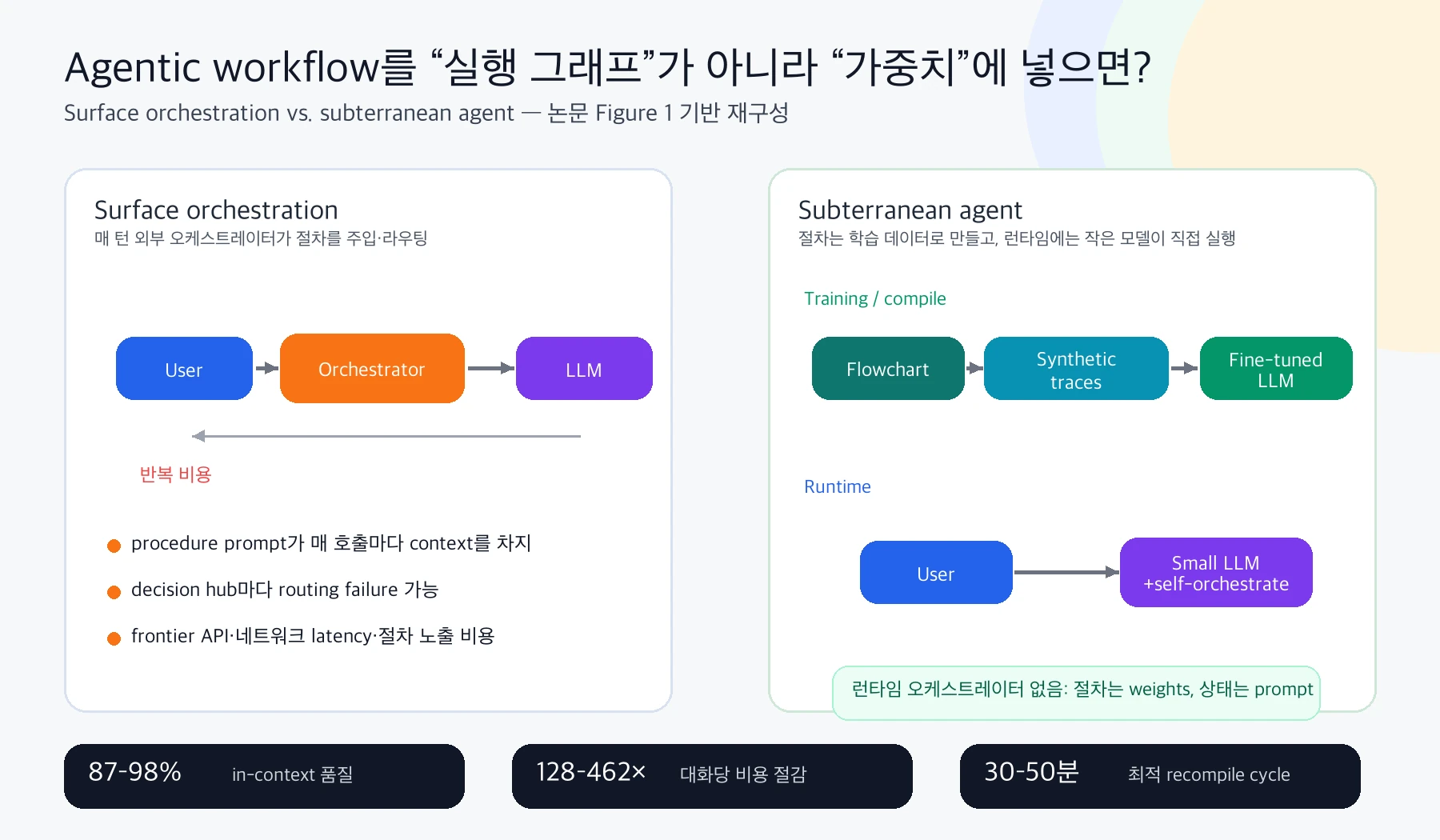
요즘 에이전트 시스템은 대개 LangGraph, CrewAI, OpenAI Agents SDK, Semantic Kernel, LlamaIndex 같은 외부 orchestration layer 위에서 돌아간다.
그래프나 상태 머신이 다음 node를 고르고, 매 턴 procedure prompt를 모델에 넣고, decision hub에서는 routing을 다시 판단한다.
이 구조는 개발자에게는 익숙하고 디버깅하기 쉽지만, 절차가 안정적인 업무에서는 같은 절차 설명을 매번 context에 다시 싣는 비용을 만든다.
Compiling Agentic Workflows into LLM Weights는 이 관성을 정면으로 건드린다.
논문이 제안하는 subterranean agent는 오케스트레이터를 런타임 컨트롤러로 쓰지 않는다.
대신 flowchart로 정의한 절차를 synthetic conversation 데이터로 만들고, 작은 모델을 full fine-tuning해서 그 절차를 모델 가중치 안에 내재화한다.
논문의 핵심 문장은 간단하다. persistent structure는 weights에, transient state는 prompt에 둔다.
무엇을 해결하려는가
논문이 겨냥하는 병목은 “에이전트 framework가 불필요하다”가 아니라, 안정적인 절차형 workflow를 매번 외부 graph로 실행해야 하는가다.
여행 예약, 고객지원, 보험 청구처럼 정해진 절차와 decision hub가 있는 업무에서는 절차 자체가 자주 바뀌지 않는다.
그런데 surface orchestration은 그 절차를 매 턴 prompt에 넣고, 외부 node template과 router가 모델의 자연스러운 대화 흐름을 계속 잘라낸다.
저자들은 이전 연구에서 frontier model에 전체 procedure를 system prompt로 넣는 in-context 방식이 orchestration보다 절차형 task에서 강하다는 결과를 출발점으로 삼는다.
하지만 in-context 방식도 문제가 있다. frontier model을 매 대화에 써야 하고, 절차 prompt가 context window를 차지하며, 회사 내부 procedure가 API provider에게 그대로 노출될 수 있다.
결국 논문은 “frontier model + 긴 system prompt”의 품질을 유지하면서, 런타임 비용과 절차 노출을 줄이는 방법으로 workflow compilation을 제안한다.
여기서 compilation은 metaphor가 아니다.
절차 flowchart를 따라 가능한 path를 샘플링하고, Claude Sonnet 4.5가 turn-by-turn synthetic conversation을 생성한다.
그 대화들을 작은 Qwen 계열 모델에 full-parameter fine-tuning하면, inference 때는 “You are a helpful travel booking assistant” 같은 최소 prompt만 넣어도 모델이 절차를 따라가도록 만든다.
외부 graph는 더 이상 런타임 interpreter가 아니라 training data generator가 된다.
핵심 아이디어 / 구조 / 동작 방식
논문은 procedure를 directed graph F = (N, E, n₀, T)로 표현한다.N은 agent/user node와 prompt template, E는 optional condition이 붙은 transition, n₀는 start node, T는 success·abandonment·escalation 같은 terminal state다.
중요한 점은 이 graph가 배포 시점에는 직접 실행되지 않는다는 것이다.
Subterranean pipeline은 네 단계다.
- 업무 절차를 flowchart node와 edge로 정의한다.
- flowchart의 valid path를 샘플링해 synthetic conversation을 만든다.
- 해당 대화로 작은 LLM을 full fine-tuning한다.
- 런타임에서는 절차 prompt, flowchart state, routing logic 없이 fine-tuned model을 직접 배포한다.
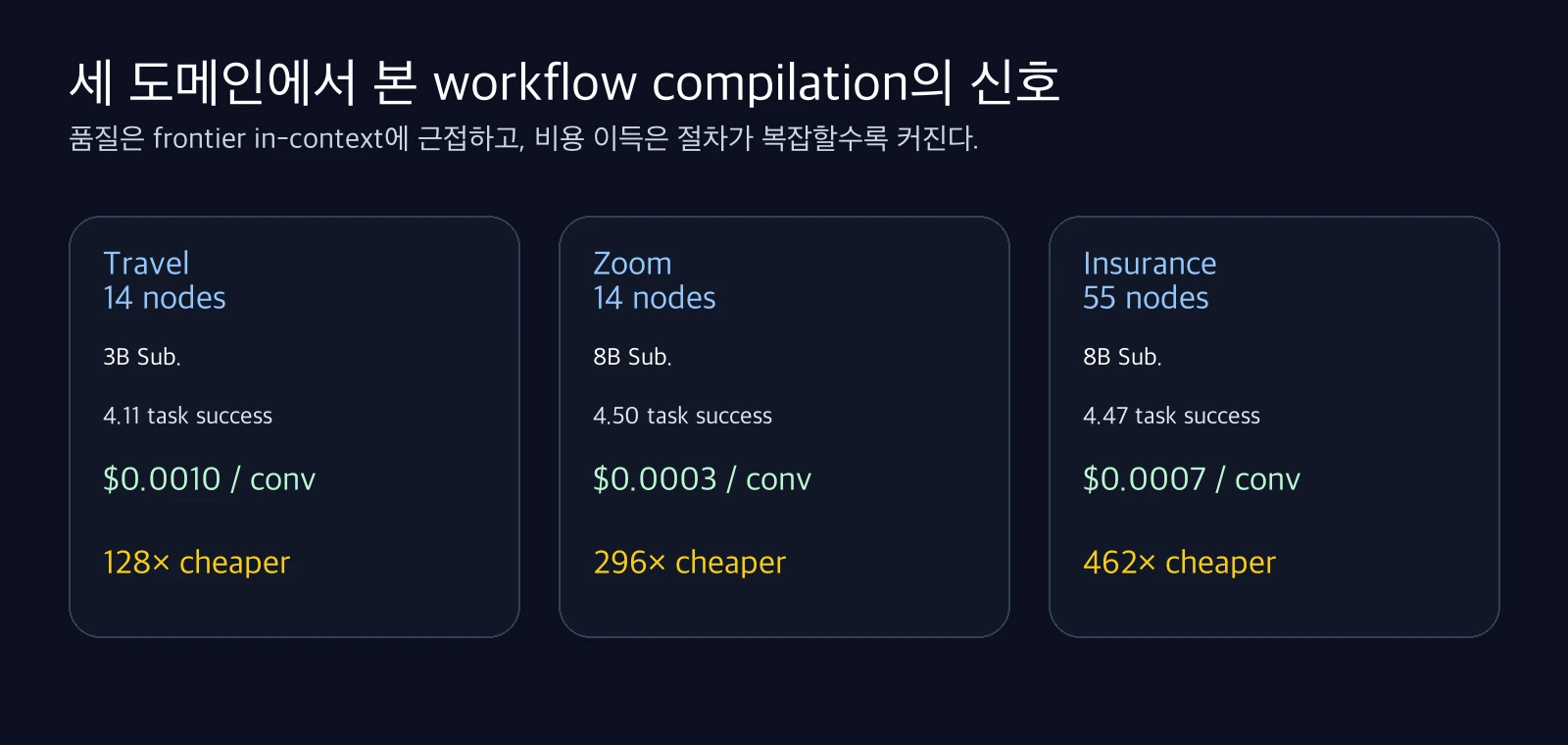
실험 도메인은 세 개다.
| 도메인 | 절차 규모 | 모델 / 데이터 | 논문이 보려는 질문 |
|---|---|---|---|
| Travel booking | 14 nodes, 3 decision hubs, 86 acyclic paths | Qwen 2.5 3B, 2,125 synthetic conversations | 같은 3B 모델에서 compilation이 explicit orchestration보다 나은가 |
| Zoom support | 14 nodes, 3 decision hubs, 60 acyclic paths | Qwen3-8B, 6,264 training conversations | product-specific knowledge까지 weights에 내재화되는가 |
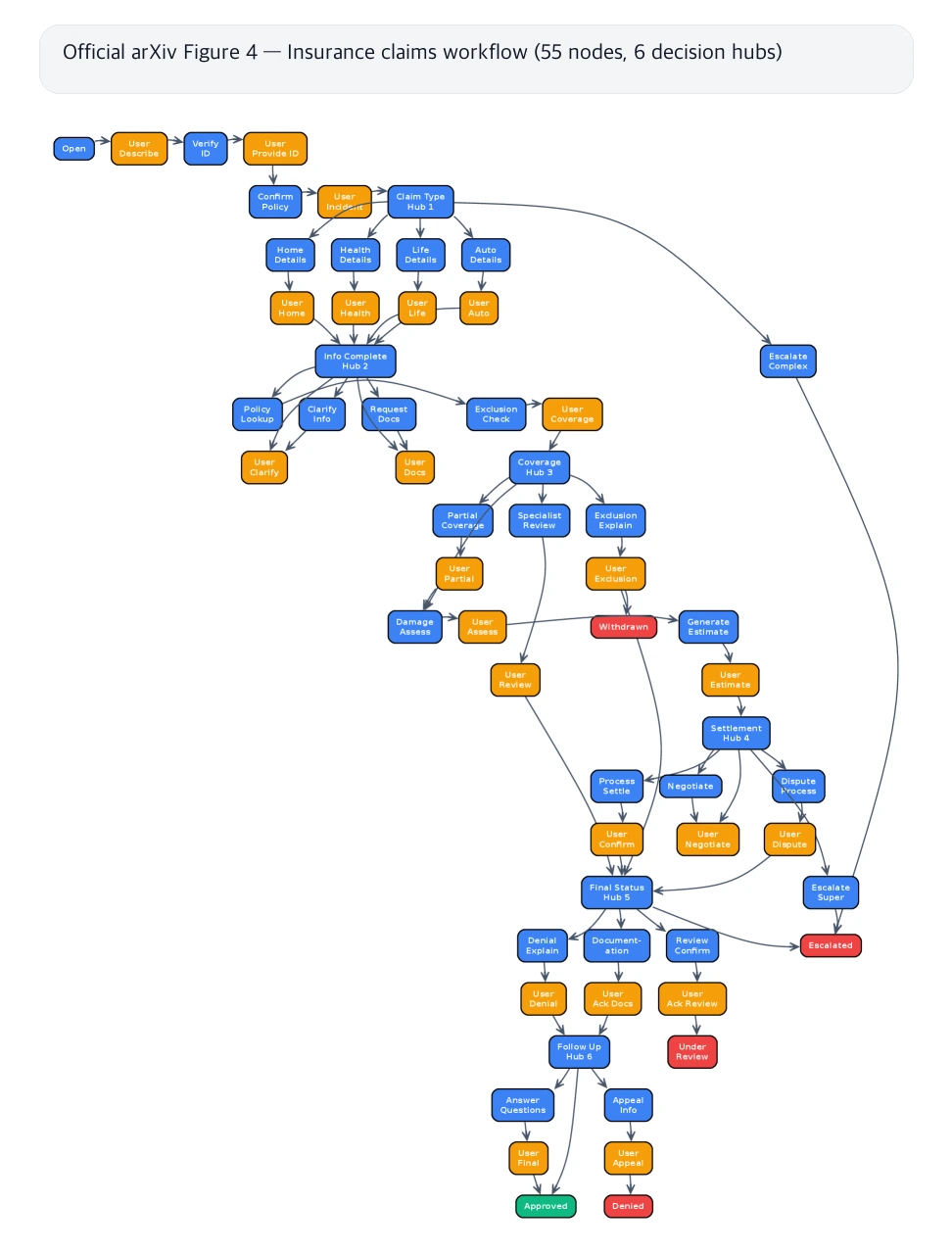
| Insurance claims | 55 nodes, 6 decision hubs, 2,381 acyclic paths | Qwen3-8B, 3,000 synthetic conversations | 더 복잡한 절차에서도 품질·비용 이득이 유지되는가 |
여행 실험은 특히 중요하다.
같은 Qwen 2.5 3B를 두 방식으로 비교한다.
하나는 flowchart node prompt와 routing을 매 턴 주입하는 3B surface orchestrator이고, 다른 하나는 fine-tuned 3B subterranean agent다.
이 비교는 “모델이 달라서”가 아니라 절차를 외부에서 실행하느냐, 가중치 안에 넣느냐의 차이를 분리한다.
반대로 Zoom과 보험 청구는 Qwen3-8B로 확장한다.
Zoom은 UI, 설정 메뉴, error code 같은 제품 지식이 필요하고, 보험 청구는 55 nodes와 nested loop를 가진 복잡한 절차다.
즉 단순한 slot filling보다 더 현실적인 customer operation workflow에 가깝다.
공개된 근거에서 확인되는 점
평가는 각 도메인·조건마다 n = 200 scenario를 사용한다. baseline은 두 개다.
첫째, Claude Sonnet 4.5를 LangGraph로 오케스트레이션하는 surface orchestrator다.
둘째, Claude Sonnet 4.5에 전체 serialized flowchart를 system prompt로 넣는 in-context baseline이다.
평가는 Claude Sonnet 4.5 LLM-as-judge가 task success, information accuracy, consistency, graceful handling, naturalness를 1–5점으로 채점하고, judge self-preference 가능성을 줄이기 위해 GPT-4.1 judge replication도 Appendix C에서 다시 수행한다.
품질 결과만 보면 in-context frontier baseline이 여전히 가장 강하다.
하지만 compiled model은 생각보다 가까이 간다.
Travel에서 3B subterranean agent는 같은 3B explicit orchestrator보다 task success, consistency, graceful handling, naturalness에서 모두 유의하게 앞선다.
Information accuracy는 4.75로 높지만 차이는 유의하지 않다.
LangGraph frontier orchestrator와 비교하면 task success와 consistency는 비슷하고, naturalness와 graceful handling은 LangGraph가 낫지만, information accuracy는 3B compiled model이 더 높게 나온다.
Zoom에서는 8B로 키우면서 naturalness와 graceful handling 격차가 많이 줄어든다.
8B subterranean agent는 LangGraph보다 naturalness가 높고(4.87 vs. 4.64), graceful handling은 비슷하다.
다만 product-specific information accuracy에서는 LangGraph가 앞선다(4.75 vs. 4.26).
이 결과는 “절차를 weights에 넣는 것”과 “넓은 제품 지식을 유지하는 것”이 같은 문제가 아님을 보여준다.
보험 청구는 논문에서 가장 설득력 있는 도메인이다.
55 nodes, 6 decision hubs, 2,381 acyclic paths로 절차가 훨씬 크지만, 8B compiled model은 in-context baseline의 92–98% 품질을 낸다.
LangGraph와 비교하면 task success와 information accuracy는 비슷하고, graceful handling(4.81 vs. 4.38), naturalness(4.92 vs. 4.58), consistency(4.51 vs. 4.39)에서 compiled model이 더 낫다.
비용 쪽 신호는 더 강하다.
논문은 Claude Sonnet 4.5 API 가격을 input $3/M, output $15/M token으로 두고, Qwen3-8B self-hosting은 A100 80GB reserved GPU($2.50/hr) + vLLM throughput 기준으로 대략 input $0.05/M, output $0.23/M token이라고 계산한다.
여기에 in-context baseline의 절차 prompt overhead가 붙는다.
14-node travel에서는 약 2배 token overhead, 55-node insurance에서는 약 7배 overhead다.
| 도메인 | In-context 비용 | LangGraph 비용 | Subterranean 비용 | In-context 대비 |
|---|---|---|---|---|
| Travel | $0.133 | $0.077 | $0.0010 | 128× cheaper |
| Zoom | $0.103 | $0.054 | $0.0003 | 296× cheaper |
| Insurance | $0.327 | $0.174 | $0.0007 | 462× cheaper |
실패율도 흥미롭다.
Judge가 task success를 3 이하로 준 conversation을 failure로 보면, travel에서는 compiled 3B가 5.5%, LangGraph가 24.0%다.
보험 청구에서는 compiled 8B가 9.0%, LangGraph가 17.0%다.
Zoom은 11.0% vs. 9.0%로 LangGraph가 약간 낫다.
즉 이 논문은 “항상 compiled가 이긴다”가 아니라, 절차 복잡도와 product knowledge 요구에 따라 다른 profile을 보여준다.
Flexibility에 대한 답도 공격적이다.
저자들은 procedure가 바뀌면 다시 학습해야 한다는 점을 인정하지만, optimized pipeline에서는 synthetic data generation 15–30분, fine-tuning 10–15분, spot-check 5분 정도로 묶어 30–50분 recompile cycle이 가능하다고 주장한다.
단, 이 수치는 8×H200과 병렬 API 요청을 전제로 한다.
단일 A100 80GB에서는 3–4시간 정도로 더 느리다.
공개 release surface는 보수적으로 봐야 한다. arXiv abstract와 HTML에서는 별도 공식 GitHub repository, Hugging Face model, dataset page 링크를 확인하지 못했다. exact title과 arXiv ID 기반 검색에서도 명확한 공식 companion artifact는 보이지 않았다.
따라서 현재 독자가 바로 내려받아 재현할 수 있는 오픈소스 framework라기보다, 논문 중심의 empirical argument로 읽는 편이 안전하다.
실무 관점에서의 해석
내가 보기에 이 논문의 가치는 “오케스트레이션을 버려라”가 아니라, agent workflow를 어느 계층에 저장할지 다시 생각하라는 데 있다.
반복 업무 절차에는 세 층이 있다.
자주 바뀌지 않는 procedure, 대화마다 바뀌는 user state, 그리고 외부 tool/API의 실제 실행 상태다.
지금 많은 agent framework는 이 셋을 모두 prompt와 graph runtime 안에 넣는다.
논문은 최소한 첫 번째, 즉 persistent procedure는 weights에 넣을 수 있다고 주장한다.
이 접근이 잘 맞는 곳은 명확하다.
고객지원, 예약, 보험 청구, 내부 운영 SOP처럼 path는 많지만 구조가 안정적인 workflow다.
이런 업무에서는 orchestration framework가 제공하는 투명성과 수정 용이성이 중요하지만, 일정 volume을 넘으면 매 turn procedure injection과 frontier API 호출이 비용 병목이 된다.
논문의 break-even 추정은 일회성 compilation 비용 $50–80을 포함해도 500 conversations 안쪽이다.
운영 volume이 충분하면 경제성이 생긴다.
하지만 caveat도 크다.
첫째, 이건 open-ended autonomous agent가 아니다.
목표가 계속 바뀌고 tool universe가 열려 있거나, 매번 새로운 plan을 짜야 하는 업무라면 절차를 weights에 굳히는 것이 오히려 위험할 수 있다.
둘째, full-parameter fine-tuning이 전제다.
논문은 LoRA rank 16–128 같은 parameter-efficient fine-tuning이 절차 internalization에서 full fine-tuning에 못 미친다고 언급한다.
일반 팀에게는 데이터 생성, 학습 인프라, regression evaluation이 모두 필요하다.
셋째, 평가가 synthetic user와 LLM judge 중심이다.
GPT-4.1 replication을 넣은 것은 좋은 장치지만, 실제 고객지원에서는 사용자 인내심, 정책 준수, tool side effect, human escalation 기준이 더 복잡하다.
특히 Zoom 결과처럼 product-specific knowledge가 중요한 영역에서는 작은 compiled model이 절차는 잘 따라도 세부 지식에서 frontier model에 밀릴 수 있다.
그래서 실무적으로는 hybrid routing이 가장 자연스럽다.
안정적이고 volume이 높은 80% path는 compiled small model이 처리하고, 새 정책·예외·낮은 confidence·destructive action은 기존 graph orchestrator나 frontier model, 또는 human review로 넘기는 방식이다.
이렇게 보면 subterranean agent는 LangGraph 같은 framework의 경쟁자라기보다, 성숙한 workflow의 hot path를 distill해 runtime cost를 줄이는 compilation target에 가깝다.
에이전트 생태계에서 지금까지 절차 지식은 prompt, skill, memory, graph node, tool schema 같은 외부 harness에 많이 저장됐다.
이 논문은 그 반대편 선택지를 보여준다.
절차가 충분히 안정적이고, 대화량이 많고, 재학습·검증 pipeline을 운영할 수 있다면, “절차를 매번 설명하는 agent”보다 “절차를 이미 배운 agent”가 더 싸고 단순할 수 있다.
다만 그 단순함은 공짜가 아니다.
런타임 복잡도를 줄이는 대신, training data generation과 release validation을 운영 프로세스로 받아들여야 한다.