KoHRM-Text는 이름만 보면 또 하나의 한국어 LLM처럼 보이지만, 공개 저장소를 따라가 보면 조금 다른 성격이 드러난다.
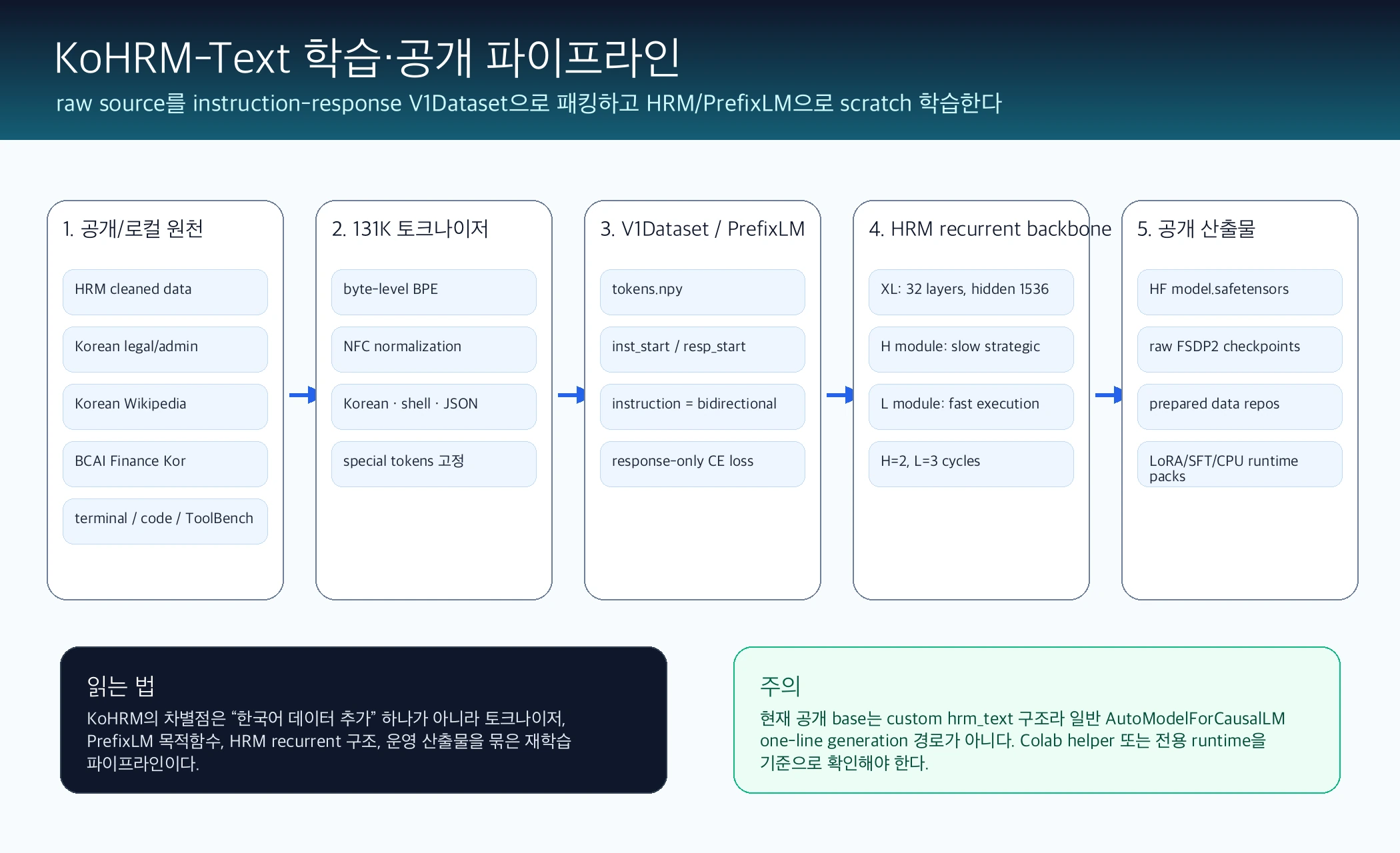
이 프로젝트는 sapientinc/HRM-Text를 포크한 뒤, 원본 HRM-Text의 recurrent architecture와 PrefixLM 학습 구조를 유지하면서 한국어, 영어, 코드, 터미널, 툴콜 데이터를 새 토크나이저와 prepared dataset으로 다시 패킹해 학습하는 작업 저장소다.
중요한 점은 이것이 sapientinc/HRM-Text-1B 가중치를 이어 미세조정한 모델이 아니라는 것이다.
README와 Hugging Face model card 모두 KoHRM-Text-1.4B를 scratch training / scratch-pretrained 계열로 설명한다.
즉 핵심 질문은 “한국어 데이터를 얼마나 넣었나”가 아니라, HRM-Text식 저비용 instruction pretraining 레시피를 한국어·터미널 도메인으로 옮길 때 무엇을 바꾸고 무엇을 유지했나에 가깝다.
이 글에서는 KoHRM-Text를 완성된 챗봇 모델로 보지 않고, 공개된 코드·문서·Hugging Face 산출물에서 확인되는 학습 시스템 실험으로 읽는다.
특히 upstream HRM-Text 논문의 효율 주장은 KoHRM의 최종 성능 주장과 분리해서 봐야 한다.
무엇을 해결하려는가
HRM-Text 논문과 저장소가 던진 메시지는 분명하다.
거대한 raw-text causal LM을 인터넷 규모 코퍼스로 학습하는 표준 경로만이 사전학습의 유일한 길은 아니라는 것이다.
원본 HRM-Text는 hierarchical recurrent model, PrefixLM masking, response-only task-completion objective를 결합해 1B급 모델을 상대적으로 적은 비용으로 처음부터 학습하는 레시피를 제시했다.
KoHRM-Text는 이 문제의식을 한국어와 작업형 데이터 쪽으로 가져온다.
공개 README 기준 목표 도메인은 한국어, 영어, 코드, 터미널, 툴콜이다.
특히 일반 한국어 문서뿐 아니라 법률/행정, 위키, 금융, 터미널 대화, ToolBench식 툴콜, 코드·SWE 궤적을 학습 데이터 흐름 안에 넣는다.
따라서 이 저장소는 “한국어 base 모델”이라기보다, 한국어와 agentic terminal 행동을 함께 겨냥한 HRM-Text 재학습 파이프라인에 가깝다.
또 하나의 문제는 실행 가능성이다. custom architecture를 가진 연구 모델은 weight만 공개해도 일반 사용자에게는 곧바로 쓰기 어렵다.
KoHRM 쪽 문서는 이 점을 숨기지 않는다.
공개 base는 model_type: "hrm_text", architectures: ["HrmTextForCausalLM"]인 custom 구조라, 현재 일반적인 AutoModelForCausalLM.from_pretrained() 경로가 바로 지원되는 상태가 아니다.
대신 Colab T4용 helper, raw checkpoint, prepared data, CPU runtime pack 같은 보조 산출물을 함께 공개해 “무엇이 되고 무엇이 아직 안 되는지”를 문서화한다.
핵심 아이디어 / 구조 / 동작 방식
KoHRM-Text의 첫 번째 축은 instruction pretraining from scratch다.
일반 raw LM 사전학습은 모든 텍스트를 다음 토큰 예측 대상으로 삼지만, KoHRM 문서는 학습 샘플을 instruction/prefix와 response/target으로 나눈다. instruction 구간은 입력 컨텍스트로 읽히지만 loss가 걸리지 않고, response 구간에만 cross entropy loss가 걸린다.
instruction / prefix: bidirectional attention, no loss
response: causal attention, response-only CE loss
이 점 때문에 KoHRM은 이름상 pretraining이지만 전통적 SFT와 목적함수는 닮아 있다.
차이는 이미 완성된 base 위에 작은 curated SFT를 얹는 것이 아니라, 큰 prepared instruction-response 코퍼스를 가지고 처음부터 base 능력 형성 단계 자체를 진행한다는 데 있다.
두 번째 축은 HRM recurrent backbone이다.
공개 config와 model card 기준 표준 모델은 HRM XL 계열로, 약 1,384,120,320 parameters, hidden size 1536, 32 configured layers, 12 attention heads, context length 4,096, vocab size 131,072를 쓴다.
H module은 더 느린 전략적 상태, L module은 더 빠른 실행/정제 상태로 설명되며, 기본 recurrence는 H_cycles=2, L_cycles=3이다.
세 번째 축은 KoHRM 전용 131K byte-level BPE 토크나이저다. upstream HRM-Text 쪽 65K BPE와 달리 KoHRM은 한국어, 영어, 코드, shell/terminal text, JSON/tool-call 형식을 겨냥한 131,072 vocab 토크나이저를 쓴다.
공개 model card의 샘플 측정값은 한국어 일반 텍스트 2.60 chars/token, 한국어 법률 텍스트 2.36 chars/token, 한국어 터미널 instruction 2.18 chars/token, shell command 2.68 chars/token, tool-call JSON 3.32 chars/token, Python code 3.37 chars/token, English 4.40 chars/token이다.
마지막 축은 prepared V1Dataset 중심 운영이다.
공개 prepared-data dataset card는 각 데이터셋이 raw text가 아니라 tokens.npy, inst_start, inst_len, resp_start, resp_len 같은 배열을 가진 HRM-Text V1Dataset 형태라고 설명한다.
즉 이 프로젝트에서 중요한 산출물은 모델 가중치만이 아니라, 원천 데이터가 HRM/PrefixLM 학습 포맷으로 어떻게 변환됐는지를 보여주는 prepared data repos다.
| 구성 요소 | 공개 문서에서 확인되는 값 | 해석 |
|---|---|---|
| 모델 계열 | HRM XL / hrm_text custom architecture |
일반 Transformer wrapper가 아닌 recurrent HRM 계열 |
| 파라미터 | 1,384,120,320 | 131K vocab 때문에 upstream 1B보다 큰 1.4B급 |
| 컨텍스트 | 4,096 tokens | 원본 HRM-Text 레시피와 같은 문맥 길이 축 |
| 토크나이저 | 131,072 vocab byte-level BPE | 한국어·터미널·툴콜 포맷을 겨냥한 재설계 |
| 목적함수 | PrefixLM + response-only CE loss | instruction은 컨텍스트, response만 supervised target |
| 공개 산출물 | HF model, raw checkpoints, prepared data, notebooks, CPU runtime | 단일 model card보다 운영 산출물 묶음에 가까움 |
공개된 근거에서 확인되는 점
가장 먼저 확인할 것은 lineage다.
GitHub README는 KoHRM-Text가 sapientinc/HRM-Text를 기반으로 하지만, upstream weight continuation이 아니라 새 한국어/터미널 131K 토크나이저와 새 data mix로 처음부터 학습한다고 명시한다.
유지한 부분은 HRM recurrent architecture, PrefixLM attention, instruction-response V1Dataset format, response-only loss, Adam-atan2 optimizer, EMA checkpointing, bf16/FSDP2 training path다.
바꾼 부분은 모델 타깃, 토크나이저, data mix, staged continuation, Hugging Face 공개 운영 문서다.
데이터 쪽 공개 근거도 꽤 구체적이다. prepared-data card는 koterm_pretrain_mix_v1, HRM cleaned fast-cap/full stages, local terminal conversations, Korean legal/admin data, Korean Wikipedia, BCAI Finance Kor, ToolBench train, SWE-ZERO/GLM reasoning subsets 등을 나열한다.
예를 들어 local_terminal_conversations_ctx9k_resp6k_v1은 9.39B tokens, BCAI Finance Korean은 857.7M tokens, Korean legal/admin task data는 629.0M tokens, Korean Wikipedia는 462.5M tokens로 적혀 있다.
동시에 ToolBench eval split, Terminal Bench 2 style evaluation data, chi-bench benchmark data 등은 식별되는 범위에서 제외했다고 밝힌다.
학습 운영도 문서화되어 있다.TRAINING_TIME_AND_DATA_FLOW_2026-06-01.md 스냅샷 기준 KoHRM run은 8×H200에서 stage1d fastcap repeat3를 진행 중이었고, global batch는 180,224 token slots/step, 관측 속도는 약 1.01 steps/s로 기록됐다.
같은 문서는 KoHRM의 총 token presentations를 약 166.1B로 잡아 upstream HRM-Text reference의 60B보다 2.77배 크다고 해석한다.
그래서 upstream의 16×H100, 약 46시간 레시피보다 wall-clock이 길어지는 것은 이상 현상이 아니라 데이터량, GPU 수, vocab/model size, staged operation 차이로 설명된다.

Hugging Face model card에서 가장 실용적인 근거는 “base와 terminal fine-tuning lineage를 구분한다”는 점이다. card는 base checkpoint가 TB2-lite terminal next-action JSON에서 약하다고 쓰고, 유용한 terminal behavior는 adapter와 full SFT 위에서 나온다고 설명한다.
공개 표 기준 KoHRM-Text-1.4B-stage4d direct는 TB2-lite score 11.48, terminal-tool-core-r64 LoRA는 29.11, FullSFT LFM25 Terminal ToolBench Epoch2는 45.90으로 적혀 있다.
다만 이것은 KoHRM 전체가 특정 benchmark에서 최종 우위를 확보했다는 뜻이 아니라, base pretraining과 terminal SFT/LoRA 산출물을 분리해서 읽어야 한다는 신호다.
실행 제약도 중요하다. model card는 public repo에 converted weights와 tokenizer가 있지만 아직 Hugging Face trust_remote_code modeling implementation이 없다고 설명한다.
따라서 plain Transformers one-line generation은 지원 경로가 아니며, 현재는 tokenizers.Tokenizer.from_file("tokenizer.json"), safetensors.torch.load_file("model.safetensors"), kohrm_colab_generate.py helper를 쓰는 Colab T4 확인 경로가 제시된다.
별도 CPU runtime pack도 GGUF가 아니라 PyTorch 전용 runtime을 택한다.
이유는 llama.cpp가 HrmTextForCausalLM의 H/L recurrent forward, PrefixLM boundary, tokenizer mapping을 알아야 하기 때문이다.
upstream HRM-Text의 benchmark scatter는 KoHRM을 이해하는 배경으로는 유용하지만, KoHRM 성능 그래프로 읽으면 안 된다.
아래 그림은 HRM-Text 원본이 내세운 효율성 맥락을 보여주는 참고 자료다.
| 공개 근거 | 확인되는 사실 | 주의해서 읽을 부분 |
|---|---|---|
| GitHub README | KoHRM은 HRM-Text fork이며 scratch training이라고 명시 | upstream weight continuation으로 오해하면 안 됨 |
| HF model card | base model, terminal LoRA/SFT lineage, compatibility note 제공 | base checkpoint와 SFT checkpoint 성능을 섞으면 안 됨 |
| prepared-data card | V1Dataset 구조와 주요 token 규모 공개 | 원천 license는 각 source를 따르며 재배포 검토 필요 |
| CPU runtime card | GGUF가 아닌 PyTorch runtime 경로 제시 | custom architecture라 일반 llama.cpp 변환 문제가 아님 |
| HRM-Text paper/repo | low-cost scratch pretraining reference 제공 | 논문 benchmark는 upstream HRM-Text 결과이지 KoHRM 결과가 아님 |
실무 관점에서의 해석
KoHRM-Text에서 흥미로운 부분은 “한국어 모델 하나 더”가 아니라 학습 방식의 이식 실험이다.
HRM-Text가 주장한 효율성은 architecture와 objective의 co-design에서 나온다.
KoHRM은 이 co-design을 그대로 가져오되, 토크나이저와 데이터 구성을 한국어·터미널·툴콜 도메인에 맞춰 다시 만든다.
이 조합은 한국어 agent 모델을 만들 때 raw web-scale pretraining 외의 경로가 있는지를 탐색한다는 점에서 의미가 있다.
특히 터미널/툴콜 데이터가 단순 부가 데이터가 아니라 학습 포맷과 연결되어 있다는 점이 중요하다.
PrefixLM 구조에서는 terminal log, 파일 내용, tool schema 같은 입력을 prefix로 읽고, response만 supervised target으로 맞힌다.
이것은 agent runtime에서 흔히 보는 “긴 상태를 읽고 다음 행동을 내는” 패턴과 잘 맞는다.
KoHRM의 terminal fine-tuning lineage가 base와 별도 공개되는 것도 이 방향을 보여준다.
반대로 아직 실무 도입 모델로 읽기에는 제약이 분명하다.
첫째, 공개 base는 final aligned instruct model이 아니다. model card도 full planned continuation, final SFT, safety tuning, final public benchmark가 끝났다고 말하지 않는다.
둘째, custom hrm_text architecture 때문에 일반 Transformers, GGUF, llama.cpp ecosystem과 바로 맞물리지 않는다.
셋째, prepared data에는 다양한 공개·로컬·license-sensitive source가 섞여 있으므로 downstream 사용자는 license와 redistribution 조건을 다시 확인해야 한다.
따라서 KoHRM-Text를 가장 생산적으로 읽는 방식은 “지금 바로 쓸 한국어 챗봇”이 아니라, 작은 팀이 한국어/터미널 특화 foundation model 실험을 어떤 산출물 단위로 공개할 수 있는가에 대한 사례로 보는 것이다.
코드, model card, dataset card, raw checkpoint, Colab helper, CPU runtime pack이 함께 움직인다.
이 묶음은 benchmark headline보다 더 실무적인 정보를 준다.
어떤 데이터가 들어갔는지, 어떤 포맷으로 패킹됐는지, 어떤 generation 경로가 아직 막혀 있는지, 어떤 fine-tuning lineage에서 terminal behavior가 개선됐는지가 공개 문서에 남아 있기 때문이다.
이 저장소의 다음 관찰 포인트도 명확하다. trust_remote_code 또는 표준 wrapper가 추가되어 일반 inference 경로가 열리는지, terminal/full-SFT checkpoint의 평가가 더 넓은 benchmark로 확장되는지, 한국어 법률·금융·위키 데이터가 실제 downstream 품질로 이어지는지, 그리고 HRM recurrent 구조가 한국어·agentic workload에서 dense Transformer 대비 어떤 비용/품질 trade-off를 보이는지가 핵심이다.
그 전까지 KoHRM-Text는 최종 성능 주장보다 학습 파이프라인과 공개 운영 방식이 더 중요한 프로젝트다.