사진을 찍을 때 필요한 조언은 “나중에 어디를 자르면 예쁠까”만이 아니다.
지금 구도를 유지해도 되는지, 조금 더 가까이 들어가야 하는지, 아예 다시 찍어야 하는지, 그리고 사람이라면 어떤 포즈를 취해야 장면과 잘 맞는지까지 촬영 순간에 결정해야 한다.
ShutterMuse: Capture-Time Photography Guidance with MLLMs는 이 문제를 사후 크롭 추천이 아니라 capture-time photography guidance 문제로 다시 정의한 논문이다.
저자들은 CaptureGuide-Bench라는 평가 벤치마크와 약 130K 샘플 규모의 CaptureGuide-Dataset을 만들고, Qwen3-VL-8B 기반 MLLM인 ShutterMuse를 SFT와 GRPO 계열 reinforcement fine-tuning으로 학습했다.

이 글은 Hugging Face Papers, arXiv v1, 공식 프로젝트 페이지, GitHub 저장소, Hugging Face 모델·데이터셋 API를 기준으로 정리했다.
수치는 저자 공개 README와 논문 보고값이며, 별도 재현 실험은 하지 않았다.
문제 설정: 크롭 모델만으로는 촬영 중 조언이 부족하다
기존 aesthetic cropping 벤치마크는 대체로 이미 찍힌 사진에서 더 나은 crop box를 찾는 문제로 구성된다.
하지만 실제 촬영 상황에서는 세 가지가 섞인다.
| 상황 | 필요한 출력 | 기존 크롭 벤치마크의 빈틈 |
|---|---|---|
| 현재 구도가 괜찮음 | keep |
모든 사진을 개선 대상으로 보면 불필요한 크롭을 권할 수 있다 |
| 구도는 고칠 수 있음 | refine + composition box |
이 영역은 기존 crop 모델이 비교적 잘 다루는 구간이다 |
| 크롭으로 해결 불가 | reject |
조명, 가림, 피사체 위치처럼 다시 찍어야 하는 경우를 분리해야 한다 |
| 피사체가 사람임 | scene-conditioned pose | 카메라 쪽 구도뿐 아니라 피사체 쪽 행동 지시가 필요하다 |
논문의 핵심 주장은 단순하다.
일반 MLLM은 “이 사진이 괜찮아 보이는가” 같은 고수준 판단은 할 수 있지만, 정밀한 refinement box localization은 약하다.
반대로 전문 aesthetic cropping 모델은 crop localization에는 강하지만 keep이나 reject, 피사체 포즈 추천까지는 다루지 않는다.
ShutterMuse는 이 둘을 하나의 capture-time assistant 관점으로 묶으려는 시도다.
CaptureGuide: 100K 구도 샘플과 30K 포즈 샘플
논문이 만든 데이터는 두 축으로 나뉜다.
전체 CaptureGuide-Dataset은 약 130K 이미지이며, 그중 100K는 photographer-side guidance, 30K는 subject-side guidance다.
별도 평가용 CaptureGuide-Bench에는 photographer-side 421개 held-out 샘플과 subject-side 552개 샘플이 포함된다. refine 샘플에는 이미지당 3~5개의 ground-truth bounding box가 붙는다.
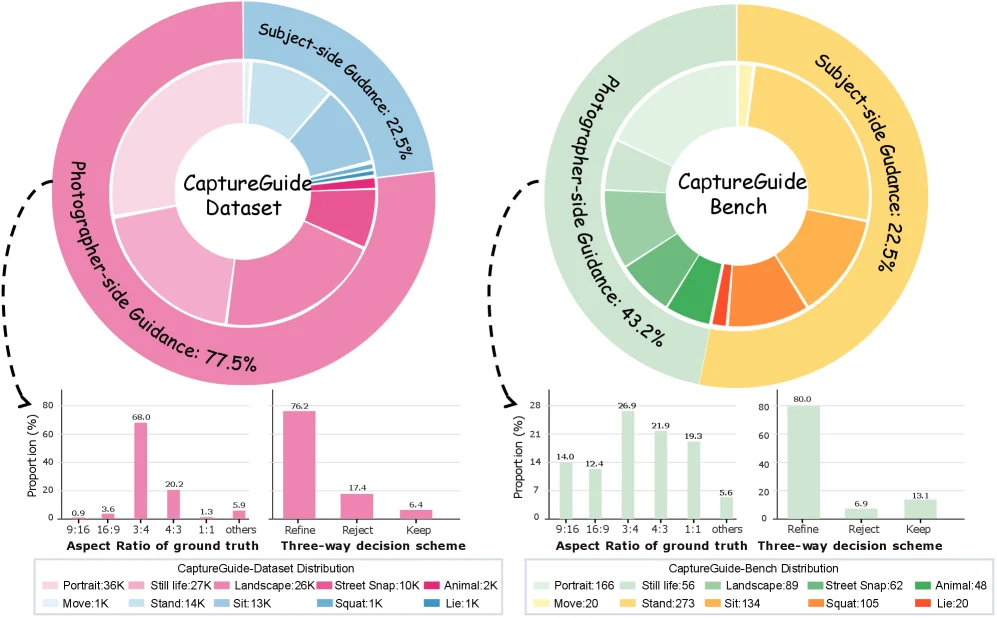
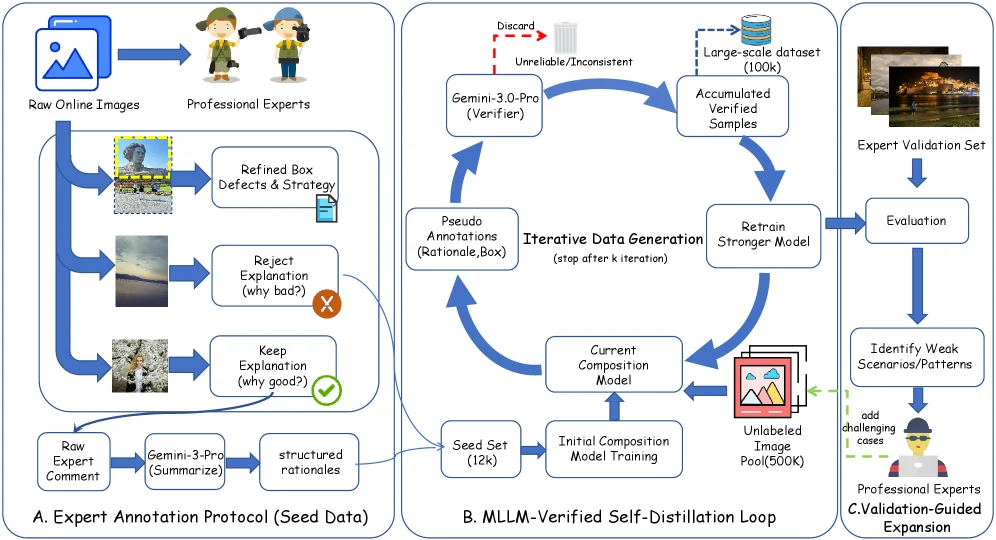
Photographer-side 데이터 구축은 expert seed annotation에서 시작한다.
전문가가 만든 초기 주석을 MLLM으로 구조화하고, pseudo-labeling과 verification을 거쳐 확장한 뒤 held-out validation set으로 품질을 모니터링한다.
즉 단순히 웹 이미지를 긁어 crop box를 붙인 것이 아니라, keep/refine/reject 판단과 그 이유, refinement box를 함께 갖는 데이터셋을 만들려는 설계다.
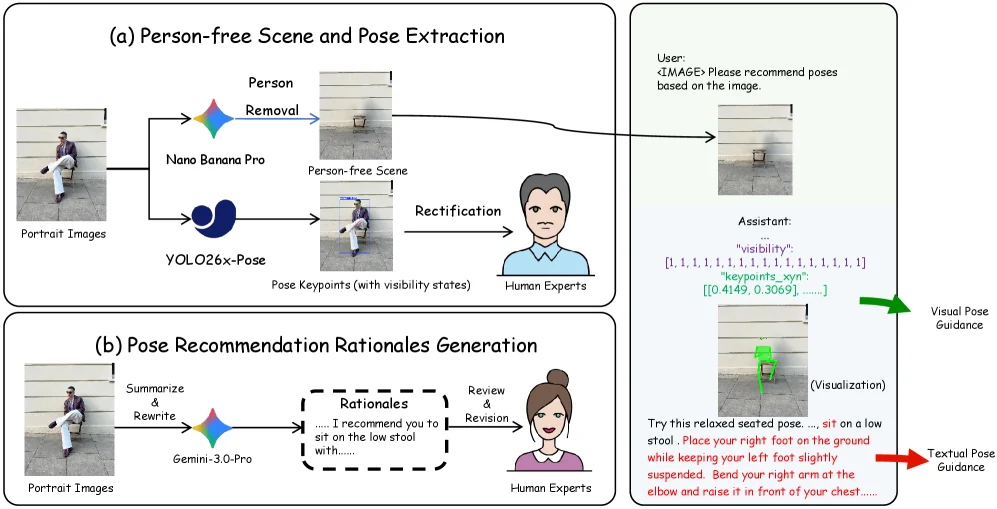
Subject-side 데이터는 조금 더 흥미롭다.
원본 portrait image에서 사람을 제거해 person-free scene을 만들고, 원래 인물의 COCO-17 keypoint를 추출한다.
이후 Gemini-3.0-Pro가 장면과 포즈를 설명하고, 전문 주석자가 rationale과 keypoint를 검수한다.
논문은 occlusion과 truncation을 다루기 위해 각 keypoint에 세 가지 visibility state를 둔다.
최종적으로 장면 이미지, 목표 포즈 keypoint, 포즈가 왜 그 장면에 맞는지 설명하는 rationale이 한 묶음이 된다.
이 방식의 장점은 “포즈 이미지 생성” 자체를 모델 목표로 삼지 않는다는 점이다.
ShutterMuse는 장면에 맞는 구조화된 pose recommendation을 내고, 프로젝트 페이지의 예시에서는 이 keypoint pose를 GPT-Image-2가 렌더링해 사람이 보기 쉬운 결과로 보여 준다.
즉 포즈 생성 모델이라기보다, 촬영 지시를 구조화하는 MLLM에 가깝다.
모델: Qwen3-VL-8B 위에 구조화된 촬영 지시를 학습한다
ShutterMuse는 Qwen3-VL-8B 기반 MLLM으로 소개된다.
입력 이미지를 보고 photographer-side에서는 JSON 형태로 task_type, reason, composition_xy 같은 구조화 출력을 만들고, subject-side에서는 COCO-17 keypoint와 visibility, rationale을 포함한 응답을 만든다.
훈련은 두 단계로 읽을 수 있다.
| 단계 | 역할 | 공개 자료에서 확인되는 구현 단서 |
|---|---|---|
| SFT | CaptureGuide-Dataset의 구조화 답변 형식을 학습 | GitHub README는 ModelScope Swift 기반 stage1 SFT 스크립트를 제공한다 |
| GRPO / RFT | composition box, decision, pose visibility 등 보상 신호로 후속 정렬 | README에는 ratio_orm, iou_orm, pose_visibility_orm, saliency_orm reward 함수가 언급된다 |
실무적으로는 “사진 전문가의 언어 조언을 흉내 내는 챗봇”보다 더 제한된 schema를 가진 모델로 보는 편이 안전하다.
출력이 box, keypoint, visibility state처럼 기계가 후처리할 수 있는 형태를 포함하기 때문이다.
촬영 앱에 붙인다면 자연어 안내와 UI overlay를 함께 만들 수 있는 구조다.
결과: 구도 쪽은 강하고, 포즈 쪽은 비용 대비 빠르다
GitHub README에 공개된 photographer-side 결과를 보면 ShutterMuse는 IoU, BDE, refinement success rate, MLLM-Score에서 가장 좋은 값을 보고한다.
단, keep success rate는 Gemini-3.0-Pro가 더 높고, reject success rate는 Gemini-3.0-Pro와 ShutterMuse가 같은 값으로 보고된다.
| Method | IoU ↑ | BDE ↓ | R ↑ | RSR ↑ | KSR ↑ | MLLM-Score ↑ |
|---|---|---|---|---|---|---|
| Gemini-3.0-Pro | 63.62 | 0.070 | 47.48 | 82.76 | 89.09 | 0.54 |
| GPT-5.5 | 65.44 | 0.091 | 41.84 | 10.34 | 81.82 | 0.48 |
| Venus | 69.43 | 0.076 | 57.27 | 0.00 | 3.64 | 0.57 |
| ShutterMuse | 74.30 | 0.054 | 70.03 | 82.76 | 74.55 | 0.64 |
여기서 중요한 지표는 IoU 하나만이 아니다.R은 IoU가 0.7을 넘는 refinement success rate이고, RSR/KSR은 각각 reject와 keep을 제대로 맞히는 비율이다.
촬영 중 assistant라면 “잘라야 할 때 잘 자르는가”와 “그냥 두거나 버려야 할 때를 구분하는가”가 함께 중요하다.
Subject-side 결과는 더 조심스럽게 봐야 한다.
Nano-Banana-Pro와 GPT-Image-2가 평균 품질 점수에서는 앞서지만, ShutterMuse는 시간과 token 비용에서 훨씬 낮은 값을 보고한다.
| Method | Plausibility ↑ | Interaction ↑ | Aesthetics ↑ | Mean ↑ | Time ↓ | Tokens ↓ |
|---|---|---|---|---|---|---|
| Nano-Banana-Pro | 0.63 | 0.35 | 0.17 | 0.39 | 55.16 | 1370 |
| GPT-Image-2 | 0.59 | 0.29 | 0.15 | 0.35 | 102.61 | 1427 |
| ShutterMuse | 0.58 | 0.27 | 0.14 | 0.34 | 4.96 | 412 |
이 표의 메시지는 “ShutterMuse가 이미지 생성 모델보다 포즈 품질이 무조건 좋다”가 아니다.
오히려 품질은 약간 낮지만, keypoint 기반 pose recommendation을 훨씬 작은 비용으로 낼 수 있다는 쪽에 가깝다.
촬영 앱처럼 여러 후보를 빠르게 탐색해야 하는 환경에서는 이 차이가 더 실용적일 수 있다.
공식 예시에서 보이는 사용 방식
프로젝트 페이지는 photographer-side와 subject-side 예시를 많이 제공한다.
Photographer-side 예시는 원본 사진과 ShutterMuse의 recommended crop을 나란히 보여 준다.
이 예시는 모델이 단순히 “좋아요/나빠요”를 말하는 것이 아니라, 실제 UI가 box overlay로 보여 줄 수 있는 출력을 만든다는 점을 잘 보여 준다.

Subject-side 예시는 scene image에 맞는 pose skeleton을 추천하고, 이를 이미지 생성 모델로 렌더링한 결과를 보여 준다.
여기서 실용적인 포인트는 모델 출력이 “오른쪽으로 살짝 돌아서세요” 같은 문장만이 아니라, COCO keypoint와 visibility state를 포함할 수 있다는 점이다.
AR guide, camera preview overlay, 생성형 reference pose UI와 연결하기 쉬운 형태다.

공개 상태와 주의할 점
공개 상태는 비교적 빠르게 정리되어 있다.
GitHub 저장소에는 quick start, evaluation, training 스크립트가 있고, Hugging Face에는 ShutterMuse/ShutterMuse 모델과 ShutterMuse/CaptureGuide-Bench 데이터셋이 올라와 있다.
확인 시점 기준 GitHub API는 저장소 star 37개, fork 0개, open issue 1개를 반환했다.
HF 모델 API는 public, gated false, image-text-to-text pipeline, Qwen/Qwen3-VL-8B-Instruct base model, BF16 약 8.77B parameter safetensors 4개 shard를 보고한다.
다만 라이선스는 조심해야 한다.
GitHub API에는 license가 null로 보이고, README의 License 섹션도 “TODO: Add license information before public release.”
상태다.
HF 데이터셋 카드도 license를 other로 표시한다.
따라서 연구 검토와 로컬 실험은 가능해 보여도, 상업 제품에 바로 넣을 수 있는 오픈 라이선스 릴리스로 단정하면 안 된다.
실행 관점에서도 모델 카드만 보고 가볍게 돌릴 수 있는 크기는 아니다.
HF API 기준 weights storage는 약 35.08GB이고, README는 base 또는 merged Qwen-VL checkpoint와 ShutterMuse LoRA/checkpoint 경로를 준비하라고 안내한다.
즉 “웹 데모 하나 클릭”보다는, Qwen3-VL 계열 추론 환경과 9B급 VLM 운영 준비가 필요한 연구 릴리스에 가깝다.
실무적으로 읽히는 의미
ShutterMuse의 재미있는 지점은 사진 앱의 AI 기능을 후보 보정 필터가 아니라 촬영 전 의사결정 시스템으로 본다는 데 있다.
지금까지 많은 이미지 AI 기능은 이미 찍은 사진을 더 예쁘게 만들거나, 텍스트로 새 이미지를 생성하는 쪽에 몰려 있었다.
ShutterMuse는 그보다 앞단, 즉 사용자가 셔터를 누르기 전에 모델이 무엇을 말해야 하는지를 묻는다.
이 관점에서는 세 가지가 중요하다.
첫째, keep/refine/reject의 삼분류는 UX적으로 꽤 현실적이다.
모든 사진에 crop box를 띄우면 피로도가 높다.
좋은 구도는 그대로 두고, 안 되는 사진은 crop으로 억지 수정하지 않으며, 애매한 경우에만 box를 제안하는 것이 실제 assistant에 가깝다.
둘째, subject-side guidance는 카메라 앱과 생성 모델 사이의 중간 표현이 될 수 있다.
사람이 취할 포즈를 keypoint로 구조화하면, 프리뷰 overlay, reference pose 렌더링, 촬영 코칭 음성 안내를 모두 같은 출력에서 만들 수 있다.
셋째, 데이터 구축 방식 자체가 앞으로 더 중요해질 수 있다.
ShutterMuse의 성능은 모델 크기만이 아니라, 사진 전문가 seed, MLLM verification, person-free scene 생성, keypoint visibility 검수 같은 데이터 파이프라인에 많이 기대고 있다.
촬영 조언은 주관적이지만, 제품에 넣으려면 적어도 어떤 조언이 actionable한지 평가할 수 있어야 한다.
CaptureGuide-Bench는 그 평가 형식을 제안한다는 점에서 의미가 있다.
정리
ShutterMuse는 “사진을 예쁘게 잘라 주는 모델”보다 넓은 문제를 다룬다.
촬영 중 사용자가 필요한 것은 사후 편집이 아니라, 지금 이 장면에서 무엇을 해야 하는지에 대한 짧고 실행 가능한 안내다.
이 논문은 그 안내를 photographer-side composition decision/refinement와 subject-side pose recommendation으로 쪼개고, 각각을 box, keypoint, rationale이 있는 구조화 문제로 만든다.
가장 큰 기여는 세 가지로 요약할 수 있다.
- 사후 crop prediction 중심이던 사진 구도 평가를
keep/refine/reject가 있는 capture-time guidance로 확장했다. - 100K photographer-side, 30K subject-side 샘플과 held-out CaptureGuide-Bench를 공개해 평가 기준을 제안했다.
- Qwen3-VL 기반 ShutterMuse를 공개하고, 구도 보정에서는 강한 저자 보고 성능을, 포즈 추천에서는 품질 대비 낮은 시간·token 비용을 보여 줬다.
반대로 아직 확인할 것도 분명하다.
라이선스가 정리되지 않았고, 결과는 저자 벤치마크와 MLLM judge 기반 평가에 크게 의존한다.
실제 스마트폰 카메라 앱에서 조명, 움직임, 다인 인물, 문화권별 포즈 선호까지 견딜지는 별도 검증이 필요하다.
그래도 “사진 AI”를 사후 보정에서 촬영 순간의 상호작용으로 끌어올리는 방향은 꽤 설득력 있다.
Sources:
- Hugging Face paper page: https://huggingface.co/papers/2606.25763
- arXiv abstract: https://arxiv.org/abs/2606.25763
- arXiv HTML: https://arxiv.org/html/2606.25763v1
- arXiv PDF: https://arxiv.org/pdf/2606.25763v1
- Official project page: https://lijayutnt.github.io/ShutterMuse/
- GitHub repository: https://github.com/lijayuTnT/ShutterMuse
- Hugging Face model: https://huggingface.co/ShutterMuse/ShutterMuse
- CaptureGuide-Bench dataset: https://huggingface.co/datasets/ShutterMuse/CaptureGuide-Bench