월드 모델이라는 말은 쉽게 쓰이지만, 실제로 1분 길이의 장면을 720p로 유지하면서 카메라 궤적까지 정밀하게 따라가게 만드는 일은 여전히 어렵다.
일반적인 비디오 생성 모델은 짧은 클립에서는 그럴듯해도, 시간이 길어질수록 공간 구조가 흐트러지고, 이전 위치로 돌아왔을 때 같은 장면이 다시 보여야 하는 revisit memory가 약해진다.
여기에 6-DoF 카메라 제어까지 붙이면 문제는 단순한 비디오 품질이 아니라 장면의 3D 일관성, 장기 문맥, 추론 비용이 동시에 얽힌다.
NVIDIA가 공개한 SANA-WM은 이 병목을 “더 큰 비디오 모델”이 아니라 효율적인 1분 월드 모델이라는 방향으로 푼다.
논문과 프로젝트 페이지 기준으로 SANA-WM은 2.6B 파라미터의 공개 world model이며, 한 장의 이미지와 카메라 trajectory를 입력받아 720p, 60초 길이의 controllable video를 생성한다.
핵심은 Hybrid Linear Attention, dual-branch camera control, two-stage long-video refiner, 그리고 public video에서 metric-scale 6-DoF pose를 뽑아내는 annotation pipeline이다.
흥미로운 점은 이 릴리스가 성능표만 내세우지 않는다는 것이다.
논문 초록은 약 213K public video clip, 64 H100에서 15일 학습, 단일 GPU 추론, 그리고 RTX 5090 + NVFP4 수준의 배포 가능성을 함께 강조한다.
Hugging Face에는 Efficient-Large-Model/SANA-WM_bidirectional 체크포인트도 올라와 있다.
즉 SANA-WM은 “시각적으로 멋진 60초 데모”보다, 긴 월드 생성의 비용 구조를 공개 모델 체급으로 낮추려는 시스템 설계로 읽는 편이 더 정확하다.

무엇을 해결하려는가
SANA-WM이 겨냥하는 문제는 video generation과 embodied AI 사이의 빈 공간이다.
로봇, 자율주행, 게임 시뮬레이션, 3D scene understanding에서 필요한 비디오는 단순히 “그럴듯하게 움직이는 영상”이 아니다.
사용자가 지정한 카메라 경로를 따라가야 하고, 같은 지점으로 돌아오면 이전 장면과 맞아야 하며, 60초 이상 길어져도 물체·배경·공간 구조가 급격히 붕괴하지 않아야 한다.
기존 공개 비디오 모델은 대개 짧은 클립이나 text-to-video 품질에 집중했다.
월드 모델 계열의 일부 baseline은 긴 trajectory를 다루지만, 480p 해상도, 다중 GPU 추론, 높은 메모리 사용량, 느린 throughput이 실무 병목으로 남는다.
논문 Table 2에서 비교되는 LingBot-World, HY-WorldPlay, Matrix-Game 3.0 같은 모델들이 바로 이 맥락이다.
SANA-WM의 목표는 이들과 비슷한 혹은 더 나은 action-following과 시각 품질을 내면서, 훈련·추론·배포 비용을 크게 줄이는 것이다.
여기서 중요한 것은 “카메라 제어”의 정의다.
단순히 좌우로 흔들리는 prompt를 넣는 것이 아니라, metric-scale 6-DoF pose trajectory를 조건으로 넣고, 생성된 비디오에서 다시 복원한 카메라 경로가 실제 입력 경로와 얼마나 맞는지를 평가한다.
따라서 SANA-WM의 성능 주장은 일반적인 VBench 점수만이 아니라 rotation error, translation error, camera-motion consistency 같은 trajectory-following 지표와 함께 봐야 한다.
핵심 아이디어 / 구조 / 동작 방식
SANA-WM의 구조는 기존 SANA 계열 diffusion transformer를 긴 비디오 월드 모델로 확장한 형태다.
가장 눈에 띄는 구성은 Hybrid Linear Attention이다.
프레임 단위의 Gated DeltaNet(GDN) 계열 recurrent/linear attention을 사용해 긴 sequence의 메모리 비용을 낮추고, 중간에 softmax attention block을 섞어 전역 정보 혼합을 보완한다.
논문은 이 조합을 GDN + softmax 형태로 설명하며, 긴 context를 완전히 softmax attention으로 처리할 때의 메모리 폭증을 피하려는 설계로 제시한다.
두 번째 축은 dual-branch camera control이다.
SANA-WM은 카메라 pose를 단순한 auxiliary token으로만 넣지 않는다.
그림의 구조를 보면 pose token, reference image token, latent token, text token이 함께 들어가고, UCPE attention과 Plücker mixing 같은 geometry-aware component가 attention block 안에 들어간다.
즉 coarse global pose 조건과 pixel-aligned geometric signal을 함께 써서 “대략 앞으로 가라”가 아니라 “이 6-DoF trajectory를 따라가라”에 가깝게 조건을 넣는 구조다.
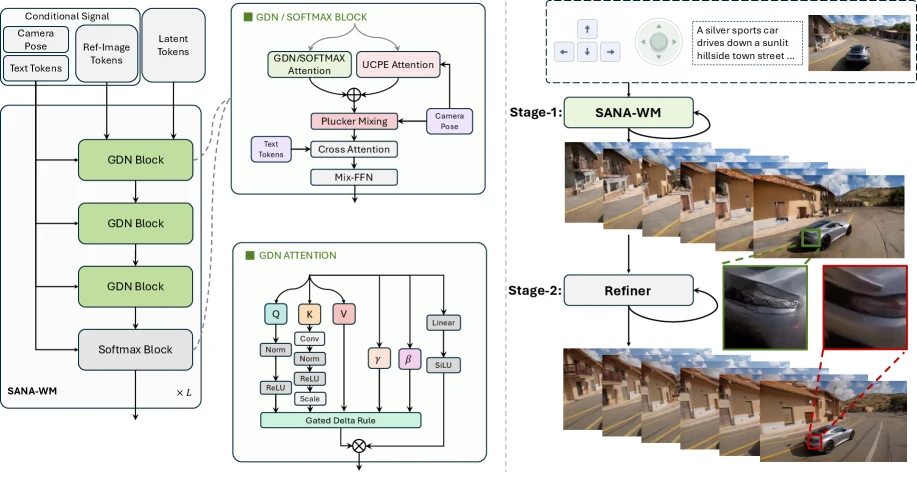
세 번째 축은 two-stage generation pipeline이다.
Stage 1의 SANA-WM이 긴 rollout의 기본 latent video를 만들고, Stage 2의 long-video refiner가 texture, object structure, temporal consistency를 보강한다.
Hugging Face 모델 카드 기준 공개 repo에는 Stage 1 DiT, LTX-2 VAE, Stage 2 refiner, refiner용 Gemma text encoder가 나뉘어 들어 있다.
이 구조는 SANA-WM을 하나의 작은 모델 파일로만 보면 놓치기 쉽다.
핵심 backbone은 2.6B지만, 실제 고품질 decode path는 refiner와 text encoder까지 포함한 multi-component bundle이다.
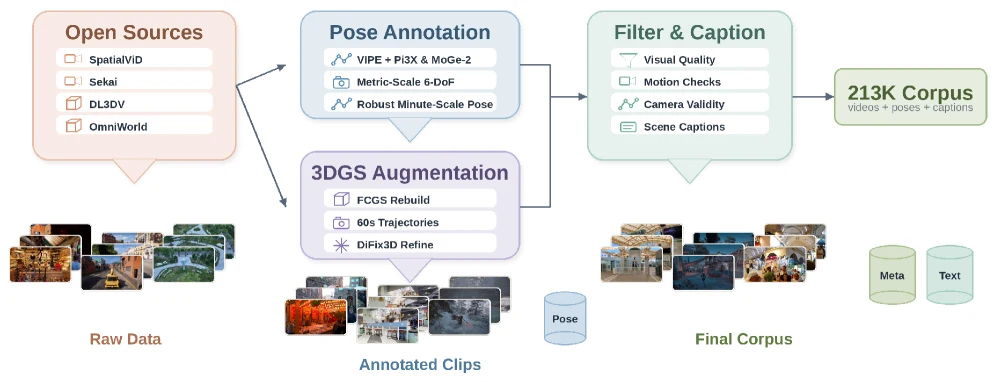
네 번째 축은 데이터다.
SANA-WM은 proprietary action-labeled video에 의존하는 대신, public video와 static 3D source에서 metric-scale pose annotation을 복원한다.
논문 Figure 3과 Table 1은 SpatialVID-HQ, DL3DV, OmniWorld, Sekai, MiraData 등을 모아 VIPE, Pi3X, MoGe-2, 3DGS augmentation, quality filtering, scene captioning을 거쳐 총 212,975개 clip 규모의 학습 corpus를 만든다고 설명한다.
이는 SANA-WM의 성과가 모델 구조만이 아니라 “카메라 pose가 붙은 public video corpus를 어떻게 만들 것인가”의 문제라는 뜻이다.
| 구성 축 | 공개 자료에서 확인되는 내용 | 실무적 의미 |
|---|---|---|
| Backbone | 2.6B SANA-WM diffusion transformer | 60초 720p 생성을 frontier급 거대 모델이 아닌 공개 체급으로 낮추려는 설계 |
| Attention | frame-wise GDN + periodic softmax | 긴 비디오 context에서 softmax-only 메모리 폭증을 피함 |
| Camera control | 6-DoF pose, UCPE attention, Plücker mixing | 단순 prompt motion이 아니라 metric camera trajectory following을 목표로 함 |
| Refiner | LTX-2 기반 long-video refiner | Stage 1 rollout의 texture와 후반부 품질 저하를 보강 |
| Data pipeline | public videos + pose/depth estimators + 3DGS augmentation | proprietary simulator 없이 camera-supervised corpus를 구성하려는 접근 |
| Benchmark | 80 first-frame scenes, Simple/Hard 60s revisit trajectories | 긴 월드 생성에서 action following과 revisit consistency를 함께 평가 |
공개된 근거에서 확인되는 점
정량 결과에서 SANA-WM의 가장 강한 메시지는 action-following과 throughput이다.
논문 Table 2 기준 Hard-Trajectory split에서 SANA-WM + refiner는 rotation error 8.34°, translation error 1.39, CMC 1.44를 기록한다.
같은 표의 LingBot-World는 rotation error 18.99°, HY-WorldPlay는 35.46°, Matrix-Game 3.0은 18.79°다.
즉 SANA-WM은 저자들이 구성한 60초 benchmark 안에서는 camera trajectory를 훨씬 더 잘 따라가는 쪽으로 제시된다.
시각 품질은 더 미묘하게 봐야 한다.
Hard split에서 SANA-WM + refiner의 VBench Overall은 81.89로 LingBot-World와 같은 수준이며, Matrix-Game 3.0의 78.79, HY-WorldPlay의 70.46보다는 높다.
Simple split에서는 SANA-WM + refiner가 80.62, LingBot-World가 81.82로 LingBot 쪽이 약간 높다.
따라서 이 결과를 “모든 시각 지표에서 압도”로 읽기보다는, 비슷한 visual-quality band를 훨씬 낮은 추론 비용과 더 나은 pose accuracy로 달성했다고 보는 편이 맞다.
효율성 차이는 훨씬 선명하다.
Table 2에서 SANA-WM + refiner의 throughput은 8 H100 기준 22.0 videos/hour로, LingBot-World의 0.6 videos/hour 대비 약 36.7배다. peak memory도 SANA-WM + refiner가 74.7GB, LingBot-World가 454.1GB로 표시된다.
Stage 1 SANA-WM만 보면 throughput은 24.1 videos/hour, memory는 51.1GB다.
이런 숫자는 SANA-WM이 “품질 최고점”보다 “long-horizon world model의 비용 재설계”에 가까운 릴리스라는 점을 잘 보여준다.
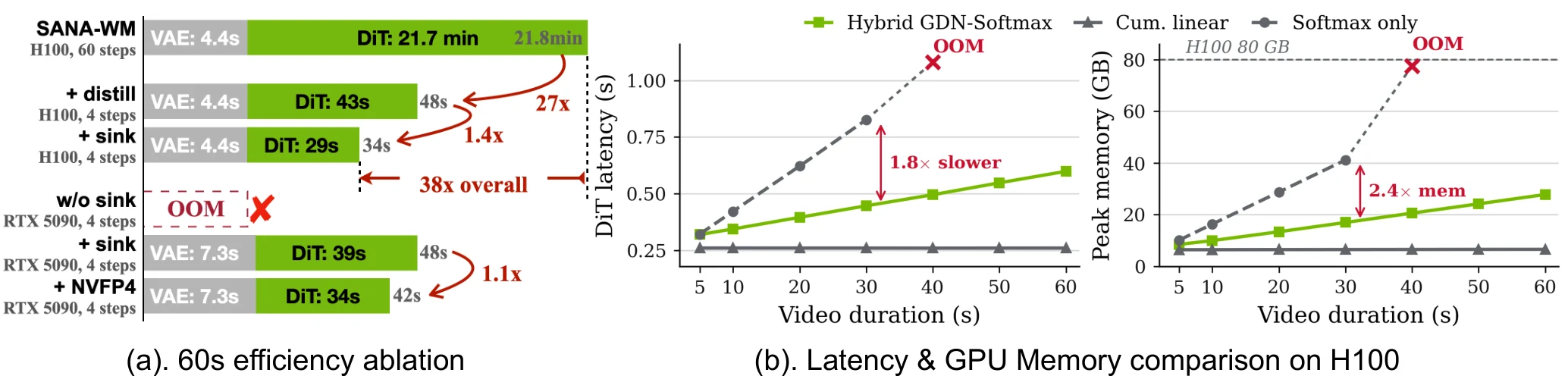
프로젝트 페이지의 efficiency figure도 같은 메시지를 보강한다.
60초 clip 기준 full H100 denoising path는 21.8분 규모로 표시되지만, distillation과 sink path를 적용하면 H100 4-step 기준 34초까지 내려간다.
RTX 5090 + NVFP4 경로도 수십 초 단위로 제시된다.
다만 논문 초록은 RTX 5090 + NVFP4에서 60초 720p clip denoising 34초를 언급하고, 프로젝트 figure는 H100 sink 34초와 RTX 5090 + NVFP4 42초 구성을 함께 보여준다.
표면별 숫자가 약간 다르게 노출되는 만큼, 안전하게 해석하면 “single GPU에서 60초 720p denoising을 수십 초 단위로 끌어내리려는 경로가 공식 자료에 제시되어 있다” 정도가 적절하다.
Ablation도 구조적 해석을 뒷받침한다.
Progressive-training ablation에서 Sana-Video baseline은 VBench-I2V Total 0.8378, memory 8.90GiB, latency 1266.6ms로 표시된다.
LTX2 VAE를 붙이면 Total은 0.8390으로 조금 오르고 memory와 latency는 5.40GiB / 371.7ms로 크게 줄어든다.
여기에 Hybrid attention을 더하면 Total은 0.8530으로 올라가지만 latency는 433.2ms로 약간 늘어난다.
즉 SANA-WM의 효율성은 단일 trick이 아니라 tokenizer/VAE 교체, attention 구조, progressive training이 함께 만든 결과로 보인다.
Refiner도 단순 후처리 필터가 아니다.
Table 5에서 original LTX-2.3 refiner는 Simple split IQ가 38.16, Hard split IQ가 37.17로 낮고 dynamic degree가 0으로 표시된다.
반면 SANA-WM의 long-video refiner는 Simple IQ 72.12, Hard IQ 71.38까지 끌어올리고, Overall도 각각 80.62 / 81.89로 높인다.
다만 refiner를 붙이면 memory는 51.1GB에서 74.7GB로 늘고 throughput은 24.1에서 22.0 videos/hour로 조금 낮아진다.
품질 보강과 비용 증가 사이의 명확한 tradeoff가 있다.

공개 패키징을 보면 릴리스는 꽤 적극적이지만 아직 정리 중인 면도 있다.
Hugging Face 모델 repo Efficient-Large-Model/SANA-WM_bidirectional은 API 기준 2026-05-18 생성, ungated, Apache-2.0 tag, image-to-video pipeline으로 표시된다. sibling file에는 dit/sana_wm_1600m_720p.safetensors, vae/, refiner/refiner.safetensors, refiner/text_encoder/ 등이 포함되고, used storage는 약 105GB로 표시된다.
모델 카드의 구성표는 Stage 1 DiT 약 10GB, VAE 약 2GB, refiner 약 41GB, refiner text encoder 약 46GB로 나눠 설명한다.
반면 GitHub 쪽은 조심해서 봐야 한다.NVlabs/Sana repository는 이미 성숙한 SANA 계열 repo이고, API 기준 Apache-2.0 라이선스, 수천 개 star, v1.5.0 release와 v1.0.0 tag를 갖고 있다.
하지만 inspection 시점의 main branch tree에는 Hugging Face 모델 카드가 예시로 든 inference_video_scripts/inference_sana_wm.py가 보이지 않았고, root README도 SANA-WM을 news와 project link 중심으로만 언급한다.
즉 checkpoint와 논문, 프로젝트 페이지는 공개되어 있지만, SANA-WM 전용 inference code surface는 아직 문서와 repository가 완전히 맞물린 상태라고 단정하기 어렵다.
라이선스도 실무적으로 중요한 부분이다.
모델 repo는 Apache-2.0 tag를 달고 있지만, 논문 Appendix G는 학습·annotation·refiner 주변 asset의 terms가 섞여 있음을 별도로 정리한다.
SpatialVID-HQ, OmniWorld 같은 데이터는 CC-BY-NC-SA 계열 조건이 있고, DL3DV는 custom project terms, LTX-2는 community license, 일부 도구와 데이터는 non-commercial 혹은 프로젝트별 조건을 확인해야 한다.
따라서 “SANA-WM 모델 파일이 Apache-2.0 tag를 가진다”와 “전체 학습 recipe를 상업적으로 그대로 재현할 수 있다”는 서로 다른 명제다.
실무 관점에서의 해석
SANA-WM의 진짜 의미는 긴 비디오를 만든다는 사실 자체보다, 월드 모델을 평가하고 배포하는 단위를 바꾼다는 데 있다.
일반적인 video generation demo는 몇 초짜리 sample을 보고 품질을 판단한다.
SANA-WM은 여기에 60초 trajectory, revisit pair, pose reconstruction, GPU memory, videos/hour를 함께 놓는다.
이 프레임에서는 “보기 좋은가”보다 “카메라 제어를 지키는가, 다시 돌아왔을 때 기억하는가, 단일 GPU로 돌릴 수 있는가”가 더 중요해진다.
이 관점은 embodied AI에 꽤 중요하다.
로봇이나 자율주행에서 필요한 시뮬레이션은 현실을 완벽히 예측하는 oracle이 아니라, 다양한 장면에서 action-conditioned rollout을 빠르게 만들어 downstream policy나 planner가 실험할 수 있는 환경이다.
SANA-WM은 아직 물리 시뮬레이터라기보다 camera-conditioned generative world model에 가깝지만, pose-supervised public video corpus와 60초 revisit benchmark를 묶은 점은 향후 embodied data generation의 한 방향을 보여준다.

동시에 한계도 분명하다.
첫째, benchmark는 80개의 Nano Banana Pro first-frame scene과 저자들이 설계한 Simple/Hard trajectory에 기반한다.
이 benchmark는 긴 월드 생성의 난점을 잘 드러내지만, 실제 로봇 환경이나 자율주행 로그 전체를 대체하는 검증은 아니다.
둘째, 모델 bundle은 “2.6B”라는 숫자만 보고 가볍다고 생각하기에는 크다. refiner와 text encoder까지 포함하면 HF storage가 100GB를 넘고, 고품질 path는 여전히 고성능 GPU를 전제한다.
셋째, release maturity는 체크포인트 공개와 code integration을 분리해서 봐야 한다.
SANA 계열 repo는 충분히 공개되어 있지만, SANA-WM 전용 스크립트와 문서가 inspection 시점에 완전히 정리되어 있지는 않았다.
빠르게 움직이는 연구 릴리스에서는 흔한 상태지만, 바로 production pipeline에 넣으려는 팀은 GitHub branch, model card, project page가 서로 어느 정도 동기화되었는지 다시 확인해야 한다.
넷째, “world model”이라는 이름이 실제 세계의 물리 법칙을 안정적으로 예측한다는 뜻은 아니다.
논문 자체도 broader impact에서 생성 비디오를 실제 관찰로 오해하거나 safety-critical planning에 과신하는 위험을 언급한다.
SANA-WM은 장면 일관성과 카메라 제어를 향상시킨 생성 모델이지, 검증된 물리 시뮬레이터나 정책 안전성 평가기를 대체하는 도구는 아니다.
그럼에도 SANA-WM은 중요한 기준선을 세운다.
오픈 월드 모델 경쟁은 앞으로 단순히 몇 초짜리 데모 품질을 겨루는 쪽에서, 긴 rollout, controllable camera, revisit memory, GPU throughput, checkpoint packaging까지 함께 묻는 쪽으로 갈 가능성이 크다.
SANA-WM의 강점은 바로 이 질문들을 하나의 공개 artifact로 묶었다는 점이다.
1분짜리 720p 월드를 하나의 이미지와 카메라 trajectory에서 만들고, 그 비용을 단일 GPU 배포 표면까지 끌어내리려는 시도 자체가 앞으로의 video foundation model 릴리스가 맞춰야 할 새로운 기준이 되고 있다.