최근 오픈 웨이트 LLM 릴리스들을 보면, 흥미로운 변화가 하나 보인다.
더 큰 모델, 더 높은 벤치마크, 더 긴 컨텍스트라는 익숙한 경쟁은 계속되지만, 실제 아키텍처의 변화는 점점 더 좁고 구체적인 병목으로 향한다.
바로 긴 컨텍스트에서 KV cache, memory traffic, attention FLOPs를 어떻게 줄일 것인가다.
Sebastian Raschka의 Ahead of AI 글 「Recent Developments in LLM Architectures: KV Sharing, mHC, and Compressed Attention」는 이 흐름을 잘 묶어 준다.
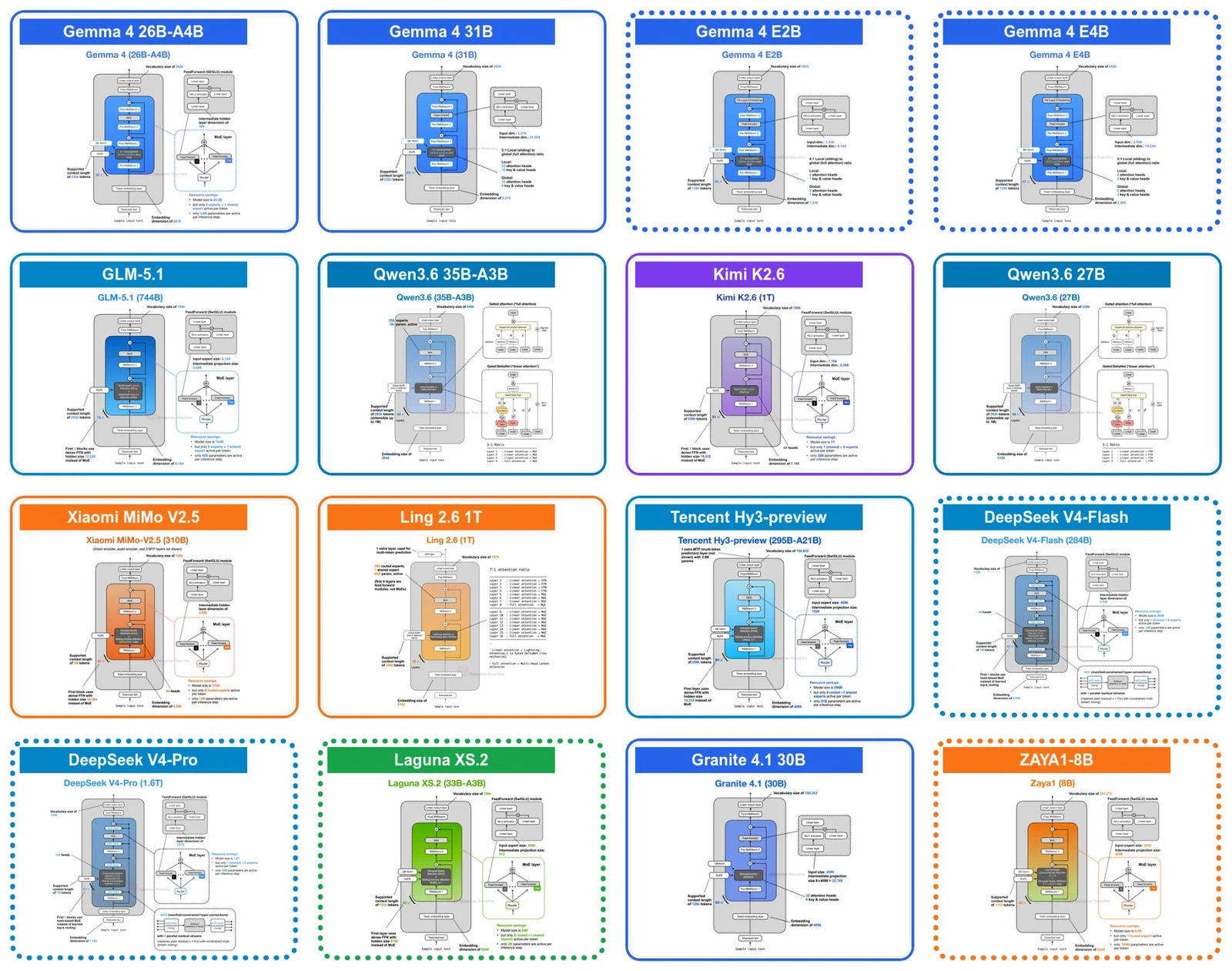
글의 대상은 2026년 봄 전후에 공개된 주요 오픈 웨이트 모델들이다.
Gemma 4, Laguna XS.2, ZAYA1-8B, DeepSeek V4처럼 서로 다른 회사와 모델군이지만, 공통 질문은 비슷하다. reasoning model과 agent workflow가 더 많은 토큰을 오래 들고 가는 시대에, 기존 transformer block을 어디까지 재배치해야 하는가.
내가 보기엔 이 글의 핵심 가치는 개별 모델 홍보를 다시 요약하는 데 있지 않다.
오히려 모델 카드나 benchmark table 뒤에 숨어 있는 설계 변화, 즉 transformer 내부의 KV cache, attention head budget, compressed latent attention, residual stream을 하나의 비용 절감 지도 위에 올려 놓는 데 있다.
PyTorch KR 커뮤니티에서 이 글이 별도로 소개된 것도 그 지점 때문이다.
한국어권 독자에게도 이제 “무슨 모델이 점수가 높다”보다 “왜 이 구조가 긴 문맥에서 더 싸게 돌아가는가”가 더 중요한 질문이 되고 있다.
무엇을 해결하려는가
LLM inference에서 긴 컨텍스트는 단순히 attention score 계산만 키우지 않는다.
매 토큰마다 이전 토큰들의 K/V 상태를 보관하고 다시 읽어야 하므로, 컨텍스트가 길어질수록 KV cache가 메모리와 bandwidth를 동시에 잡아먹는다.
특히 agent가 긴 tool trace를 유지하거나, reasoning model이 긴 중간 추론을 반복하거나, coding assistant가 큰 repository context를 붙잡고 있는 경우에는 이 비용이 곧 제품 latency와 운영비로 이어진다.
과거의 아키텍처 개선은 종종 “모델을 얼마나 크게 만들 것인가” 또는 “MoE로 총 파라미터와 활성 파라미터를 어떻게 분리할 것인가”에 집중했다.
하지만 Raschka가 이번 글에서 짚는 변화는 조금 다르다.
최근 모델들은 전체 parameter count를 줄이는 대신, 어떤 상태를 저장하고, 어떤 layer가 비싼 attention을 쓰고, 어떤 표현을 compressed latent로 유지하며, residual stream을 어떻게 안정적으로 넓힐지를 더 세밀하게 조정한다.
이 관점에서 Gemma 4의 cross-layer KV sharing, Laguna XS.2의 layer-wise attention budgeting, ZAYA1-8B의 Compressed Convolutional Attention(CCA), DeepSeek V4의 mHC와 CSA/HCA는 서로 다른 이름을 가진 같은 계열의 답변처럼 보인다.
모두 “긴 문맥을 더 길게 만든다”가 아니라, “긴 문맥을 감당 가능한 비용 구조로 바꾼다”는 문제를 푼다.
핵심 아이디어 / 구조 / 동작 방식
1) Gemma 4: layer마다 KV를 새로 만들지 않는다
Gemma 4 E2B와 E4B에서 가장 눈에 띄는 설계는 cross-layer KV sharing이다.
일반적인 transformer block은 각 layer의 attention module에서 Q, K, V projection을 따로 계산한다.
반면 cross-layer attention에서는 일부 layer가 자기 K/V를 새로 만들지 않고, 같은 attention type을 가진 이전 non-shared layer의 KV tensor를 재사용한다.
Query는 각 layer가 계속 계산하므로 layer별 attention pattern은 유지하지만, 메모리와 cache 측면에서 비싼 K/V 상태를 여러 layer가 나눠 쓰는 방식이다.
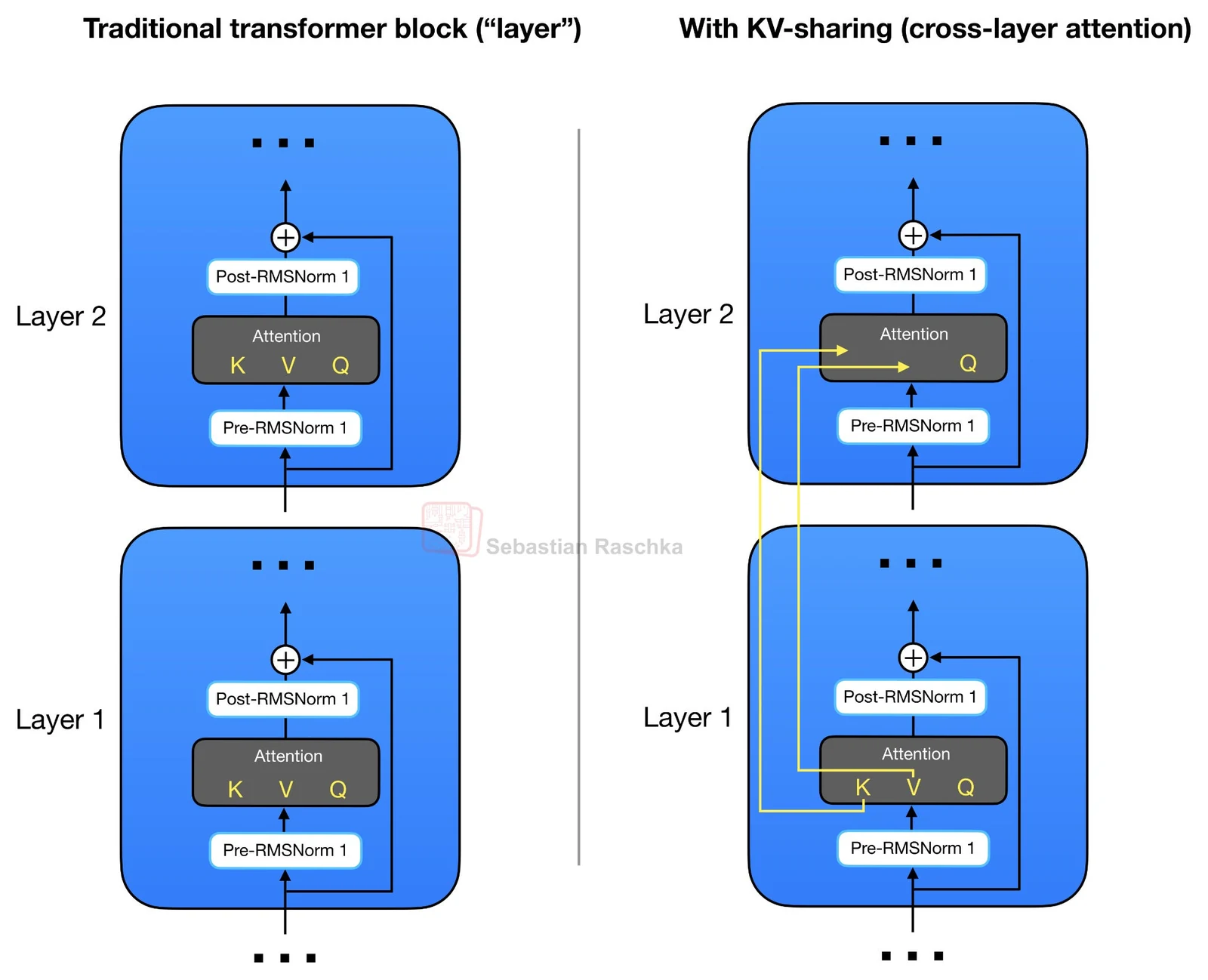
Raschka가 정리한 수치에 따르면 Gemma 4 E2B는 35개 transformer layer 중 처음 15개만 자기 KV projection을 계산하고, 마지막 20개 layer는 이전 non-shared layer의 KV를 재사용한다.
Gemma 4 E4B는 42개 layer 중 24개가 자기 KV를 계산하고, 마지막 18개가 공유한다.
대략 절반 가까운 KV를 공유하므로 128K context, bfloat16 기준으로 E2B는 약 2.7GB, E4B는 약 6GB의 KV cache 절감 효과가 나온다.
여기에 Gemma 4 E 계열은 PLE(per-layer embeddings)도 함께 쓴다.
PLE는 KV cache를 줄이는 장치라기보다는 parameter efficiency 장치다.
예를 들어 Gemma 4 E2B는 2.3B effective parameters이지만 embedding까지 세면 5.1B parameters로 설명되고, E4B도 4.5B effective / 8B with embeddings 구조를 가진다.
핵심은 transformer stack 자체를 모두 크게 키우지 않고, layer별 token-specific embedding slice를 통해 representational capacity를 보강하는 것이다.
2) Laguna XS.2: 모든 layer에 같은 attention 예산을 주지 않는다
Poolside의 Laguna XS.2는 겉으로 보면 비교적 표준적인 decoder-only 모델처럼 보이지만, config를 보면 layer-wise attention budgeting이 드러난다.
이 모델은 40개 layer 중 30개를 sliding-window attention layer로, 10개를 global/full attention layer로 구성한다. sliding-window layer는 512-token local window만 보므로 싸고, full attention layer는 전체 context를 볼 수 있지만 비싸다.
여기까지는 여러 최신 모델에서 볼 수 있는 hybrid attention 패턴이다.
Laguna XS.2의 더 흥미로운 부분은 query head 수를 layer마다 다르게 둔다는 점이다.
Hugging Face config의 num_attention_heads_per_layer는 full attention layer와 sliding-window layer가 서로 다른 query head budget을 갖도록 만든다.
KV head는 8개로 고정하면서, full attention layer는 KV head당 6 query heads, sliding-window layer는 KV head당 8 query heads를 쓰는 식이다.
이 설계는 꽤 실용적인 메시지를 준다.
전체 context를 보는 layer는 이미 비싸므로 query head 수를 줄이고, local window만 보는 layer에는 더 많은 query head를 배정한다.
즉 attention capacity를 균일하게 뿌리는 대신, layer의 역할과 비용에 따라 다르게 배치한다.
앞으로 LLM 아키텍처가 단순한 “N layers × same block”에서 벗어나, layer별 budget allocation 문제로 이동할 수 있다는 신호다.
3) ZAYA1-8B: attention 자체를 compressed latent 공간에서 수행한다
Zyphra의 ZAYA1-8B에서 핵심은 Compressed Convolutional Attention(CCA)다.
CCA는 DeepSeek 계열의 MLA(Multi-head Latent Attention)와 비슷하게 compressed latent representation을 attention block 안으로 들여오지만, 그 latent를 쓰는 방식이 다르다.
MLA는 주로 KV cache를 compact하게 저장한 뒤, 실제 attention 계산을 위해 다시 head space로 projection한다.
반면 CCA는 Q, K, V를 모두 압축하고, attention operation 자체를 compressed latent space에서 수행한다.
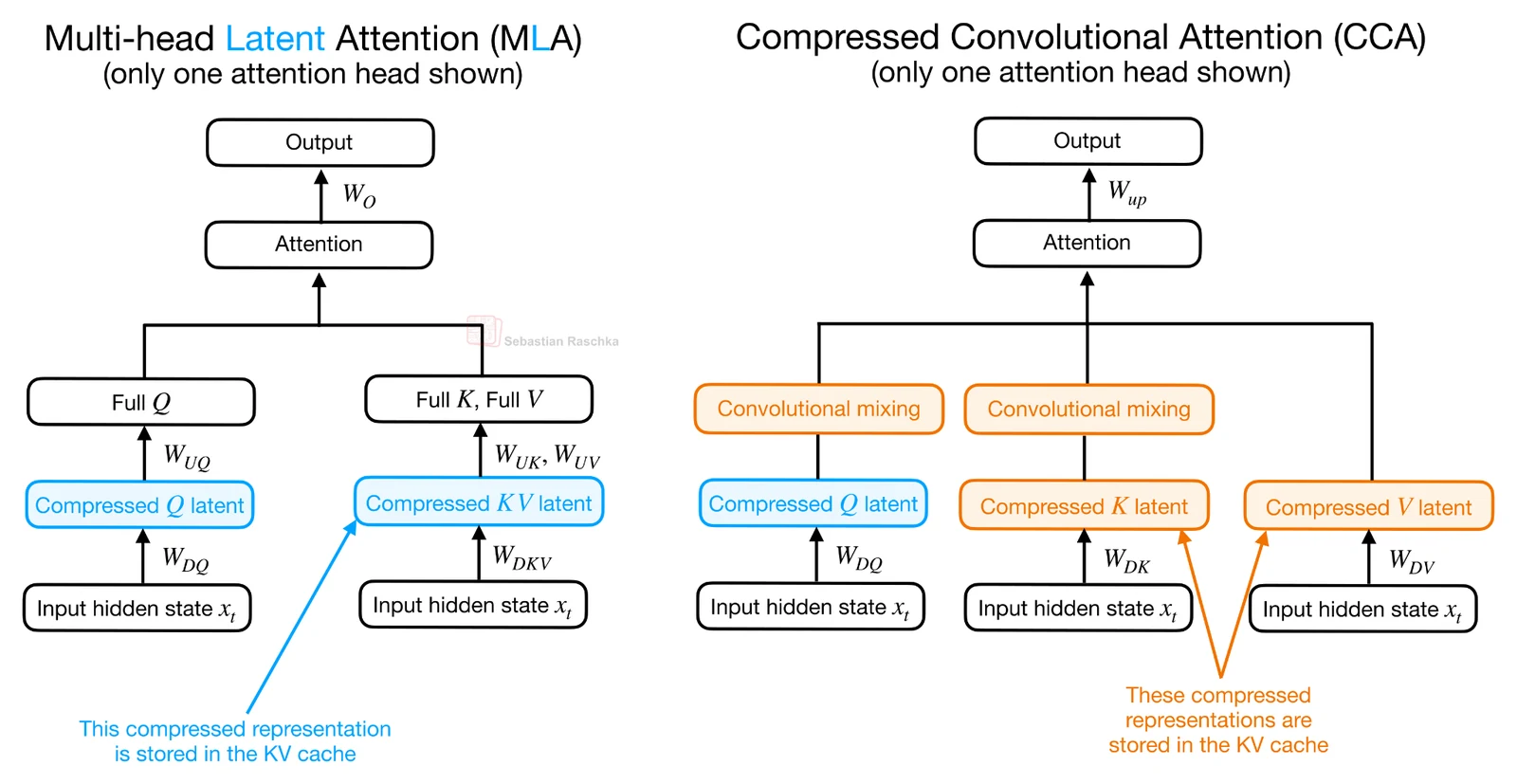
이 차이는 중요하다.
MLA가 “저장되는 KV 표현을 줄이는” 쪽에 가깝다면, CCA는 cache뿐 아니라 prefill과 training에서의 attention FLOPs까지 줄일 수 있는 방향이다.
다만 compressed attention은 표현력이 떨어질 수 있으므로, CCA는 compressed Q와 K에 convolutional mixing을 추가한다.
값 V가 아니라 attention score를 결정하는 Q/K 쪽에 local context를 저렴하게 섞어 주는 셈이다.
ZAYA1-8B의 공개 config도 이 해석을 뒷받침한다. cca: true, num_hidden_layers: 80, num_experts: 16, moe_router_topk: 1, max_position_embeddings: 131072 같은 설정이 보이며, Raschka는 이를 80개의 alternating layer entry, 즉 attention과 MoE feed-forward가 교차하는 구조로 읽는다.
CCA paper 자체의 실험에서는 comparable compression setting에서 CCA가 MLA보다 낫다고 보고하지만, 실무적으로는 “모든 경우의 범용 대체재”라기보다 compressed latent attention의 한 강한 설계 후보로 보는 편이 안전하다.
4) DeepSeek V4: residual stream과 long-context attention을 동시에 바꾼다
DeepSeek V4의 변화는 두 축으로 나눠 보는 것이 좋다.
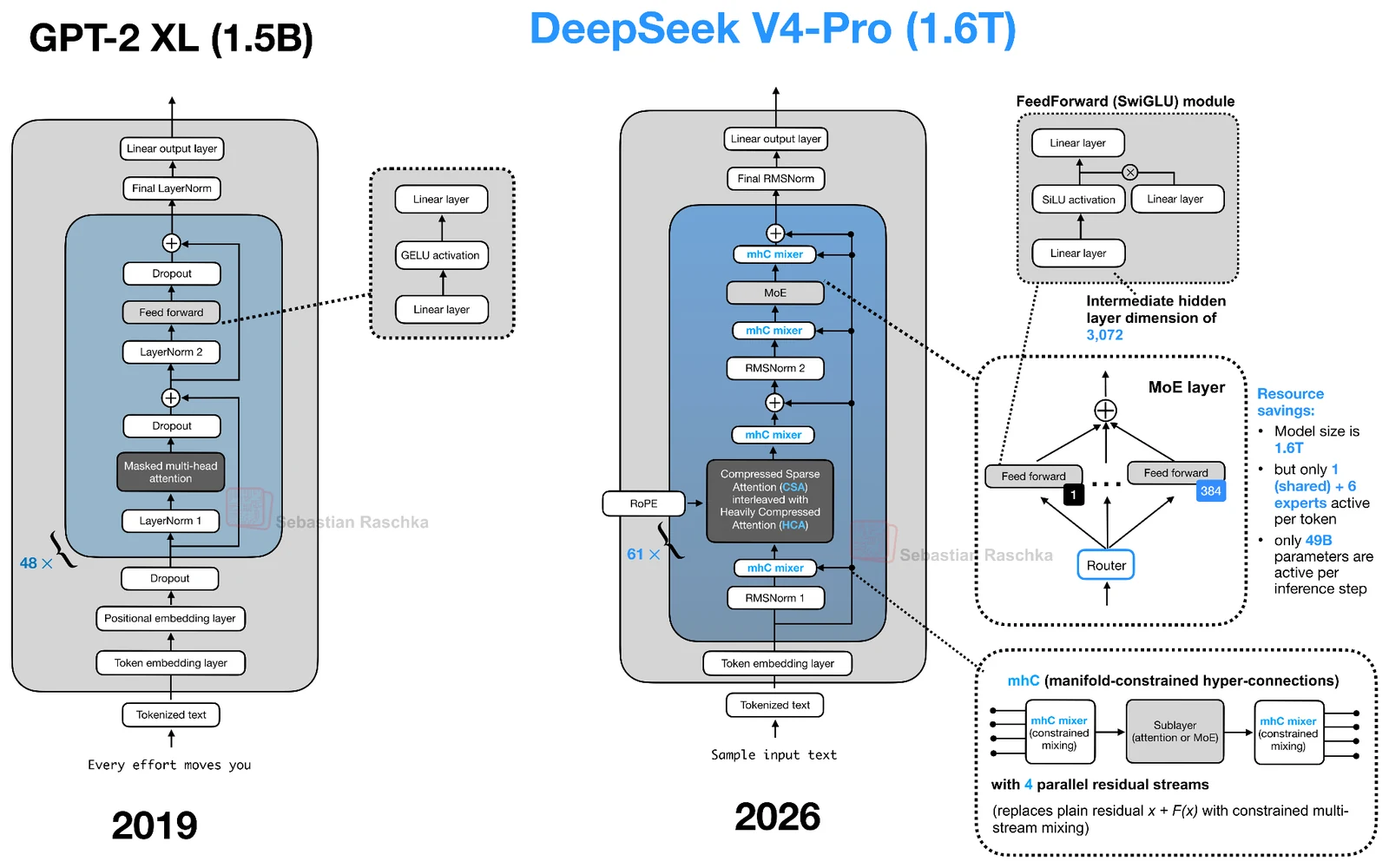
하나는 mHC(Manifold-Constrained Hyper-Connections)이고, 다른 하나는 CSA/HCA 기반 compressed long-context attention이다. mHC는 attention mechanism 자체가 아니라 residual connection 쪽의 변화다.
기존 transformer block이 하나의 residual stream을 계속 갱신한다면, hyper-connections는 여러 parallel residual streams를 두고 layer 사이에서 이들을 섞는다.
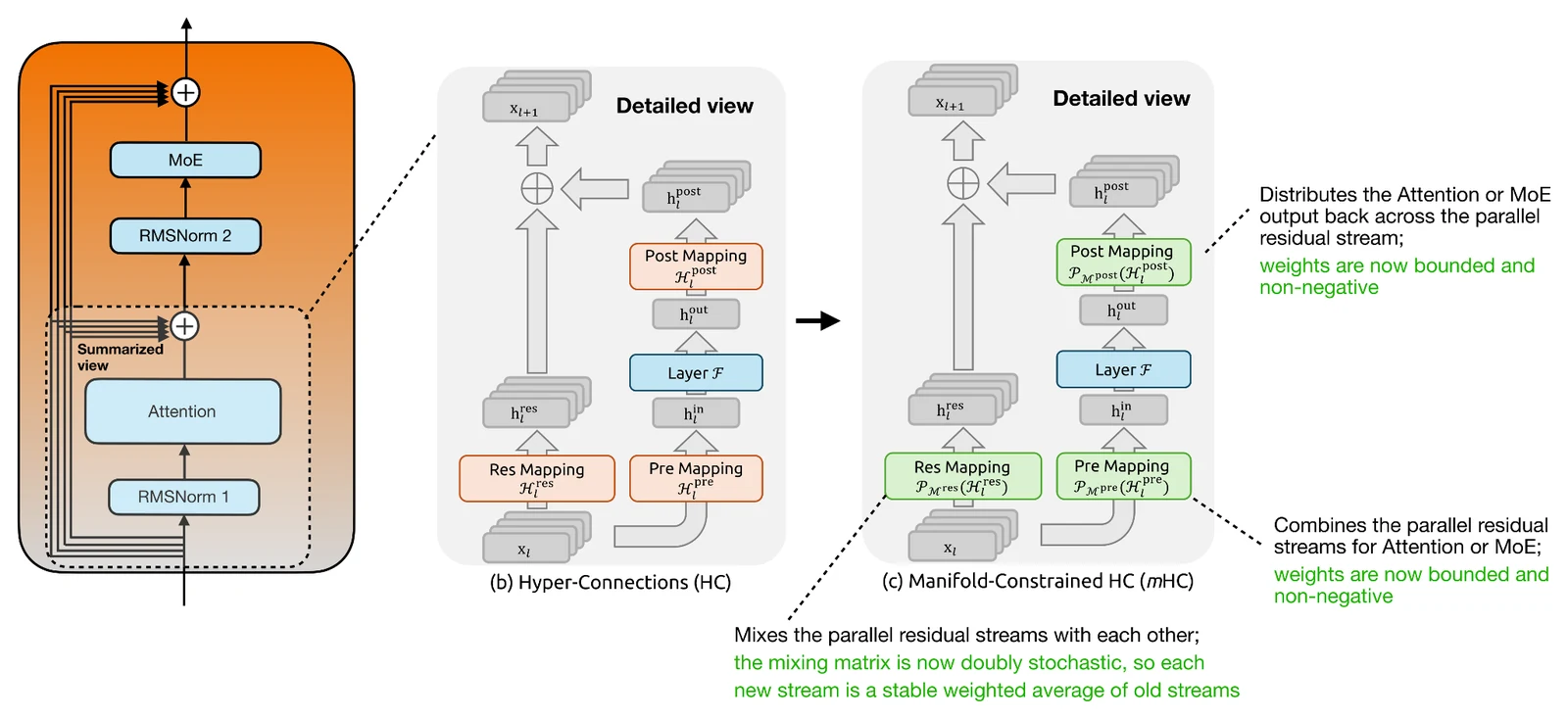
mHC의 핵심은 이 mixing을 아무 제약 없이 학습하지 않는다는 점이다. residual mapping을 doubly stochastic matrix manifold 위로 projection해, 행과 열의 합이 1이고 음수가 아닌 안정적인 재분배처럼 작동하게 만든다.
Pre Mapping과 Post Mapping도 non-negative, bounded 제약을 받는다.
결과적으로 여러 residual stream이 서로 정보를 주고받되, 깊은 모델에서 신호가 과도하게 커지거나 상쇄되는 위험을 줄인다.
Raschka가 인용한 mHC paper의 27B 실험에서는 4개 residual stream을 모든 block에 넣는 최적화 구현이 single-stream baseline 대비 6.7% 추가 training time overhead를 보였다고 한다.
attention 쪽에서는 CSA(Compressed Sparse Attention)와 HCA(Heavily Compressed Attention)가 등장한다.
여기서 중요한 구분은 MLA와의 차이다.
MLA는 token마다 하나의 compressed KV entry를 유지하므로 sequence length 자체는 그대로다.
반면 CSA와 HCA는 sequence dimension을 압축한다.
즉 여러 token을 하나의 compressed KV entry로 요약해 cache의 길이 자체를 줄인다.
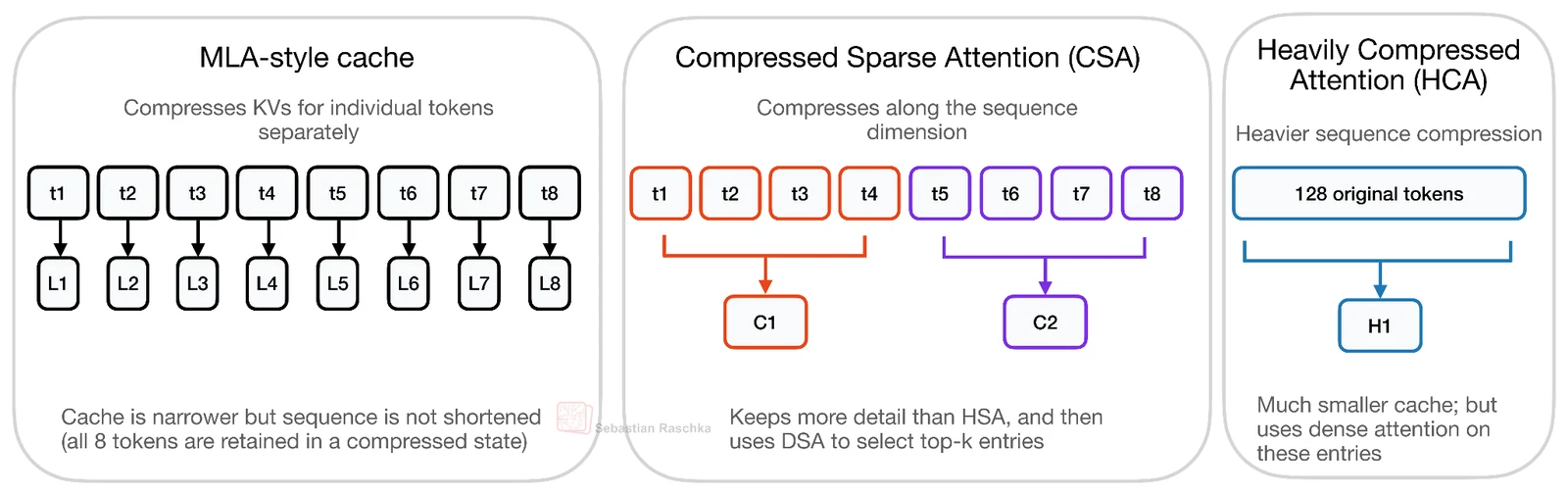
CSA는 비교적 약한 sequence compression과 sparse top-k selection을 결합한다.
HCA는 훨씬 강하게 압축해, 예컨대 128 tokens를 하나의 compressed KV entry로 만들고 그 짧아진 cache 위에서 dense attention을 수행한다.
두 방식 모두 최근 uncompressed token을 보는 sliding-window branch를 함께 두어, 멀리 있는 history는 압축해 싸게 보고 가까운 token은 더 정밀하게 보는 구조를 만든다.
공개된 근거에서 확인되는 점
Raschka의 글은 각 모델의 benchmark 우열을 다시 나열하기보다, 공개된 architecture diagram, config, paper claim을 통해 어떤 비용 축을 건드리는지 보여 준다.
이를 실무 관점에서 다시 정리하면 다음과 같다.
| 모델 / 설계 | 바뀐 부분 | 줄이려는 비용 | 주의할 점 |
|---|---|---|---|
| Gemma 4 E2B/E4B | cross-layer KV sharing, PLE | KV cache memory, transformer stack parameter cost | KV sharing은 capacity를 일부 줄이는 approximation이며, PLE 효과는 공개 비교 실험이 더 있으면 좋음 |
| Laguna XS.2 | layer별 query head budget, sliding/full attention 혼합 | full-context attention 비용, layer별 capacity 낭비 | 아키텍처 자체는 표준적으로 보이므로 config를 봐야 차이가 드러남 |
| ZAYA1-8B | CCA, compressed Q/K/V latent attention | KV cache, prefill/training attention FLOPs | compressed latent에서 attention을 하므로 표현력 보완을 위한 convolutional mixing이 중요 |
| DeepSeek V4 | mHC, CSA/HCA, sliding-window branch | residual path 안정성, 1M-context FLOPs, KV cache | CSA/HCA는 MLA보다 공격적인 sequence compression이므로 일반적으로 “더 낫다”보다 long-context efficiency design으로 봐야 함 |
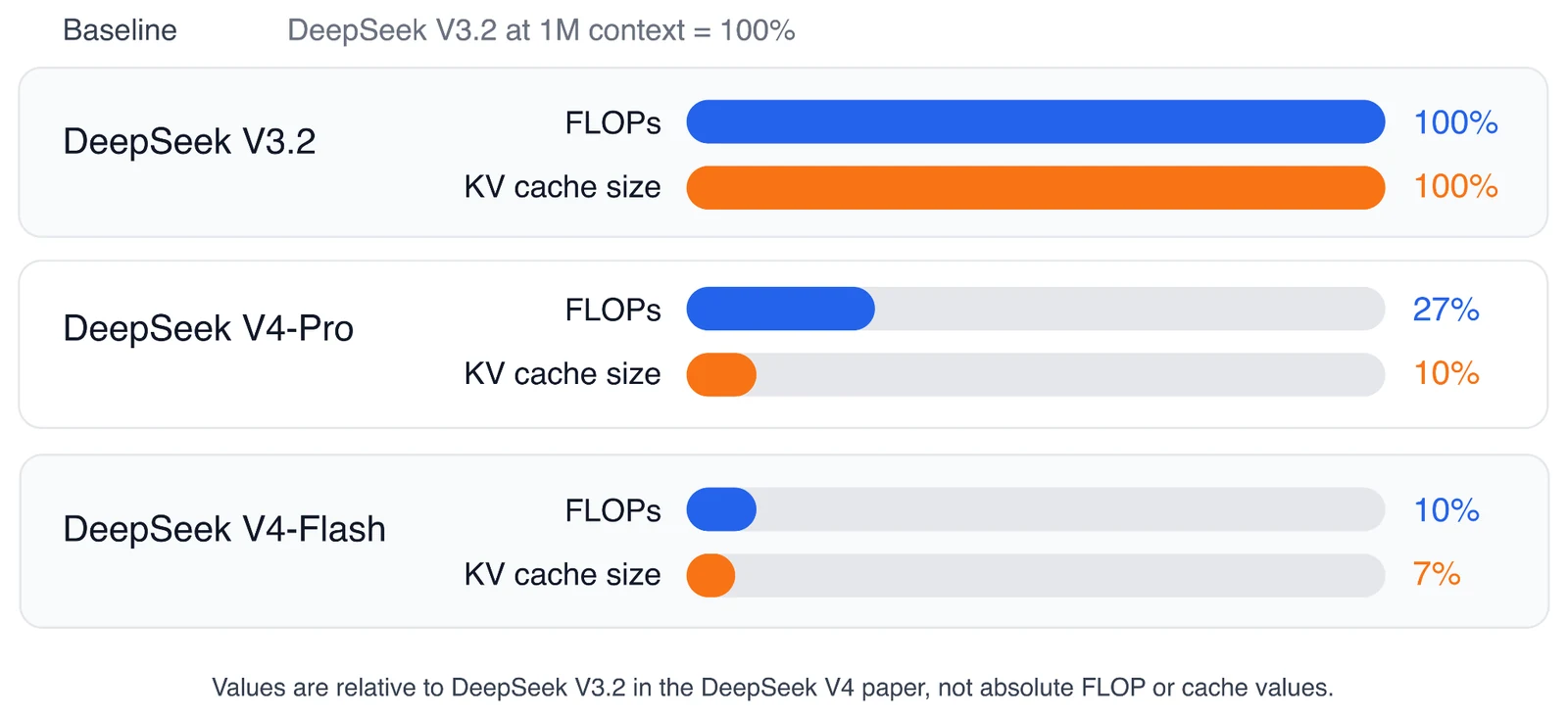
가장 눈에 띄는 숫자는 DeepSeek V4 쪽이다.
DeepSeek V4 paper 기준으로 1M-token context에서 DeepSeek V4-Pro는 DeepSeek V3.2 대비 single-token inference FLOPs가 27%, KV cache size가 10% 수준이라고 보고된다.
DeepSeek V4-Flash는 더 작아서 FLOPs 10%, KV cache 7% 수준으로 제시된다.
이 수치가 중요한 이유는 단순히 “더 긴 context를 지원한다”가 아니라, 긴 context에서 실제 inference economics를 얼마나 바꿨는지 보여 주기 때문이다.
동시에 과도한 일반화는 피해야 한다.
Raschka도 CSA/HCA를 MLA보다 일반적으로 우월하다고 말하지 않는다.
CSA/HCA는 sequence length 자체를 줄이는 더 공격적인 long-context 설계이고, MLA는 per-token KV representation을 compact하게 만드는 다른 축의 압축이다.
압축률이 높아질수록 token-level detail을 잃을 수 있으므로, DeepSeek V4의 결과는 mHC, Muon optimizer, 데이터, training recipe, system optimization까지 포함한 전체 recipe의 결과로 읽어야 한다.
또 하나 중요한 근거는 Hugging Face config와 API에서 보이는 release surface다.
Laguna XS.2 config에는 실제로 num_attention_heads_per_layer가 들어 있고, ZAYA1-8B config에는 cca: true, moe_router_topk: 1, max_position_embeddings: 131072가 드러난다.
ZAYA1-8B와 Laguna XS.2 모두 Apache 2.0 license tag를 갖고 있으며, DeepSeek V4-Pro는 MIT license tag와 모델 파일·encoding/inference 자료를 함께 공개한다.
즉 이 논의는 논문 속 speculation만이 아니라 실제 공개 모델 패키징 표면에서도 확인되는 변화다.
실무 관점에서의 해석
내가 보기에 이 흐름의 가장 큰 의미는 LLM 아키텍처가 다시 “시스템 문제”가 되고 있다는 점이다.
모델 품질을 올리는 일은 여전히 데이터, post-training, RL, distillation에 크게 의존하지만, 긴 컨텍스트를 실제 제품에 넣는 순간 병목은 cache layout, memory movement, attention schedule, residual-state stability로 내려온다.
즉 앞으로의 오픈 모델 비교는 parameter count나 benchmark 평균만으로 설명하기 어려워질 가능성이 크다.
특히 agent와 coding assistant에서는 이 변화가 바로 체감된다. agent는 긴 action history와 tool result를 계속 들고 있고, coding assistant는 repository context를 반복적으로 참조한다.
여기에 reasoning model의 long trace까지 더해지면, 단순히 context window를 1M으로 늘렸다는 말만으로는 부족하다.
그 1M context에서 한 토큰을 생성할 때 FLOPs와 KV cache가 얼마인지, local window와 global attention을 어떻게 섞는지, cache를 layer 간 공유하는지, compressed sequence entry를 쓰는지가 실제 latency를 좌우한다.
또한 이 흐름은 구현 난도를 크게 높인다.
예전에는 decoder-only transformer block을 비교적 짧은 PyTorch 코드로 구현하고 이해할 수 있었다면, 이제는 GQA, sliding-window attention, cross-layer KV sharing, MLA, CCA, CSA/HCA, MoE routing, residual stream mixing, custom encoding까지 겹친다.
Raschka가 마지막에 지적하듯, 이런 변화는 런타임 비용을 줄이지만 코드 복잡도와 학습 난도를 크게 올린다.
그래서 이 글의 실용적 takeaway는 “새 attention 이름을 외우자”가 아니다.
더 정확히는 다음과 같다.
앞으로 모델을 고를 때는 benchmark score 옆에 KV cache strategy, attention compression axis, layer-wise budget, residual-path stability, serving implementation maturity를 함께 봐야 한다.
긴 문맥과 agent workflow가 기본값이 될수록, 좋은 LLM은 더 이상 checkpoint 하나가 아니라 model architecture와 runtime economics가 결합된 시스템으로 평가될 것이다.