작은 언어모델을 툴 에이전트로 쓰고 싶은 이유는 분명하다.
비용이 낮고, 지연 시간이 짧고, 기업 내부나 로컬 환경에 배포하기 쉽다.
하지만 실제 MCP-style 툴 사용은 단순히 “함수 이름과 JSON 인자를 맞히는 문제”가 아니다.
에이전트는 현재 노출된 도구 catalog를 찾고, schema를 만족하는 인자를 채우고, 중간 결과를 다음 호출에 연결하며, 최종 답변을 실제 실행 결과에 근거시켜야 한다.
Evoflux: Inference-Time Evolution of Executable Tool Workflows for Compact Agents는 이 실패 모드를 작은 모델의 지식 부족보다 실행 가능한 workflow repair 문제로 해석한다.
작은 planner가 처음부터 완벽한 graph를 한 번에 내도록 학습시키기보다, 실행 중에 여러 candidate workflow를 만들고, 실패 증거를 바탕으로 수정하고, 점수가 좋은 후보를 남기는 방식이다.
흥미로운 지점은 이 논문이 SFT나 DPO를 배제하지 않는다는 것이다.
오히려 같은 search-mined trace를 SFT와 SFT+DPO 학습 데이터로도 써 보고, held-out MCP-Bench에서 비교한다.
결론은 꽤 날카롭다.
수백 개 수준의 teacher trace만 있을 때는, 그 trace를 weight update로 밀어 넣는 것보다 실제 task와 tool catalog 위에서 inference-time repair를 돌리는 편이 더 안정적이었다.
무엇을 해결하려는가
MCP는 모델이 외부 서버의 도구를 발견하고 호출하는 인터페이스를 표준화한다.
그래서 MCP-Bench 같은 벤치마크는 단일 API 호출보다 긴 horizon을 테스트한다.
논문은 MCP-Bench가 28개 live MCP server와 250개 tool을 포함하고, finance, travel, scientific computing, academic search 등 여러 domain에 걸친다고 설명한다.
여기서는 user query가 명시적으로 tool name을 주지 않는 경우가 많고, fuzzy tool discovery, parameter grounding, multi-hop execution, cross-domain orchestration이 함께 필요하다.
이 환경에서 작은 planner는 자주 그럴듯한 graph를 낸다.
문제는 그 graph가 실행되지 않는다는 점이다.
도구 이름이 catalog에 없거나, 필수 인자가 빠졌거나, 앞 단계 output을 뒤 단계 인자에 제대로 연결하지 못하거나, 실행 결과 없이 모델의 사전지식으로 final answer를 만들어 버릴 수 있다.
텍스트만 보면 plausible하지만, tool resolution과 schema validation을 통과하지 못하는 workflow가 된다.
기존 대응은 stronger agent의 trace를 작은 모델에 distill하는 것이다.
하지만 논문은 몇 가지 규모 차이를 짚는다.
ToolLLM은 약 12,000개, xLAM은 약 60,000개, Agent-FLAN은 약 34,000개 trajectory를 쓰는 반면, live tool execution과 judge evaluation이 들어가는 MCP-style 환경에서 그런 규모의 teacher trace를 만들기는 쉽지 않다.
수백 개 trace는 workflow format과 자주 보이는 action pattern을 가르칠 수는 있어도, 실패한 plan을 고치는 recovery behavior까지 충분히 덮지 못할 수 있다.
그래서 Evoflux의 질문은 단순하다.
같은 작은 planner와 같은 search-mined supervision budget이 있다면, compute를 학습에 쓸 것인가, 아니면 실행 중 repair에 쓸 것인가.
핵심 아이디어 / 구조 / 동작 방식
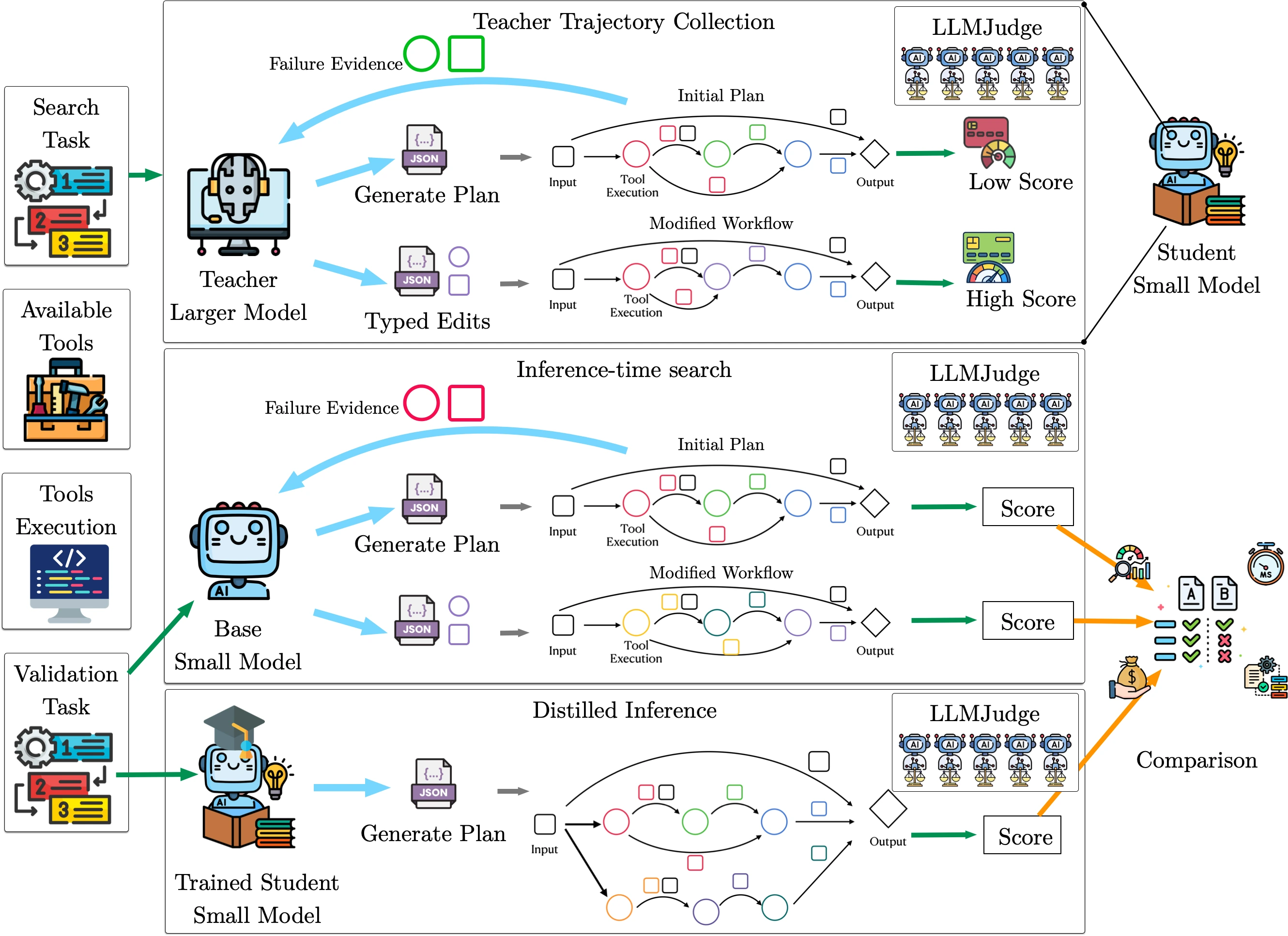
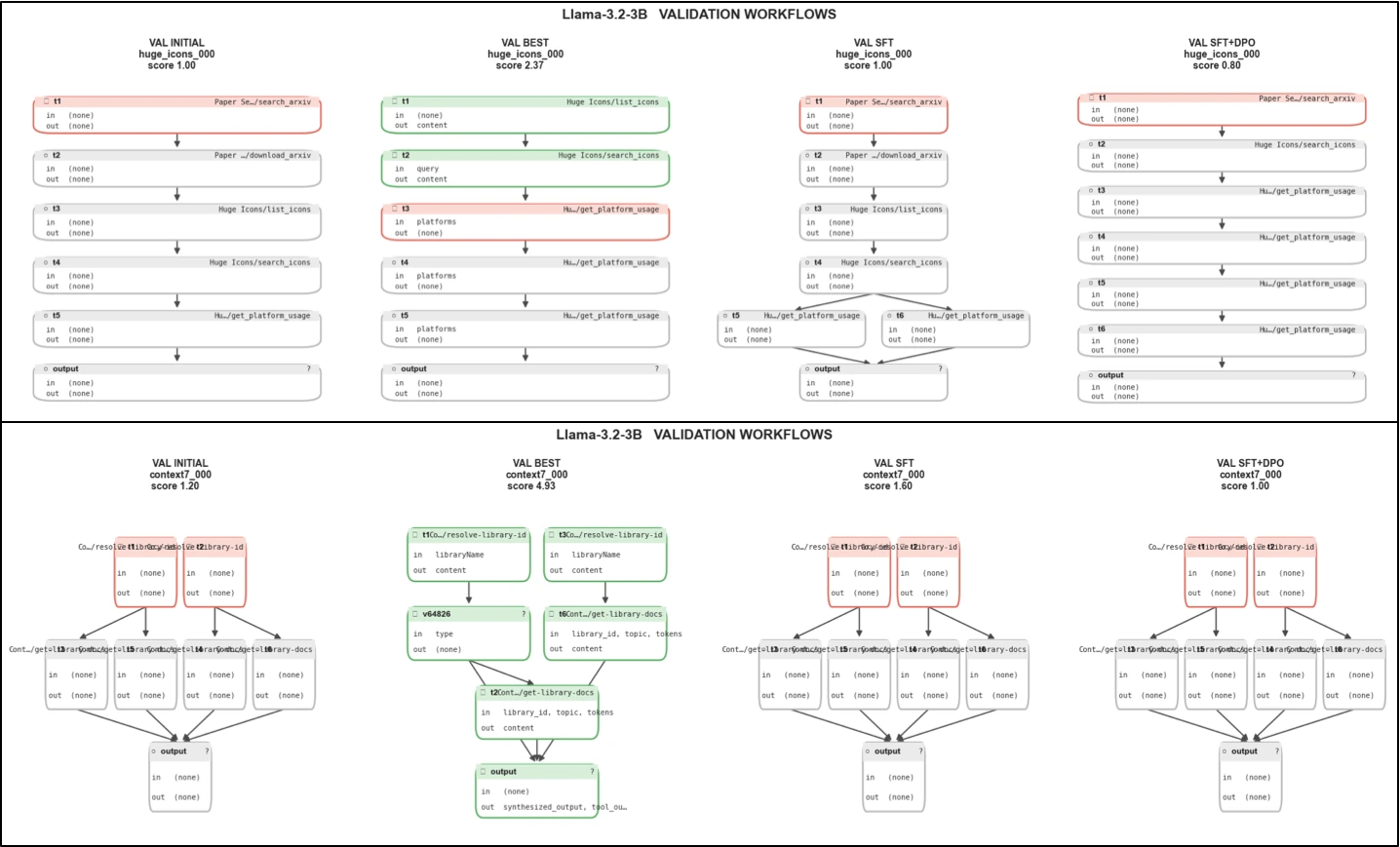
Evoflux는 plan을 typed workflow graph로 표현한다. graph에는 tool node, dependency edge, optional validator node, terminal output node가 들어간다.
각 tool node는 server identifier, tool name, input parameter assignment, upstream parent outputs를 갖는다.
즉 “어떤 도구를 어떤 인자로 부르고, 어떤 결과를 어디에 연결하는가”를 graph 자체가 명시한다.
검색 루프는 대략 다음 흐름이다.
| 단계 | 역할 | 실무적 의미 |
|---|---|---|
| 초기 후보 생성 | planner가 symbolic workflow를 제안하고 compile/validate/execute한다 | 작은 모델의 one-shot plan을 출발점으로 삼되 실패 원인을 기록한다 |
| typed mutation | tool swap, parameter edit, tool insertion/removal, step reordering, validator insertion 등을 적용한다 | 무제한 재작성 대신 MCP 실패 모드에 맞춘 안전한 edit space를 둔다 |
| execution scoring | MCP-Bench LLMJudge가 task fulfillment, grounding, tool appropriateness, parameter accuracy, dependency awareness, efficiency를 평가한다 | syntax가 아니라 실제 실행 trace와 final response를 기준으로 후보를 고른다 |
| adaptive intensity | 최근 개선이 작으면 exploration과 meta guidance를 늘리고, 개선이 있으면 좋은 후보 주변을 exploit한다 | 고정 budget 안에서 막힌 graph를 더 과감히 바꾼다 |
| diversity pruning | action-hash bucket으로 비슷한 workflow만 남는 collapse를 줄인다 | 같은 실패 pattern을 반복하지 않도록 population diversity를 유지한다 |
중요한 것은 작은 모델이 solver 전체가 아니라 proposal operator가 된다는 점이다. planner는 후보 graph와 edit를 제안하지만, 후보가 살아남을지는 compile, schema check, execution, judge score가 결정한다.
이 구조는 작은 모델이 “맞는 답을 바로 생성”해야 하는 부담을 줄이고, 대신 실행 환경에서 나온 evidence를 다음 mutation context로 돌려준다.
학습 baseline도 같은 search history를 쓴다. search 과정에서 나온 성공 trace, hard negative, preference pair를 SFT와 DPO용 데이터로 만든다.
따라서 비교는 공정하다.
“Evoflux만 더 좋은 데이터를 봤다”가 아니라, 같은 trace를 weights에 넣었을 때와 inference-time repair에 썼을 때를 비교한다.
공개된 근거에서 확인되는 점
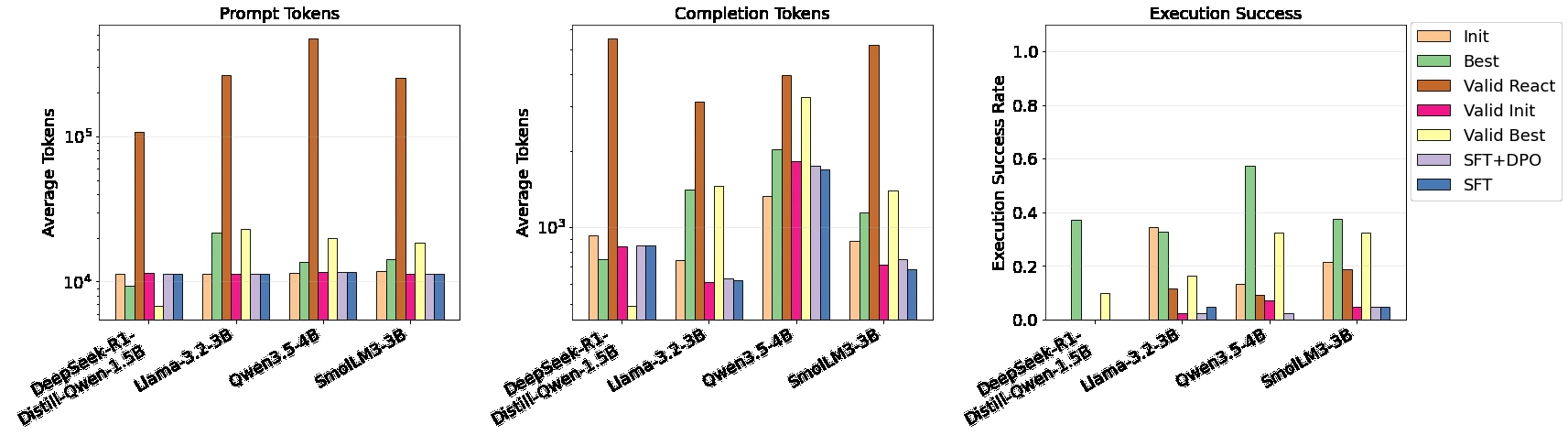
논문 abstract의 headline 결과는 held-out MCP-Bench에서 Evoflux가 작은 planner의 execution feasibility를 약 3%에서 17–24%로 올렸다는 것이다. validation section을 보면 Llama-3.2-3B는 Valid Init이 약 3% 수준으로 떨어지지만 Valid Best가 약 17%까지 회복된다.
Qwen3.5-4B도 held-out one-shot feasibility가 약 3%인 반면, Valid Best는 약 24%까지 오른다.
반대로 trained checkpoint 쪽은 기대보다 약하다.
Llama-3.2-3B의 SFT는 약 5% execution success, SFT+DPO는 약 3%로 Valid Init과 크게 다르지 않다.
Qwen3.5-4B의 SFT/SFT+DPO는 usable plan을 거의 내지 못해 heuristic fallback으로 떨어졌다고 논문은 설명한다.
즉 search가 만들어 낸 trace가 inference-time 후보로는 유용했지만, 작은 모델의 weight 안에 안정적인 repair policy로 내재화되지는 않았다.
Search split에서도 흥미로운 패턴이 있다.
Qwen3.5-4B는 initial score 1.44에서 best score 3.35로 올라 132% 상대 개선을 보인다. gemma-4-E2B는 90%, SmolLM3-3B는 74% 개선된다.
Sonnet-4-5도 4.94에서 6.26으로 좋아지지만 상대 개선은 27%다.
논문의 해석처럼 search는 이미 강한 모델보다, “약하지만 복구 가능한 구조를 내는 작은 planner”에서 더 큰 상대 이득을 낸다.
다만 모든 작은 모델이 좋은 frontier에 오르는 것은 아니다. token efficiency 분석에서 Nemotron-3-Nano-4B, granite-4.0-h-micro, Qwen3.5-4B가 작은 모델 쪽의 실용 frontier로 보이고, gemma-4-E2B처럼 더 많은 token을 쓰고도 비슷한 점수에 머무는 모델은 덜 매력적이다.
논문은 heuristic fallback token을 planner token total에 넣지 않았다고 밝히기 때문에, 이 token frontier는 full-system cost라기보다 planner cost로 읽어야 한다.
| 비교 축 | 논문에서 확인되는 결과 | 해석 |
|---|---|---|
| Held-out feasibility | Valid Init 약 3% → Evoflux Valid Best 약 17–24% | 실행 환경 위에서 고치는 search가 one-shot compact planner를 크게 보완한다 |
| SFT / SFT+DPO | Llama-3.2-3B는 3–5% 수준, Qwen3.5-4B는 usable plan collapse | 작은 trace budget에서는 workflow format 학습이 repair behavior 학습으로 이어지지 않는다 |
| ReAct | 강한 planner에서 높은 peak 가능, 대신 variance와 token cost 증가 | 긴 trajectory를 유지할 능력이 있는 모델에만 안정적으로 맞는다 |
| Code release | IBM/Evoflux public Python repo, Apache-2.0, toy benchmark smoke test와 MCP-Bench run script 제공 | 연구 재현을 위한 코드 surface는 있지만, 확인 시점 기준 tags/releases는 비어 있는 초기 release 형태다 |
공개 repository도 논문 해석에 도움이 된다.
IBM/Evoflux README는 scripts.run_pipeline을 통해 toy benchmark로 search+validation smoke test를 돌릴 수 있고, MCP-Bench를 clone한 뒤 single, 2server, 3server, all complexity로 search/validation pass를 실행하는 방법을 제공한다. run.sh는 planner와 judge용 vLLM server lifecycle을 다루며, MODEL_VERSION=sft 또는 MODEL_VERSION=sft+dpo로 fine-tuned checkpoint 평가를 분리한다.
즉 단순 PDF만 있는 아이디어가 아니라, 논문 실험 형태를 따라가려는 연구 코드가 공개되어 있다.
실무 관점에서의 해석
내가 보기에 Evoflux의 핵심 가치는 “진화 알고리즘을 에이전트에 붙였다”는 표면보다, 툴 에이전트의 실패를 text generation failure가 아니라 executable graph repair failure로 바꿔 본 것에 있다.
실제 운영에서 툴 호출은 토큰 몇 개가 아니라 작은 프로그램에 가깝다.
어떤 tool을 고르고, 어떤 인자를 채우고, 어떤 output을 다음 step에 연결할지 결정한다.
그렇다면 evaluation도 “답변이 그럴듯한가”보다 “이 graph가 compile되고 실행되고 evidence를 보존하는가”를 봐야 한다.
이 접근은 특히 compact agent를 써야 하는 환경에 잘 맞는다.
예를 들어 사내 MCP server, private API catalog, 로컬/온프레미스 배포, 낮은 latency/cost 제약이 있는 업무에서는 Sonnet급 planner를 매번 길게 굴리기 어렵다.
작은 모델이 초안을 내고, 실행 feedback으로 graph를 고치는 bounded search를 붙이면, 모델 크기만 키우는 것과 다른 축의 개선을 얻을 수 있다.
하지만 Evoflux도 공짜는 아니다.
첫째, 여러 candidate를 실행하고 judge를 돌리기 때문에 tool side effect와 비용 관리가 중요하다.
논문도 ethical considerations에서 permission checks, sandboxing, rate limits, audit logs, irreversible action safeguard를 강조한다.
실제 제품에서는 read-only/search 계열 tool과 destructive action tool을 분리하고, mutation 후보가 외부 상태를 바꾸기 전에 dry-run 또는 human approval layer를 둬야 한다.
둘째, MCP-Bench와 LLMJudge에 묶인 결과라는 한계가 있다.
논문은 wall-clock time, model calls, monetary cost, tokens per solved task 같은 배포 관점 숫자가 더 필요하다고 인정한다.
특히 ReAct와 Evoflux의 선택은 단순 accuracy 문제가 아니라 variance, token budget, side-effect risk, latency SLA의 tradeoff다.
셋째, 작은 trace budget에서 SFT/DPO가 약했다는 결과를 “distillation은 쓸모없다”로 읽으면 안 된다.
논문도 큰 데이터, 다른 negative construction, RL, trained checkpoint 위의 Evoflux 조합은 달라질 수 있다고 말한다.
더 정확한 해석은 이렇다.
수백 개 search trace만 있는 초기 단계에서는, trace를 곧바로 모델에 굳히기보다 runtime repair loop로 쓰는 편이 안전할 수 있다.
에이전트 시스템 설계 관점에서는 Reinforced Agent류의 pre-execution review, Subterranean Agent류의 workflow compilation, 그리고 Evoflux류의 execution-grounded search가 서로 다른 위치를 차지한다.
Reinforced Agent는 이미 나온 tool call을 실행 전에 검토한다.
Subterranean Agent는 안정적인 절차를 weights에 컴파일한다.
Evoflux는 작은 planner의 불완전한 workflow를 실행 중에 고친다.
공통점은 모두 “에이전트 성능은 모델 단독이 아니라 runtime harness와 execution boundary에서 결정된다”는 방향으로 수렴한다는 점이다.
결국 Evoflux는 작은 툴 에이전트를 더 똑똑하게 “학습”시키는 논문이라기보다, 작은 모델이 낸 workflow를 실제 도구 환경 위에서 더 안전하게 “진화”시키는 논문에 가깝다.
MCP-style tool universe가 커질수록 이 관점은 중요해진다.
도구가 많아지고 schema가 자주 바뀌고 중간 output dependency가 늘어나면, 정답은 한 번에 생성되는 문장이 아니라 검증되고 복구되는 실행 graph가 된다.