이미지 생성 모델의 품질이 올라갈수록 병목은 더 선명해진다.
1024×1024 해상도에서 DiT/flow-matching 계열 모델을 50 step으로 돌리면, 샘플링 자체가 제품 경험의 대기시간이 된다.
MrFlow 논문은 Qwen-Image-20B의 1024 해상도 샘플링이 A100에서 최대 47초 수준까지 갈 수 있다고 설명한다.
이 정도면 “좋은 이미지 모델”이어도 인터랙티브한 도구 안에 넣기 어렵다.
Multi-Resolution Flow Matching: Training-Free Diffusion Acceleration via Staged Sampling은 이 문제를 모델 재학습이나 커스텀 커널이 아니라 샘플링 경로의 해상도 배분으로 푼다.
핵심은 저해상도에서 전역 구조를 빠르게 잡고, 픽셀 공간 super-resolution으로 1차 복원한 다음, 약한 노이즈와 한두 번의 고해상도 flow refinement로 세부 묘사를 다시 맞추는 것이다.
이 글에서 볼 포인트는 “저해상도 생성 후 업스케일”이라는 익숙한 아이디어가 아니라, 왜 MrFlow가 latent-space upsampling 대신 pixel-space super-resolution과 low-strength noise를 조합했는가다.
논문의 주장은 간단하다.
구조는 저해상도에서 충분히 정해지고, 고해상도 모델은 전체 이미지를 처음부터 다시 만들 필요 없이 잘못된 고주파 디테일만 다시 샘플링하면 된다.
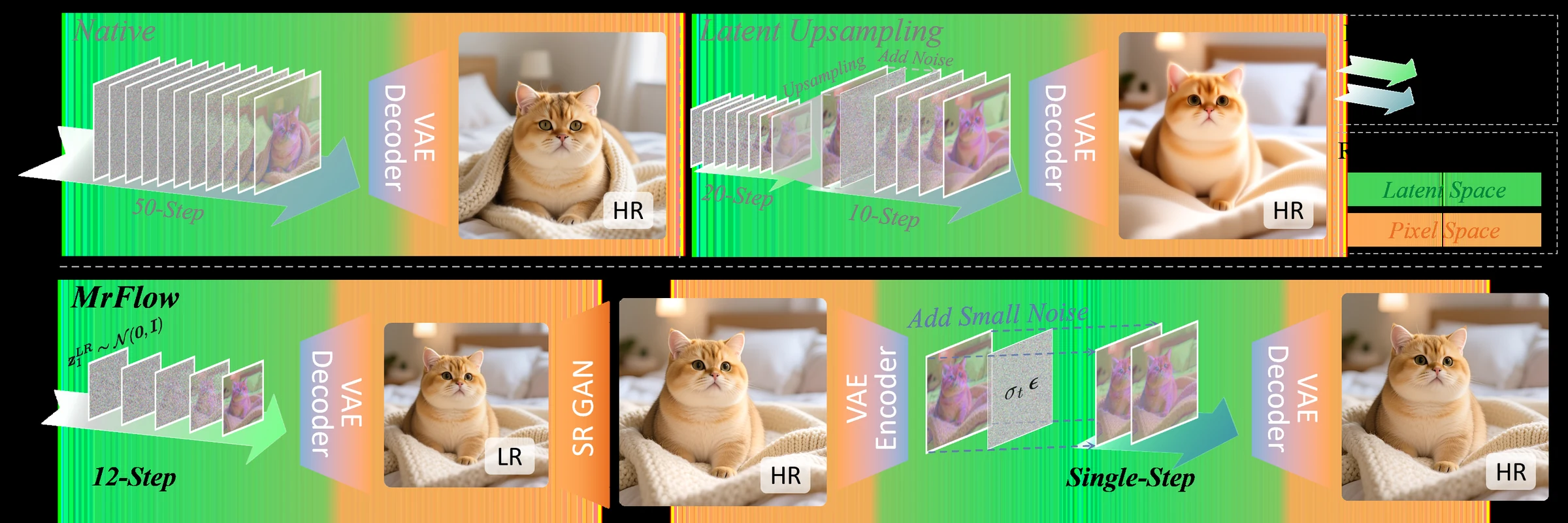
공식 GitHub asset.
MrFlow는 저해상도 latent sampling → VAE decode → pixel-space super-resolution → VAE encode → 약한 노이즈 주입 → 고해상도 refinement로 이어지는 staged pipeline을 쓴다.
무엇을 해결하려는가
Diffusion/flow-matching 이미지 모델을 빠르게 만드는 방법은 이미 여러 갈래가 있다.
Timestep distillation은 NFE를 50–100에서 1–4 수준까지 줄일 수 있지만 별도 학습이 필요하다.
Feature caching은 학습 없이 적용할 수 있지만 공격적인 speedup에서는 품질이 무너질 수 있다.
Token pruning/merging은 일반적이지만 실제 end-to-end speedup은 제한적이다.
Multi-resolution generation은 그 중간 지점에 있다.
이미지 한 변을 절반으로 줄이면 image token 수가 대략 4분의 1이 되고, attention 성분만 보면 더 큰 이득도 기대할 수 있다.
문제는 기존 방식이 latent space나 frequency domain에서 업스케일을 수행하면서 blur, artifact, 구조적 깨짐을 만들기 쉽다는 점이다.
논문은 특히 latent-space upsampling과 부분 영역 선택이 고주파 디테일을 망가뜨릴 수 있다고 본다.
MrFlow는 이 문제를 “저해상도 구조”와 “고해상도 디테일”의 역할 분리로 다시 짠다.
저해상도 stage는 prompt의 semantic layout과 전역 구조를 빠르게 고정하고, super-resolution stage는 픽셀 공간에서 자연스러운 디테일 후보를 만든다.
이후 아주 약한 noise를 넣어 SR artifact를 일부 흐트러뜨린 뒤, 원래의 pretrained flow prior로 마지막 디테일을 보정한다.
핵심 아이디어 / 구조 / 동작 방식
기본 pipeline은 다음 순서다.
| 단계 | 동작 | 왜 필요한가 |
|---|---|---|
| Low-resolution latent sampling | 낮은 해상도 latent에서 12–20 step 샘플링 | token 수가 줄어 per-step 비용이 낮고, 전역 구조를 빨리 잡는다. |
| VAE decode | 저해상도 latent를 pixel image로 복원 | latent upsampling 대신 pixel-space SR을 쓰기 위한 변환이다. |
| Pixel-space SR | Real-ESRGAN ×2 등으로 1024 해상도까지 업스케일 | global layout을 보존하면서 plausible high-frequency detail을 넣는다. |
| VAE encode | 업스케일 이미지를 다시 고해상도 latent로 변환 | pretrained flow model의 고해상도 prior가 작동할 공간으로 돌려놓는다. |
| Low-strength noise | 보통 σ≈0.1–0.15 수준의 약한 noise를 주입 | SR이 만든 잘못된 고주파 디테일을 다시 샘플링할 여지를 만든다. |
| HR refinement | 고해상도에서 1 step 또는 소수 step 보정 | 구조를 유지한 채 local detail만 pretrained prior로 정리한다. |
논문과 README가 반복해서 강조하는 대표 설정은 12plus1이다.
12번의 저해상도 denoising, Real-ESRGAN ×2 super-resolution, 그리고 sigma=0.12 부근에서 시작하는 1번의 고해상도 refinement다.
더 품질을 보수적으로 가져가려면 20plus1처럼 저해상도 step을 늘리는 운영점도 제시된다.
흥미로운 부분은 마지막 1 step이다.
저자들은 고해상도 refinement가 clean image endpoint 근처에서 시작하므로 trajectory가 비교적 곧고, 작은 strength에서는 한 번의 Euler step만으로도 주요 보정이 충분하다고 설명한다.
Appendix의 CLIP similarity 분석에서도 s=0.1에서는 1-step denoising이 5-step denoising에 매우 가깝게 나온다.
공개된 근거에서 확인되는 점
논문은 FLUX.1-dev와 Qwen-Image를 중심으로 training-free baseline과 비교한다.
핵심 headline은 MrFlow가 aggressive speed regime에서 품질 붕괴 없이 8–10× 수준의 end-to-end acceleration을 달성한다는 것이다.
| 모델 / 방법 | 설정 | Speedup | Geneval | DPG | OneIG-En / Zh |
|---|---|---|---|---|---|
| FLUX.1-dev native | 50 NFE | 1× | 0.66 | 84.07 | 0.44 / - |
| FLUX.1-dev MrFlow | 20, 1 | 5.78× | 0.65 | 82.19 | 0.39 / - |
| FLUX.1-dev MrFlow | 12, 1 | 8.25× | 0.63 | 81.65 | 0.36 / - |
| Qwen-Image native | 50×2 NFE | 1× | 0.88 | 88.67 | 0.53 / 0.53 |
| Qwen-Image MrFlow | 20, 1 ×2 | 6.98× | 0.87 | 88.00 | 0.54 / 0.52 |
| Qwen-Image MrFlow | 12, 1 ×2 | 10.3× | 0.86 | 87.10 | 0.52 / 0.51 |
이 표에서 중요한 것은 단순히 speedup 숫자가 아니다.
같은 training-free 범주에서 TeaCache나 DB-Taylor는 8–9× 구간에서 Qwen-Image의 Geneval/DPG가 크게 떨어지는 반면, MrFlow는 native 대비 작은 손실로 남아 있다.
논문 abstract의 “OneIG 1% gap 이내”라는 표현도 이 흐름을 가리킨다.
다만 metric별로 손실 폭은 다르므로, 모든 품질 지표가 완전히 보존된다는 뜻으로 읽으면 안 된다.
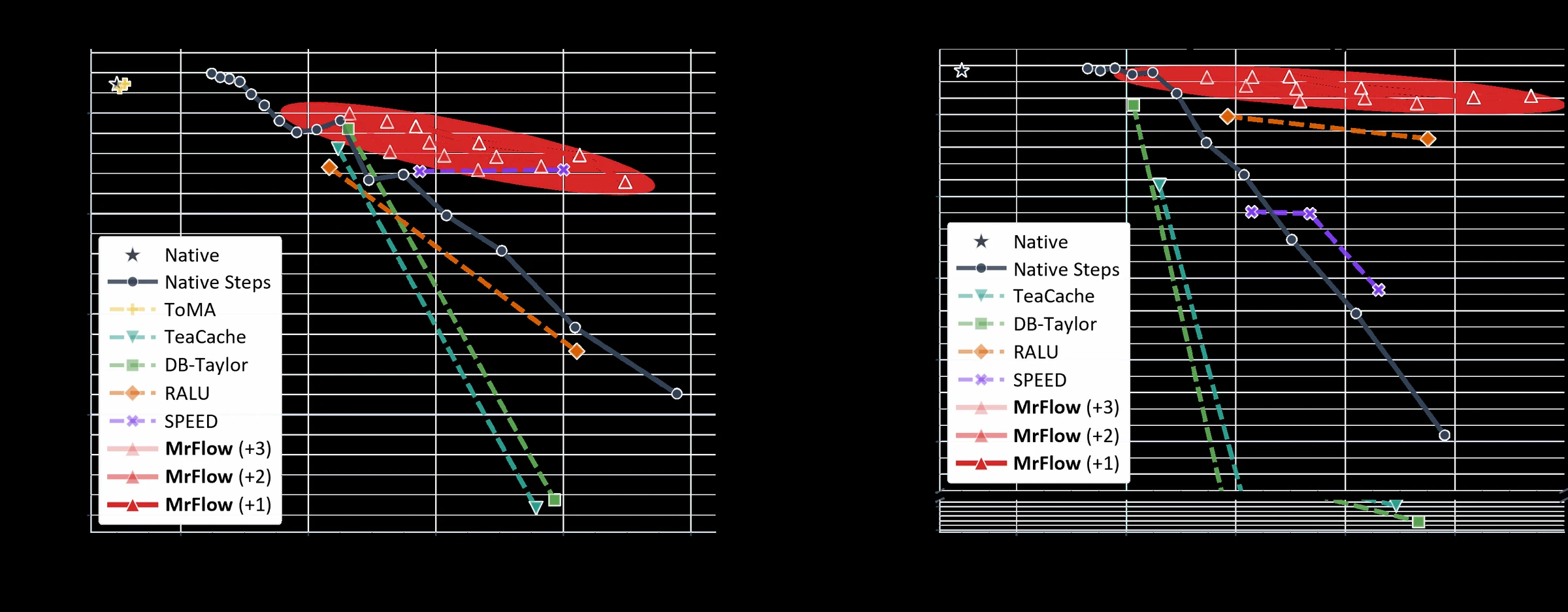
공식 arXiv HTML Figure.
FLUX.1-dev와 Qwen-Image에서 training-free 가속 방법들의 품질-속도 trade-off를 비교한다.
MrFlow는 공격적인 speedup 구간에서 비교적 완만한 품질 저하를 보인다.
Training-dependent 방법과의 조합도 흥미롭다.
MrFlow 자체는 training-free지만, 이미 timestep-distilled model이 있으면 그 위에 다시 얹을 수 있다.
논문은 FLUX.1-dev에서 Pi-Flow와 결합한 MrFlow†가 11.3×, FLUX-schnell과 결합한 MrFlow‡가 19.5×에 도달한다고 보고한다.
Qwen-Image + Pi-Flow 조합에서는 4, 1 설정으로 25.1× speedup을 제시한다.
즉 MrFlow는 distillation을 대체한다기보다, distillation된 sampling path에도 붙일 수 있는 별도 축에 가깝다.
Qwen-Image 12plus1의 runtime breakdown은 왜 이 방식이 빠른지 더 직접적으로 보여준다.
| 항목 | Native 50×2 | MrFlow 12,1 ×2 |
|---|---|---|
| Text encoding | 0.067s | 0.067s |
| Low-resolution sampling | - | 3.2s |
| Mid VAE decode | - | 0.035s |
| Super-resolution | - | 0.18s |
| VAE encode | - | 0.083s |
| High-resolution sampling | 49s | 1.0s |
| Final VAE decode | 0.14s | 0.14s |
| Total | 약 49s | 약 4.8s |

공식 arXiv HTML Figure.
Native Qwen-Image에서는 고해상도 diffusion forward가 대부분의 시간을 차지하지만, MrFlow는 비용을 저해상도 sampling과 짧은 HR refinement로 분산한다.
Super-resolution 선택도 별도 ablation으로 확인된다.
Qwen-Image 12,1 조건에서 Real-ESRGAN은 10.3× speedup, Geneval 0.86, DPG 87.10을 보인다.
Interpolation도 metric만 보면 비슷하지만, 논문은 실제 visual comparison에서 blur가 남고, OSEDiff는 문자나 local detail이 틀어질 수 있다고 설명한다.
그래서 MrFlow의 설계 포인트는 “SR이면 무엇이든 된다”가 아니라, GAN 기반 pixel-space SR이 global layout을 유지하면서 local detail 후보를 만들고, 이후 flow refinement가 그 후보를 다시 검증한다는 데 있다.
정성 예시도 이 논문의 주장에 중요하다.
MrFlow는 단순 latency 표가 아니라 Qwen-Image와 FLUX 샘플에서 texture, 문자형 디테일, 복잡한 장면 구성을 비교한다.
특히 text-to-image 모델에서 빠른 sampling은 종종 “이미지는 나오지만 글자·패턴·세부 구조가 흐려지는” 방식으로 실패하는데, MrFlow는 이 실패를 high-resolution refinement로 완화하려 한다.

공식 GitHub asset.
Qwen-Image에서 MrFlow 12plus1 설정으로 만든 예시.
논문은 10× 이상 speedup 조건에서도 다양한 고해상도 샘플을 유지한다고 제시한다.
코드와 공개 아티팩트 상태
arXiv abstract는 공식 코드 링크로 Xingyu-Zheng/MrFlow를 제시한다.
GitHub 저장소는 Apache-2.0 라이선스이며, 글 작성 시점의 공개 tree에는 qwen_image_mrflow.py, flux1_mrflow.py, mrflow_utils.py, examples/, ComfyUI-MrFlow/, assets/, community/가 있다.
별도 GitHub release나 tag는 아직 보이지 않는다.
| 표면 | 확인한 내용 | 해석 |
|---|---|---|
| arXiv 2607.01642v1 | 방법, main results, ablation, extended FLUX.2 Klein/Z-Image 결과 제공 | 논문의 실험 근거와 수식 설명의 중심 |
| GitHub README | FLUX.1-dev, Qwen-Image, FLUX.2 Klein, Z-Image 계열 demo와 speedup 표 제공 | paper-only가 아니라 실행 스크립트가 공개된 초기 구현 |
| Root scripts | qwen_image_mrflow.py, flux1_mrflow.py, shared scheduler helper |
최소 reference implementation 중심 |
| examples/ | Pi-Flow 조합, FLUX.2 Klein, Z-Image-Turbo 예시 포함 | 여러 backbone으로 확장하려는 의도가 보임 |
| ComfyUI-MrFlow/ | Qwen-oriented custom node, workflow/API JSON, subgraph 제공 | 연구 코드뿐 아니라 ComfyUI workflow로도 확산하려는 표면 |
| releases/tags | latest release 404, tags 없음 | 아직 버전 고정된 패키지라기보다 빠르게 업데이트되는 초기 공개 repo로 보는 편이 안전 |
공식 GitHub asset.
저장소는 ComfyUI-MrFlow/ custom-node와 예시 workflow JSON을 함께 공개한다.
다만 checkpoint path와 Real-ESRGAN weight는 사용자가 로컬에서 맞춰야 한다.
실행 관점에서는 “pip install 한 줄로 끝나는 라이브러리”로 보기는 어렵다.
README는 target backbone에 맞는 Diffusers 환경, Real-ESRGAN x2 weight, 로컬 checkpoint path 수정을 요구한다.
Pi-Flow 예시는 별도 LakonLab checkout도 필요하다.
따라서 지금의 공개 상태는 productized acceleration plugin이라기보다, 연구 아이디어를 재현·이식하기 위한 reference implementation과 ComfyUI extension의 중간 단계다.
실무 관점에서의 해석
MrFlow가 실무적으로 흥미로운 이유는 이미지 생성 추론 비용을 “모델 자체를 작게 만들기”나 “커널을 새로 짜기”가 아니라, sampling trajectory의 어디에 계산을 쓸지로 바꾼다는 점이다.
이미 훈련된 flow-matching 모델을 유지한 채, 저해상도 stage에 구조 생성을 맡기고 고해상도 stage는 detail correction으로 축소한다.
이 사고방식은 serving 팀이 모델 weight를 건드리지 않고도 latency-quality trade-off를 조절할 수 있는 여지를 만든다.
특히 제품 관점에서는 12plus1과 20plus1 같은 discrete operating point가 중요하다.
“가장 빠른 모드”와 “더 안정적인 모드”를 나누어 사용자 옵션으로 노출하거나, preview generation에는 12plus1, 최종 export에는 20plus1을 쓰는 식의 정책을 만들 수 있다.
Distilled backbone이 있을 경우 MrFlow를 다시 얹어 더 공격적인 preview path를 만드는 것도 가능하다.
하지만 제한도 분명하다.
첫째, 품질 평가는 자동 metric과 정성 샘플에 의존하므로, 제품에서 중요한 문자 정확도·브랜드 로고·인물 identity·세밀한 패턴은 별도 검증이 필요하다.
둘째, Real-ESRGAN이 만드는 고주파 후보가 항상 의미적으로 맞는 것은 아니다.
논문은 low-strength noise와 HR refinement가 이를 보정한다고 보지만, prompt 유형에 따라 SR artifact가 남을 수 있다.
셋째, VAE decode/encode와 SR stage가 추가되므로, 작은 모델이나 낮은 해상도에서는 speedup 양상이 다르게 나올 수 있다.
내가 보기에 MrFlow의 가장 좋은 포지션은 “모든 diffusion 모델을 10배 빠르게 만드는 만능 버튼”이 아니라, 고해상도 flow-matching T2I 모델에서 전역 구조와 고주파 디테일을 분리해 latency budget을 재배치하는 sampler다.
고해상도 생성 비용이 큰 FLUX/Qwen-Image류 모델에는 설득력이 있고, 이미 distillation이나 few-step model을 쓰는 환경에서도 orthogonal하게 붙을 가능성이 있다.
반대로 품질 허용 오차가 극도로 낮거나, SR artifact가 치명적인 산업 디자인·정밀 도면·의료 이미지 같은 영역에서는 별도의 task-specific 검증 없이 headline speedup만 믿기는 어렵다.
그래도 이 논문이 주는 메시지는 꽤 실용적이다.
이미지 생성 inference는 단순히 NFE를 줄이는 문제가 아니라, 어느 해상도에서 어떤 정보를 결정할지의 문제다.
MrFlow는 구조는 싸게 만들고, 디테일은 짧게 고치는 쪽으로 그 답을 제시한다.