거대 MoE 모델을 줄이는 일은 이제 단순한 “파라미터 다이어트”가 아니다.
Dense 모델에서는 width나 layer를 잘라낸 뒤 distillation을 붙이는 접근이 비교적 익숙하지만, MoE에서는 문제가 더 복잡하다.
어떤 layer를 줄일지, hidden dimension을 얼마나 줄일지, 수백 개 expert를 pruning할지 merging할지, 그리고 그 상태에서 계속 학습할 때 어떤 loss를 섞을지까지 모두 성능 회복에 영향을 준다.
SlimQwen: Exploring the Pruning and Distillation in Large MoE Model Pre-training은 이 문제를 Qwen3-Next 계열 MoE에서 꽤 체계적으로 실험한다.
논문은 Qwen3-Next-80A3B를 teacher로 두고, 이를 23A2B 모델로 줄이는 과정에서 구조적 pruning과 지식 증류를 “사후 압축 트릭”이 아니라 pretraining-scale continual training recipe로 다룬다.
핵심 메시지는 명확하다.
같은 target architecture라도 처음부터 새로 학습하는 것보다 pretrained MoE를 잘라서 시작하는 편이 훨씬 낫고, 한 번에 거칠게 줄이는 것보다 단계적으로 구조를 바꾸는 편이 더 안정적이라는 것이다.
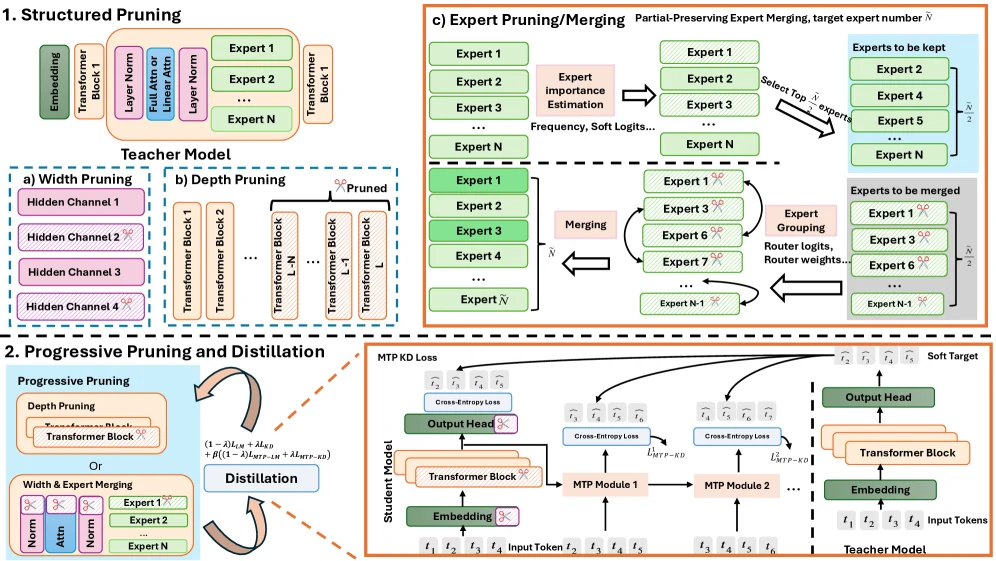
흥미로운 점은 SlimQwen이 단일 기법 논문이라기보다 “MoE 압축에서 실제로 무엇이 중요한가”를 묻는 실험 보고서에 가깝다는 점이다.
저자들은 depth pruning, width pruning, expert pruning/merging, KD와 LM loss의 조합, multi-token prediction distillation, progressive pruning schedule을 한 묶음으로 검증한다.
따라서 이 논문은 “23B급 Qwen 모델 하나를 만들었다”보다, 큰 sparse model을 작은 sparse model로 이전할 때의 작업 순서와 손실 함수 설계를 보여 주는 자료로 읽는 편이 더 유용하다.
무엇을 해결하려는가
MoE 압축의 어려움은 압축 축이 하나가 아니라는 데 있다.
Qwen3-Next-80A3B 같은 모델은 총 파라미터는 크지만 토큰당 활성화되는 파라미터는 제한된다.
그래서 단순히 total parameter만 보고 줄이면 실제 inference 비용, 메모리 footprint, expert specialization, router 동작을 동시에 설명하기 어렵다.
논문이 다루는 질문은 크게 세 가지다.
- Pruned initialization이 scratch training보다 나은가? 같은 target architecture와 같은 training budget에서 pretrained teacher를 잘라 시작하는 것이 정말 이득인지 검증한다.
- Expert compression은 어떻게 해야 하는가? router score, routing frequency, expert activation, REAP류 기준 등 여러 expert pruning/merging 방법이 continual pretraining 뒤에도 큰 차이를 만드는지 본다.
- 압축 뒤 계속 학습할 때 어떤 recipe가 좋은가? KD만 쓸지, LM loss를 섞을지, MTP distillation을 넣을지, 한 번에 줄일지 단계적으로 줄일지 비교한다.
이 질문이 중요한 이유는 실무적으로 명확하다.
이미 비싼 비용으로 학습된 frontier급 MoE가 있을 때, 작은 serving variant를 만들고 싶다면 scratch pretraining을 다시 하는 것은 거의 항상 비싸다.
하지만 무작정 pruning만 하면 성능이 무너질 수 있다.
SlimQwen은 이 사이에서 **“얼마나 잘라낼 것인가”보다 “어떤 궤적으로 작게 만들 것인가”**를 중심 질문으로 세운다.
핵심 아이디어 / 구조 / 동작 방식
SlimQwen의 base teacher는 80A3B hybrid MoE 모델이다.
논문 기준 이 모델은 48개 transformer block을 갖고, 그 안에 12개 full attention layer와 36개 linear attention layer가 섞여 있다.
MoE layer는 모듈당 512개 expert를 두며, 토큰마다 routed expert 10개와 shared expert 1개가 활성화된다.
Target인 SlimQwen-23A2B는 여러 축을 동시에 줄인다.
Depth에서는 transformer block 12개를 제거하고, width에서는 hidden size를 2048에서 1536으로 줄인다.
Expert 쪽에서는 모듈당 expert 수를 512개에서 256개로 줄이고, 토큰당 routed expert도 10개에서 8개로 줄인다.
결과적으로 총 파라미터는 80B에서 23B로 줄고, active parameter는 약 3.8B에서 2.0B로 줄어든다.
| 압축 축 | SlimQwen에서의 처리 | 실무적으로 읽히는 의미 |
|---|---|---|
| Depth pruning | 48개 block 중 12개 제거 | 단순히 hidden만 줄이지 않고 sequence of computation 자체를 줄임 |
| Width pruning | hidden size 2048 → 1536 | attention, MoE, normalization 전반의 표현 폭을 함께 축소 |
| Expert compression | 512 experts → 256 experts, top-10 → top-8 | MoE memory footprint와 routed capacity를 동시에 줄임 |
| Partial-preservation merging | target expert 절반은 그대로 보존, 나머지는 중요도/유사도 기반 merging | 핵심 expert specialization과 통합 효과 사이의 타협점 |
| Distillation objective | NTP KD, LM loss, MTP loss, MTP KD 조합 | teacher imitation만이 아니라 backbone 학습과 speculative decoding 품질까지 함께 고려 |
| Progressive pruning | 40B token 중간 학습 후 최종 구조로 추가 pruning, 이후 360B token 학습 | 모델 구조를 갑자기 바꾸기보다 최적화 궤적을 완만하게 전환 |
가장 눈에 띄는 설계는 partial-preservation expert merging이다.
모든 target expert를 aggressive merging으로 새로 만들면 기존 expert specialization이 지나치게 균질해질 수 있다.
반대로 중요도가 높은 expert만 보존하면 덜 두드러지지만 보완적인 expert 지식이 버려질 수 있다.
논문은 target expert의 절반은 중요도 기준으로 그대로 남기고, 나머지 절반은 버려질 expert를 유사한 base expert에 병합하는 절충안을 제안한다.
Distillation 쪽에서는 next-token prediction KD만 쓰지 않는다.
표준 LM loss를 함께 섞고, MTP module이 여러 future token을 예측하도록 distillation을 넣는다.
이 부분은 단순한 benchmark 성능보다도 speculative decoding 관점에서 의미가 있다.
MTP KD는 draft token이 verifier에게 더 오래 받아들여지도록 만들어, backbone 품질과 multi-token generation acceptance rate를 동시에 겨냥한다.
공개된 근거에서 확인되는 점
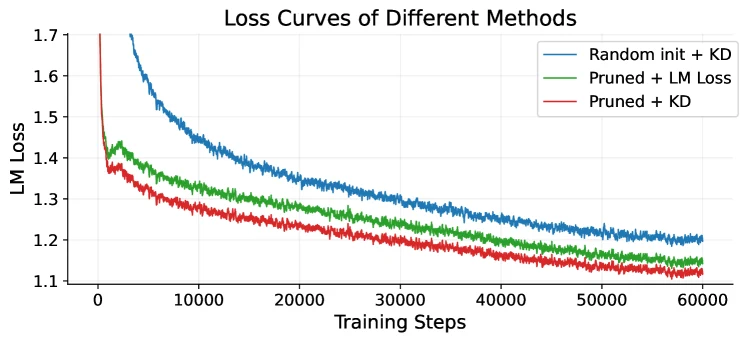
첫 번째 결과는 pruned initialization의 힘이다.
같은 23A2B target 구조를 120B token으로 학습할 때, random initialization에서 KD loss로 학습한 모델은 평균 61.66을 기록한다.
반면 Qwen3-Next teacher를 pruning해 초기화한 뒤 LM loss만 써도 평균 69.96이고, pruned initialization에 KD를 결합하면 평균 73.45까지 오른다.
| 방법 | MMLU | MMLU-Pro | GSM8K | EvalPlus | 평균 |
|---|---|---|---|---|---|
| Qwen3-Next-80A3B teacher | 85.22 | 62.86 | 90.07 | 74.12 | 82.68 |
| Random Init + KD Loss | 65.06 | 34.54 | 73.35 | 58.67 | 61.66 |
| Pruned + LM Loss | 72.76 | 48.24 | 81.84 | 67.05 | 69.96 |
| Pruned + KD Loss | 75.67 | 51.19 | 83.17 | 69.30 | 73.45 |
이 표에서 중요한 것은 KD 여부보다 initialization이다.
Random Init + KD와 Pruned + KD의 평균 차이는 11.79포인트다.
즉 teacher logits를 따라 하는 것만으로는 충분하지 않고, teacher에서 물려받은 구조적 weight가 compressed model의 출발점을 크게 바꾼다.
Expert compression 결과도 흥미롭다.
논문은 24A2B 모델을 6A1B로 줄이는 설정에서 여러 expert pruning/merging 기준을 비교한다.
Router weight, router logits, expert vector, routing frequency, soft logits, REAP류 지표를 바꿔도 continual pretraining 뒤에는 특정 한 방법이 모든 benchmark를 지배하지 않는다.
대신 partial-preservation을 넣은 expert merging은 MMLU, MMLU-Pro, GSM8K 같은 주요 benchmark에서 비교적 일관된 개선을 보인다.
Training objective 쪽에서는 KD만 단독으로 쓰는 것보다 LM loss를 함께 쓰는 편이 낫다.
Table 3 기준 NTP KD는 MMLU 74.16, MMLU-Pro 50.97인데, NTP KD + LM Loss는 각각 74.93, 51.44로 오른다.
여기에 MTP KD를 포함한 full objective는 MMLU 75.67, EvalPlus 69.30, CMMLU 80.95를 기록한다.
모든 항목에서 절대 최고는 아니지만, 전반적으로 가장 균형 잡힌 recipe에 가깝다.
Progressive pruning도 핵심 근거다.
같은 최종 23A2B 모델과 같은 400B training tokens를 쓰더라도, 한 번에 압축하는 one-stage보다 중간 구조를 거쳐 줄이는 schedule이 대체로 낫다.
| Pruning schedule | Tokens | MMLU | MMLU-Pro | MMLU-Redux | GSM8K | EvalPlus |
|---|---|---|---|---|---|---|
| One-stage | 400B | 75.86 | 52.97 | 75.41 | 85.22 | 70.07 |
| Joint | 40B + 360B | 76.30 | 53.12 | 76.93 | 86.05 | 70.58 |
| Width-first | 40B + 360B | 77.14 | 52.80 | 77.07 | 84.00 | 71.40 |
| Depth-first (SlimQwen) | 40B + 360B | 77.39 | 53.22 | 78.01 | 85.82 | 69.08 |
논문은 최종적으로 depth-first progressive model을 SlimQwen으로 지정한다.
MMLU는 one-stage 대비 1.53포인트, MMLU-Redux는 2.60포인트 높다.
다만 benchmark별로 보면 width-first가 EvalPlus에서 더 좋고, joint가 GSM8K에서 더 높다.
따라서 이 결과는 “depth-first가 모든 문제의 정답”이라기보다, 단계적 구조 전환이 one-shot 압축보다 낫다는 쪽이 더 강한 결론이다.
마지막으로 효율 수치도 실무적으로 볼 만하다.
Appendix Table 11 기준 peak memory는 Qwen3-Next-80A3B 156.56GB에서 SlimQwen-23A2B 43.30GB로 줄어든다.
HF backend에서는 prefill latency가 0.99초에서 0.44초로 줄고, decoding throughput은 4.05 tok/s에서 6.55 tok/s로 오른다. vLLM backend에서도 decoding throughput은 142.58 tok/s에서 210.87 tok/s로 증가한다.
| 모델 | Peak memory | HF prefill | HF decoding | vLLM prefill | vLLM decoding |
|---|---|---|---|---|---|
| Qwen3-Next-80A3B | 156.56GB | 0.99s | 4.05 tok/s | 0.08s | 142.58 tok/s |
| SlimQwen-23A2B | 43.30GB | 0.44s | 6.55 tok/s | 0.06s | 210.87 tok/s |
공개 release 관점에서는 아직 논문 중심이다. arXiv abstract와 HTML, Hugging Face Papers 페이지에서 확인되는 공식 companion code/model 링크는 보이지 않았고, SlimQwen 또는 2605.08738 기준 GitHub/Hugging Face 검색에서도 이 논문과 직접 연결되는 공식 저장소나 checkpoint는 확인되지 않았다.
따라서 현재 읽을 수 있는 핵심 근거는 paper/html의 실험 결과와 figure/table이며, 즉시 내려받아 재현할 수 있는 공개 모델 bundle로 보기는 어렵다.
실무 관점에서의 해석
SlimQwen의 가장 중요한 메시지는 “작은 MoE를 만들려면 큰 MoE를 잘라내면 된다”가 아니다.
오히려 반대다.
큰 MoE에서 작은 MoE로 가는 과정은 구조 변경, expert specialization 보존, teacher signal, language modeling signal, speculative decoding objective, training schedule이 얽힌 압축용 pretraining 문제라는 점을 보여 준다.
특히 pruned initialization 결과는 강하다.
같은 target architecture라도 scratch에서 KD를 붙인 모델보다 pretrained teacher를 구조적으로 잘라 시작한 모델이 훨씬 낫다.
이는 기업이나 연구팀이 이미 큰 MoE family를 갖고 있을 때, 작은 variant를 만들기 위해 완전히 별도 모델을 학습하기보다 family 내부에서 weight inheritance와 continual pretraining을 설계하는 전략이 비용 대비 효율적일 수 있음을 시사한다.
Partial-preservation expert merging도 실무적으로 좋은 감각을 준다.
MoE expert는 단순히 “중요한 것만 남기고 나머지는 버린다”로 다루기 어렵다.
중요도 높은 expert는 그대로 보존해야 하지만, 낮은 순위의 expert에도 보완 지식이 있을 수 있다.
SlimQwen의 절반 보존/절반 병합 전략은 이 균형을 단순한 heuristic으로 잡는다.
완벽한 이론은 아니지만, 대규모 continual pretraining 뒤에는 지나치게 정교한 one-shot expert selection보다 이런 robust한 보존 전략이 더 실용적일 수 있다.
또 하나의 포인트는 MTP KD다.
최근 Qwen3-Next류 모델에서 MTP는 단순 부가 head가 아니라 inference efficiency와 연결되는 구성 요소다.
SlimQwen은 compressed model의 benchmark를 복구하는 것뿐 아니라, speculative decoding에서 draft token acceptance를 높이는 방향으로도 distillation을 건다.
즉 작은 모델을 만드는 목표가 “정확도 유지”에 그치지 않고, 실제 serving path에서 더 빠르게 검증 가능한 token을 만들도록 학습하는 것까지 포함된다.
한계도 분명하다.
첫째, 이 논문은 Qwen3-Next 계열 내부 실험에 강하게 묶여 있다.
다른 MoE family, 다른 router 설계, 다른 data mixture에서도 같은 pruning 순서와 loss weight가 최적일지는 별도 검증이 필요하다.
둘째, 공개 코드나 checkpoint가 아직 뚜렷하지 않기 때문에 외부 팀이 즉시 같은 recipe를 재현하기는 어렵다.
셋째, benchmark별로 최선 schedule이 조금씩 다르므로, depth-first SlimQwen을 보편적 winner로 해석하기보다는 progressive compression의 한 강한 인스턴스로 보는 편이 안전하다.
그럼에도 SlimQwen은 꽤 실용적인 연구다.
MoE 압축을 parameter count만의 문제가 아니라 학습 궤적을 보존하면서 architecture를 전환하는 문제로 정리했기 때문이다.
앞으로 foundation model lab들이 하나의 거대 MoE에서 여러 크기의 serving model을 뽑아내는 일이 더 흔해진다면, SlimQwen류의 pruning-and-distillation recipe는 모델 family 운영의 기본 도구에 가까워질 가능성이 있다.