이미지 생성 모델의 다음 병목은 “더 예쁜 한 장”만이 아니다.
실무에서 자주 필요한 산출물은 발표 슬라이드, 정보 그래픽, 포스터, 제품 화면, 만화 컷, 캘린더처럼 텍스트와 레이아웃이 이미지 안에 함께 들어가는 결과물이다.
여기서는 글자 하나가 틀리거나 표 안의 정렬이 무너지면, 전체 결과가 바로 사용할 수 없는 초안이 된다.
Qwen-Image-2.0 Technical Report는 이 문제를 정면으로 잡는다.
논문은 Qwen-Image-2.0을 고품질 text-to-image 생성과 instruction-based image editing을 하나의 프레임워크에서 처리하는 omni-capable image generation foundation model로 설명한다.
공식 블로그와 README도 같은 방향을 강조한다.
1K 토큰 길이의 지시를 받아 PPT, poster, comic, infographic 같은 전문 텍스트 중심 이미지를 만들고, native 2K 해상도 포토리얼리즘과 생성·편집 통합을 함께 겨냥한다는 것이다.
이 글에서 중요한 해석은 “Qwen이 또 하나의 이미지 모델을 냈다”가 아니다.
Qwen-Image-2.0은 이미지 생성 모델이 문자 렌더링, 문서형 레이아웃, 멀티이미지 편집, 고해상도 사실감, 추론 효율을 한꺼번에 다루려면 어떤 시스템 구성이 필요한지를 보여주는 사례에 가깝다.

무엇을 해결하려는가
기존 이미지 생성 모델은 큰 물체, 스타일, 조명, 분위기를 잘 맞추는 방향으로 빠르게 발전했다.
하지만 텍스트가 많은 이미지는 여전히 어렵다.
글자 획이 조금만 무너지면 사용자는 결과를 즉시 알아차린다.
특히 중국어·영어가 섞인 bilingual layout, 작은 글씨가 많은 표, 포스터 속 제목과 부제, 슬라이드 안의 계층 구조처럼 문자 정확도와 시각적 조형성이 동시에 필요한 작업은 단순한 aesthetic score로 평가하기 어렵다.
또 하나의 병목은 생성과 편집의 분리다.
실제 워크플로에서는 “처음부터 이미지를 생성”하는 일과 “기존 이미지를 바탕으로 일부만 바꾸는 일”이 자주 이어진다.
모델이 text-to-image에서는 강하지만 editing에서 identity를 잃거나, editing은 잘하지만 dense text를 못 쓰면, 사용자는 여러 모델을 오가야 한다.
Qwen-Image-2.0은 이 두 트랙을 하나로 합치려는 설계다.
공식 블로그는 Qwen-Image 계열의 전개를 generation track과 editing track의 병렬 발전으로 설명한다.
Qwen-Image는 정확한 텍스트 렌더링, Qwen-Image-2512는 디테일과 포토리얼리즘, Qwen-Image-Edit 계열은 단일·다중 이미지 편집과 consistency를 개선해 왔고, 2.0에서는 이 두 흐름을 하나의 모델로 합쳤다는 설명이다.
핵심 아이디어 / 구조 / 동작 방식
논문이 제시하는 Qwen-Image-2.0의 구조는 세 축으로 요약된다.
첫째, 조건 인코더로 Qwen3-VL을 사용한다.
둘째, 이미지를 latent로 압축하고 복원하는 VAE가 있다.
셋째, latent 공간에서 denoising을 수행하는 MMDiT backbone이 텍스트와 이미지 표현을 함께 처리한다.
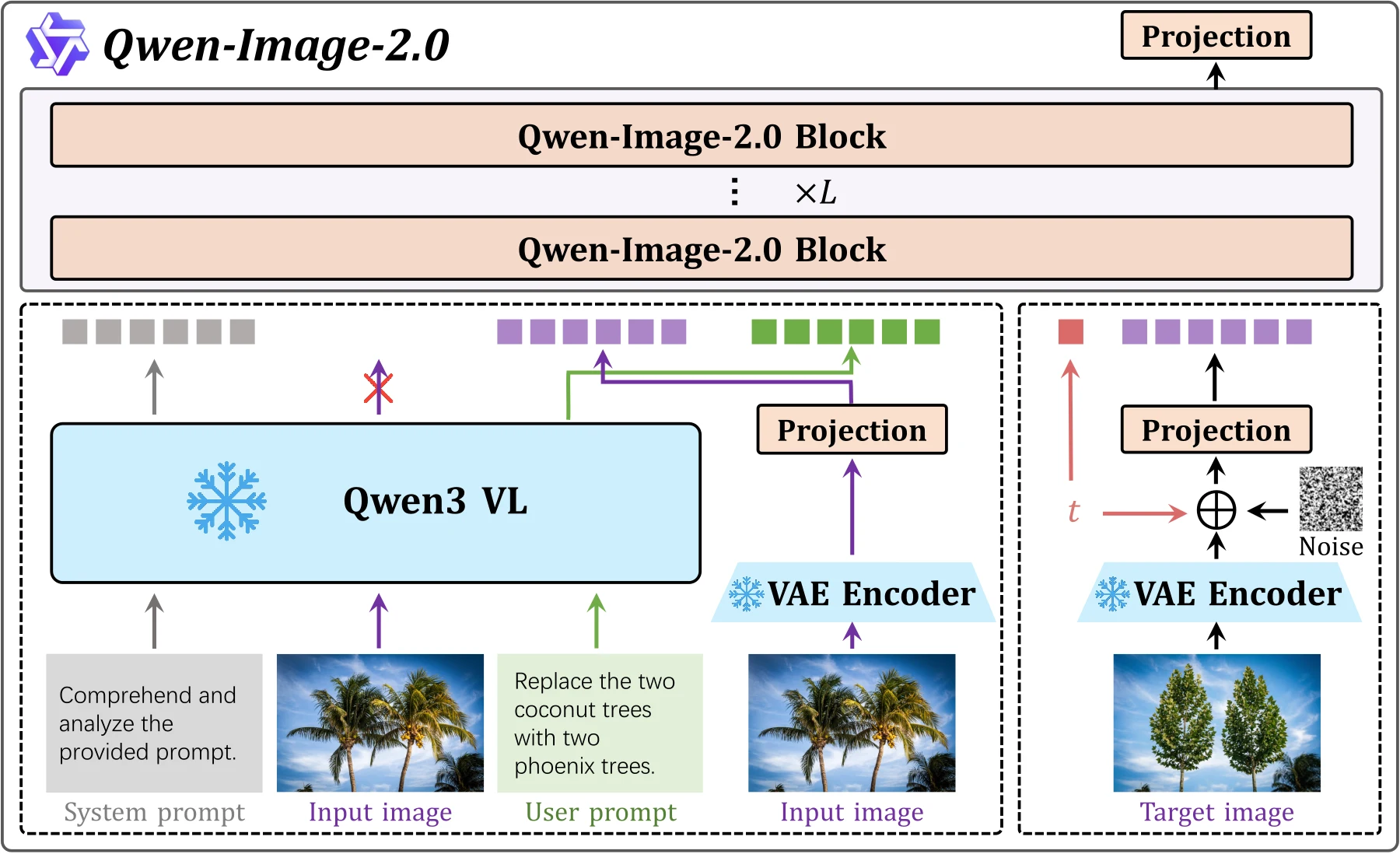
이 구조에서 흥미로운 부분은 “텍스트 인코더 + 이미지 디퓨전” 정도로 끝나지 않는다는 점이다.
Qwen3-VL이 텍스트와 시각 입력을 modality-aware representation으로 인코딩하고, VAE가 이미지 representation을 latent로 바꾼 뒤, MMDiT가 이들을 같은 transformer backbone 안에서 처리한다.
논문은 이 unified stream에 MSRoPE positional encoding을 적용하고, modulation module에서 bias를 제거한 multiplicative modulation을 사용한다고 설명한다.
또한 joint text-image training에서 activation magnitude가 커지는 문제를 완화하기 위해 MLP에 SwiGLU를 넣는다.
VAE는 Qwen-Image-2.0에서 특히 중요하다.
논문은 기존 공개 VAE들이 주로 8× compression을 쓰는 반면, Qwen-Image-2.0은 16× compression을 사용한다고 설명한다.
2K native generation을 생각하면 latent token 수를 줄이는 것이 학습·추론 비용에 직접 영향을 준다.
하지만 compression을 높이면 reconstruction fidelity가 떨어지고, latent channel을 늘리면 diffusion이 어려워진다.
Qwen-Image-2.0은 residual autoencoder, 64-channel latent, text-rich corpus, semantic alignment loss를 조합해 이 균형을 맞추려 한다.
논문의 VAE 표를 짧게 재구성하면 다음과 같다.
같은 16× compression 계열끼리 보면 Qwen-Image-2.0 VAE가 ImageNet과 text-rich reconstruction에서 가장 높은 값을 제시한다.
| VAE 모델 | 설정 | Enc / Dec params | ImageNet 256 PSNR / SSIM | Text 256 PSNR / SSIM |
|---|---|---|---|---|
| HunyuanImage-3.0 | f16c32 | 389M / 871M | 31.08 / 0.8655 | 29.23 / 0.9521 |
| Wan2.2 | f16c48 | 150M / 555M | 31.30 / 0.8784 | 28.19 / 0.9508 |
| Stepvideo-T2V | f16c64 | 110M / 389M | 31.54 / 0.8973 | 29.62 / 0.9641 |
| Qwen-Image-2.0 | f16c64 | 79M / 259M | 33.42 / 0.9225 | 32.81 / 0.9795 |
데이터 쪽도 단순한 대형 수집으로 설명되지 않는다.
논문은 realistic photography, graphic design, artistic content, synthetic imagery, slides, posters, rendered assets를 포함한 T2I 데이터와, attribute modification, background replacement, style transfer, text editing, restoration, single-image/multi-image editing 데이터를 함께 다룬다.
특히 captioning도 일반 캡션, text caption, knowledge caption, structured caption으로 나누어 text-rich·diagram-like 이미지의 구조를 더 잘 설명하도록 설계했다.

학습 레시피는 pre-training, continual pre-training, supervised fine-tuning, RLHF, few-step distillation로 이어진다.
논문 표 기준 기본 multi-stage training configuration은 다음과 같다.
| 단계 | steps | 해상도 | T2I / TI2I 비율 | batch size | learning rate |
|---|---|---|---|---|---|
| Pre-training | 700K | 256 / 512 | 0.9 / 0.1 | 32K / 16K | 1e-4 |
| Continual pre-training | 250K | 512 / 1024 / 2048 | 0.7 / 0.3 | 16K / 8K / 4K | 2e-5 |
| Supervised fine-tuning | 10K | 512 / 1024 / 2048 | 0.7 / 0.3 | 16K / 8K / 4K | 1e-5 |
RLHF는 T2I와 TI2I의 reward를 분리해 구성한다.
T2I에는 aesthetic reward, image-text alignment reward, portrait reward가 들어가고, TI2I에는 instruction-following reward와 visual consistency reward가 들어간다.
최적화는 diffusion 모델에 맞춘 GRPO 계열로 설명되며, rollout sampling에서는 CFG를 쓰되 policy optimization objective에서는 unconditional branch를 제외하는 hybrid strategy를 사용한다.
이후에는 DMD 기반 few-step distillation을 통해 40-step teacher에 가까운 품질을 4 NFE student로 줄이는 방향도 제시한다.
공개된 근거에서 확인되는 점
가장 강한 공개 근거는 preference benchmark와 qualitative evidence다.
기술보고서는 LMArena T2I leaderboard에서 Qwen-Image-2.0이 2026년 4월 22일 접근 기준 global #9, Chinese model 중 #1, ELO 1168을 기록했다고 설명한다.
논문은 이 결과를 이전 Qwen-Image 계열 대비 생성과 편집 모두에서 개선된 evidence로 제시한다.
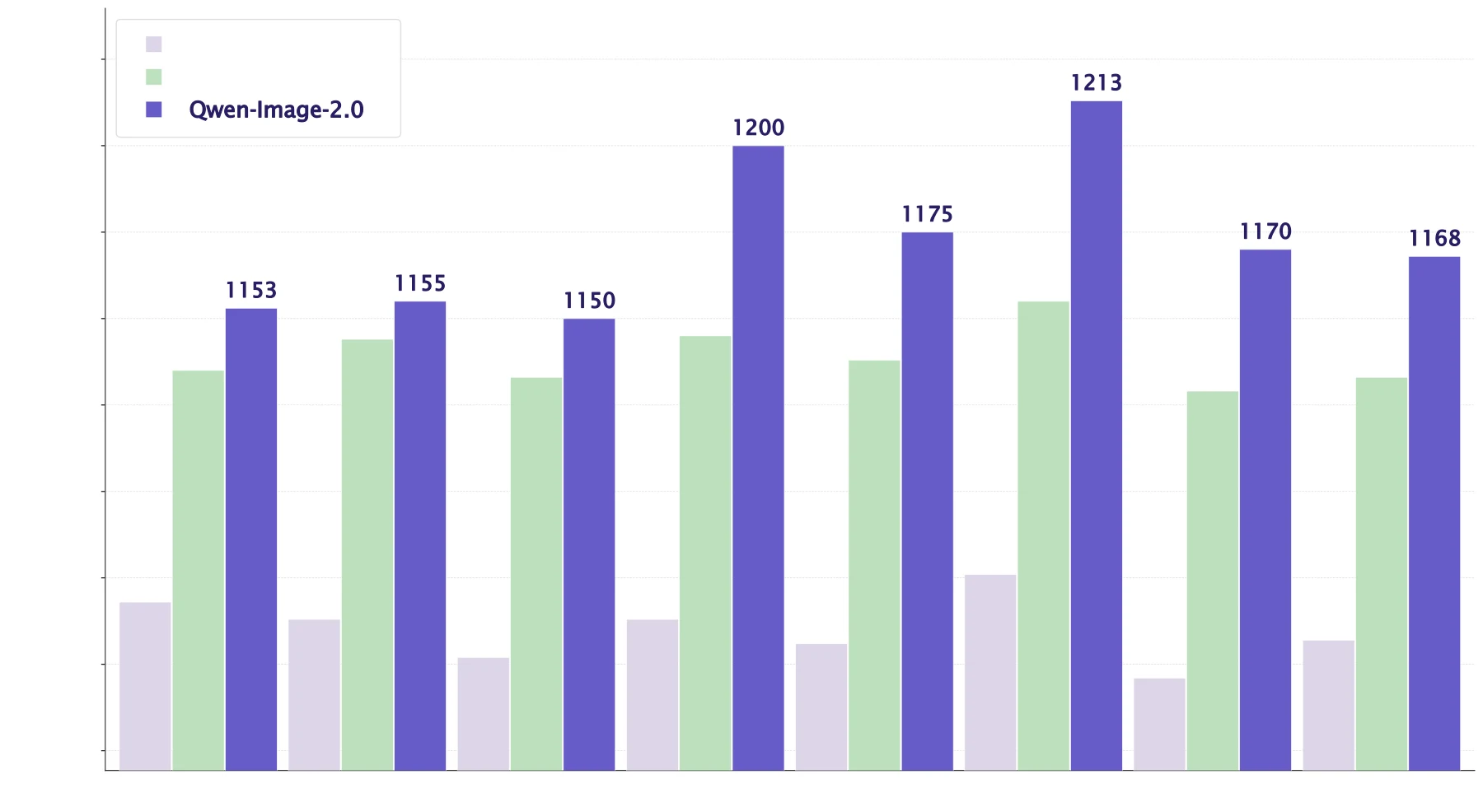
다만 이 수치는 절대적인 “모든 작업에서 최고”라는 뜻으로 읽으면 안 된다.
LMArena는 사용자 preference 기반의 blind comparison이며, 논문이 접근한 특정 시점의 leaderboard snapshot이다.
그럼에도 text-rich output과 editing을 하나의 모델로 묶은 상태에서 상위권 preference score를 기록했다는 점은 실무 관점에서 의미가 있다.
텍스트 렌더링 성능만 좋아도 이미지 품질이 떨어지면 쓸 수 없고, 포토리얼리즘만 좋아도 글자가 깨지면 문서형 산출물에는 부적합하기 때문이다.
공식 블로그의 예시는 Qwen-Image-2.0이 무엇을 팔고 싶은 모델인지 더 분명하게 보여준다.
아래 AB testing report 이미지는 단순한 “멋진 그림”이 아니라, 제목, bilingual heading, 표, 화살표, KPI, p-value, recommendation block을 모두 포함한 infographic이다.
이런 이미지는 문자가 맞아야 하고, 표 구조가 읽혀야 하며, 전체 레이아웃이 보고서처럼 보여야 한다.

또 다른 예시는 comic layout이다.
공식 블로그는 4×6 grid comic prompt를 제시하고, 각 컷 안의 대화와 장면을 안정적으로 배치하는 능력을 강조한다.
이미지 모델이 만화 컷을 만들 수 있다는 말 자체는 새롭지 않지만, 컷 수가 많고 dialogue balloon이 많은 경우에는 character consistency, panel structure, speech text placement가 동시에 필요하다.

편집 쪽에서는 multi-image composition과 identity preservation이 핵심이다.
공식 블로그의 두 이미지 합성 예시는 같은 인물을 서로 다른 복장과 맥락으로 자연스럽게 배치하는 작업이다.
논문 역시 TI2I editing에서 complex Chinese text rendering과 identity preservation을 주요 qualitative task로 다룬다.
즉 Qwen-Image-2.0의 편집 주장은 단순한 inpainting이 아니라, 기존 이미지의 identity와 구조를 보존하면서 새로운 지시를 수행하는 쪽에 가깝다.

공개 표면을 함께 보면 release maturity는 조금 보수적으로 읽어야 한다.
| 표면 | 확인한 내용 | 해석 |
|---|---|---|
| arXiv 2605.10730 | Qwen-Image-2.0 Technical Report, 2026년 5월 11일 제출 | 구조, 데이터, 학습, benchmark의 가장 강한 근거 |
| 공식 Qwen blog | 1K-token instruction, native 2K, generation/editing 통합, text-rich 예시 제공 | 제품 포지셔닝과 시각 예시의 주요 출처 |
| GitHub QwenLM/Qwen-Image | README에 Qwen-Image-2.0 launch와 Qwen Chat 체험 링크가 있고, quick start는 Qwen-Image-2512 / Edit-2511 중심 | 2.0은 글 작성 시점에 repo만으로 local reproduction surface가 명확하다고 보기는 어려움 |
| Hugging Face API | 공개 검색에서는 Qwen-Image, Qwen-Image-2512, Qwen-Image-Edit 계열이 확인됨 | 2.0 공개 가중치 여부는 기존 2512 계열과 분리해서 봐야 함 |
| GitHub metadata | QwenLM/Qwen-Image는 약 7.9K stars, 495 forks, latest release 404, tags 없음 | 빠르게 진화하는 공개 repo이지만, 버전 태깅된 2.0 배포 패키지로 해석하기에는 아직 이른 상태 |
이 점은 글의 결론을 바꾼다.
Qwen-Image-2.0은 논문·블로그·Qwen Chat 표면에서는 강하게 제시된 모델이지만, 사용자가 바로 로컬에 내려받아 2.0을 재현하는 open-weight release로 단정하면 안 된다.
적어도 현재 공개 자료 기준으로는 기술보고서와 제품 체험 표면이 먼저 있고, 공개 체크포인트·태그·재현 패키지는 이전 Qwen-Image 라인보다 덜 명확한 상태로 보는 편이 안전하다.
실무 관점에서의 해석
Qwen-Image-2.0에서 가장 흥미로운 지점은 텍스트 렌더링을 부가기능이 아니라 foundation model 설계의 중심으로 둔다는 점이다.
많은 이미지 모델은 “이미지 안에 텍스트도 어느 정도 쓸 수 있다”고 말하지만, Qwen-Image-2.0은 아예 1K-token prompt, slides, posters, infographics, comics, multilingual typography를 전면에 세운다.
이는 이미지 생성 모델의 사용처가 광고·콘셉트 아트에서 문서형 visual production으로 넓어지고 있다는 신호다.
이 방향은 에이전트 워크플로와도 잘 맞는다.
사용자가 짧은 요구를 말하면 LLM이 구조화된 prompt로 확장하고, 이미지 모델이 그 prompt를 실제 시각 산출물로 만든다.
논문의 Prompt Enhancer는 바로 이 지점을 모델 안쪽에 넣으려는 시도다.
PE는 짧고 모호한 사용자 prompt를 layout, object relation, visual hierarchy, composition intent가 풍부한 prompt로 바꾸고, SFT 이후 GRPO 기반 RL로 downstream image quality까지 맞춘다.
실무적으로는 세 가지 가능성이 크다.
첫째, 디자인 초안의 밀도가 올라간다.
기존에는 “대략 이런 느낌”의 이미지를 만든 뒤 사람이 Figma나 PowerPoint에서 텍스트와 표를 다시 얹어야 했다.
Qwen-Image-2.0류 모델이 좋아질수록 첫 번째 출력이 바로 리뷰 가능한 slide/report mockup에 가까워진다.
둘째, localization과 multilingual creative production 비용이 줄어든다.
중국어·영어가 섞인 poster, bilingual infographic, regional campaign asset을 한 번에 만들 수 있기 때문이다.
셋째, image editing과 generation의 경계가 약해진다.
같은 모델이 기존 사진에 시를 넣고, 인물을 합성하고, text-rich poster를 만드는 식의 복합 작업을 처리할 수 있다.
반대로 리스크도 분명하다. text rendering이 좋아졌다고 해서 문서 검수 문제가 사라지지는 않는다.
숫자, 단위, 인명, 법적 문구, 의학·금융 disclosure가 들어가는 이미지는 여전히 사람이 확인해야 한다.
모델이 복잡한 표를 “그럴듯하게” 만들수록 작은 오류는 더 눈에 띄지 않을 수 있다.
따라서 Qwen-Image-2.0의 강점은 final authority가 아니라 검수 가능한 고밀도 초안을 빠르게 만드는 능력으로 보는 편이 실무적이다.
두 번째 리스크는 공개 배포 표면이다.
Qwen-Image 계열은 이미 Hugging Face와 ModelScope에 여러 공개 체크포인트를 갖고 있지만, 2.0은 공식 블로그와 Qwen Chat 체험 경로가 먼저 보인다.
조직에서 실제 파이프라인에 넣으려면 weight availability, license, runtime memory, batching, 안전 필터, prompt enhancer 포함 여부, editing API 형태를 별도로 확인해야 한다.
특히 논문에서 말하는 full system과 repo quick start가 가리키는 공개 모델이 항상 같은 것은 아니다.
왜 중요하게 볼 만한가
Qwen-Image-2.0은 “이미지 생성 모델이 어디까지 갈 수 있는가”보다 “이미지 생성 모델이 어떤 작업 도구가 되어야 하는가”에 가까운 답을 준다.
단일 장면을 예쁘게 만드는 모델에서, 텍스트·표·슬라이드·편집·멀티이미지 합성을 다루는 production assistant로 이동하는 흐름이다.
기술적으로는 Qwen3-VL 조건 인코더, 16× VAE, MMDiT, prompt enhancer, data flywheel, RLHF, distillation이 모두 같은 방향을 향한다.
모델을 무작정 키우기보다, text-rich creative workflow에서 실제로 실패하는 지점을 데이터·구조·보상·추론 효율로 나누어 고치는 접근이다.
따라서 Qwen-Image-2.0을 볼 때는 benchmark 순위만 보지 않는 편이 좋다.
더 중요한 질문은 이것이다.
앞으로 이미지 모델은 “그림을 그리는 모델”에 머물 것인가, 아니면 “복잡한 시각 문서를 작성하고 수정하는 모델”이 될 것인가.
Qwen-Image-2.0은 후자에 꽤 강하게 베팅한 릴리스다.