온디바이스 언어 모델 경쟁은 이제 “작은 모델도 돌아간다”를 넘어섰다.
개인 비서, 로컬 코파일럿, 사내 문서 에이전트처럼 실제 사용자가 계속 대화하고 도구를 호출하는 제품에서는 모델 크기보다 툴 호출 지연, 긴 컨텍스트 안정성, hallucination 경계, 로컬 런타임 지원이 더 직접적인 병목이 된다.
클라우드 API를 쓰지 않는다는 장점도, 모델이 느리거나 도구 호출을 자주 망치면 제품 가치로 이어지기 어렵다.
Liquid AI의 LFM2.5-8B-A1B는 이 문제를 정면으로 겨냥한 업데이트다.
2025년 공개된 LFM2-8B-A1B의 8.3B total / 1.5B active MoE 골격을 유지하면서, 컨텍스트를 32K에서 128K로 늘리고, pretraining scale을 12T에서 38T tokens로 키웠으며, 65K BPE tokenizer를 128K vocabulary로 확장했다.
여기에 reasoning-only 후처리, doom-loop 완화, hallucination 경계 학습, 대규모 RL을 더해 “노트북에서 도구를 연쇄 호출하는 개인 비서”라는 더 구체적인 사용 장면으로 모델을 재배치한다.
흥미로운 점은 이 릴리스가 단순한 성능표 갱신이 아니라는 것이다.
Liquid는 Hugging Face 기본 체크포인트와 base 모델뿐 아니라 GGUF, ONNX, MLX, vLLM, SGLang, llama.cpp, LEAP 경로를 함께 내놓았다.
즉 LFM2.5-8B-A1B는 “작은 공개 모델”이라기보다 엣지 에이전트 모델을 실제 런타임 표면까지 어떻게 묶을 것인가에 대한 패키지형 답안에 가깝다.
무엇을 해결하려는가
LFM2.5가 풀려는 첫 번째 문제는 작은 모델의 에이전트 신뢰도다.
온디바이스 모델은 지연과 개인정보 측면에서 매력적이지만, 지식 용량이 작고 도구 호출이 불안정하면 실제 assistant loop에서 곧바로 한계가 드러난다.
Liquid는 이를 instruction following, tool calling, Tau² 같은 agentic workflow, hallucination 억제 벤치마크를 한 번에 묶어 평가한다.
모델 크기 자체보다 “로컬에서 빠르게 돌아가면서도 도구 호출을 얼마나 안정적으로 이어 가는가”가 중심 질문이다.
두 번째 문제는 긴 컨텍스트와 긴 reasoning trace의 비용이다.
LFM2.5는 컨텍스트 길이를 131,072 tokens로 늘리고, 128K 확장을 위해 RoPE base θ 조정과 400B token 규모의 long-document / long-trajectory midtraining을 수행했다고 설명한다.
이는 단순히 긴 문서를 넣기 위한 기능이라기보다, 여러 도구 호출과 중간 reasoning이 누적되는 로컬 에이전트 세션을 염두에 둔 선택으로 읽힌다.
세 번째 문제는 다국어 토큰화 효율이다.
기존 65K tokenizer를 그대로 버리지 않고, 기존 token ID를 최대한 보존한 채 BPE merge를 이어 학습하고 새 embedding row를 sub-token 평균으로 초기화한다.
공식 표에서 Hindi는 chars/token이 0.961에서 2.118로, Thai는 0.671에서 2.269로, Vietnamese는 1.519에서 3.311로 크게 오른다.
Korean도 1.652에서 1.943으로 약 17.6% 개선된다.
영어 중심 tokenizer에서는 작은 모델일수록 비라틴권 언어가 토큰 예산을 많이 잡아먹는데, 이 병목을 직접 줄이려 한 것이다.
핵심 아이디어 / 구조 / 동작 방식
구조적으로 LFM2.5-8B-A1B는 LFM2-8B-A1B의 hybrid MoE 설계를 이어간다.
Hugging Face 모델 카드 기준으로 이 모델은 8.3B total / 1.5B active, 24 layers, 18개의 double-gated LIV convolution block, 6개의 GQA block을 가진 text-only 모델이다.
즉 모든 층을 attention으로 채우는 대신, 짧은 convolution 블록과 소수의 grouped-query attention을 섞고, MoE FFN을 통해 총 용량과 활성 계산량을 분리한다.
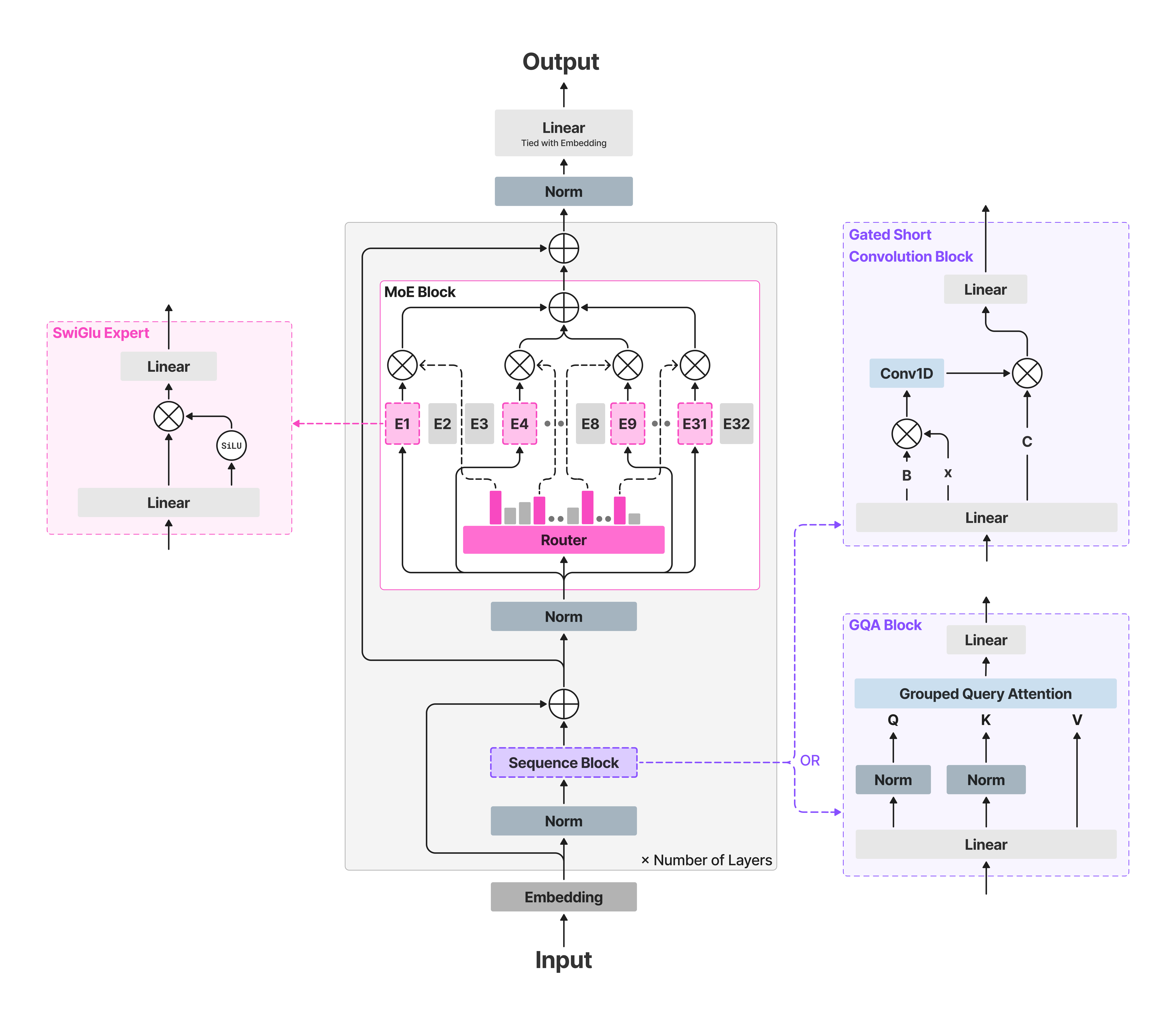
이번 업데이트의 핵심은 backbone 자체를 완전히 바꾸는 것이 아니라, 같은 구조를 더 긴 컨텍스트, 더 넓은 tokenizer, 더 강한 후처리 학습으로 다시 맞춘다는 데 있다.
| 축 | LFM2-8B-A1B | LFM2.5-8B-A1B | 해석 |
|---|---|---|---|
| 총/활성 파라미터 | 8.3B / 1.5B | 8.3B / 1.5B | sparse MoE 용량과 활성 계산량은 유지 |
| 컨텍스트 | 32,768 | 131,072 | 긴 문서와 긴 에이전트 trajectory를 겨냥 |
| Pretraining scale | 12T tokens | 38T tokens | 같은 체급에서 데이터·학습량을 크게 확대 |
| Vocabulary | 65,536 | 128,000 | 비라틴권 언어 토큰 효율 개선 |
| 동작 성격 | 일반 post-trained 모델 | reasoning-only 모델 | 답변 전 명시적 reasoning trace를 생성하는 방향 |
| 배포 표면 | HF / GGUF 중심 | HF, GGUF, ONNX, MLX, llama.cpp, vLLM, SGLang, LEAP | 로컬·모바일·서버 런타임을 동시에 겨냥 |
특히 reasoning-only 설계는 장점과 위험을 함께 만든다.
Liquid는 MoE가 compute-bound 환경에서 적은 활성 파라미터만 쓰기 때문에 reasoning token의 추가 비용이 상대적으로 작고, 품질 상승을 얻기 쉽다고 설명한다.
반대로 제품 관점에서는 reasoning trace를 어디까지 사용자에게 보여 줄지, 로그에 남길지, tool output과 섞일 때 어떤 보안·개인정보 정책을 둘지 별도 설계가 필요하다.
“reasoning을 한다”가 곧바로 “운영하기 쉽다”는 뜻은 아니다.
공개된 근거에서 확인되는 점
가장 큰 개선 신호는 전작 대비 표다.
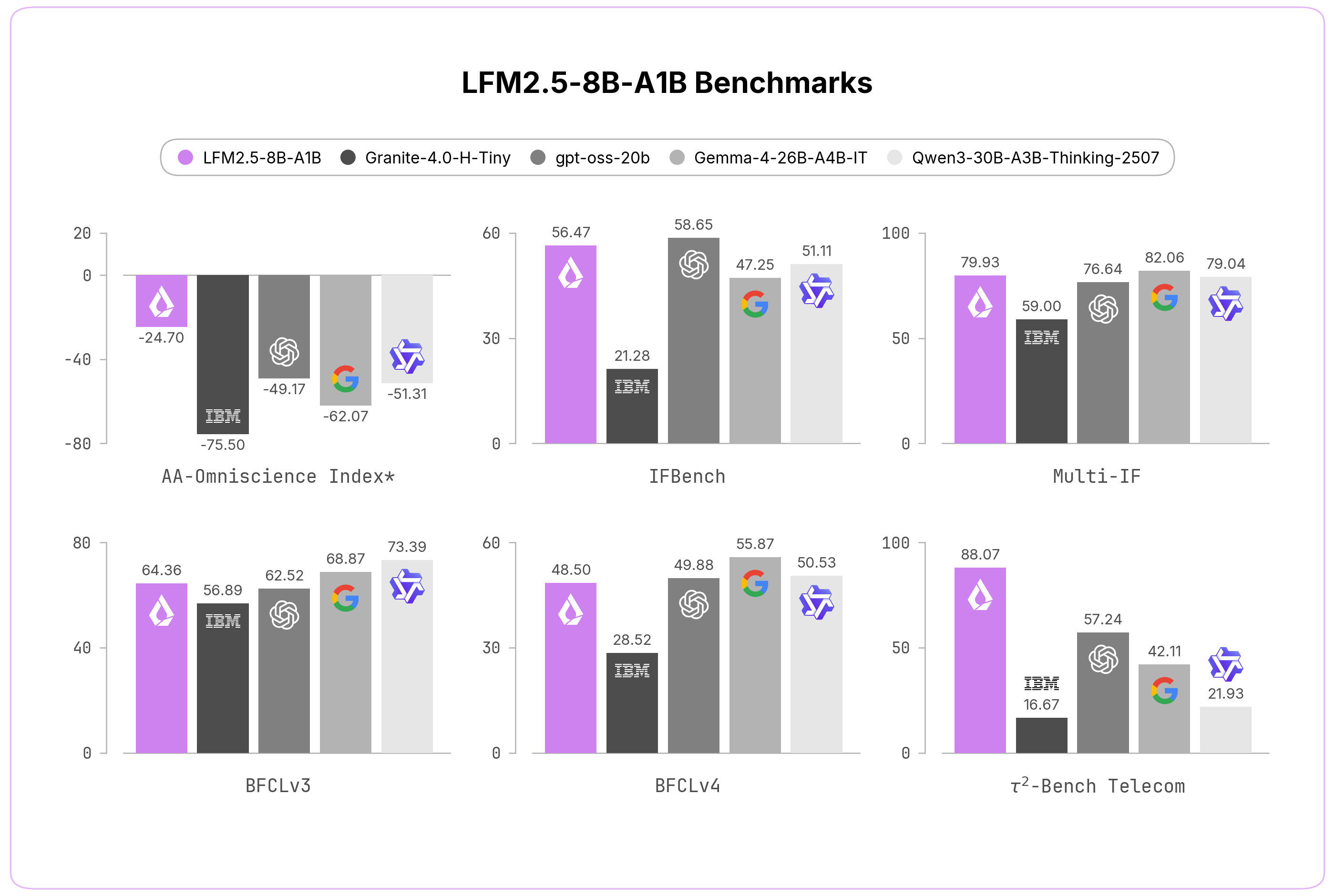
LFM2.5-8B-A1B는 IFEval 91.84, IFBench 56.47, Multi-IF 79.93을 기록하며 전작보다 instruction following 쪽에서 크게 오른다.
MATH500은 74.80에서 88.76으로, AIME25는 20.00에서 42.53으로 올라간다.
Tool-use 계열인 BFCLv3/v4와 Tau²에서도 상승폭이 크다.
| Benchmark | LFM2-8B-A1B | LFM2.5-8B-A1B | 변화 |
|---|---|---|---|
| AA-Omniscience Non-Hallucination Rate | 7.46 | 63.47 | +56.01 |
| IFEval | 79.44 | 91.84 | +12.40 |
| IFBench | 26.00 | 56.47 | +30.47 |
| Multi-IF | 58.54 | 79.93 | +21.39 |
| MATH500 | 74.80 | 88.76 | +13.96 |
| AIME25 | 20.00 | 42.53 | +22.53 |
| Tau² Telecom | 13.60 | 88.07 | +74.47 |
| Tau² Retail | 7.02 | 39.82 | +32.80 |
다만 이 표를 “모든 면에서 절대 우위”로 읽으면 안 된다.
공식 비교표에서도 Qwen3.5-4B는 AIME25/AIME26, BFCL, Tau² Retail에서 LFM2.5보다 높은 항목이 있고, Gemma-4-26B-A4B-IT는 Multi-IF와 일부 tool-use 항목에서 강하다.
LFM2.5의 메시지는 “모든 벤치마크 1등”이 아니라 1.5B active 경로로 instruction following, hallucination 경계, agentic telecom workflow에서 강한 trade-off를 만든다에 가깝다.
Hallucination 개선도 조심해서 읽어야 한다.
Liquid는 avg@k 기반 reward를 지식 데이터셋에 적용해, 모델이 모르는 질문에서 무리하게 답하기보다 abstention과 불확실성 표현을 배우도록 했다고 설명한다.
AA-Omniscience의 Non-Hallucination Rate가 7.46에서 63.47로 오른 것은 이 방향과 맞물린다.
하지만 같은 표의 Accuracy는 8.67로 여전히 낮다.
즉 LFM2.5는 “모르는 것을 덜 지어내는 작은 모델”에 가까우며, retrieval 없이 지식 집약형 QA를 맡길 수 있는 거대 모델로 해석하면 안 된다.
릴리스 표면은 꽤 넓다.
Hugging Face API 기준 post-trained 모델과 base 모델은 public, ungated이고, model.safetensors, config.json, chat_template.jinja, tokenizer 파일을 포함한다.
Quantized / runtime repository도 별도로 나뉜다.
| 배포 표면 | 공개 repo | 확인되는 의미 |
|---|---|---|
| Native checkpoint | LiquidAI/LFM2.5-8B-A1B |
Transformers, vLLM, SGLang, fine-tuning 또는 일반 추론용 기본 포맷 |
| Base model | LiquidAI/LFM2.5-8B-A1B-Base |
downstream fine-tuning을 위한 pre-trained base |
| GGUF | LiquidAI/LFM2.5-8B-A1B-GGUF |
llama.cpp와 로컬 CPU/edge inference 경로 |
| ONNX | LiquidAI/LFM2.5-8B-A1B-ONNX |
ONNX Runtime 기반 cross-platform accelerator 경로 |
| MLX 8-bit | LiquidAI/LFM2.5-8B-A1B-MLX-8bit |
Apple Silicon 로컬 실행 경로 |
라이선스는 실무적으로 따로 확인해야 한다.
모델 카드는 license: other, license_name: lfm1.0을 표시하고, 실제 LICENSE는 LFM Open License v1.0이다.
이 라이선스는 상업적 사용을 허용하되, 연매출 1,000만 달러 이상의 legal entity가 commercial use를 하는 경우에는 해당 계약 아래 라이선스되지 않는다고 적는다.
그래서 개인 개발, 연구, 소규모 제품 실험과 대기업 제품 탑재는 법무 검토의 무게가 다르다.
Sparse inference, everywhere의 실무적 의미
이번 릴리스에서 가장 제품적인 부분은 inference 섹션이다.
Liquid는 LFM2.5-8B-A1B가 llama.cpp, MLX, vLLM, SGLang, ONNX, LEAP을 day-one 지원한다고 주장한다.
이는 작은 모델 릴리스에서 흔히 보는 “가중치는 올렸고, 나머지 런타임은 커뮤니티가 따라오길 기다리는” 방식과 다르다.
모델 자체가 edge assistant를 목표로 한다면, 런타임 포맷과 예제 notebook이 성능표만큼 중요하다.
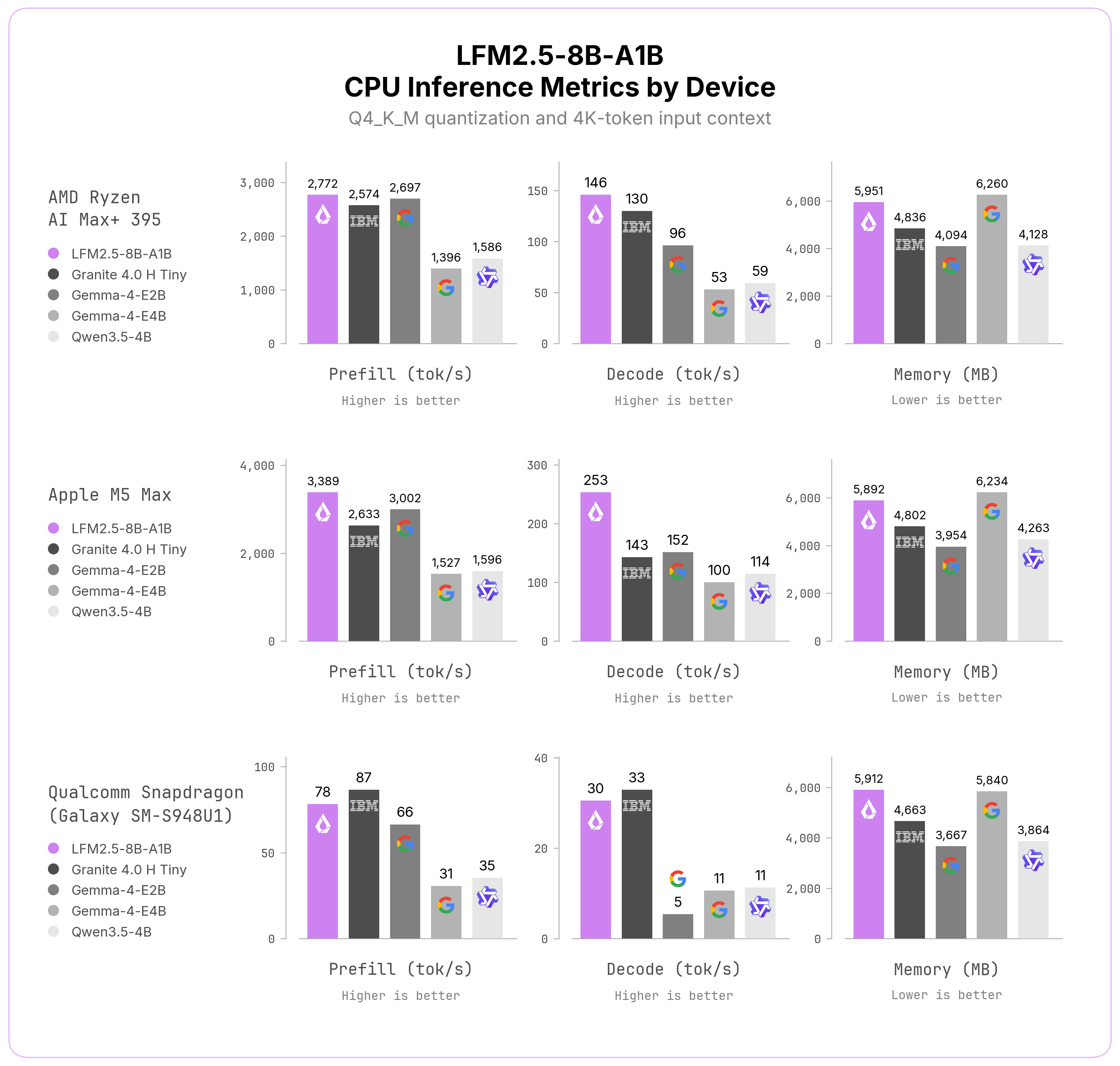
CPU 수치는 이 모델의 포지셔닝을 잘 보여 준다.
Liquid는 laptop-class 칩에서 prompt reading과 answer generation이 가장 빠른 축에 들어가며, 6GB 미만 메모리로 M5 Max 253 tokens/s, Ryzen AI Max+ 395 146 tokens/s decode를 기록한다고 설명한다.
전화기에서도 약 30 tokens/s를 유지한다고 하니, 짧은 도구 선택·호출·확인 loop라면 사용자가 “로컬이어서 느리다”고 느끼지 않을 가능성이 있다.
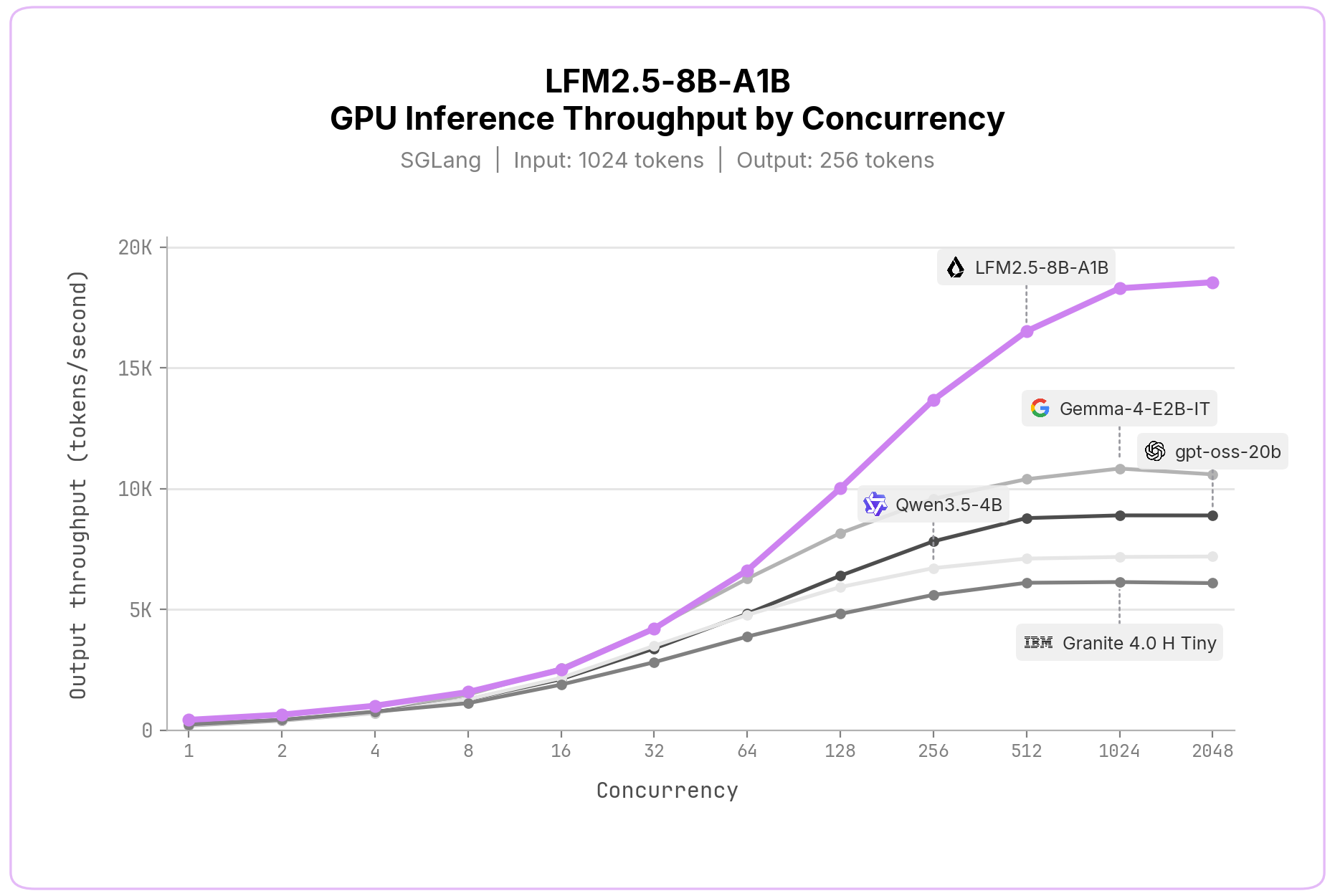
GPU 쪽은 서버 배포 해석에 가깝다.
Liquid는 단일 NVIDIA H100 SXM5에서 SGLang 0.5.12, BF16, 1,024 input tokens, 최대 256 output tokens, concurrency별 sustained-load setting으로 측정했고, high concurrency에서 18.5K output tokens/s, 하루 1.6B tokens 이상을 제시한다.
이 수치는 “온디바이스 모델”이 꼭 개인 노트북만 뜻하지 않음을 보여 준다.
같은 sparse MoE가 로컬 assistant와 고처리량 서버 endpoint 양쪽을 겨냥할 수 있다는 메시지다.
실무 관점에서의 해석
내가 보기에 LFM2.5-8B-A1B의 핵심은 “8B 모델이 좋아졌다”보다 온디바이스 에이전트의 최소 작동 단위를 어디까지 끌어올릴 수 있는가에 있다.
이전 LFM2가 엣지용 hybrid backbone과 모델 패밀리의 가능성을 보여 줬다면, LFM2.5는 그중 8B/A1B MoE 축을 개인 비서·툴 호출·긴 reasoning trajectory에 맞춰 다시 학습한 버전이다.
제품 팀 입장에서 강점은 세 가지다.
첫째, 1.5B active path 덕분에 로컬 지연을 낮추면서도 8B급 총 용량을 활용한다.
둘째, GGUF·MLX·ONNX·vLLM·SGLang 경로가 함께 있어 프로토타입부터 서버 fallback까지 선택지가 넓다.
셋째, tokenizer와 long-context가 개선되어 영어 중심 짧은 prompt demo를 넘어 다국어 문서와 긴 로컬 workflow에 더 가까워졌다.
하지만 한계도 선명하다.
지식 집약형 QA에서는 여전히 retrieval이나 도메인 grounding이 필요하다.
Reasoning-only 모델은 trace 노출 정책을 따로 설계해야 한다.
Benchmarks는 공식 harness와 특정 비교군에 묶여 있으므로, 실제 앱에서는 도구 schema, function-call format, quantization별 품질 저하, 열 throttling, 모바일 NPU/CPU backend, 개인정보 로그 정책을 별도로 검증해야 한다.
또 LFM Open License v1.0의 commercial threshold는 대기업이나 매출 규모가 큰 조직에는 중요한 제약이다.
그럼에도 LFM2.5는 온디바이스 AI 경쟁의 방향을 꽤 선명하게 보여 준다.
앞으로 로컬 assistant는 단순 챗봇이 아니라 문서 읽기, 함수 호출, MCP 서버, 파일 작업, 음성·화면 입력을 엮는 작은 에이전트 런타임이 될 가능성이 높다.
그런 관점에서 LFM2.5-8B-A1B는 “작고 빠른 모델”이 아니라, 로컬 에이전트 운영에 필요한 컨텍스트·토크나이저·추론·런타임 표면을 한 번에 맞추려는 공개 모델 릴리스로 읽는 편이 더 정확하다.