AI가 보안 취약점을 찾는다는 이야기는 오래전부터 있었다. 하지만 실제 제품 코드베이스에서 중요한 것은 “의심스러운 줄을 찾았다”가 아니라, 그 finding이 실제로 reachable한지, exploitability가 있는지, 중복은 아닌지, 담당 팀이 Patch Tuesday 일정 안에서 처리할 수 있을 만큼 검증되었는지다. 이 간극 때문에 AI 보안 스캐너는 연구 데모에서 운영 파이프라인으로 넘어가기가 쉽지 않았다.
Microsoft Security가 공개한 MDASH, 즉 Microsoft Security multi-model agentic scanning harness는 이 간극을 정면으로 겨냥한다. Microsoft의 설명에 따르면 MDASH는 단일 LLM 스캐너가 아니라, frontier model과 distilled model을 섞은 다중 모델 패널, 100개 이상의 전문 에이전트, debate·dedup·prove 단계를 갖춘 취약점 탐지·검증 하네스다. 공개 글의 가장 중요한 문장은 사실 벤치마크 숫자보다 이것에 가깝다. 모델은 입력 중 하나이고, 제품은 하네스다.
이번 발표가 눈에 띄는 이유는 숫자도 강하기 때문이다. Microsoft는 MDASH가 Windows networking/authentication stack에서 16개 CVE를 찾는 데 기여했고, private test driver의 planted vulnerability 21개를 false positive 없이 모두 찾았으며, 공개 CyberGym benchmark에서 88.45% 성공률로 leaderboard 1위를 기록했다고 밝혔다. 다만 이 수치는 “보안 연구자가 필요 없어졌다”는 신호가 아니라, 취약점 탐지 자동화에서 후보 생성보다 검증 가능한 end-to-end workflow가 더 중요해졌다는 신호로 읽는 편이 맞다.
무엇을 해결하려는가
대규모 코드베이스의 보안 감사는 일반적인 coding agent task보다 훨씬 까다롭다. Windows, Hyper-V, Azure 같은 사유 코드베이스는 공개 학습 말뭉치에 그대로 들어 있지 않고, kernel calling convention, IRP 규칙, lock invariant, IPC trust boundary처럼 문서화되지 않은 내부 관습도 많다. 모델이 단순히 “본 적 있는 패턴”을 되풀이해서는 충분하지 않다.
또 하나의 병목은 triage 비용이다. 보안 스캐너가 후보를 많이 뱉는 것은 어렵지 않다. 문제는 그 후보가 실제로 exploitable한지, 네트워크에서 reachable한지, 이미 알려진 finding과 같은 것인지, 담당 팀에 넘겨도 되는지다. false positive가 많으면 보안팀의 시간이 아니라 제품팀 전체의 시간을 태운다. Microsoft가 MDASH에서 debate, dedup, prove 단계를 강조하는 이유가 여기에 있다.
마지막으로, 취약점은 로컬 함수 하나에서 보이지 않는 경우가 많다. 이번 글에서 Microsoft가 깊게 다룬 tcpip.sys의 use-after-free와 ikeext.dll의 double-free는 모두 단일 파일·단일 함수 분석으로는 놓치기 쉬운 유형이다. 객체 lifetime, aliasing, shallow copy, concurrency, input reachability가 여러 파일과 실행 단계에 걸쳐 이어진다. 이런 문제는 “모델에게 코드를 많이 넣어 주면 된다”보다, 증거를 찾고 반박하고 실행으로 증명하는 시스템이 필요하다.
핵심 아이디어: 모델이 아니라 하네스가 보안 연구를 조직한다
MDASH의 구조는 prepare, scan, validate/dedup, prove라는 단계로 설명된다. Prepare 단계는 대상 repository를 ingest하고 language-aware index를 만들며, 과거 commit과 code context를 바탕으로 attack surface와 threat model을 잡는다. Scan 단계에서는 전문 auditor agent들이 candidate finding을 낸다. Validate 단계에서는 debater agent들이 finding의 reachability와 exploitability를 찬반으로 검토한다. Dedup은 의미적으로 같은 finding을 묶고, Prove는 가능한 경우 triggering input이나 PoC를 만들어 실제 취약점 존재를 검증한다.
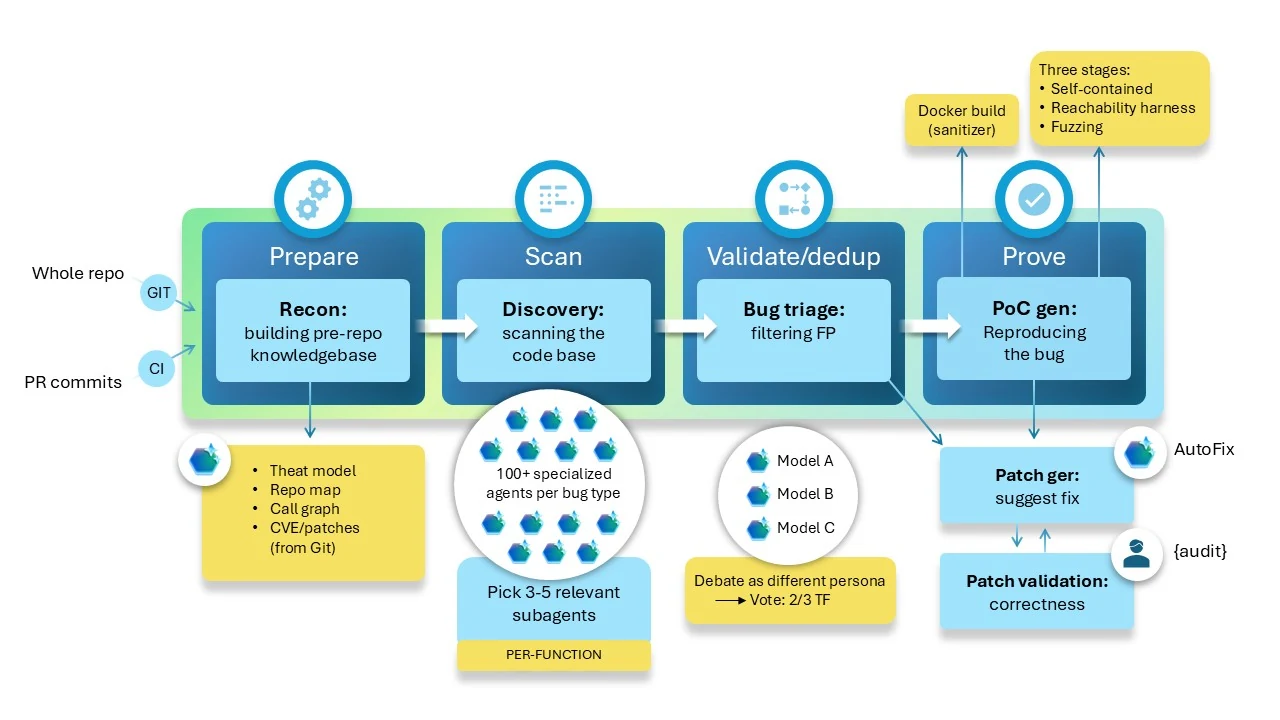
이 구조에서 모델 앙상블은 목적이 아니라 수단이다. Microsoft는 SOTA model을 heavy reasoner로, distilled model을 cost-effective debater로, 별도의 SOTA model을 독립 counterpoint로 쓴다고 설명한다. 한 모델이 모든 stage에서 최고일 것이라는 가정 대신, agent role과 model role을 분리한다. auditor, debater, prover는 서로 다른 prompt regime, tool, stop criterion을 가진다.
이 설계의 실무적 장점은 portability다. 특정 모델이 좋아져도 prepare, scope, plugin, validation, proof generation이라는 주변 투자는 그대로 남는다. 새 모델이 나오면 전체 제품을 갈아엎는 것이 아니라 panel configuration을 바꾸고 A/B test를 돌릴 수 있다. 최근 coding agent나 research agent에서 반복해서 보이는 패턴과 같다. 오래 가는 차별점은 “어떤 모델을 썼는가”보다 모델 주변의 실행 하네스가 무엇을 검증하고 강제하는가다.
공개된 근거에서 확인되는 점
Microsoft가 공개한 근거는 크게 네 묶음이다. 하나는 실제 Patch Tuesday cohort, 하나는 private planted-vulnerability test, 하나는 내부 MSRC historical recall, 마지막은 공개 CyberGym benchmark다.
| 근거 | 공개된 수치 | 해석할 때 중요한 점 |
|---|---|---|
| Patch Tuesday cohort | Windows networking/authentication stack의 16개 CVE | 실제 제품 보안 프로세스에 연결된 forward-looking signal |
| Critical RCE | 4건 | tcpip.sys, ikeext.dll, netlogon.dll, dnsapi.dll 등 고가치 component 포함 |
| Private StorageDrive test | 21/21 planted vulnerabilities, zero false positives | 학습 데이터 오염 가능성을 줄이기 위해 공개되지 않은 interview용 driver 사용 |
| Historical MSRC recall | clfs.sys 28건 중 96%, tcpip.sys 7건 중 100% |
“과거에 이미 중요한 것으로 판정된 bug”를 pre-patch snapshot에서 재발견하는 retrospective test |
| CyberGym | 1,507개 real-world vulnerability task, 188 OSS-Fuzz project, 88.45% | Level 1 setting에서 vulnerable source와 high-level vulnerability description을 제공받는 public benchmark |
16개 CVE 목록도 흥미롭다. tcpip.sys가 다수이고, ikeext.dll, http.sys, netlogon.dll, dnsapi.dll, telnet.exe 같은 usermode/service component가 섞여 있다. 유형은 remote code execution, denial of service, information disclosure, security feature bypass, elevation of privilege로 분산되어 있다. 즉 한 bug class를 잘 찾은 데모라기보다, Windows network/authentication surface의 여러 subsystem을 훑은 결과에 가깝다.
다만 숫자를 읽을 때는 evaluation setting을 분리해야 한다. StorageDrive의 21/21은 private planted-vulnerability test라서 contamination 가능성을 줄인 대신 외부 재현은 어렵다. MSRC historical recall은 ground truth가 명확하지만 retrospective benchmark다. CyberGym은 공개 benchmark라는 장점이 있지만 Level 1은 취약한 source code와 high-level vulnerability description을 제공하는 setting이다. 그러므로 이 결과는 “무작위 production repository에서 blind로 88% 취약점을 찾는다”는 뜻이 아니라, 주어진 vulnerability reproduction task를 end-to-end PoC 생성까지 밀어붙이는 agentic harness 성능으로 해석해야 한다.
CyberGym은 왜 중요한 비교 기준인가
CyberGym은 UC Berkeley 연구진이 공개한 대규모 cybersecurity agent evaluation framework다. benchmark는 OSS-Fuzz에서 발견·패치된 실제 취약점에서 파생된 1,507개 task와 188개 대형 software project를 포함한다. 기본 과제는 agent가 vulnerability description과 pre-patch codebase를 받고, 해당 취약점을 재현하는 proof-of-concept input을 만들어내는 것이다.

이 benchmark가 MDASH 발표와 잘 맞는 이유는 “취약점 후보를 맞혔는가”보다 “실제로 trigger되는가”를 보기 때문이다. Microsoft도 CyberGym 평가를 위해 MDASH의 prove stage를 확장해 PoC input을 자동 제출하고 flag를 회수했다고 설명한다. 이는 MDASH의 설계 철학과 맞다. scan은 시작일 뿐이고, proof가 triage 가능한 finding을 만든다.
CyberGym의 공개 repo도 release signal을 제공한다. sunblaze-ucb/cybergym은 Apache-2.0으로 공개되어 있고, README는 benchmark data가 약 240GB, full server data가 약 10TB에 이르는 무거운 평가 환경임을 밝힌다. 즉 이 벤치마크는 간단한 JSON QA set이 아니라, source checkout, Docker/server data, PoC submission protocol을 포함한 실행형 evaluation harness다. MDASH가 여기서 높은 점수를 냈다는 것은 agent가 codebase reasoning과 runtime proof loop를 함께 다룰 수 있다는 신호다.
Microsoft의 실패 분석도 실무적으로 유용하다. 남은 약 12%의 실패 중 wrong code area를 타깃한 case에서는 82%가 vague description을 가졌고 function/file identifier가 없었다고 한다. 또 어떤 경우에는 agent가 libFuzzer-style input을 만들었지만 task는 honggfuzz-format input을 요구해 실패했다. 이 대목은 agentic security 평가에서 문제 설명 품질과 harness format alignment가 성능의 일부라는 점을 보여 준다. 모델만 강해져도, benchmark adapter와 tool protocol이 어긋나면 성공하지 못한다.
왜 단일 모델 스캐너와 다른가
Microsoft가 공개한 두 deep dive는 MDASH를 단순 LLM scanner와 구분하는 데 도움이 된다. 첫 번째는 tcpip.sys의 CVE-2026-33827이다. Windows IPv4 receive path에서 reference-counted Path object의 lifetime을 잘못 관리해, reference를 drop한 뒤 SSRR 처리 중 같은 pointer를 다시 사용하는 use-after-free다. 이 문제는 remote unauthenticated IPv4 packet path에서 reachable하고, path cache cleanup이나 interface state-driven garbage collection 같은 concurrent free path가 엮인다.
단일 모델이 이 문제를 놓치기 쉬운 이유는 bug가 지역적으로 보이지 않기 때문이다. release와 reuse 사이에 여러 validation과 branch가 있고, 같은 코드베이스 안의 “올바른 순서”와 비교해야 inconsistency가 드러난다. 즉 모델이 한 함수만 보고 “release-then-use” 패턴을 잡는 문제가 아니라, object ownership, cross-file analog, network reachability, concurrency window를 한 chain으로 묶어야 한다.
두 번째는 ikeext.dll의 CVE-2026-33824다. IKEv2 SA_INIT와 fragmentation 처리에서 shallow memcpy가 receive context의 heap pointer ownership을 복제하고, 두 owner가 같은 pointer를 free하면서 double-free가 난다. Microsoft는 이 bug가 여섯 개 파일에 걸친 aliasing lifecycle bug라고 설명한다. ike_A.c의 bad memcpy, ike_B.c의 alias origin, ike_C.c의 잘못된 free, ike_D.c의 correct pattern과 second free, ike_E.c의 remote population, ike_F.c의 dispatcher/UAF read site가 함께 봐야 한다.
이런 사례에서는 debate stage가 단순한 “critic prompt” 이상이 된다. auditor가 candidate finding을 냈을 때, debater는 reachability와 exploitability를 반박하거나 강화한다. prover는 domain knowledge를 가진 plugin과 함께 triggering input을 만든다. CLFS recall에서 Microsoft가 강조한 것도 이 부분이다. CLFS-specific proving plugin은 on-disk container layout, block validation sequence, in-memory state machine을 알고 triggering log file을 구성한다. foundation model이 모든 내부 파일시스템 invariant를 외우는 것이 아니라, domain plugin이 그 지식을 하네스에 넣고 모델이 활용한다.
실무 관점에서의 해석
MDASH 발표의 가장 큰 시사점은 보안 자동화의 경쟁 축이 바뀌고 있다는 것이다. “어떤 모델이 더 취약점을 잘 찾는가”는 여전히 중요하지만, 운영 환경에서는 그 질문만으로 부족하다. 더 중요한 질문은 “찾은 것을 어떻게 반박하고, 중복 제거하고, 증명하고, owner에게 넘길 수 있는가”다. 보안팀 입장에서는 candidate volume보다 validated finding throughput이 중요하다.
두 번째 시사점은 agentic system의 durable asset이 모델이 아니라 주변 자산이라는 점이다. Scope file, domain plugin, code index, proof generator, benchmark adapter, triage workflow, historical CVE corpus는 모델 세대가 바뀌어도 남는다. MDASH가 새 모델을 configuration flip과 A/B test로 받아들일 수 있다고 말하는 이유도 여기에 있다. 이는 최근 coding agent, research agent, data agent에서 반복되는 하네스 중심 설계와 같은 방향이다.
세 번째는 한계다. MDASH 자체는 공개 오픈소스 도구가 아니라 Microsoft 내부 팀이 사용하고 일부 고객에게 limited private preview로 제공하는 시스템이다. 정확한 prompt, agent 구성, 모델 panel, plugin interface, cost profile, false positive 운영 지표는 공개되어 있지 않다. 따라서 외부 팀이 당장 같은 성능을 재현할 수 있다고 보기는 어렵다. 공개적으로 재현 가능한 쪽은 CyberGym benchmark와 그 evaluation harness이고, Microsoft의 MDASH 구현은 제품/연구 발표의 범위 안에서 읽어야 한다.
그래도 방향성은 분명하다. 취약점 탐지에서 AI를 제대로 쓰려면 “모델에게 코드를 읽히기”에서 멈추면 안 된다. 코드베이스를 prepare하고, 공격 표면을 좁히고, 전문 agent가 hypothesis를 만들고, 독립 agent가 반박하고, domain plugin이 proof를 구성하고, 결과가 triage workflow로 들어가는 시스템이 필요하다. 그 시스템이 잘 만들어지면 모델 발전은 곱셈 효과를 낸다. 반대로 그 시스템이 없으면 더 강한 모델도 더 많은 noise를 만들 수 있다.
MDASH는 그래서 보안 제품 하나 이상의 의미가 있다. AI agent를 운영 가능한 engineering system으로 만들 때 반복해서 등장하는 교훈을 보안이라는 고압 환경에서 다시 보여 준다. 신뢰성은 모델의 말에서 나오지 않는다. 실행 환경, 검증 루프, domain-specific plugin, 그리고 실패를 받아낼 수 있는 하네스에서 나온다.