문서 기반 AI 시스템을 만들 때 가장 먼저 부딪히는 문제는 “문서를 읽게 하는 것”이 아니다.
실제 병목은 읽은 내용을 어떤 구조로 남길 것인가다.
단순 요약은 금방 휘발되고, 벡터 인덱스는 검색에는 좋지만 관계·시간·공간·중복 병합 같은 구조를 명시적으로 다루기 어렵다.
반대로 처음부터 도메인별 지식 그래프 스키마를 설계하면 도입 비용이 커진다.
Hyper-Extract는 이 사이를 겨냥한 Python/CLI 프레임워크다.
프로젝트의 핵심 표현은 “Transform documents into structured knowledge with one command”다.
비정형 텍스트를 LLM으로 읽고, 결과를 단순 리스트부터 Pydantic 모델, 지식 그래프, 하이퍼그래프, temporal/spatial/spatio-temporal graph 같은 타입 있는 Knowledge Abstract로 만든다.
내가 보기에 이 저장소의 흥미로운 지점은 “또 하나의 GraphRAG 구현체”라기보다, 문서 → 구조화 추출 → 저장/검색/시각화 → 에이전트 질의까지 이어지는 작은 운영 표면을 한 패키지 안에 모으려 한다는 점이다.
그래서 RAG 라이브러리, 정보 추출 템플릿, 그래프 시각화 도구, Obsidian export, MCP 서버의 경계에 걸쳐 있다.
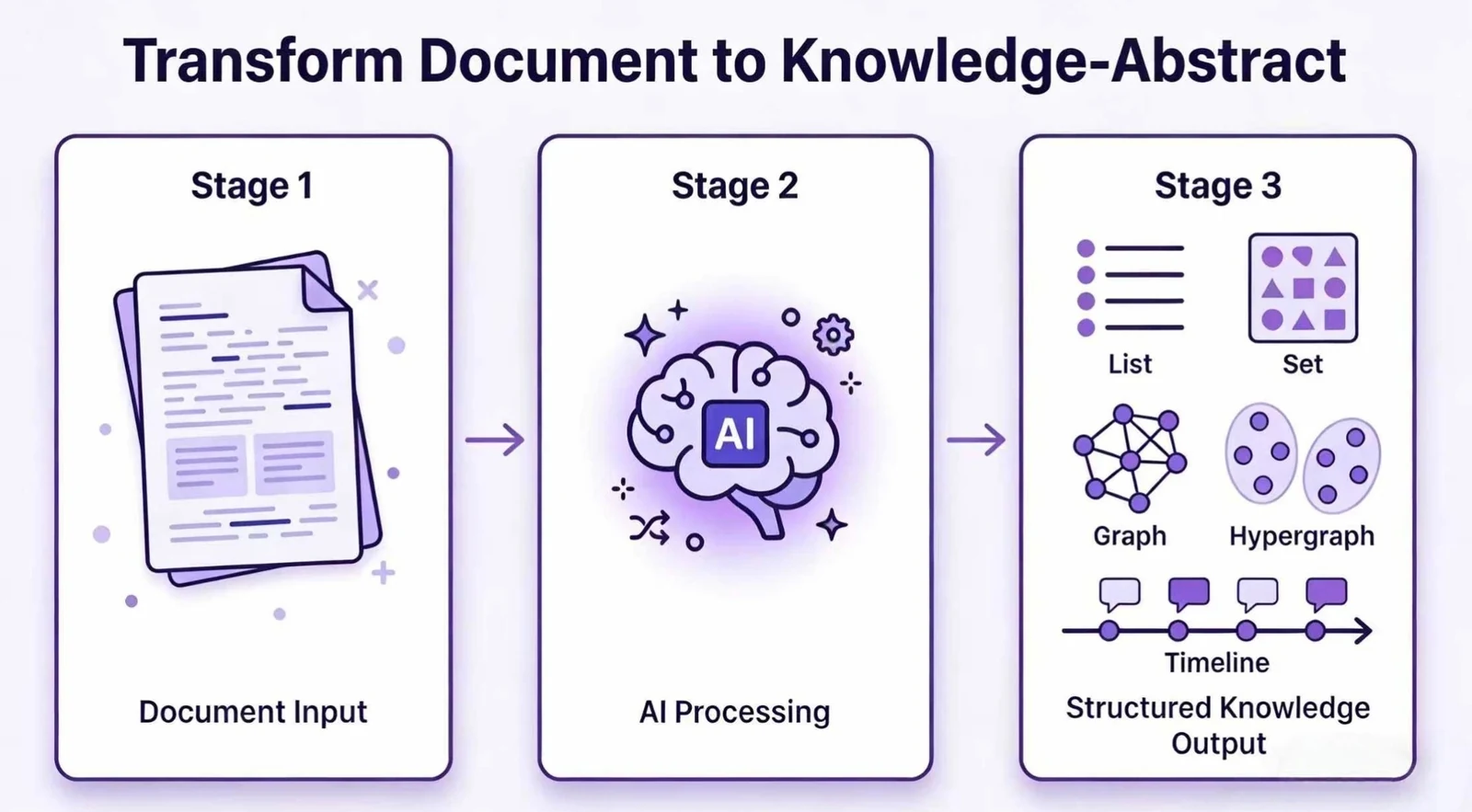
무엇을 해결하려는가
기존 문서 AI 파이프라인은 보통 세 가지 중 하나로 치우친다.
첫째, 프롬프트로 JSON을 뽑는 가벼운 extractor다.
빠르지만 chunking, merge, 중복 제거, schema reuse, indexing을 매번 다시 만들어야 한다.
둘째, GraphRAG/LightRAG 같은 그래프 기반 RAG 시스템이다.
문서 규모가 커지면 강하지만, 도메인별 출력 타입과 템플릿을 사용자가 직접 설계해야 하는 경우가 많다.
셋째, Notion/Obsidian/Neo4j 같은 저장소 중심 workflow다.
사람이 보기에는 좋지만 추출 스키마와 LLM provider 교체, semantic search, CLI 자동화가 별도 문제로 남는다.
Hyper-Extract는 이 공백을 “Knowledge Abstract”라는 단위로 묶는다.
문서를 넣으면 특정 Auto-Type 인스턴스가 나오고, 그 인스턴스는 저장, 로드, 검색, chat, 시각화, export의 대상이 된다.
즉 결과물이 단순한 dict나 임시 JSON이 아니라 후속 작업을 가진 객체가 된다.
공식 문서의 architecture 설명을 보면 흐름은 단순하다.
- 긴 입력 텍스트를 chunk로 나눈다.
- 각 chunk를 LLM structured output으로 추출한다.
- chunk별 결과를 merge한다.
- 최종 결과를 Auto-Type 인스턴스로 만든다.
- 필요하면 index를 만들고 search/chat/show/export 단계로 이어간다.
이 설계가 유용한 이유는 “한 번 뽑고 끝”이 아니라 계속 자라는 지식 베이스를 상정하기 때문이다.
문서에는 feed_text()를 통해 새 내용을 기존 Knowledge Abstract에 추가하고, 중복과 충돌을 병합하며, index를 다시 만들어 search/chat에 반영하는 workflow가 나온다.
핵심 아이디어: Auto-Type, Method, Template의 세 층
Hyper-Extract의 구조는 세 층으로 읽으면 쉽다.
| 층 | 역할 | 예시 |
|---|---|---|
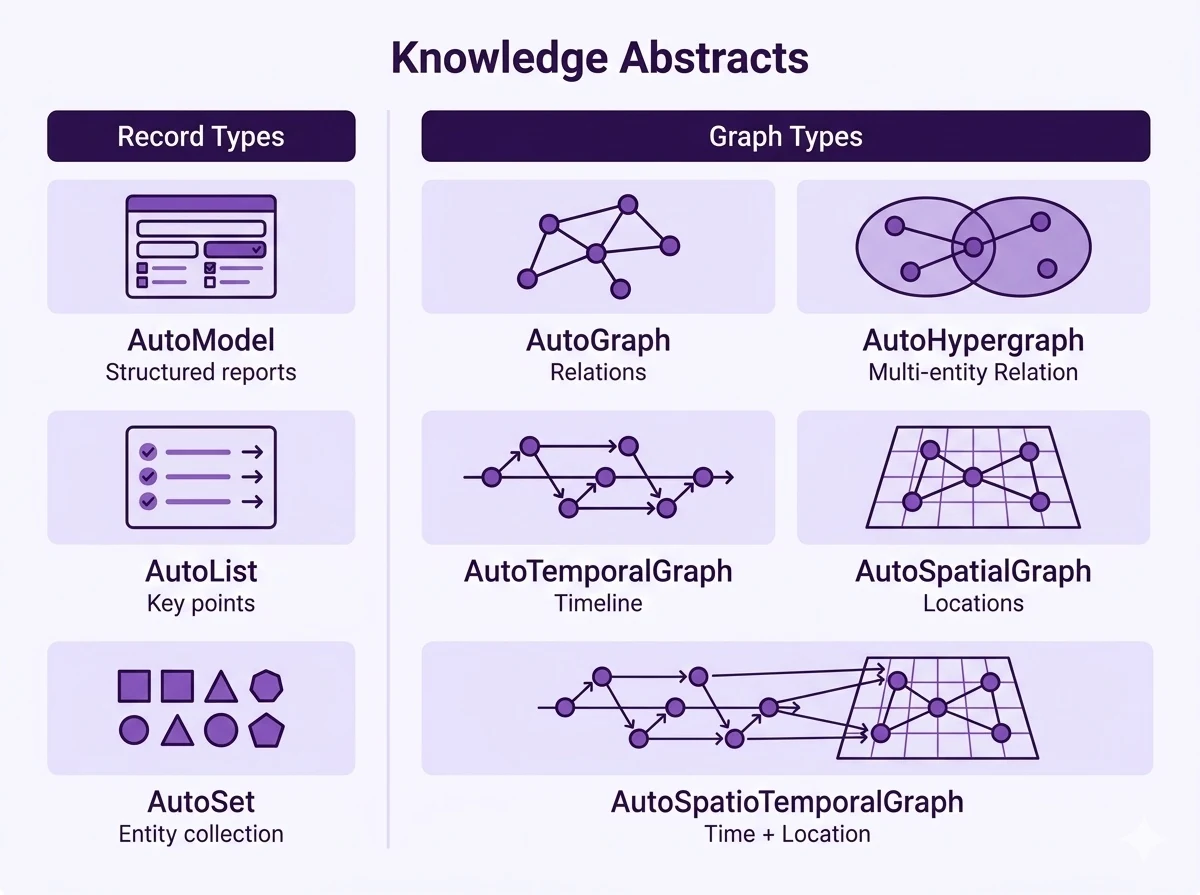
| Auto-Type | 추출 결과의 데이터 구조를 정한다 | AutoModel, AutoList, AutoGraph, AutoHypergraph, AutoSpatioTemporalGraph |
| Method | 어떤 추출 알고리즘을 쓸지 정한다 | itext2kg, kg_gen, atom, light_rag, graph_rag, hyper_rag, cog_rag |
| Template | 도메인별 설정을 YAML로 묶는다 | finance, legal, medicine, TCM, industry, general presets |
Auto-Type은 출력 모양을 결정한다.AutoModel은 하나의 구조화 객체, AutoList는 순서 있는 항목 목록, AutoSet은 중복 없는 엔티티 집합이다.
그래프 계열은 더 중요하다.AutoGraph는 두 엔티티 사이의 binary relationship을 다루고, AutoHypergraph는 3개 이상 엔티티가 함께 걸리는 관계를 다룬다.AutoTemporalGraph, AutoSpatialGraph, AutoSpatioTemporalGraph는 여기에 시간과 위치 차원을 더한다.
Method는 extraction strategy다.
공식 methods 문서는 direct extraction 계열과 RAG-based 계열을 나눈다.
작은 문서나 직접 추출에는 itext2kg, itext2kg_star, kg_gen, atom 같은 typical method가 쓰이고, 큰 문서나 복잡한 질의에는 light_rag, graph_rag, hyper_rag, hypergraph_rag, cog_rag 같은 RAG method가 쓰인다.
문서 크기 기준으로는 1K words 미만은 itext2kg/kg_gen, 1–10K는 light_rag/itext2kg_star, 10–50K는 light_rag/graph_rag, 50K 초과는 graph_rag를 추천한다.
Template은 사용자의 진입 비용을 낮추는 층이다.
README와 docs는 finance, legal, medical, TCM, industry, general 도메인을 강조한다.
현재 저장소 트리 기준으로는 hyperextract/templates/presets/ 아래에 37개의 YAML preset이 확인된다.
반면 README와 문서의 마케팅 문구는 “80+ Domain Templates”라고 설명하고, docs reference table에도 일부 경로명이 실제 파일명과 다르게 보이는 항목이 있다.
따라서 도입할 때는 문구 숫자보다 실제 he list 또는 repository tree로 필요한 template이 있는지 확인하는 편이 안전하다.
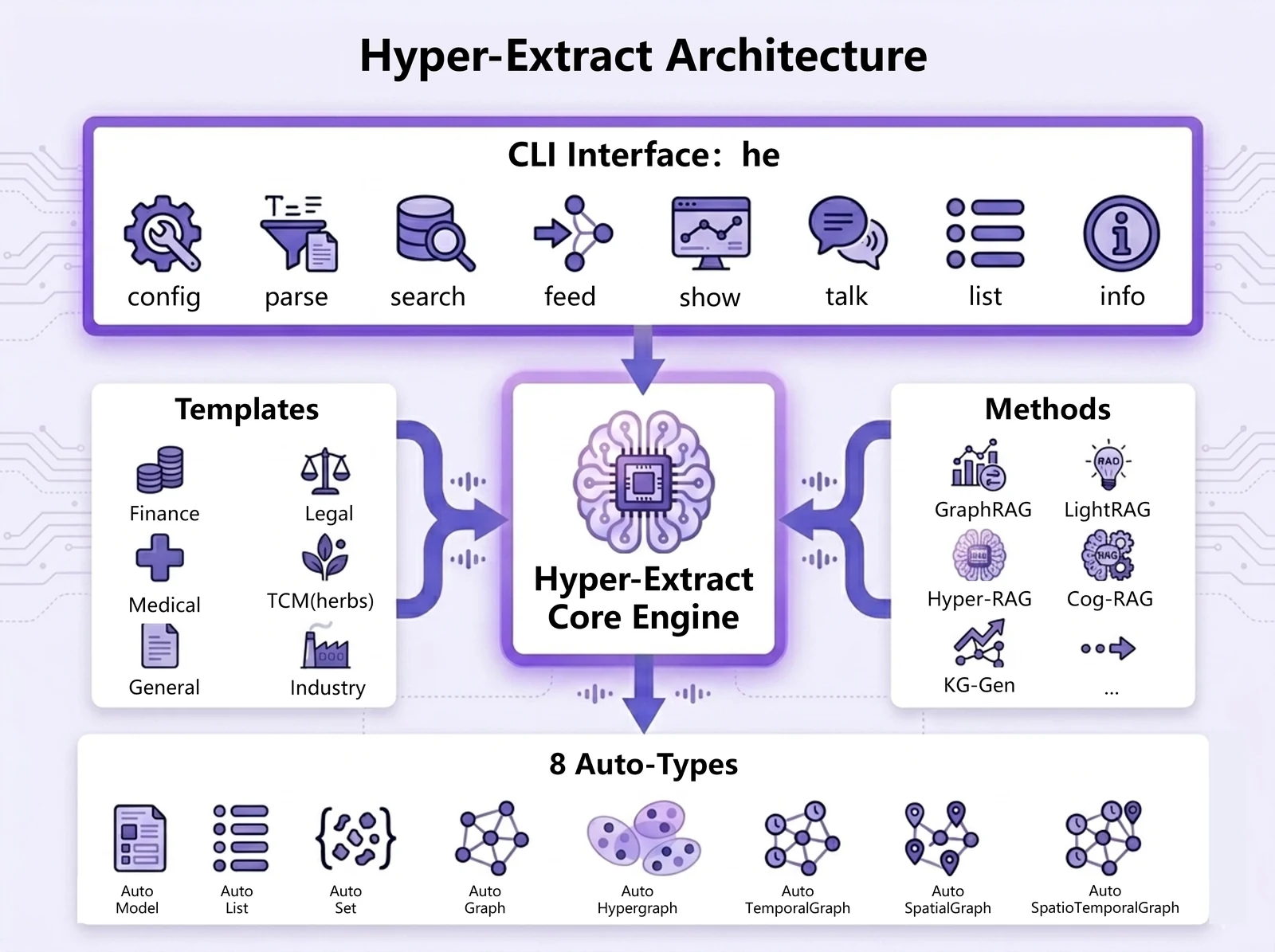
사용 표면: CLI, Python SDK, MCP, Obsidian
사용자는 CLI와 Python API 중 하나로 시작할 수 있다.
README의 30초 quick start는 다음 흐름이다.
uv tool install hyperextract
he config init -k YOUR_OPENAI_API_KEY
he parse examples/en/tesla.md -t general/biography_graph -o ./output/ -l en
he search ./output/ "What are Tesla's major achievements?"
he show ./output/
he export obsidian ./output/ -o ./vault/
Python에서는 Template.create("general/biography_graph")로 template을 만들고, parse() 결과를 show()하거나 build_index(), search(), chat()으로 이어간다. search/chat은 index가 필요하고, 검색 결과는 graph type의 경우 nodes와 edges를 반환한다. chat 응답에는 retrieval에 사용된 nodes/edges를 additional kwargs로 확인할 수 있도록 설계돼 있다.
최근 v0.3.0에서 붙은 MCP 서버도 이 프로젝트의 방향을 잘 보여준다. he-mcp는 기존 Knowledge Abstract를 MCP-capable assistant에서 질의하고 export하기 위한 stdio MCP 서버다.
문서와 코드 기준 도구는 다음과 같다.
| MCP tool | 역할 | 주의점 |
|---|---|---|
list_templates |
사용 가능한 extraction template 목록 | LLM 불필요 |
info |
KA의 template, node/edge count, index 상태 확인 | LLM 불필요 |
search |
Knowledge Abstract semantic search | index와 embedder 필요 |
ask |
RAG 기반 Q&A | index, embedder, LLM 필요 |
export_obsidian |
graph 계열 KA를 Obsidian vault로 export | 기존 KA를 export하는 read/export 성격 |
중요한 것은 MCP 서버가 read + export only로 설명된다는 점이다.
문서와 mcp_server.py 모두 KA를 새로 만들거나 삭제·수정하지 않는다고 적고 있다.
즉 Hyper-Extract는 “에이전트가 마음대로 문서를 재추출하는 서버”라기보다, 이미 만들어 둔 지식 추출 결과를 에이전트에게 질의 가능한 context surface로 열어 주는 쪽에 가깝다.
Obsidian export도 같은 맥락이다.
그래프를 Markdown note와 [[wikilinks]]로 바꿔 vault에 내보낼 수 있다.
이 기능은 순수 검색 인덱스와 다른 가치를 만든다.
사람이 읽고 고칠 수 있는 지식 노트가 생기고, 에이전트는 다시 그 vault를 context source로 쓸 수 있다.
LightRAG 기준으로 본 raw 문서 의미 추출 정확도
여기서 LightRAG와 비교할 때의 핵심은 라이브러리 기능이나 운영 workflow가 아니라, raw 문서에서 의미를 얼마나 정확히 뽑아 구조화하느냐다.
LightRAG의 graph construction prompt는 지정된 entity type을 기준으로 문서에서 entity와 relationship을 찾고, entity description, relationship description, relationship strength, high-level keyword 같은 정보를 만들어 knowledge graph에 넣는다.
즉 비교 대상은 “검색이 빠른가”보다 “원문에 실제로 있는 의미 단위를 빠짐없이, 틀리지 않게, 근거와 함께 뽑았는가”가 되어야 한다.
이 관점에서 Hyper-Extract의 강점은 AutoGraph, AutoHypergraph, AutoTemporalGraph, AutoSpatialGraph처럼 출력 타입을 먼저 정해 놓고 추출한다는 점이다.
LightRAG식 graph extraction은 retrieval용 entity/relation graph를 만드는 데 초점이 있고, Hyper-Extract는 도메인 template과 Auto-Type이 요구하는 구조를 채우는 데 초점이 있다.
따라서 두 방식을 비교하려면 같은 raw 문서, 같은 gold annotation, 같은 entity/relation schema를 놓고 “추출 정확도”를 봐야 한다.
| 평가 대상 | 정확하다는 뜻 | 대표 실패 유형 |
|---|---|---|
| Entity | 원문에 있는 개체를 정확한 span/name/type으로 잡는다 | 누락, 과분할, alias 미병합, 잘못된 type |
| Relationship | 원문이 지지하는 source-target-predicate를 뽑는다 | 방향 오류, 관계 label 오류, 원문에 없는 hallucinated edge |
| Attribute | 수치, 날짜, 역할, 상태, 조건을 entity/relation에 올바르게 붙인다 | 단위 오류, 날짜 오독, 조건 누락, 다른 entity에 귀속 |
| Higher-order relation | 3개 이상 entity가 함께 만드는 사건·거래·인과를 보존한다 | binary edge로 쪼개며 의미 손실, 참여자 누락 |
| Temporal/spatial meaning | 시간 순서와 위치 제약을 구조로 남긴다 | 전후 관계 반전, 위치 scope 오류, 기간 누락 |
| Evidence grounding | 각 claim이 원문 chunk/span으로 역추적된다 | 근거 없는 추론, citation 누락, 잘못된 chunk 연결 |
정량 지표도 answer-level win rate보다 extraction-level metric을 우선해야 한다.
LightRAG 논문의 Comprehensiveness, Diversity, Empowerment, Overall은 RAG 답변 품질 지표라서 참고는 되지만, raw 문서 의미 추출기의 정확도를 직접 말해 주지는 않는다.
Hyper-Extract를 평가하려면 다음 지표가 더 맞다.
| 지표 | 계산 방식 | 해석 |
|---|---|---|
| Entity precision/recall/F1 | gold entity와 predicted entity를 span/name/type 기준으로 alignment | 의미 단위를 얼마나 빠짐없이, 과잉 없이 잡는가 |
| Relation precision/recall/F1 | (source, relation, target) strict match와 alias-normalized soft match를 함께 계산 |
원문 관계를 방향과 label까지 맞게 복원하는가 |
| Attribute accuracy | entity/relation별 field exact match, numeric tolerance, date normalization match | 문서의 세부 의미를 구조 필드에 정확히 옮기는가 |
| Unsupported claim rate | predicted entity/relation 중 원문 근거가 없는 비율 | hallucinated graph를 얼마나 만들지 않는가 |
| Evidence hit rate | 각 추출 항목이 올바른 source chunk/span을 가리키는 비율 | 사람이 검증 가능한 추출 결과인가 |
| Canonicalization accuracy | 같은 개체의 alias를 하나로 합치고 다른 개체를 분리하는 정확도 | chunk 경계와 표현 차이를 견디는가 |
| Schema adherence | required field 누락률, enum/type violation, Pydantic parse 실패율 | typed Knowledge Abstract의 계약을 지키는가 |
| Complex meaning coverage | event, causal relation, temporal/spatial constraint, hyperedge의 recall | 단순 entity list를 넘어 문서의 고차 의미를 살리는가 |
실험 설계는 작게라도 gold set을 만드는 쪽이 좋다.
예를 들어 문서 20~50개를 골라 entity, relation, attribute, evidence span을 사람이 annotation하고, Hyper-Extract의 itext2kg/light_rag/graph_rag method와 LightRAG식 extraction을 같은 schema로 돌린다.
그다음 graph size나 답변 점수가 아니라 extraction F1, unsupported claim rate, evidence hit rate, schema adherence를 먼저 비교한다.
이렇게 해야 “문서를 GraphRAG에 쓸 수 있게 만들었다”가 아니라 “raw 문서의 의미를 실제로 얼마나 정확히 구조화했는가”를 말할 수 있다.
공개된 근거에서 확인되는 점
2026년 6월 26일 조회 기준 공개 표면은 다음과 같다.
| 항목 | 확인 내용 | 해석 |
|---|---|---|
| 저장소 | yifanfeng97/Hyper-Extract, Python 주 언어, 기본 브랜치 main |
단일 Python 패키지 중심의 오픈소스 프로젝트 |
| 관심도 | GitHub API 기준 stars 2,405, forks 274, open issues 2 | 짧은 기간에 빠르게 관심을 받은 상태 |
| 생성/활동 | repo 생성 2026-01-07, 최근 push 2026-06-25 | 2026년 상반기에 빠르게 기능이 추가되는 프로젝트 |
| 최신 릴리스 | v0.3.0 - Claude, Obsidian, MCP & Clean, 2026-06-19 |
Claude provider, Obsidian export, MCP server, he clean, reliability fixes가 핵심 |
| PyPI | hyperextract 0.3.0, wheel/sdist 업로드 2026-06-19, Python >=3.11 |
uv tool install hyperextract와 Python 패키지 설치가 실제 배포되어 있음 |
| 실행 명령 | he, he-mcp가 pyproject.toml의 script로 등록 |
CLI와 MCP 서버가 배포 표면에 포함됨 |
| 라이선스 | LICENSE와 pyproject.toml은 Apache-2.0, GitHub API license field는 NOASSERTION |
실제 파일 기준 Apache-2.0으로 보되, API metadata는 정규화되지 않은 상태 |
| Provider | OpenAI, Alibaba Bailian, Anthropic Claude, local vLLM 문서화 | structured output과 embedding provider 호환성이 핵심 제약 |
| Local path | Qwen3.5-9B GPTQ-Marlin + bge-m3 via vLLM 예시 | 온프레미스/로컬 문서 추출 시나리오를 명시적으로 겨냥 |
| Template count | README/docs는 “80+”를 말하지만 현재 preset YAML은 37개 확인 | 빠르게 변하는 문서/코드 상태로 보이며, 필요한 도메인은 직접 확인 필요 |
v0.3.0 릴리스 노트에서 가장 실용적인 변화는 세 가지다.
첫째, Anthropic Claude provider가 들어왔다.
Claude는 LLM으로만 쓰고 embedding은 OpenAI-compatible embedder와 조합해야 한다는 caveat가 문서에 명확히 적혀 있다.
둘째, Obsidian vault export가 추가됐다.
셋째, MCP 서버가 생겼다.
여기에 multi-chunk embedding mean, OpenAI-compatible embedding batch cap, llm_* merge strategy fix 같은 안정성 수정이 붙었다.
다만 프로젝트 자체는 PyPI classifier 기준 Development Status :: 3 - Alpha다.
따라서 production document pipeline의 핵심 컴포넌트로 바로 넣기보다는, template coverage, provider compatibility, structured output 실패율, chunk merge 품질, index 재생성 비용을 작은 corpus에서 먼저 확인해야 한다.
실무 관점에서의 해석
Hyper-Extract가 유용해 보이는 첫 번째 영역은 반복되는 문서 구조화 작업이다.
예를 들어 earnings report, legal contract, medical discharge note, 산업 설비 failure report처럼 매번 비슷한 타입의 문서를 받아 엔티티·관계·리스크·타임라인을 뽑아야 하는 경우다.
이런 작업은 일반 RAG보다 “내가 어떤 구조를 원한다”는 제약이 강하다.
Template + Auto-Type 조합은 이 제약을 코드와 YAML로 남길 수 있게 한다.
두 번째 영역은 에이전트용 장기 context 제작이다.
에이전트가 문서 원문을 매번 검색하는 대신, 한 번 Knowledge Abstract로 뽑아 두고 MCP나 Obsidian vault로 질의하게 만들면 context surface가 더 작고 명시적이 된다.
특히 그래프 계열 출력은 사람·조직·사건·위치·시간의 관계를 장기적으로 관리하는 데 맞다.
세 번째는 로컬/온프레미스 추출이다.
문서에 Qwen3.5-9B GPTQ-Marlin과 bge-m3를 vLLM으로 띄우는 예시가 있는 점은 중요하다.
민감한 보고서나 내부 문서를 외부 API로 보내기 어렵다면, local vLLM provider와 embedding endpoint를 붙이는 경로가 있다.
물론 이때도 모델의 structured output 안정성, GPU 메모리, latency, embedding 품질을 별도로 평가해야 한다.
반대로 조심해야 할 점도 있다.
Hyper-Extract가 “그래프를 만든다”고 해서 곧바로 고품질 knowledge graph가 보장되는 것은 아니다.
LLM extraction은 누락, hallucinated relation, 중복 entity, 스키마 불일치, chunk boundary 문제를 만든다. docs의 architecture도 결국 prompt → LLM call → Pydantic parse → merge 구조다.
따라서 사람이 검토할 수 있는 visualization과 Obsidian export는 장점이지만, 운영에서는 validation rule, sampling review, domain-specific schema test가 필요하다.
또 하나의 caveat는 template/documentation drift다.
README의 “80+ templates”와 실제 tree에서 보이는 preset YAML 수가 다르고, docs overview table에도 현재 파일명과 완전히 맞지 않는 항목이 보인다.
빠르게 성장하는 프로젝트에서 흔한 현상이지만, 사용자 입장에서는 문서의 headline보다 he list, repository tree, PyPI version을 기준으로 채택 범위를 정해야 한다.
정리
Hyper-Extract는 비정형 텍스트를 “검색 가능한 문서 조각”이 아니라 타입 있는 지식 산출물로 바꾸려는 도구다.
Auto-Type은 출력 구조를 정하고, Method는 추출 알고리즘을 정하고, Template은 도메인별 사용성을 낮춘다.
그 결과물은 CLI에서 검색·시각화할 수 있고, Python SDK로 앱에 붙일 수 있으며, MCP와 Obsidian을 통해 에이전트/노트 workflow로 이어진다.
이 프로젝트를 가장 잘 설명하는 문장은 “GraphRAG보다 강한 하이퍼그래프”라기보다, 문서 추출 결과를 에이전트가 다시 쓸 수 있는 Knowledge Abstract로 포장하는 프레임워크에 가깝다.
아직 alpha 성격과 문서/템플릿 drift는 있지만, 문서 → 구조화 지식 → 검색/질의/에이전트 context로 이어지는 경량 스택을 찾는 팀이라면 살펴볼 만하다.