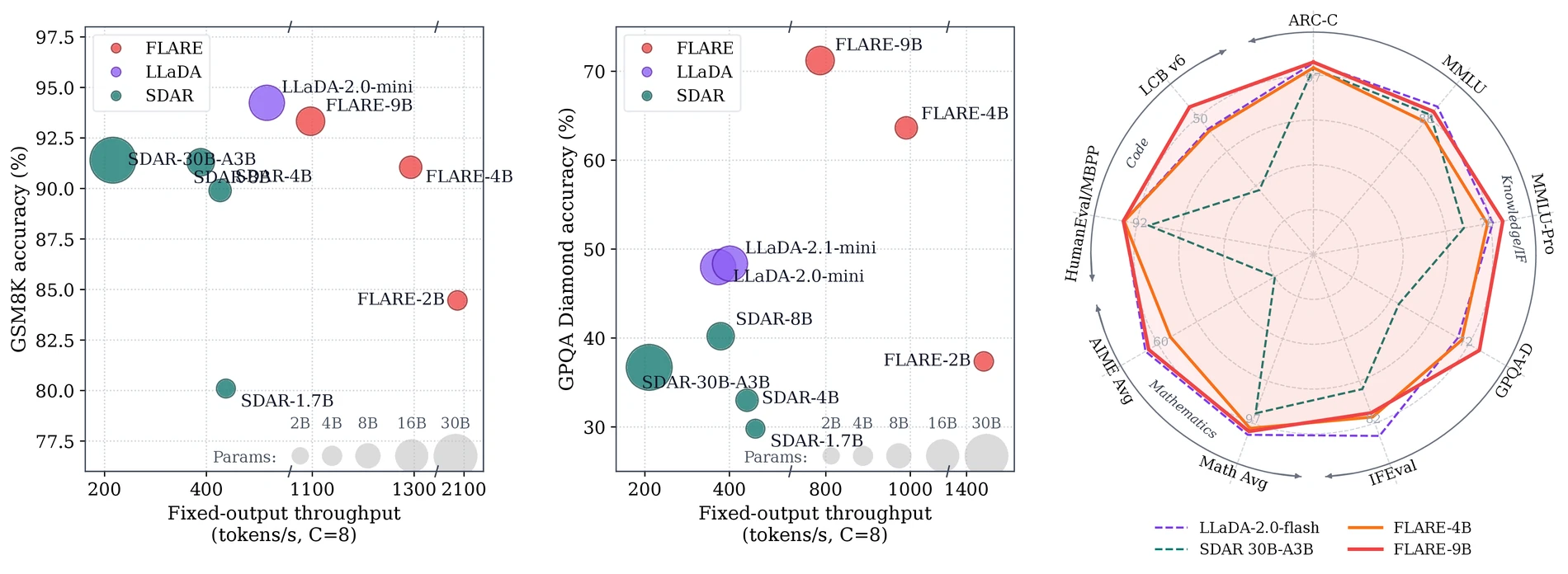
첫째, FLARE-2B/4B/9B는 Qwen3.5 하이브리드 어텐션 체크포인트에서 약 10B token의 단일 SFT stage로 변환된 것으로 설명된다.
프로젝트 페이지는 FLARE 숫자가 별도 표시가 없는 경우 AR-Trust speculative decoding 기준이라고 밝힌다.
둘째, 품질은 원본 AR source model에 “가깝게” 유지된다.
예를 들어 프로젝트 페이지 표에서 FLARE-9B는 MATH-500 95.20으로 Qwen3.5-9B의 96.60에 가깝고, AIME-24는 63.33 대 65.56, MMLU-Pro는 77.39 대 81.39로 제시된다.
MBPP에서는 FLARE-9B가 91.05로 Qwen3.5-9B의 89.11보다 높게 보고된다.
다만 IFEval이나 일부 code benchmark에는 여전히 잔여 격차가 있다.
셋째, throughput에서는 dLLM baseline 대비 분명한 이득을 주장한다.
프로젝트 페이지의 single A100-80GB, bf16, SGLang, max_new_tokens=2048, concurrency C=8 조건에서 FLARE-2B는 GSM8K 2087 tokens/s, FLARE-4B는 1293.2, FLARE-9B는 1096.5를 보고한다.
같은 조건의 LLaDA-2.1-mini는 963.0, SDAR-1.7B는 438.3이다.
따라서 페이지가 말하는 “open dLLM 대비 최대 4.8×”는 FLARE-2B와 SDAR-1.7B의 GSM8K C=8 비교에서 나온 수치로 읽는 것이 안전하다.
| 항목 | 공개 자료에서 보이는 형태 |
|---|---|
| 변환 출발점 | Qwen3.5 계열 하이브리드 어텐션 AR 체크포인트 |
| 전이 예산 | 약 10B token, 단일 SFT stage |
| 모델 규모 | FLARE-2B / FLARE-4B / FLARE-9B |
| 대표 디코딩 | AR-Trust speculative, Diffusion-Trust parallel denoising |
| 서빙 측정 | SGLang, A100-80GB, bf16, concurrent serving |
| 공개 상태 | 논문·프로젝트 페이지 공개, 코드와 모델은 coming soon |
왜 전이가 되는가: objective보다 데이터가 더 중요해지는 구간
FLARE 논문에서 흥미로운 부분은 단순 성능표보다 controlled study다.
저자들은 Qwen3-1.7B seed를 고정하고 약 10B-token budget, 12개 benchmark suite에서 어떤 요소가 AR-to-dLLM transfer를 살리는지 분해한다.
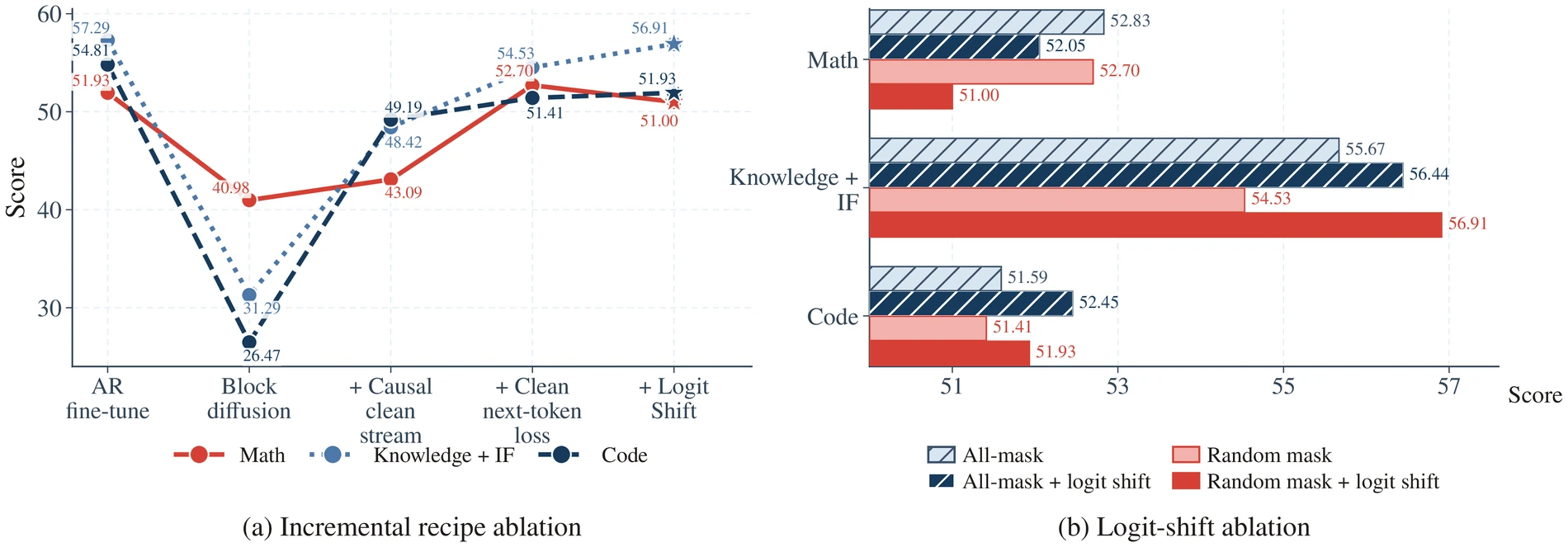
가장 큰 레버는 clean stream alignment다.
순수 block diffusion objective로 바꾸면 capability group 평균이 크게 무너지고, 프로젝트 페이지는 이 하락을 평균 -21.8pt로 요약한다.
여기에 token-causal AR clean stream을 복원하면 평균 +14.0pt가 회복된다.
그 다음 clean next-token loss와 logit shift를 더하면 수학 성능과 디코딩 compatibility가 더 안정화된다.
하지만 논문이 더 강조하는 결론은 “일단 objective와 mask가 맞으면, 남은 차이는 데이터가 지배한다”에 가깝다.
프로젝트 페이지는 cheap AR fine-tuning 결과가 converted dLLM 품질을 꽤 잘 추적한다고 설명한다.
즉 expensive dLLM conversion을 매번 돌리기 전에, 같은 data mix로 AR-SFT를 해 보고 data recipe를 선별할 수 있다는 뜻이다.
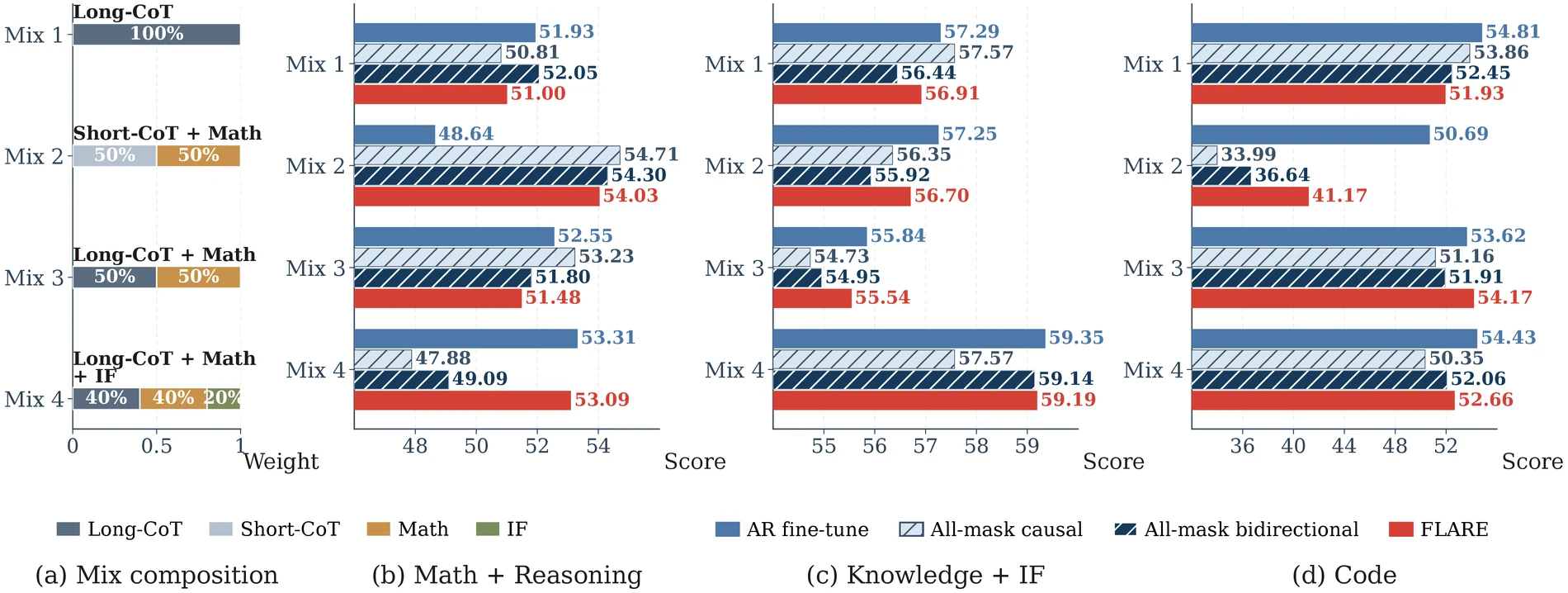
이 지점은 실무적으로 중요하다. dLLM 연구는 종종 sampler나 mask 설계 중심으로 설명되지만, FLARE는 “좋은 전이 데이터가 없으면 dLLM conversion도 source model 능력을 보존하기 어렵다”는 쪽에 무게를 둔다.
논문 결론도 practical dLLM의 병목이 decoding algorithm만이 아니라 objective, data, architecture, inference system의 공동 설계라고 정리한다.
실무 관점에서의 해석
FLARE를 바로 “공개 dLLM 신모델”로만 읽으면 핵심을 놓치기 쉽다.
지금 가장 중요한 메시지는 모델 카드나 checkpoint 릴리스가 아니라, 강한 AR 하이브리드 모델을 capability-preserving dLLM으로 변환하는 공정이다.
AR 모델의 지식을 clean stream에 고정하고, noisy stream에 디퓨전 경로를 열고, 그 둘을 실제 하이브리드 어텐션 커널에서 돌아가게 만드는 것이 논문의 중심이다.
이 접근은 최근 diffusion LM 흐름에서 중요한 중간 지점을 만든다.
순수 dLLM을 처음부터 학습하는 것은 비용과 품질 리스크가 크다.
반대로 AR 모델에 speculative decoding만 붙이면 병렬 계획 능력을 모델 내부 objective로 학습시키는 데 한계가 있다.
FLARE는 둘 사이에서 “강한 AR checkpoint를 seed로 삼고, 제한된 후처리 예산으로 dLLM-style decoding surface를 추가한다”는 경로를 제시한다.
다만 한계도 명확하다.
논문 스스로 block-diffusion training이 clean view와 noisy view를 이어 붙이는 2L 입력을 쓰기 때문에 per-step compute와 memory가 대략 두 배로 늘어난다고 적는다.
커널은 GPU utilization을 끌어올려 이 overhead를 완화하지만, two-stream formulation 자체의 비용을 없애지는 않는다.
또한 best data mix에서도 원본 AR source model 대비 일부 benchmark 격차가 남고, 논문 검증 범위는 10B 미만 dense checkpoint와 단일 SFT stage에 머문다.
MoE backbones, RL post-training, 더 큰 scale은 미래 과제로 남아 있다.
릴리스 성숙도도 아직 초기다.
공식 페이지의 Code/Models가 coming soon이므로, 지금의 FLARE는 “바로 가져다 쓸 수 있는 배포형 오픈 모델”이라기보다 논문과 프로젝트 페이지로 공개된 변환 레시피 및 시스템 설계로 보는 것이 맞다.
실제 팀이 도입을 검토하려면 코드 공개 이후 kernel 구현, SGLang integration, checkpoint license, 데이터 레시피, 재현 가능한 throughput 조건을 다시 확인해야 한다.
그럼에도 방향성은 크다. dLLM의 실용화가 “샘플러를 몇 step으로 줄였는가”가 아니라, 좋은 AR 모델을 어떻게 전이하고, 하이브리드 백본의 state를 어떻게 맞추고, 같은 checkpoint를 어떤 serving policy로 운영할 것인가의 문제라면, FLARE는 그 질문을 꽤 정면으로 다룬다.
디퓨전 LM을 AR의 대체재가 아니라 AR 체크포인트 위에 얹히는 병렬 디코딩 운영면으로 다시 해석하게 만드는 논문이다.
Sources:
- arXiv abstract: https://arxiv.org/abs/2606.01774
- arXiv PDF: https://arxiv.org/pdf/2606.01774
- Official project page: https://tokflare.github.io/