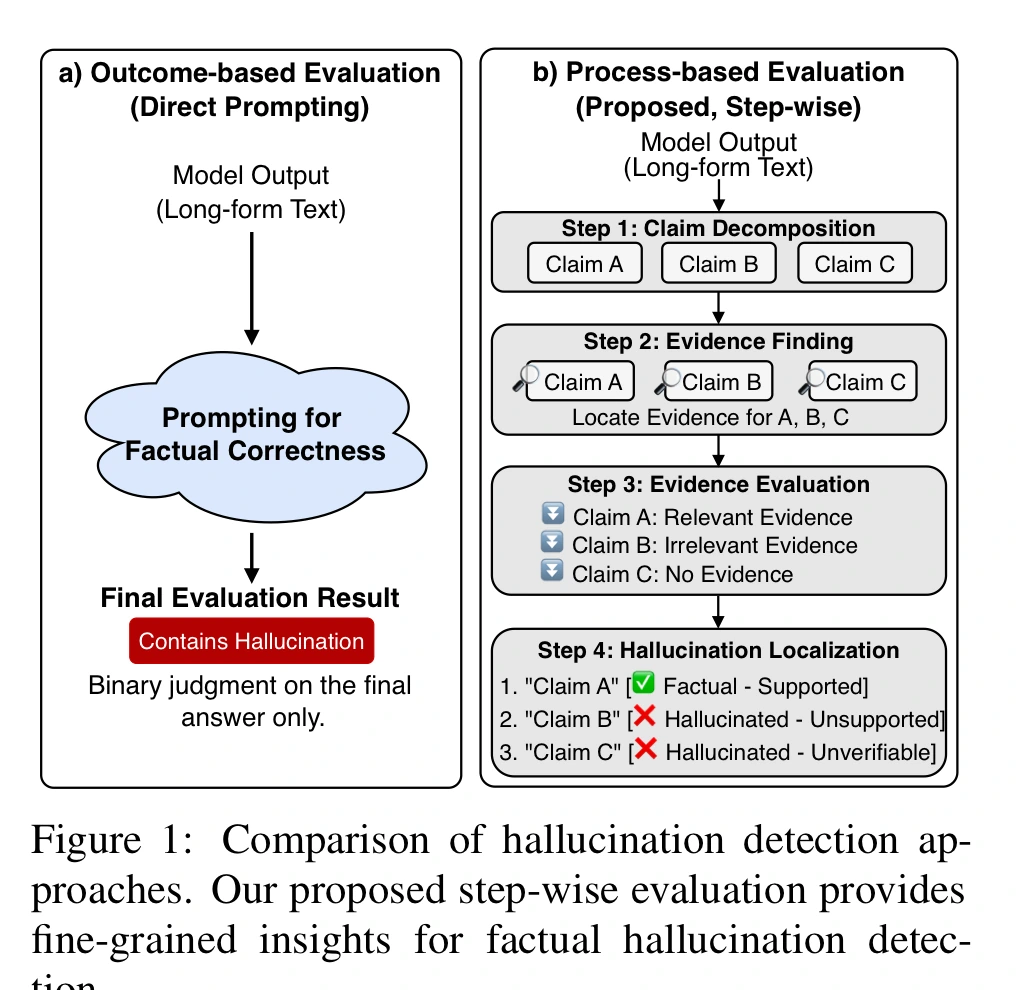
LLM 환각 탐지는 보통 “이 답변이 사실인가 아닌가”라는 최종 판정 문제로 다뤄진다.
모델에게 전체 답변과 근거 문서를 주고, 환각이 있는지 직접 물어보는 식이다.
이 방식은 구현이 쉽지만, 실패했을 때 원인을 알기 어렵다. claim을 잘못 쪼갠 것인지, 근거를 못 찾은 것인지, 근거는 찾았지만 support 여부를 잘못 판단한 것인지가 모두 한 점수 안에 묻힌다.
PROBE: PROcess-Based BEnchmark for Hallucination Detection는 이 병목을 평가 설계의 문제로 본다.
논문은 환각 탐지를 하나의 judge prompt가 아니라 claim decomposition → evidence finding → evidence evaluation → hallucination localization으로 이어지는 검증 과정으로 분해한다.
그리고 각 단계를 따로 측정해, 현재 LLM이 환각 탐지에서 실제로 어디서 무너지는지를 보여주려 한다.
이 작업은 ACL 2026 Findings에 실린 CUHK와 NVIDIA 연구진의 논문이다.
핵심 산출물은 12,000개 테스트 케이스와 약 11.8만 개 claim annotation을 가진 process-based hallucination detection benchmark다.
논문 자체는 “released training data”를 전제로 파인튜닝 실험을 보고하지만, 확인 시점 기준 ACL Anthology 페이지와 PDF에는 별도 GitHub, Hugging Face, project page 링크가 직접 노출되어 있지는 않다.
따라서 현재 공개 표면에서 읽을 때는 paper와 checklist 중심의 벤치마크 제안으로 보는 편이 안전하다.
무엇을 해결하려는가
PROBE가 겨냥하는 환각은 “세상에 존재하지 않는 사실” 일반이 아니라, 주어진 source material에 충실하지 않은 생성이다.
논문은 이를 RAG식 설정으로 본다.
모델이 Wikipedia 기반 passage를 받고 요약, 질문응답, style transfer를 수행했을 때, 출력 안의 개별 claim이 source에 의해 지지되는지를 따지는 문제다.
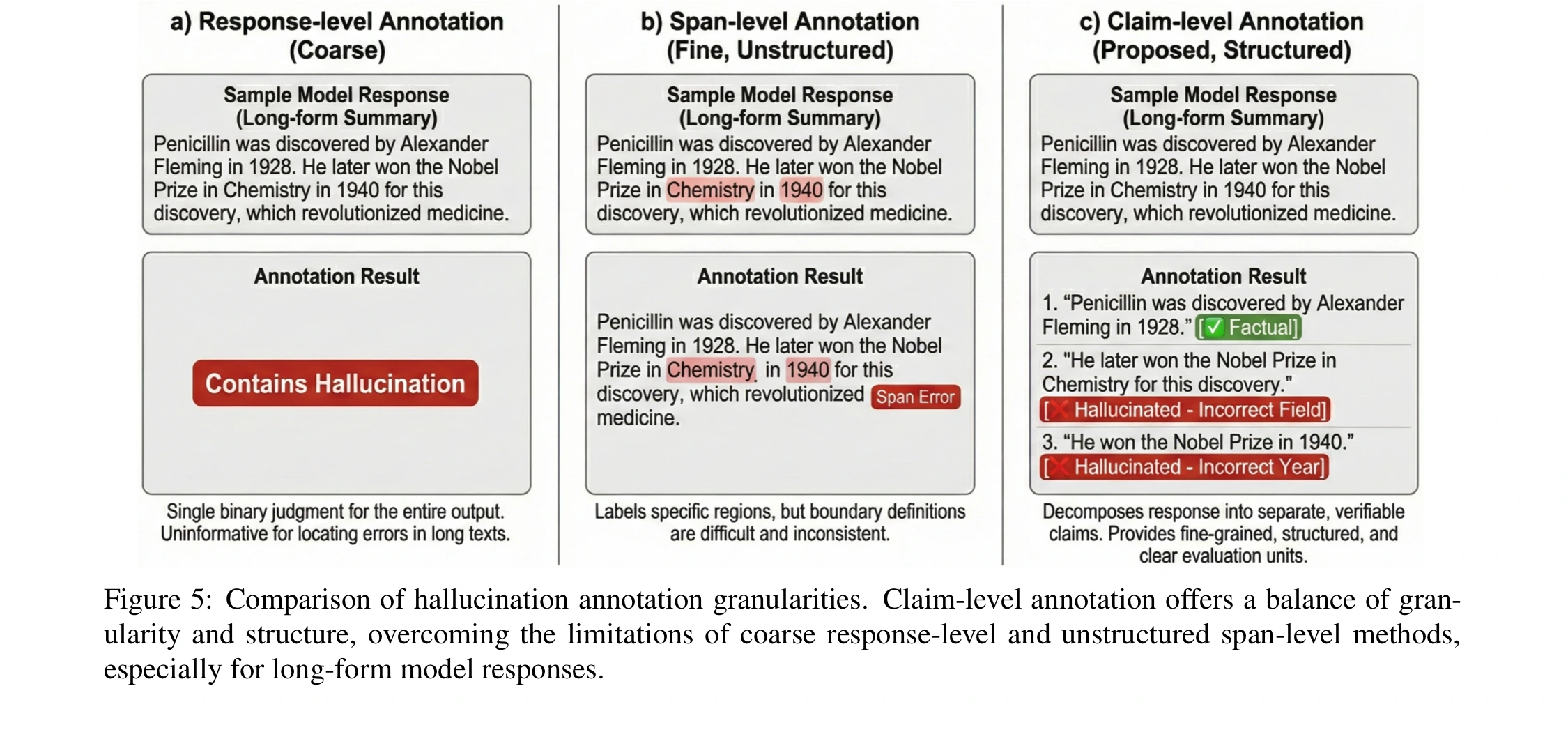
기존 benchmark의 약점은 평가 단위가 너무 거칠거나, 반대로 너무 비구조적이라는 데 있다. response-level label은 “환각 있음”만 알려주고 어디가 틀렸는지 알려주지 않는다. span-level annotation은 더 세밀하지만, 경계가 애매하다.
어디까지가 틀린 span인지, 같은 오류를 어떻게 일관되게 표시할지 어렵다.
PROBE는 그 중간 지점으로 claim-level annotation을 택한다.
하나의 긴 답변을 검증 가능한 atomic claim으로 나누고, 각 claim에 대해 evidence와 support 여부를 붙인다.
이 framing이 중요한 이유는 실무형 RAG 평가에서도 동일하다.
“답변이 틀렸다”는 사실만으로는 retrieval을 고쳐야 하는지, generator를 고쳐야 하는지, verifier prompt를 고쳐야 하는지 알 수 없다.
반면 claim decomposition, evidence finding, evidence evaluation이 분리되어 있으면 실패 지점이 운영 지표가 된다.
핵심 아이디어 / 구조 / 동작 방식
PROBE의 데이터 생성은 세 단계다.
먼저 Clean Wikipedia English Articles에서 3,000개 문서를 뽑고, 각 문서로부터 요약, 질문응답, style transfer 출력을 만든다.
그 다음 세 가지 complexity 수준의 plausible hallucination을 synthetic하게 삽입한다.
마지막으로 claim을 분해하고, 원문 Wikipedia에서 supporting evidence를 찾고, evidence가 claim을 support하는지 평가해 claim-evidence pair를 만든다.
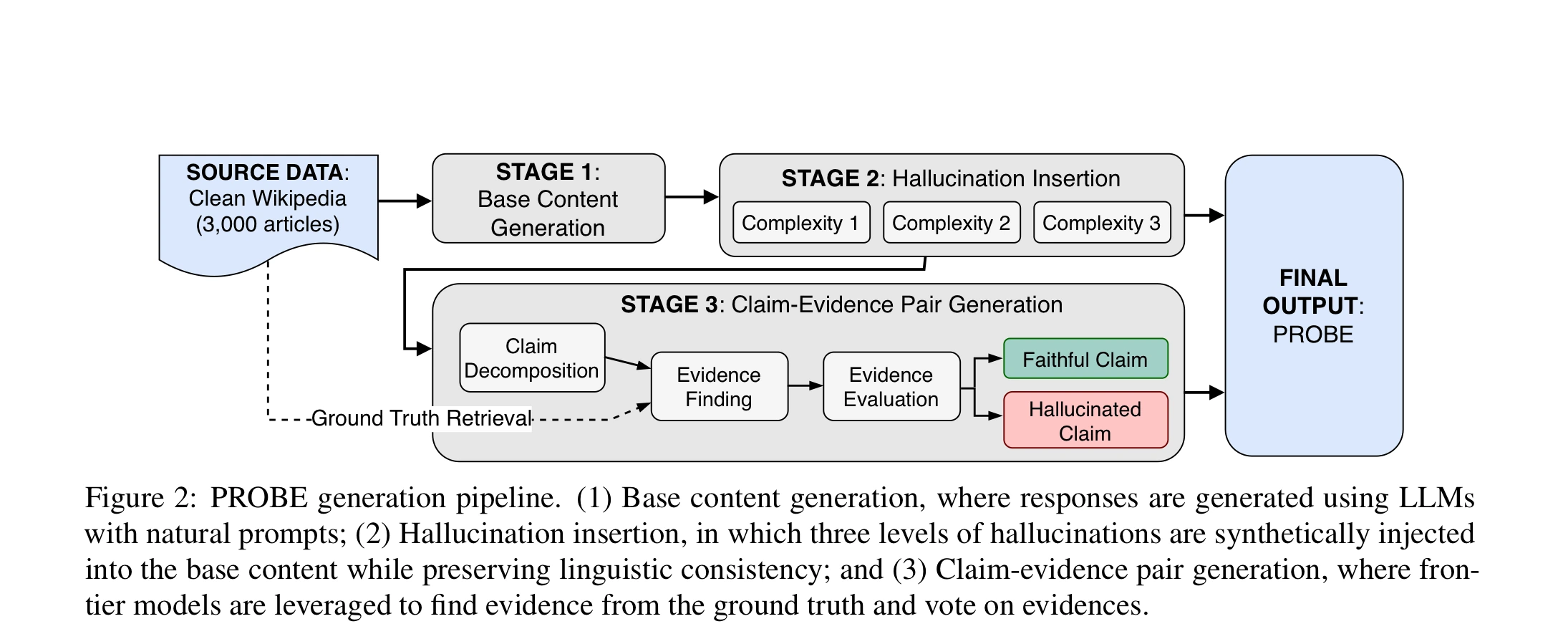
세부적으로는 각 task마다 1,000개 hallucination-free baseline sample과 3,000개 hallucination-injected sample을 둔다.
그래서 summarization, question answering, style transfer 세 task를 합쳐 총 12,000개 response가 된다.
논문은 GPT-OSS-120B를 base generation과 hallucination insertion에 사용하고, Llama-3.1-70B, GPT-4o-mini, Mixtral-8x22B, Claude-Sonnet-4.5 같은 frontier model을 evidence finding과 voting 과정에 활용했다고 설명한다.
| 구성 요소 | PROBE에서 하는 일 | 평가 관점의 의미 |
|---|---|---|
| Claim decomposition | 긴 답변을 검증 가능한 atomic claim으로 분해 | “무엇을 검증해야 하는가”를 명시 |
| Evidence finding | 각 claim을 지지하거나 반박할 수 있는 source span을 찾음 | retrieval 또는 grounding 병목을 분리 |
| Evidence evaluation | 찾은 evidence가 claim을 support하는지 판정 | 근거 충분성 판단 능력을 측정 |
| Hallucination localization | support되지 않는 claim을 hallucinated로 표시 | 최종 binary label 대신 오류 위치를 남김 |
PROBE의 차별점은 hallucination detection을 “judge 모델이 잘하느냐”가 아니라, 검증 pipeline의 각 모듈이 잘하느냐로 바꾼 데 있다.
이 구조에서는 claim 추출은 잘하지만 evidence를 빠뜨리는 모델, evidence는 찾지만 support 판단이 흔들리는 모델, recall은 높지만 precision이 낮은 모델을 서로 다르게 볼 수 있다.
공개된 근거에서 확인되는 점
데이터 규모는 꽤 크다.
논문은 총 12,000개 response와 118,628개 claim을 보고한다.
이 중 hallucinated claim은 25,613개, high-confidence grounded claim은 92,925개다. task별로 보면 질문응답은 평균 응답 길이가 짧은 대신 hallucination 비율이 높고, 요약과 style transfer는 긴 응답 안에 더 많은 claim이 들어간다.
| Task | Response 수 | Claim 수 | Hallucinated claim | Response 내 hallucination 비율 |
|---|---|---|---|---|
| Summarization | 4,000 | 41,558 | 9,908 | 15.13% |
| Question Answering | 4,000 | 12,018 | 5,489 | 47.42% |
| Style Transfer | 4,000 | 65,052 | 10,216 | 16.93% |
| Overall | 12,000 | 118,628 | 25,613 | 29.96% |
가장 중요한 실험 결과는 evidence finding이 병목이라는 점이다. claim decomposition은 frontier LLM들이 비교적 잘한다.
논문 Figure 3 기준 recall은 일관되게 95%를 넘는다.
반면 evidence finding으로 내려오면 “적어도 하나의 supporting evidence를 찾는 것”과 “필요한 evidence를 모두 찾는 것” 사이에 큰 간격이 생긴다.
Table 2를 세 task 평균으로 요약하면 다음과 같다.
Partial evidence finding은 대체로 79–85% 수준이지만, complete evidence finding은 64–71%대로 내려간다.
근거 하나를 얼추 찾는 것과 claim을 충분히 검증할 만큼 모두 찾는 것은 다른 문제라는 뜻이다.
| 모델 | Partial EF 평균 | Complete EF 평균 | Evidence Evaluation 평균 |
|---|---|---|---|
| Llama-3.1-70B | 84.7 | 69.3 | 77.2 |
| GPT-4o-mini | 79.3 | 64.1 | 76.6 |
| Mixtral-8x22B | 79.0 | 64.3 | 76.6 |
| Claude-Sonnet-4.5 | 83.2 | 68.8 | 77.7 |
| SFT Llama-3.1-8B | 84.9 | 70.6 | 82.2 |
여기서 SFT Llama-3.1-8B 결과가 흥미롭다.
논문은 PROBE의 claim-evidence training data로 Llama-3.1-8B를 full-parameter fine-tuning했고, 이 모델이 evidence finding과 evidence evaluation에서 가장 좋은 평균 성능을 보였다고 보고한다.
특히 evidence evaluation 평균은 82.2로, 일반 frontier model들의 76–78 수준보다 높다.
즉 거대한 범용 judge를 쓰는 것보다, process supervision을 받은 더 작은 specialized model이 특정 검증 단계에서 나을 수 있다는 메시지다.
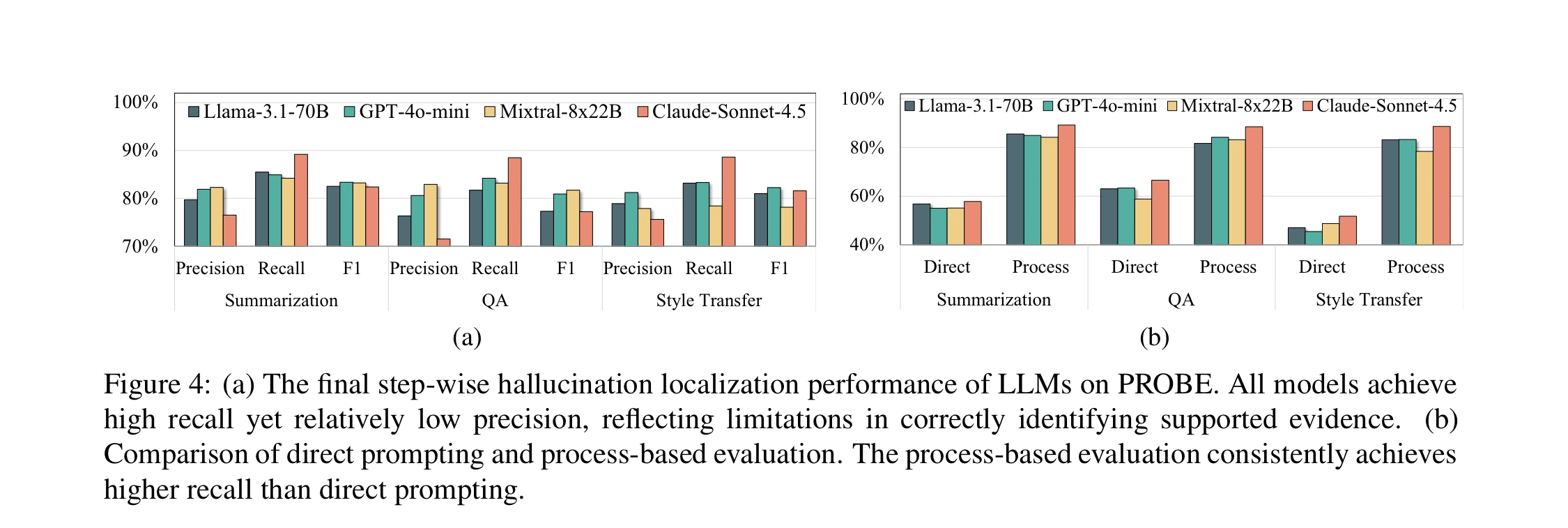
최종 hallucination detection에서도 차이는 크다.
직접 prompting은 recall이 40% 아래로 낮게 나오지만, process-based 방식은 대체로 80%를 넘고 best case에서는 90%에 가까워진다.
이는 “LLM에게 그냥 판단을 맡기는 것”보다, claim을 쪼개고 evidence를 찾고 support 여부를 따지는 절차를 강제하는 것이 훨씬 낫다는 근거다.
다만 결과는 무작정 낙관적으로 읽으면 안 된다.
Figure 4a에서 step-wise 방식은 recall은 높지만 precision이 낮다.
Claude-Sonnet-4.5는 recall 88.8%로 높지만 precision은 74.5%로 낮다고 설명된다.
즉 process를 쪼개면 놓치는 환각은 줄어들지만, evidence evaluation이 보수적으로 움직이면 supported claim까지 hallucinated로 잡아내는 비용이 생길 수 있다.
실무 관점에서의 해석
PROBE의 가장 큰 가치는 “환각 탐지기를 하나 더 만들었다”보다, 환각 탐지 시스템을 어떻게 관찰해야 하는지 보여주는 데 있다.
운영 환경에서는 답변 단위 pass/fail만으로는 개선 루프가 느리다. retrieval corpus를 보강해야 하는지, chunking을 바꿔야 하는지, answer generator를 더 보수적으로 만들어야 하는지, verifier prompt나 verifier model을 바꿔야 하는지 알기 어렵다.
PROBE식 decomposition을 적용하면 지표가 더 실용적으로 바뀐다.
예를 들어 evidence finding complete match가 낮으면 retrieval 또는 evidence selection 문제다. evidence evaluation accuracy가 낮으면 verifier가 evidence sufficiency를 잘못 판단하는 것이다. localization precision이 낮으면 support되는 claim까지 과도하게 flagging하는 false positive 문제다.
즉 각 단계가 제품 개선 backlog와 직접 연결된다.
또 하나 중요한 점은 long-form generation에서 claim-level 단위가 꽤 현실적이라는 것이다.
실제 보고서, 요약, 상담 답변, 법률·의료 보조 출력은 하나의 문장 안에도 여러 claim이 섞인다. response-level label은 너무 coarse하고, token/span-level label은 annotation 비용과 일관성이 어렵다. claim-level은 사람이 읽는 의미 단위와 verification pipeline의 단위를 비교적 잘 맞춘다.
하지만 한계도 뚜렷하다.
첫째, PROBE는 영어와 비전문 domain 중심이다.
금융, 의료, 법률처럼 evidence sufficiency 자체가 전문 지식을 요구하는 분야에서는 같은 pipeline을 쓰더라도 annotation policy와 verifier 기준을 다시 설계해야 한다.
둘째, process-based evaluation은 여러 번의 LLM invocation을 요구하므로 latency와 비용이 direct prompting보다 크다.
논문도 이 overhead를 limitations에서 명시한다.
셋째, synthetic hallucination insertion이라는 데이터 생성 방식은 통제 가능성을 주지만, 실제 모델이 자연스럽게 만드는 오류 분포와 완전히 같지는 않을 수 있다.
PROBE는 “모든 환각을 대표하는 benchmark”라기보다, source-grounded long-form generation에서 검증 과정을 분해하고 병목을 진단하기 위한 controlled benchmark로 읽는 편이 맞다.
마지막으로 release maturity는 아직 보수적으로 봐야 한다.
ACL Anthology 표면에는 PDF와 checklist만 명확히 보이고, 별도 code/data repository는 직접 연결되어 있지 않다.
논문이 말하는 training data와 specialized fine-tuning 결과는 중요하지만, 독자가 바로 benchmark를 다운로드해 evaluator를 돌릴 수 있는 공개 패키지인지 여부는 별도 확인이 필요하다.
그럼에도 PROBE가 던지는 방향은 매우 실용적이다.
앞으로 환각 탐지는 “더 강한 LLM judge를 붙인다”만으로 충분하지 않다.
좋은 시스템은 claim을 만들고, 근거를 찾고, 근거가 충분한지 판단하고, 오류 위치를 남기는 감사 가능한 검증 과정을 가져야 한다.
PROBE는 그 과정을 benchmark 문제로 명시했다는 점에서, RAG와 agent reliability 평가의 좋은 기준점이 될 만하다.