상호작용형 에이전트에서 planning은 단순한 chain-of-thought보다 까다롭다.
모델은 현재 상태를 읽고 다음 행동을 고른 뒤, 그 행동이 환경을 어떻게 바꿀지 내부적으로 예측해야 한다.
문제는 이 내부 예측이 조금만 틀려도 다음 reasoning이 틀린 상태 위에서 이어지고, horizon이 길어질수록 오류가 빠르게 누적된다는 점이다.
ProAct: Agentic Lookahead in Interactive Environments는 이 현상을 simulation drift로 정의한다.
논문의 목표는 inference 때마다 무거운 tree search를 붙이는 것이 아니라, search가 제공하는 미래 상태 감각을 모델 안에 학습시켜 에이전트가 더 정확한 lookahead reasoning을 하게 만드는 것이다.
공개 bundle은 arXiv 논문, GitHub 학습·평가 코드, Hugging Face 모델 weight로 구성되어 있으며, 실험 도메인은 stochastic한 2048과 deterministic한 Sokoban이다.
이 글에서 ProAct는 에이전트 런타임 제품이라기보다 lookahead reasoning을 학습시키는 model-training recipe로 읽는 편이 정확하다.
핵심은 두 단계다.
먼저 GLAD(Grounded LookAhead Distillation)가 환경 기반 search trajectory를 짧은 causal reasoning chain으로 압축해 SFT한다.
이후 MC-Critic이 lightweight rollout으로 보조 value estimate를 만들고, PPO/GRPO 계열 RL의 variance를 낮춰 long-horizon 의사결정을 보정한다.
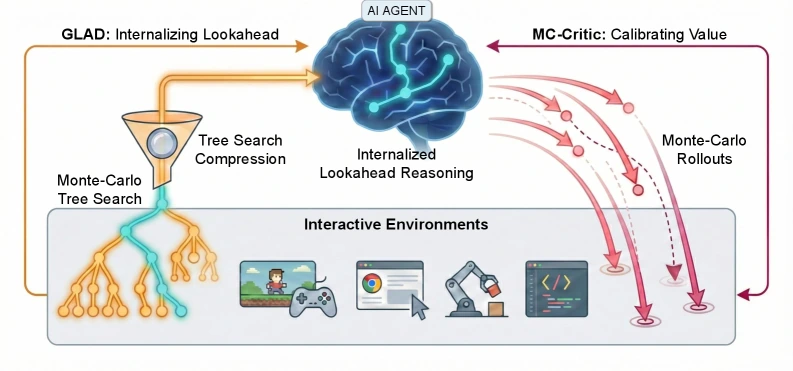
무엇을 해결하려는가
논문이 겨냥하는 병목은 “LLM이 생각을 더 길게 하면 planning을 잘한다”는 가정의 취약함이다.
2048이나 Sokoban 같은 환경에서는 현재 행동이 다음 상태를 바꾸고, 다음 상태가 다시 다음 선택지를 제한한다.
따라서 모델의 reasoning chain은 사실상 내부 world model처럼 작동한다.
하지만 LLM이 생성한 미래 상태 예측은 실제 환경 전이와 다를 수 있다.
예를 들어 2048에서 특정 이동 뒤 타일이 어떻게 합쳐질지 잘못 상상하거나, Sokoban에서 박스와 벽의 위치를 틀리게 추론하면 그 뒤의 계획은 형식적으로 그럴듯해도 실제 행동으로는 무효가 된다.
ProAct 논문은 이 오류가 lookahead depth와 함께 누적되는 현상을 simulation drift라고 부른다.
기존 대응은 크게 두 갈래다.
하나는 inference-time search를 계속 돌려 실제 환경과 맞춰 보는 방식이다.
정확도는 좋아질 수 있지만 비용이 크고, 매 step마다 search budget을 써야 한다.
다른 하나는 모델에게 더 많은 reasoning example을 주는 방식이다.
하지만 그 example이 실제 환경에 접지되어 있지 않으면, 모델은 그럴듯한 미래 상상만 더 잘하게 될 위험이 있다.
ProAct의 질문은 여기서 출발한다.
환경 search가 만든 정확한 미래 정보를 학습 데이터로 압축하고, RL 단계에서는 실제 rollout이 준 value signal로 정책을 다시 보정할 수 있는가?
핵심 아이디어 / 구조 / 동작 방식
ProAct는 두 단계 training paradigm으로 구성된다.
첫 번째 단계는 GLAD, Grounded LookAhead Distillation이다.
논문과 README는 MCTS를 사용해 환경을 실제로 probing하고, 후보 행동들의 미래 결과를 search tree로 만든다고 설명한다.
이때 중요한 것은 search tree 전체를 그대로 모델에게 주는 것이 아니다. tree에서 얻은 미래 상태 정보를 짧고 명시적인 reasoning chain으로 압축해, 모델이 “왜 이 행동이 낫다”를 causal하게 말하도록 SFT한다.
논문은 이를 cognitive compression으로 설명한다. search는 학습 데이터 생성 시점에만 무겁게 쓰이고, inference 시점에는 모델이 압축된 lookahead 습관을 내부화해 바로 행동을 고르게 한다.
즉 ProAct는 MCTS를 제품 runtime에 붙이는 방식이 아니라, MCTS를 teacher처럼 사용해 모델의 deliberation policy를 바꾸는 방식이다.
두 번째 단계는 MC-Critic, Monte-Carlo Critic이다.
GLAD가 grounded lookahead prior를 주더라도, SFT만으로는 long-horizon return을 직접 최적화하지 못한다.
그래서 ProAct는 PPO와 GRPO 같은 policy-gradient 학습에 lightweight environment rollout 기반 value estimate를 보조로 넣는다.
논문 표현대로 MC-Critic은 model-based value approximation에 의존하지 않고, 무작위 또는 lightweight rollout으로 다음 상태의 Monte-Carlo return을 추정해 advantage 계산을 안정화한다.
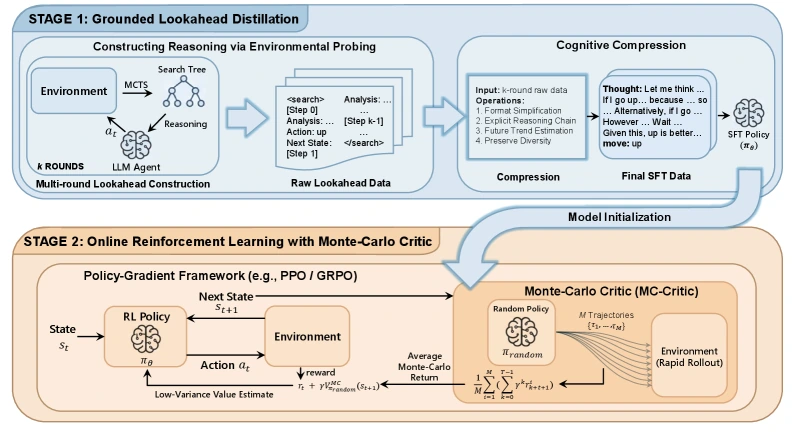
실험 설정도 이 구분을 따른다. backbone은 Qwen3-4B-Instruct이며, SFT 데이터는 2048에서 25K sample, Sokoban에서 8K sample을 수집했다고 보고된다.
RL은 GLAD checkpoint에서 이어서 학습하는 설정과, base instruction model에서 바로 시작하는 설정을 나눠 비교한다.
GitHub README 기준 학습 코드는 AReaL 기반이며, 논문 실험은 8×NVIDIA H20 GPU 노드에서 수행됐다.
공개된 근거에서 확인되는 점
가장 큰 결과 표는 2048과 Sokoban의 여러 variant에서 ProAct를 baseline과 비교한다.
논문 Table 1 기준 Qwen3-4B-Instruct base model은 2048 standard 4×4에서 721.3, 3×3 variant에서 187.3, 3072 variant에서 1603.0을 기록한다.
GLAD만 적용하면 각각 3335.3, 429.2, 4565.7로 올라가고, GLAD+MC-Critic은 4503.8, 464.4, 6013.7까지 오른다.
Sokoban에서도 같은 방향의 개선이 보고된다. base model은 unseen level(Base) 0.39, action-space variant 0.44, symbol variant 0.56이고, GLAD는 0.72, 0.52, 0.67, GLAD+MC-Critic은 0.94, 0.62, 0.70이다. absolute score 자체는 2048과 Sokoban의 metric이 다르기 때문에 직접 비교하면 안 되지만, 핵심 패턴은 GLAD가 lookahead reasoning prior를 만들고 MC-Critic이 그 위에서 long-horizon decision을 추가로 다듬는다는 점이다.
| 모델 / 방법 | 2048 4×4 | 2048 3×3* | 2048 3072* | Sokoban Base | Sokoban Action* | Sokoban Symbol* | 해석 |
|---|---|---|---|---|---|---|---|
| Qwen3-4B-Instruct | 721.3 | 187.3 | 1603.0 | 0.39 | 0.44 | 0.56 | 같은 4B backbone의 출발점 |
| Base + GLAD | 3335.3 | 429.2 | 4565.7 | 0.72 | 0.52 | 0.67 | 환경 search를 distill한 SFT만으로 큰 폭 개선 |
| Base + GLAD + MC-Critic | 4503.8 | 464.4 | 6013.7 | 0.94 | 0.62 | 0.70 | RL 단계에서 rollout 기반 value signal을 더해 추가 개선 |
* 표시는 논문이 SFT/RL 학습에서 보지 않은 environment variant로 설명하는 항목이다.
이 점은 중요하다.
ProAct의 주장 핵심은 단순히 훈련 환경을 암기한 것이 아니라, 줄어든 grid, 바뀐 목표 타일, 바뀐 action space나 symbol representation에서도 lookahead reasoning이 어느 정도 유지된다는 데 있다.

MC-Critic만 따로 떼어 보면, 논문은 GLAD-initialized policy 위에 PPO/GRPO를 올린 설정과 scratch RL 설정을 모두 제시한다.
GLAD checkpoint에서 시작한 variant evaluation에서는 MC-GRPO가 2048 3072에서 6013.7, MC-PPO가 Sokoban Extra 1.18과 Action 0.62를 기록해 baseline RL variant보다 대체로 높다. scratch setting에서도 MC-PPO는 2048 3×3 239.8, 3072 2229.1, Sokoban Action 0.96을 기록해 단순 Step-PPO보다 높게 보고된다.
다만 Sokoban 일부 항목에서는 Traj-GRPO와 MC-GRPO의 차이가 작거나 방향이 섞여 있어, MC-Critic을 모든 도메인에서 일방적으로 우세한 만능 critic으로 읽기보다는 long-horizon variance를 낮추는 보조 신호로 보는 편이 맞다.
공개 artifact도 확인할 만하다.
GitHub GreatX3/ProAct는 Apache-2.0 license metadata가 있고, README에는 inference, vLLM serving, 2048/Sokoban testing, SFT/RL training command가 정리되어 있다.
GitHub API 조회 기준 저장소는 2026년 2월 4일 생성됐고, stars 19, forks 2, open issues 0, default branch main이며, tags는 비어 있고 /releases/latest는 404를 반환했다.
따라서 현재 형태는 versioned package라기보다 논문 재현용 연구 코드와 데모 bundle에 가깝다.
Hugging Face biang889/ProAct는 논문 weight를 task와 stage별 subfolder로 나눠 공개한다.
API와 model card 기준 license tag는 Apache-2.0이고 gated는 false다.
중요한 것은 이 release가 하나의 범용 ProAct 모델이 아니라는 점이다.2048_sft, 2048_rl, sokoban_sft, sokoban_rl처럼 환경과 학습 단계가 나뉜 checkpoint bundle이며, 각 subfolder에는 safetensors shard, tokenizer, config, generation config 등이 들어 있다.
API 조회 시점의 usedStorage는 약 35.3GB이고, downloads는 0, likes는 4로 표시됐다.
실무 관점에서의 해석
ProAct의 실용적 의미는 “에이전트에게 더 길게 생각하라고 시킨다”와 “실제 환경을 보면서 미래를 검증하게 한다” 사이의 차이를 분명히 보여준다는 데 있다.
많은 agent prompting은 모델의 내부 상상에 의존한다.
하지만 interactive environment에서는 내부 상상이 실제 state transition과 맞지 않으면 reasoning은 오히려 더 설득력 있는 hallucination이 된다.
GLAD는 이 문제를 data-generation 단계에서 해결하려 한다.
환경이 실제로 보여준 미래 결과를 바탕으로 search tree를 만들고, 그 tree를 사람이 읽을 수 있는 causal reasoning chain으로 압축한다.
따라서 모델은 search algorithm의 행동을 그대로 모사하기보다, search가 발견한 미래 가치 판단의 논리를 흡수한다.
이 관점은 향후 tool-use, game, simulator, robot policy 같은 영역에서 “grounded trajectory를 어떻게 언어 reasoning으로 압축할 것인가”라는 더 일반적인 질문으로 확장될 수 있다.
MC-Critic도 운영적으로 흥미롭다.
RLHF류 학습에서 value model을 따로 학습하거나 모델 기반 critic을 두는 것은 비용과 안정성 문제가 있다.
ProAct는 controlled environment라면 lightweight rollout이 cheap한 value signal을 줄 수 있다는 쪽에 베팅한다.
제품 환경에서 모든 작업에 바로 적용되지는 않겠지만, simulator나 deterministic verifier가 있는 task라면 MC-Critic식 보조 value estimate가 충분히 매력적인 선택지가 될 수 있다.
다만 한계도 선명하다.
첫째, 실험은 2048과 Sokoban이라는 통제된 게임 환경에 집중되어 있다.
이 결과를 웹 브라우징, 소프트웨어 엔지니어링, 실제 사용자 인터랙션 같은 복잡한 에이전트 업무로 곧바로 일반화하기는 어렵다.
둘째, 공개 weight는 환경별 SFT/RL checkpoint로 분리되어 있어, 하나의 general-purpose planning model release로 보기 어렵다.
셋째, repo에 release/tag가 없고 AReaL, vLLM, 다중 H20 GPU 환경을 전제로 한 학습 절차가 포함되어 있어, 바로 가져다 쓰는 library라기보다 연구 재현 harness에 가깝다.
또 하나 조심할 점은 benchmark 표의 해석이다.
논문은 closed-source 모델과 open-source 모델을 같은 environment interface에서 비교하지만, 2048 점수와 Sokoban box metric은 서로 다른 척도이고, variant별 난이도도 다르다.
따라서 숫자는 “ProAct가 모든 planning 문제를 해결했다”가 아니라, 환경 접지형 distillation과 rollout critic이 controlled interactive benchmark에서 lookahead 품질을 개선했다는 근거로 읽어야 한다.
결론적으로 ProAct는 agent system architecture 논문이라기보다, 에이전트의 미래 상태 추론을 어떻게 학습 신호로 접지할지 보여주는 training 논문이다.
에이전트가 점점 더 긴 horizon과 외부 상태를 다루게 될수록, 단순 reasoning trace보다 실제 environment transition에 연결된 trace가 더 중요해진다.
ProAct의 가치는 바로 그 방향을 구체적인 SFT+RL recipe와 공개 checkpoint bundle로 보여준다는 데 있다.