오픈 모델을 “다운로드할 수 있는 모델”로만 이해하면 실제 사용 단계에서 금방 막힌다.
어떤 포맷을 받아야 하는지, 내 노트북 메모리에 맞는 quant는 무엇인지, 로컬 서버를 어떻게 띄울지, 코딩 에이전트가 그 서버를 어떻게 쓰게 할지까지 이어져야 비로소 작업 도구가 된다.
Hugging Face의 라이브스트림 Welcome to Open Source AI: Run Your Own Models Locally는 이 전체 흐름을 한 번에 훑는 입문 세션이다.
핵심은 “오픈 모델이 충분히 좋아졌는가”보다 한 단계 실무적이다.
이제는 모델 하나를 고르는 문제가 아니라, Hub → quant → local runtime → agent harness → 실제 업무로 이어지는 스택을 고르는 문제라는 점이다.
영상은 2026년 6월 25일 Hugging Face 채널에서 진행된 약 70분짜리 라이브스트림이고, 공식 챕터는 없었다.
이 글은 YouTube 메타데이터, 영어 자동 생성 transcript, 영상 프레임, 그리고 관련 공식 문서/블로그를 함께 확인해 정리했다.
무엇을 다루는 영상인가
영상 설명은 이 세션을 “open models를 처음 시작하는 사람을 위한 livestream”으로 소개한다.
발표 흐름은 네 축으로 나뉜다.
- Ben Burtenshaw가 오픈 모델과 로컬 모델의 차이를 설명한다.
- Merve Noyan이
llama.cpp,llama.app, Hugging Face Hub의 GGUF/llama.cpp 흐름을 보여준다. - Daniel Han이 Unsloth의 GGUF quantization, dynamic quantization, KL divergence, MTP 같은 추론 최적화 관점을 설명한다.
- Onur Solmaz가 LM Studio, Qwen/Gemma MoE 모델, OpenClaw/Pi 기반의 로컬 에이전트 활용을 시연한다.
라이브 형식이라 중간중간 Q&A와 데모 지연이 섞인다.
하지만 전체 메시지는 꽤 선명하다.
오픈 모델 사용은 “가장 큰 모델을 고르는 일”이 아니라 내 하드웨어, 메모리, context 길이, quantization, harness 권한 모델에 맞는 실행 경로를 조립하는 일이다.

오픈 모델과 로컬 모델은 같지 않다
초반부에서 좋은 구분이 나온다.
영상은 closed system, open weights, open-source model, local model을 분리해서 설명한다.
닫힌 API 뒤에 있는 모델은 사용자가 weights나 내부 실행 방식을 볼 수 없다.
반대로 Hugging Face Hub 같은 곳에서 모델 weights를 내려받아 사용할 수 있으면 open weights 모델에 가깝다.
하지만 학습 데이터, 학습 코드, 전체 재현 파이프라인까지 모두 열린 “open-source model”은 더 강한 조건이다.
또 하나 중요한 구분은 open model과 local model의 차이다.
어떤 모델은 open weights일 수 있지만, 크기와 실행 비용 때문에 개인 노트북에서 돌리기 어렵다.
영상에서는 GLM 5.2 같은 큰 모델을 예로 들며, 오픈 모델이라고 해서 모두 소비자 하드웨어에서 로컬로 돌릴 수 있는 것은 아니라고 정리한다.
이 구분은 실무적으로 중요하다.
팀이 “오픈 모델로 갈아타자”고 말할 때 실제 선택지는 적어도 세 가지다.
| 선택지 | 의미 | 장점 | 비용/주의점 |
|---|---|---|---|
| Hosted open model | Hugging Face Inference Providers 같은 라우터를 통해 오픈 모델을 원격 호출 | 하드웨어 없이 빠르게 시작 | 토큰, 과금, provider latency, 데이터 경계 확인 필요 |
| Local open model | GGUF/MLX 등으로 변환·quantize된 모델을 직접 실행 | 개인정보, 반복 비용, 실험 자유도 | RAM/VRAM, context, 냉각, 모델 관리 책임 |
| Hybrid | hosted로 시작하고 일부 업무를 local로 이전 | 도입 리스크를 줄임 | 두 경로의 설정과 평가 기준을 모두 관리해야 함 |
따라서 “로컬 AI”의 장점은 단순히 공짜라는 말로 줄일 수 없다.
하드웨어 비용은 선불로 이동하고, 운영 책임은 사용자 쪽으로 온다.
대신 민감한 데이터가 외부 API로 나가지 않고, 반복 작업에 대한 marginal cost를 크게 낮출 수 있다.
llama.cpp는 로컬 실행의 공통 접점이 된다
Merve Noyan의 파트는 llama.cpp 입문에 가깝다.
영상에서 llama.cpp는 로컬 하드웨어에서 LLM을 돌리는 오픈소스 inference engine으로 소개된다.
CUDA, Metal, ROCm, Vulkan, CPU 같은 여러 backend를 지원하고, GGUF 포맷, quantization, embedding model serving, benchmarking까지 포함한다.

공식 Hugging Face 문서도 같은 방향을 확인해준다. llama.cpp는 Hugging Face repo path와 GGUF 파일을 받아 모델을 다운로드하고 cache하며, llama-cli -hf ... 또는 llama-server -hf ... 형태로 실행할 수 있다. llama-server는 OpenAI-compatible endpoint를 제공하므로, 로컬 모델을 기존 OpenAI API 스타일 클라이언트나 에이전트 하네스에 붙이기 쉬워진다.
영상에서 특히 강조된 것은 초보자 경험이다.
예전에는 llama-server, llama-cli, build option, quant 파일 선택을 직접 알아야 했다면, 이제는 Hugging Face Hub와 llama.app이 그 사이를 더 많이 메운다.
Hub에서 llama.cpp compatible model을 필터링하고, 모델 페이지 오른쪽에서 hardware compatibility와 실행 명령을 확인하는 흐름이 소개된다.
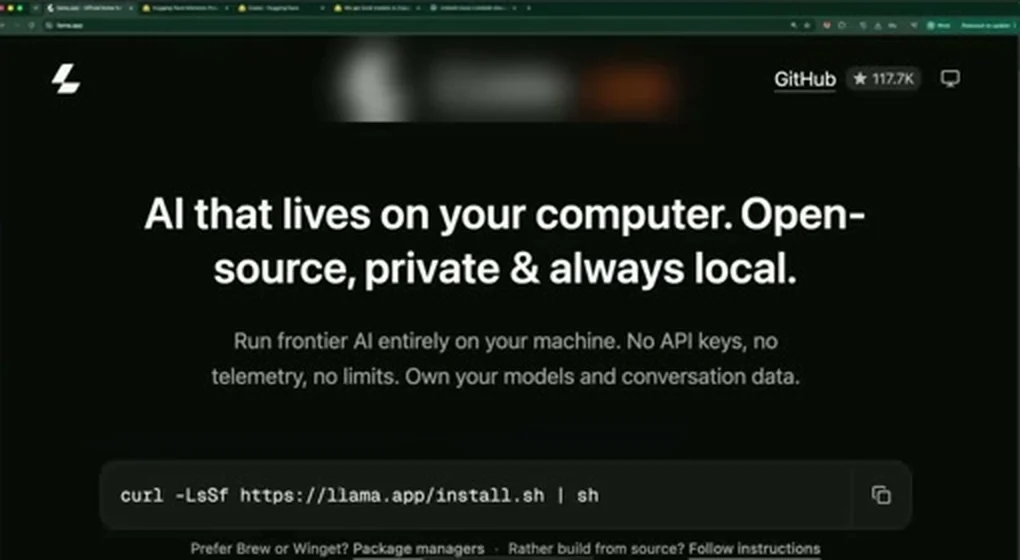
이 지점에서 llama.app은 중요한 product surface다.
공식 페이지는 “AI that lives on your computer.
Open-source, private & always local.”
이라는 메시지와 함께 설치 명령, Hugging Face 모델 탐색, Pi 연결 예시를 제공한다.
영상의 “초보자도 로컬 모델을 시작할 수 있게 하자”는 목표가 문서와 웹 UI로 이어지는 부분이다.
quantization은 ‘작게 만드는 일’이 아니라 fidelity trade-off다
Daniel Han의 Unsloth 파트는 GGUF quantization을 좀 더 깊게 다룬다.
핵심 메시지는 단순하다.
큰 모델을 로컬에서 쓰려면 파일 크기와 메모리 요구량을 줄여야 하지만, 줄이는 과정에서 원본 모델과의 동작 차이를 얼마나 억제할지가 중요하다.
영상에서는 GLM 5.2 같은 대형 모델을 예로 들며, 원본 크기가 매우 커도 quantization을 통해 훨씬 작은 크기로 만들 수 있다고 설명한다.
다만 여기서 중요한 기준은 “몇 GB까지 줄였나”가 아니라 원본 BF16 모델과 quantized 모델 사이의 분포 차이, 즉 KL divergence를 얼마나 낮게 유지하느냐다.
Unsloth의 공식 Dynamic 2.0 GGUF 문서도 같은 프레임을 쓴다.
Dynamic quantization은 모델과 layer별로 다른 quantization scheme을 적용하고, MoE와 non-MoE 모델 모두를 대상으로 accuracy를 최대한 보존하려는 접근이다.
문서는 KL Divergence, MMLU, Aider Polyglot 같은 평가를 함께 제시하며, 단순 benchmark accuracy만으로 quant 품질을 보면 flip이 가려질 수 있다고 설명한다.
실무적으로는 다음 질문을 먼저 던져야 한다.
| 질문 | 왜 중요한가 |
|---|---|
| 내 기기가 어느 정도 RAM/VRAM을 갖고 있는가 | quant level과 context window가 동시에 메모리를 먹는다 |
| 모델이 MoE인가 dense인가 | 활성 parameter 수와 실제 추론 속도가 다르다 |
| GGUF, MLX, QAT, Dynamic quant 중 어떤 표면을 쓸 것인가 | runtime과 하드웨어에 따라 최적 경로가 달라진다 |
| long-horizon agent 작업인가, 짧은 분류/요약인가 | 작은 모델은 빠르지만 긴 tool loop에서 drift가 커질 수 있다 |
| 정확한 수치 재현이 필요한가, 대략적 triage가 필요한가 | fidelity 요구가 다르면 quant 선택도 달라진다 |
영상의 좋은 점은 “작은 모델도 된다”와 “큰 모델이 필요할 때도 있다”를 동시에 말한다는 점이다.
Merve는 Qwen/Gemma MoE quant가 MacBook Pro에서 편하게 동작할 수 있다고 말하면서도, long-running task에는 더 큰 모델이나 hosted provider가 나을 수 있다고 구분한다.
Onur도 20B~40B급 MoE 모델이 32GB/64GB unified memory 환경의 sweet spot이 될 수 있다고 설명한다.
에이전트에서는 모델보다 하네스 차이가 크게 드러난다
후반부에서 Ben Burtenshaw는 같은 오픈 모델을 서로 다른 coding agent harness에 붙여도 결과 경험이 달라진다고 보여준다.
Claude Code 스타일 도구, Pi, OpenCode처럼 각 하네스가 제공하는 tool, loop, UI, customization 방식이 다르기 때문이다.
이 부분은 모델 평가에서 자주 놓치는 지점이다.
같은 GLM 5.2를 쓰더라도, 하네스가 repo file을 읽을 수 있는지, 어떤 command를 허용하는지, sub-agent를 어떻게 다루는지, 결과를 table로 정리하는지에 따라 “같은 모델”의 사용감이 달라진다.
영상에서 Pi는 더 단순하고 sharp한 harness로, OpenCode는 풍부한 UI와 slash command를 가진 harness로 설명된다.
여기서 중요한 것은 특정 도구의 우열이 아니라, 로컬/오픈 모델 도입은 model endpoint 교체가 아니라 harness compatibility 문제라는 점이다.
Hosted 경로에서는 Hugging Face Inference Providers가 중간다리가 된다.
공식 문서에 따르면 Inference Providers는 여러 provider의 모델을 Hugging Face token 하나와 OpenAI-compatible API로 접근하게 해주며, :fastest, :cheapest, :preferred 같은 provider selection policy도 제공한다.
완전 로컬 실행이 아직 부담스럽다면, 이 경로는 오픈 모델을 agent harness에 붙이는 첫 번째 단계가 될 수 있다.
반대로 fully local 경로에서는 llama.cpp나 LM Studio가 OpenAI-compatible local endpoint 역할을 한다.
OpenClaw의 LM Studio 문서는 lms server start --port 1234로 local server를 띄우고, OpenClaw onboarding에서 LM Studio provider를 선택하는 흐름을 안내한다.
LM Studio 공식 integration 문서도 OpenClaw가 LM Studio를 native model provider로 지원한다고 설명한다.
PR triage 데모가 보여주는 실용적 지점
Onur Solmaz의 데모는 “로컬 모델이 어디에 쓸 만한가”를 더 구체적으로 보여준다.
영상에서는 LM Studio로 Qwen/Gemma 계열 MoE 모델을 고르고, 35B급 MoE 모델이 Apple Silicon에서 약 30 tokens/s 수준으로 생성되는 장면을 보여준다.
이 수치는 영상 속 데모 기준이므로 일반화하면 안 되지만, 최소한 “로컬 모델은 느려서 에이전트에 못 쓴다”는 직관은 더 이상 항상 맞지 않다.
더 흥미로운 부분은 PR triage 사례다.
Hugging Face 블로그 We got local models to triage the OpenClaw repo for FREE!*는 OpenClaw repo의 이슈/PR을 local Gemma/Qwen 모델과 Pi harness로 분류하는 사례를 정리한다.
블로그는 local_models, self_hosted_inference, agent_runtime, codex, ui_tui 같은 label을 자동 분류하고, restricted read-only repo shell과 structured final_json을 결합한다.
이 사례는 로컬 모델의 현실적 사용처를 잘 보여준다.
완벽한 general assistant가 아니라, 반복적이고 high-throughput이며 민감할 수 있는 triage 작업에 먼저 붙이는 것이다.
특히 이슈/PR 내용에는 prompt injection이나 악성 입력이 섞일 수 있으므로, 영상과 블로그 모두 “로컬이라 안전하다”에서 끝내지 않고 tool boundary와 read-only shell을 이야기한다.
즉 로컬 모델의 장점은 개인정보와 비용 통제지만, 작은 모델이 prompt injection이나 data exfiltration을 더 잘 막는다는 뜻은 아니다.
오히려 로컬 모델을 agent harness에 붙일수록 command allowlist, repository shell, container, structured output, human review 같은 주변 통제가 더 중요해진다.
타임라인으로 보는 핵심 구간
공식 YouTube 챕터는 없었기 때문에 transcript 흐름과 화면 전환을 기준으로 구간을 나누면 다음처럼 읽을 수 있다.
| 시간 | 구간 | 핵심 내용 |
|---|---|---|
| 01:00–05:00 | 라이브 소개와 패널 소개 | Ben, Daniel Han, Merve Noyan, Onur Solmaz가 등장하고 local/open AI 입문 세션으로 framing |
| 05:00–10:30 | 오픈 모델과 로컬 모델의 차이 | open weights, open source, local model, privacy/cost trade-off 구분 |
| 10:30–20:45 | Merve의 llama.cpp/llama.app 파트 |
GGUF, llama-cli, llama-server, Web UI, Hub hardware compatibility, Pi extension 소개 |
| 21:00–25:30 | 하드웨어 비용 Q&A | MacBook unified memory, MoE quant, long-running task에는 더 큰 hosted model도 필요할 수 있음 |
| 25:55–37:45 | Daniel의 GGUF/Unsloth 파트 | Dynamic quantization, KL divergence, Qwen/Gemma/Kimi, MTP, Gemma demo |
| 38:35–49:40 | Ben의 coding agent harness 파트 | Claude/Codex-style 도구, Pi, OpenCode, Inference Providers, 같은 모델도 harness에 따라 결과가 달라짐 |
| 50:50–63:30 | Onur의 LM Studio/OpenClaw 파트 | Qwen/Gemma MoE 모델 선택, LM Studio 설정, local multi-agent/sub-agent demo, PR triage 사례 |
| 63:40–70:29 | 마무리와 자료 정리 | llama.app, Inference Providers docs, OpenClaw PR triage blog, Unsloth docs를 후속 자료로 제시 |
이 타임라인은 영상의 장점과 단점을 동시에 보여준다.
입문 세션답게 넓게 훑지만, 각 세부 주제는 별도 문서를 봐야 한다.
특히 quant benchmark, provider pricing, OpenClaw/LM Studio 설정은 영상만 보고 따라 하기보다 공식 문서와 블로그를 함께 읽는 편이 안전하다.
실무 관점에서의 해석
내가 이 영상을 보고 얻은 가장 큰 정리는 “로컬 AI 도입은 모델 선택표가 아니라 운영 설계표”라는 점이다.
첫 번째 결정은 어디까지 로컬이어야 하는가다.
민감한 내부 repo, 개인 문서, 고객 데이터가 들어간다면 fully local 경로가 매력적이다.
하지만 첫날부터 40B MoE 모델, quant 선택, local server, context setting, agent integration, prompt-injection 방어를 모두 운영하기는 어렵다.
Hosted Inference Providers로 open model 경험을 먼저 확인하고, 반복적이고 민감한 workload부터 로컬로 내리는 hybrid path가 현실적일 수 있다.
두 번째 결정은 어떤 모델 크기와 quant가 업무에 충분한가다.
간단한 분류, routing, 초안 요약에는 작은 모델이나 aggressive quant도 충분할 수 있다.
반대로 장기 코딩 세션, 복잡한 repo 수정, multi-agent planning, security-sensitive tool use에는 더 큰 모델이나 더 보수적인 quant가 필요할 수 있다.
영상 속 “로컬 모델은 좋다”는 메시지는 “모든 작업을 로컬 작은 모델에 맡겨도 된다”가 아니다.
세 번째 결정은 하네스의 권한 모델이다.
로컬 모델이 데이터를 외부로 보내지 않는다고 해서 자동으로 안전한 것은 아니다.
에이전트가 shell, browser, GitHub, filesystem을 만지는 순간 위험은 모델 endpoint가 아니라 tool boundary에서 생긴다.
OpenClaw PR triage 사례처럼 read-only repo shell, label schema, structured output, container, human notification 같은 설계가 붙어야 한다.
마지막으로, 이 영상은 Hugging Face가 단순 model hub를 넘어 오픈 모델 실행 surface 전체를 묶으려는 방향도 보여준다.
Hub의 hardware compatibility, llama.cpp integration, Inference Providers, llama.app, agent setup docs, OpenClaw/LM Studio 연결이 모두 같은 문제를 다른 층에서 푸는 셈이다.
정리
Welcome to Open Source AI는 새로운 단일 기술 발표라기보다, 2026년 현재 로컬 오픈 모델 생태계의 “사용 경로”를 보여주는 영상이다.
모델은 Hugging Face Hub에 있고, quant와 GGUF는 Unsloth와 community가 다듬고, llama.cpp와 LM Studio가 로컬 서버가 되며, Pi/OpenClaw/OpenCode 같은 하네스가 실제 업무로 연결한다.
따라서 로컬 AI를 시작하려는 팀에게 좋은 첫 질문은 “어떤 모델이 제일 똑똑한가”가 아니다.
더 좋은 질문은 다음이다.
- 내 업무는 hosted open model로 충분한가, fully local이어야 하는가?
- 내 하드웨어에서 돌아가는 quant와 context window는 어디까지인가?
- 이 모델을 어떤 OpenAI-compatible endpoint로 expose할 것인가?
- 에이전트 하네스는 어떤 tool과 권한을 갖는가?
- 실패했을 때 어떤 로그와 verifier로 원인을 볼 것인가?
이 질문에 답할 수 있다면, 오픈 모델은 단순한 “대체 모델”이 아니라 개인과 팀이 통제할 수 있는 실행 스택이 된다.
이 영상의 가치는 바로 그 관점을 한 시간 안에 연결해 보여준 데 있다.