멀티 에이전트 시스템은 보통 “역할을 잘 나누면 더 잘 풀 수 있다”는 직관에서 출발한다.
Planner, Solver, Critic, Tester, Judge 같은 역할을 붙이고, 문제마다 적당한 workflow를 고르면 단일 응답보다 좋은 결과가 나올 수 있다.
그런데 최근 automatic MAS 연구의 병목은 조금 더 미묘하다.
시스템 구조를 자동으로 찾거나 meta-agent가 workflow를 만들더라도, 실제로 문제를 푸는 downstream executor가 고정되어 있으면 성능 상한이 생긴다.
MetaAgent-X : Breaking the Ceiling of Automatic Multi-Agent Systems via End-to-End Reinforcement Learning는 이 상한을 논문의 핵심 문제로 잡는다.
기존 방식은 test-time search로 agent graph를 찾거나, meta-level designer만 학습하고 executor는 freeze하는 경우가 많았다.
MetaAgent-X는 반대로 자동 MAS의 설계자와 실행자를 하나의 end-to-end RL 루프 안에서 함께 학습하려 한다.
Designer는 태스크별 멀티 에이전트 스크립트를 만들고, Executor는 그 스크립트가 만든 workflow 안에서 실제 답을 낸다.
이후 환경 reward를 Designer와 Executor trajectory로 나눠 credit assignment하고, GRPO로 업데이트한다.
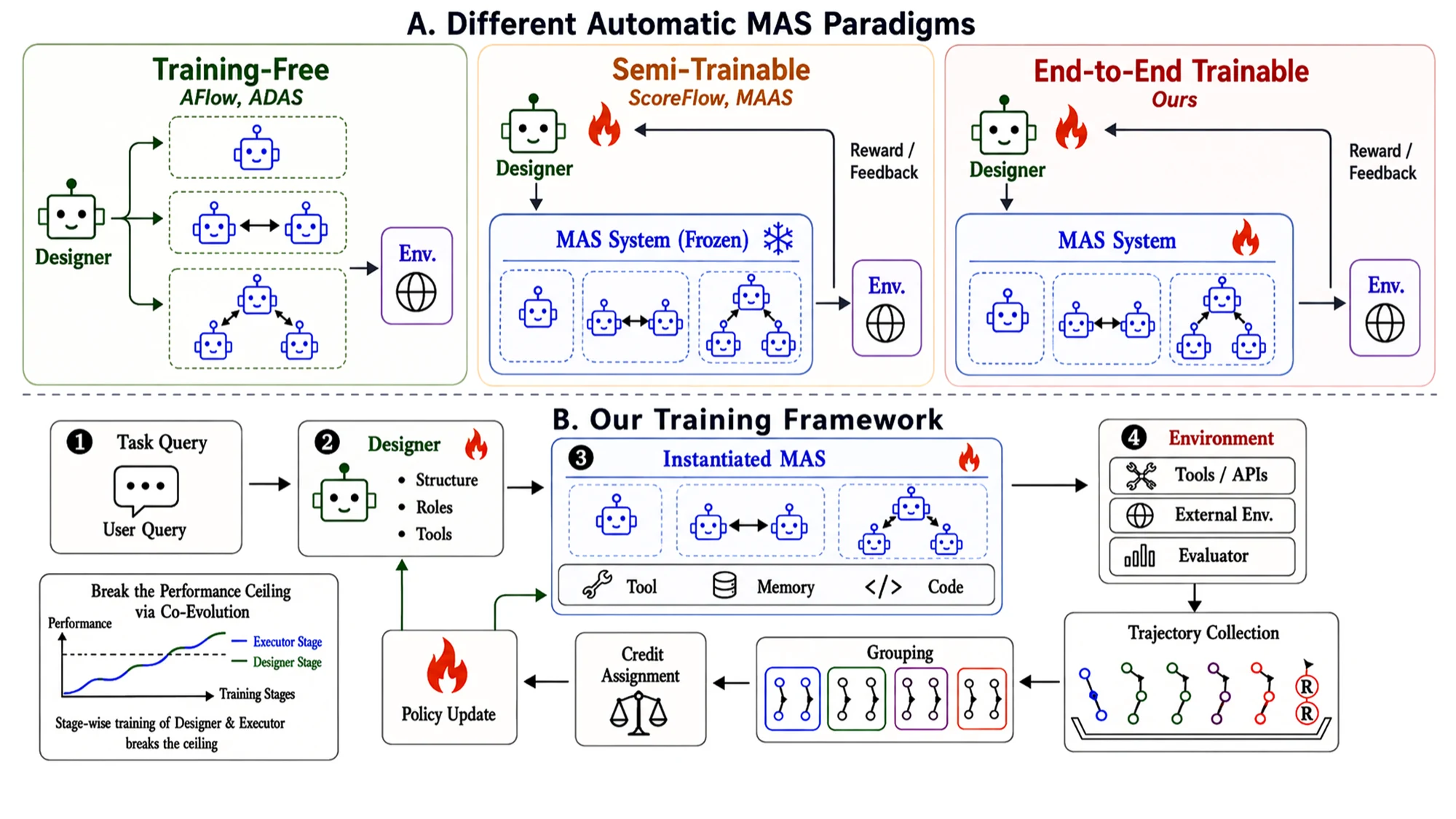
이 논문이 흥미로운 이유는 “멀티 에이전트가 좋다”는 일반론보다 더 구체적인 질문을 던지기 때문이다. workflow를 자동 생성하는 능력과 그 workflow 안에서 실제로 문제를 해결하는 실행 능력이 서로의 환경이 될 때, 둘을 어떻게 안정적으로 같이 학습할 것인가.
MetaAgent-X의 답은 크게 세 가지다.
첫째, Designer가 자연어 설명만 내는 것이 아니라 실행 가능한 lightweight Python script 형태의 MAS를 생성한다.
이 스크립트는 역할, 프롬프트, 통신 방식, 도구 사용 패턴, 제어 흐름을 지정한다.
둘째, 한 문제에 대해 여러 design을 뽑고, 각 design을 여러 번 실행하는 Executor-Designer Hierarchical Rollout으로 design 품질과 execution stochasticity를 분리한다.
셋째, Designer와 Executor를 동시에 항상 업데이트하지 않고, 일정 stage마다 active role을 바꾸는 Stagewise Co-evolution으로 non-stationary training을 완화한다.
무엇을 해결하려는가
자동 MAS 연구에는 이미 여러 흐름이 있다.
AFlow나 ADAS처럼 workflow/search space를 탐색하는 방식이 있고, ScoreFlow나 MaAS처럼 meta-controller 또는 workflow generator를 학습하는 방식도 있다.
하지만 논문이 보는 한계는 두 가지다.
첫 번째는 parameter-level disjunction이다.
Designer가 더 나은 workflow를 만들도록 학습되더라도, 그 workflow를 실행하는 모델이 고정되어 있으면 Designer가 유도할 수 있는 행동의 범위가 제한된다.
반대로 Executor가 더 잘 풀 수 있는 방향으로 workflow distribution이 변하지 않으면, Executor는 현재 design 분포의 상한 안에서만 좋아진다.
두 번째는 co-evolution dynamics의 불투명성이다.
Designer와 Executor는 서로 독립된 모듈이 아니라, 한쪽의 변화가 다른 쪽의 reward landscape를 바꾸는 결합 시스템이다.
이를 단순히 “같이 학습한다”로 밀어붙이면 gradient signal이 섞이고, 어느 역할이 실제 개선을 만들었는지 알기 어렵다.
MetaAgent-X는 이 문제를 자동 MAS를 위한 RL training system으로 재구성한다.
논문 표현으로는 self-designing and self-executing agentic model을 만드는 시도다.
즉 사람이 미리 설계한 고정 협업 패턴을 잘 실행하는 모델이 아니라, 문제마다 적절한 멀티 에이전트 프로그램을 만들고 그 프로그램 내부 역할까지 수행하는 모델을 학습한다.
핵심 아이디어 / 구조 / 동작 방식
MetaAgent-X의 한 rollout은 다음처럼 읽을 수 있다.
- 태스크 query
q가 들어온다. - Designer policy가
q에 맞는 MAS designd를 생성한다. - design은 Python script/workflow로 instantiate된다.
- Executor policy가 그 workflow 안에서 agent role들을 수행하며 trajectory
e를 만든다. - 환경은 math verifier 또는 code unit test 같은 outcome reward를 반환한다.
- 이 reward를 Designer와 Executor trajectory에 맞게 나눠 GRPO update에 사용한다.
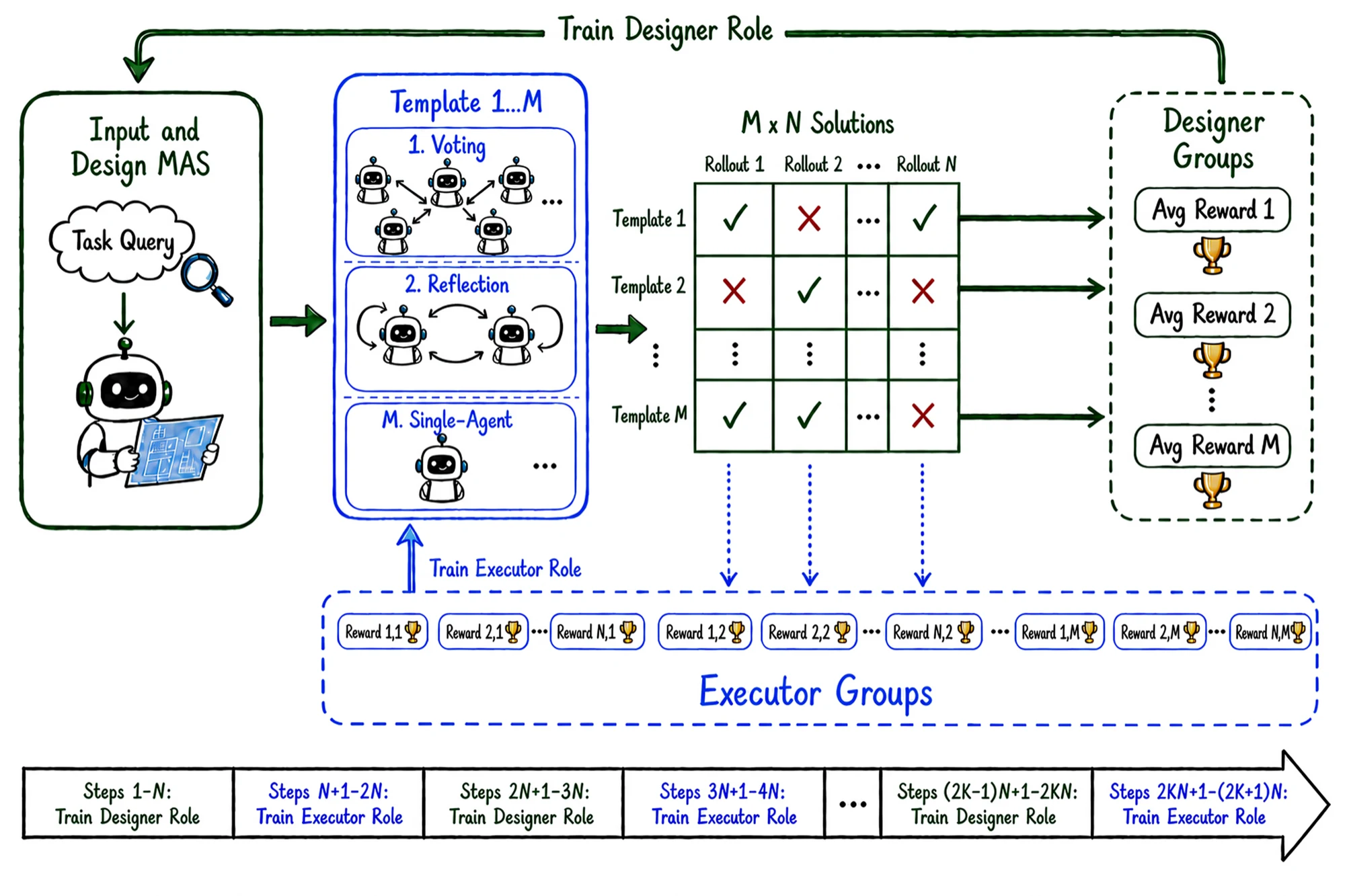
핵심은 credit assignment다.
논문은 한 문제에 대해 Designer가 M=4개의 design을 만들고, 각 design을 Executor가 N=4번 실행하는 M × N 평가 행렬을 구성한다.
Designer advantage는 같은 문제 안에서 design별 평균 reward를 비교해 계산한다.
이렇게 하면 특정 design이 운 좋게 한 번 성공했는지, 여러 실행에서 꾸준히 좋은지 구분할 수 있다.
Executor advantage는 같은 문제의 모든 executor trajectory를 모아 정규화한다.
이쪽은 design이 달라도 “이 문제를 푸는 실행 행동”을 비교하는 신호가 된다.
학습 안정화는 stagewise schedule이 담당한다.
논문은 stage length K=30을 기본으로 두고, 일정 구간에서는 Executor trajectory만 gradient에 반영하고 다음 구간에서는 Designer trajectory만 반영한다.
공유 policy setting에서는 Designer와 Executor가 같은 Qwen3 backbone을 쓰되 role prompt로 역할을 나누며, inactive role의 trajectory는 gradient에서 mask된다.
정리하면 구조는 다음과 같다.
| 구성 | 논문에서의 역할 | 실무적으로 읽히는 의미 |
|---|---|---|
| Script-based MAS generation | Designer가 역할·토폴로지·프롬프트·제어 흐름을 생성 | prompt만이 아니라 실행 가능한 workflow artifact를 만든다 |
| Hierarchical rollout | M개 design × N회 execution |
design 품질과 execution noise를 분리한다 |
| Role-aware GRPO | Designer/Executor advantage를 따로 계산 | “누가 잘했는가”를 하나의 outcome reward에서 분해한다 |
| Stagewise co-evolution | active role을 stage마다 교대 | 동시에 흔들리는 두 objective의 간섭을 줄인다 |
| Shared policy main setting | Qwen3 4B/8B가 Designer와 Executor 역할을 모두 수행 | 한 모델이 설계와 실행을 모두 internalize하도록 유도한다 |
공개된 근거에서 확인되는 점
실험 설정은 비교적 명확하다.
논문은 Qwen3 4B와 8B를 no-thinking mode로 학습·평가하고, 모든 실험을 8×H200 단일 노드에서 수행했다고 밝힌다. prompt length와 response length는 기본 8192 token이다.
학습은 두 단계다.
먼저 DeepSeek-V3.2 trajectory에서 정답으로 필터링한 3K Designer 예시와 8K Executor 예시로 SFT cold start를 만든다.
그 다음 Polaris-Dataset-53K, APPS introductory subset, CodeContests를 섞어 RL co-evolution을 수행한다.
평가는 math와 code를 함께 본다.
Math는 AIME24, AIME25, OlympiadBench이고, code는 LiveCodeBench-v6, APPS, CodeContests다.
수학은 verifier-checked numeric scoring, 코드는 공식 또는 benchmark-provided test case 실행으로 채점한다.
가장 압축적인 결과는 평균 성능이다.
| 모델 스케일 | Single Agent 평균 | SA + GRPO 평균 | 가장 강한 기존 Auto MAS 평균 | MetaAgent-X RL 평균 |
|---|---|---|---|---|
| Qwen3 8B | 27.16 | 29.10 | 32.22 (MaAS) | 38.33 |
| Qwen3 4B | 21.38 | 28.96 | 26.65 (ScoreFlow) | 34.18 |
Qwen3 8B 기준으로 MetaAgent-X RL은 Single Agent 대비 평균 +11.17, 가장 강한 Auto MAS baseline인 MaAS 대비 +6.11을 보인다.
개별 benchmark로 보면 LiveCodeBench 41.00, APPS 38.00, AIME24 40.00, AIME25 33.33, OlympiadBench 61.00이다.
논문 초록의 “up to 21.7% gains”는 Qwen3 8B의 AIME24에서 Single Agent 18.30 대비 MetaAgent-X RL 40.00으로 올라가는 절대 개선을 가리킨다.
Qwen3 4B에서도 비슷한 흐름이 나온다.
Single Agent 평균 21.38에서 MetaAgent-X RL 34.18로 올라가며, SA + GRPO 28.96보다도 높다.
4B에서는 AIME24 33.33, AIME25 26.67, OlympiadBench 58.20, LiveCodeBench 36.00이 보고된다.
즉 효과가 8B에만 국한된 것은 아니지만, 논문 스스로도 더 큰 backbone과 긴 training budget에 대한 exhaustive scaling study는 아직 하지 못했다고 밝힌다.
Ablation은 MetaAgent-X의 메시지를 더 잘 보여 준다. hierarchical rollout에서 M=4, N=4는 M=8, N=1보다 AIME24/AIME25 모두 낫다.
같은 총 sample budget 근처라면 design을 더 많이 한 번씩 실행하는 것보다, design별 repeated execution으로 평균 utility를 잡는 쪽이 안정적이었다는 해석이다.
Stagewise ablation도 중요하다.
| Variant | Math | Code |
|---|---|---|
| Coupled | 36.7% | 25.2% |
| Designer-only | 38.6% | 27.5% |
| Executor-only | 39.6% | 30.7% |
| Stagewise | 44.8% | 32.0% |
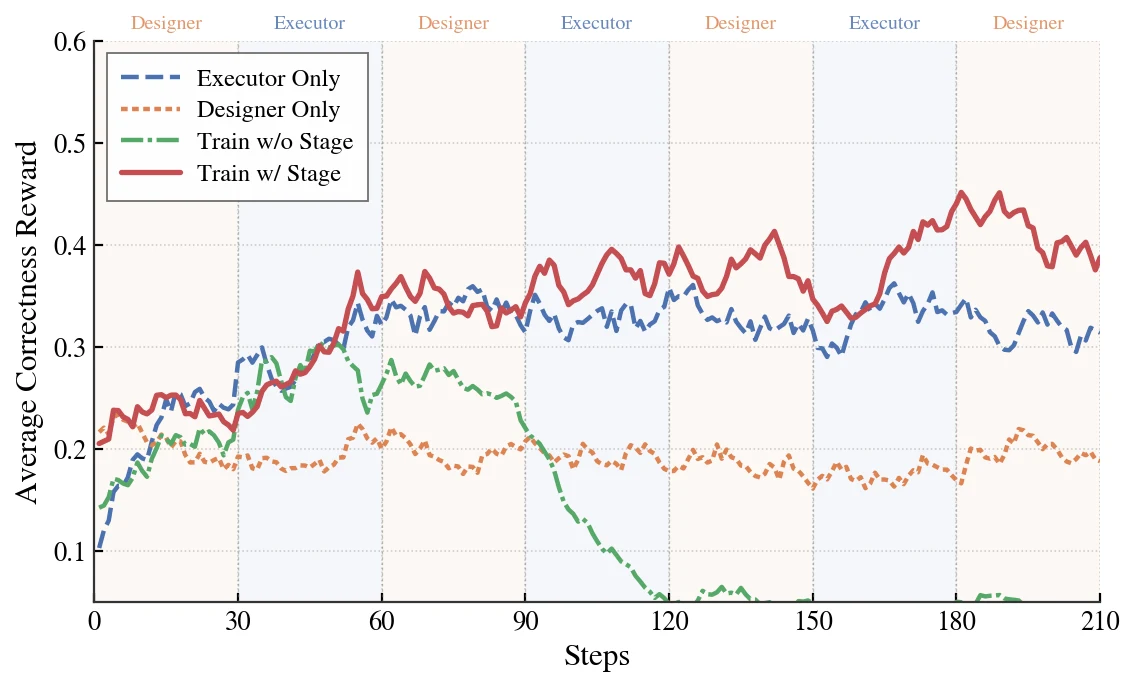
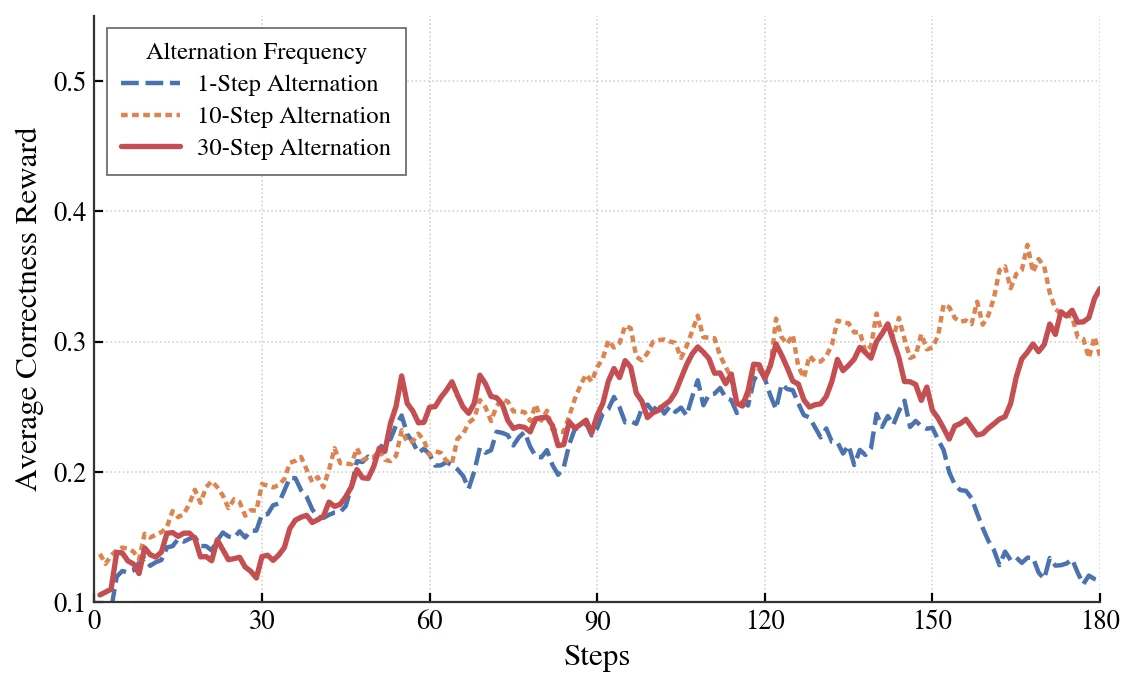
stage length 자체도 민감하다.
1-step alternation은 약 150 step 이후 collapse하고, 10-step과 30-step은 훨씬 안정적이다.
논문은 30-step schedule이 가장 높은 final reward를 보여 기본값으로 썼다고 설명한다.
또 하나 눈에 띄는 분석은 RL 이후 Designer가 고르는 구조가 바뀐다는 점이다.
AIME24와 AIME25에서는 reflection 구조가 각각 70.0%, 73.3%까지 올라간다.
반면 OlympiadBench와 APPS처럼 상대적으로 직접 풀이가 가능한 태스크에서는 single 구조 비율이 더 높다.
Ensemble은 AIME와 CodeContests에서는 약 11% 정도 남지만, LiveCodeBench와 APPS에서는 낮다.
| Benchmark | Single | Reflection | Ensemble |
|---|---|---|---|
| AIME 2024 | 18.9% | 70.0% | 11.1% |
| AIME 2025 | 15.6% | 73.3% | 11.1% |
| OlympiadBench | 46.4% | 44.8% | 8.8% |
| CodeContests | 26.7% | 62.4% | 10.9% |
| LiveCodeBench | 43.5% | 52.6% | 3.8% |
| APPS | 55.2% | 43.8% | 1.0% |
이 결과는 “멀티 에이전트라서 무조건 ensemble을 많이 쓴다”와 반대다.
RL 이후의 Designer는 어려운 reasoning/code 과제에서는 critic/reflection loop를 더 자주 쓰고, 더 직접적인 과제에서는 single solver를 택한다.
논문은 AIME25 개선 사례를 분석해, RL이 푸는 추가 문제의 절반은 같은 구조 안에서 Executor가 더 잘 실행한 것이고, 나머지 절반은 Designer가 더 나은 구조로 바꾼 덕분이라고 해석한다.
공개 구현과 모델 상태
공식 공개 surface도 꽤 많다.
GitHub 저장소는 pettingllms-ai/PettingLLMs이고, README는 PettingLLMs를 on-policy RL framework for multi-agent LLMs로 소개한다.
이 저장소는 MetaAgent-X뿐 아니라 Stronger-MAS/AT-GRPO도 함께 다루는 통합 프레임워크에 가깝다.
2026-05-19 기준 GitHub API에서 확인한 상태는 stars 170, forks 27, open issues 12, default branch main, MIT license다.
루트에는 README.md, LICENSE, docs, pettingllms, scripts, setup.py, requirements_venv.txt, requirements_venv_cu128.txt, verl 등이 있고, formal release나 tag는 아직 없다.
README의 MetaAgent-X 섹션은 단순 placeholder가 아니라 어느 정도 실행 surface를 제공한다. scripts/evaluate/autoevol/serve_ui.sh로 interactive browser demo를 띄우고, serve_demo.sh로 one-shot CLI demo를 돌리며, eval_first_open_model.sh와 example_cotrain_autoeval.sh로 평가와 학습 예시를 제공한다고 설명한다.
다만 릴리스 태그가 없고, setup.py도 version 0.1의 연구 프레임워크 형태라서 “안정 패키지”라기보다는 논문 공개와 함께 빠르게 정리 중인 연구 코드/데모 묶음으로 보는 편이 맞다.
Hugging Face 모델은 Mercury7353/MetaAgent-X로 공개되어 있다.
API 기준 private/gated/disabled가 모두 false이며, card license는 Apache-2.0, tags에는 qwen3, multi-agent-systems, reinforcement-learning, agentic-ai, code, math, arxiv:2605.14212가 들어 있다.
파일 구성은 Qwen3 checkpoint 형태의 4개 safetensors shard, tokenizer/config 파일, README 등이다.
같은 시점 API 기준 downloads 78, likes 2라서, 공개 직후 연구 artifact에 가까운 초기 상태로 읽힌다.
흥미롭게도 GitHub repo는 MIT이고 HF model card는 Apache-2.0이라, 코드와 모델 artifact의 라이선스 표기는 분리해서 봐야 한다.
실무 관점에서의 해석
내가 보기엔 MetaAgent-X의 핵심 메시지는 “에이전트 workflow를 자동 생성하자”보다 더 강하다.
이 논문은 자동 workflow 생성만으로는 부족하고, workflow를 만드는 모델과 workflow 안에서 일하는 모델이 같이 변해야 한다고 말한다.
그동안 많은 MAS 연구는 orchestration을 외부 harness 문제로 봤다.
어떤 역할을 만들지, 어떤 순서로 대화시킬지, 어느 agent가 judge할지 같은 문제다.
MetaAgent-X는 이 orchestration 자체를 모델의 학습 가능한 행동으로 끌어들인다.
실무적으로는 두 가지 시사점이 있다.
첫째, agent system optimization에서 “좋은 graph를 찾는 것”과 “그 graph 안에서 좋은 행동을 하는 것”을 분리해서 평가해야 한다.
좋은 Designer가 나쁜 Executor를 구할 수 없고, 좋은 Executor도 계속 나쁜 workflow만 받으면 제한된다.
MetaAgent-X의 hierarchical rollout은 이 둘을 outcome reward 하나에서 분리해 보려는 꽤 실용적인 장치다.
둘째, multi-agent RL은 단순히 sample을 더 많이 뽑는 문제가 아니라 training schedule의 문제다.
논문 결과만 놓고 보면 coupled update는 오히려 불안정하다.
Designer와 Executor가 서로의 환경이 되는 구조에서는, 한쪽을 일정 기간 고정된 reward distribution처럼 두고 다른 쪽을 개선하는 stagewise 방식이 더 낫다.
이는 실제 agent platform에서도 “planner policy와 worker policy를 동시에 계속 바꾸는 것”보다, 역할별 안정 구간을 둔 평가·학습 루프가 필요할 수 있음을 시사한다.
물론 한계도 분명하다.
벤치마크는 math/code 중심이고, production agent에서 흔한 장기 메모리, 외부 API 실패, 브라우저 조작, 사용자 승인, 보안 정책 같은 운영 변수는 아직 별도 검증이 필요하다.
또한 8×H200 환경의 on-policy RL pipeline은 개인 개발자가 바로 재현하기에는 무겁다.
공개 repo와 HF 모델이 있다는 점은 중요하지만, release/tag 없는 초기 연구 artifact라는 점도 함께 봐야 한다.
그래도 방향성은 강하다.
MetaAgent-X는 멀티 에이전트를 “외부에서 설계한 대화 프로토콜”이 아니라, 모델이 스스로 만들고 스스로 수행하며 outcome으로 같이 바뀌는 trainable computation pattern으로 본다.
만약 앞으로 agent foundation model이라는 범주가 실제로 생긴다면, 단일 모델의 reasoning 능력뿐 아니라 “어떤 상황에서 어떤 agent structure를 만들어야 하는가”와 “그 구조 안에서 어떻게 자기 역할을 수행해야 하는가”가 함께 학습된 형태일 가능성이 높다.
MetaAgent-X는 그 방향의 초기, 하지만 꽤 구체적인 실험으로 읽힌다.