Mixture-of-Experts(MoE)에서 라우터는 작은 행렬처럼 보이지만 실제로는 모델 품질과 효율을 동시에 좌우한다.
토큰마다 어떤 expert를 태울지 결정하는 순간, sparse model의 계산 예산과 표현력이 모두 라우터의 dot product에 걸리기 때문이다.
그런데 기존 MoE 라우터는 각 row가 특정 expert의 proxy처럼 쓰인다는 사실에 비해, 그 row가 실제 expert weight의 구조를 잘 담도록 강제하는 원리는 상대적으로 약했다.
Redesign Mixture-of-Experts Routers with Manifold Power Iteration는 이 지점을 정면으로 건드린다.
저자들은 라우터 row를 그냥 학습 가능한 벡터로 두지 말고, 대응되는 expert weight matrix의 principal singular direction 쪽으로 정렬하자고 제안한다.
이를 매 step의 비싼 SVD로 풀지 않고, power iteration 한 번과 row-wise L2 retraction으로 근사하는 방식이 Manifold Power Iteration, 즉 MPI다.
이 논문은 새 MoE 모델 릴리스라기보다 라우터 설계 원리에 가깝다. arXiv와 Hugging Face Papers 표면 기준으로 별도 공식 GitHub, checkpoint, project page 링크는 확인되지 않았고, 공개 근거는 논문 본문·HTML·HF Papers 요약에 집중되어 있다.
그 대신 실험은 1B, 3B, 11B 규모 pretraining으로 꽤 넓게 제시된다.
무엇을 해결하려는가
표준 MoE layer에서 라우터 행렬 R의 각 row는 expert 하나를 대표한다.
입력 token representation x와 R의 row를 내적하고, Top-K와 softmax를 거쳐 활성화할 expert를 고른다.
이 설계는 직관적이지만, 한 가지 암묵적 가정을 둔다.
라우터 row가 정말로 그 expert의 특성을 대표한다는 가정이다.
논문의 문제 제기는 여기서 시작된다.
Expert는 GLU-style feed-forward block으로, gate/projection/output weight matrix를 갖는다.
그런데 라우터 row는 학습 중에 loss signal을 받더라도, 해당 expert weight matrix의 주요 방향을 압축해 담으라는 직접적 제약을 받지 않는다.
결과적으로 token-expert affinity가 덜 정밀해지고, convergence와 downstream 성능, expert load balancing에 손실이 생길 수 있다.
저자들은 이를 matrix approximation 관점에서 다시 쓴다.
하나의 벡터가 행렬의 특성을 가장 잘 요약하려면 principal singular direction과 맞춰지는 것이 자연스럽다.
따라서 라우터 row R[i]를 대응 expert weight Wg[i]의 dominant direction으로 끌어당기면, 그 row가 expert proxy로서 더 의미 있는 역할을 할 수 있다는 주장이다.
핵심 아이디어 / 구조 / 동작 방식
MPI는 이름은 무겁지만 실제 계산 흐름은 단순하다.
각 expert i에 대해 라우터 row R[i]와 expert gate weight Wg[i]를 사용한다.
먼저 power iteration에 해당하는 matrix-vector product를 수행한다.
Rhat[i] = R[i] Wg[i] Wg[i]^T
이 단계는 R[i]를 Wg[i]의 principal singular direction 쪽으로 이동시키는 근사다.
정확한 SVD를 매 training step마다 수행하면 너무 비싸므로, 저자들은 한 번의 power iteration만 적용한다.
논문은 반복적인 학습 step을 거치며 이 row가 점진적으로 principal direction을 추적한다고 설명한다.
두 번째 단계는 retraction이다.
Power iteration만 두면 row norm이 커지거나 작아져 라우팅 logit scale이 흔들릴 수 있다.
그래서 MPI는 row를 고정 norm C로 다시 정규화한다.
Rprime[i] = C * Rhat[i] / ||Rhat[i]||
이후 라우팅은 기존과 동일하게 softmax(TopK(x Rprime^T))로 진행된다.
즉 MPI는 Top-K gating, expert 계산, inference interface를 바꾸는 방식이 아니라, 라우터 weight를 expert weight geometry와 더 강하게 결합하는 방식이다.
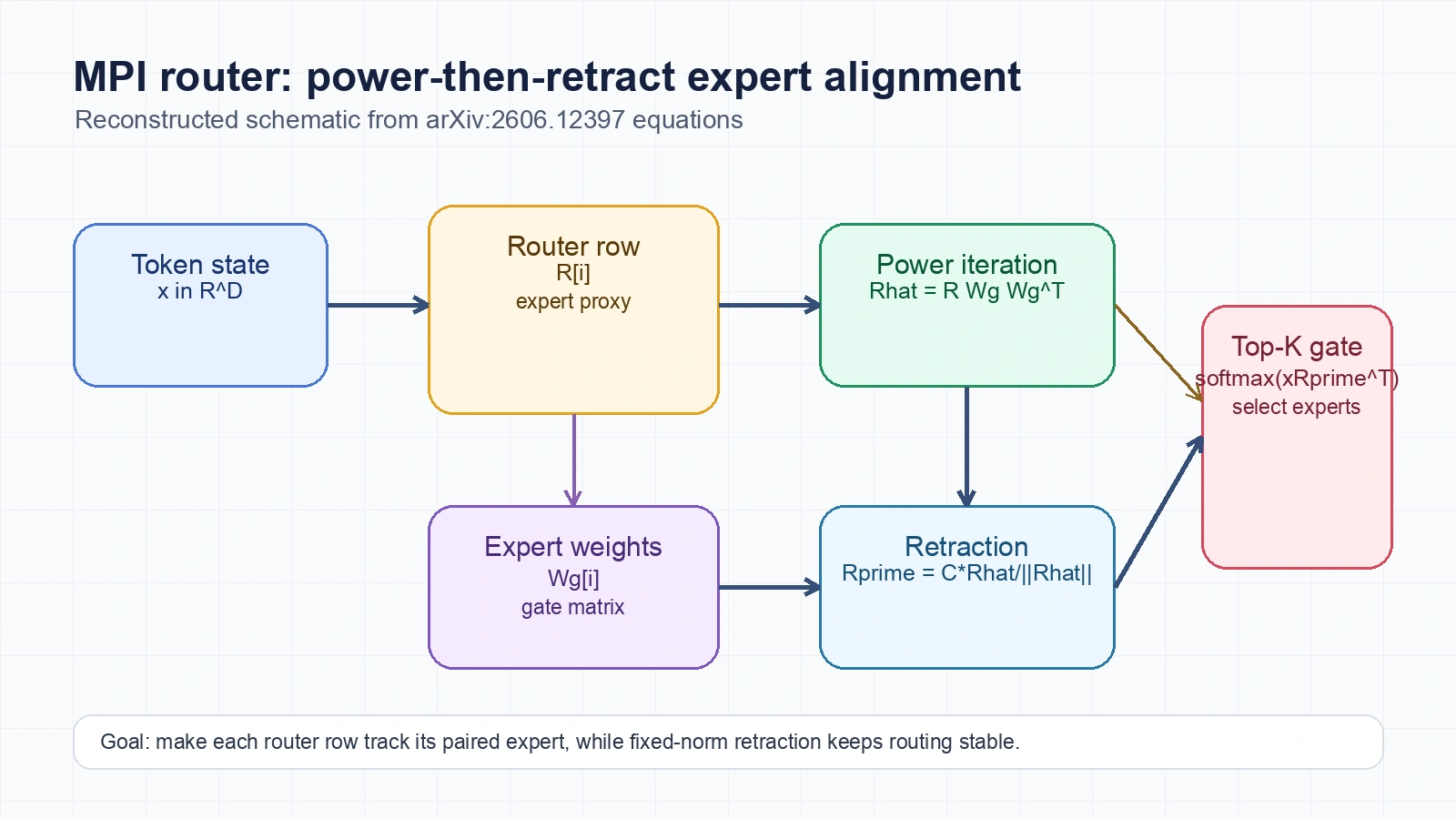
여기서 retraction은 단순한 수치 안정화 이상의 의미가 있다.
라우터 row norm이 커진 expert는 더 큰 logit을 받기 쉽고, 그 결과 특정 expert가 과도하게 선택될 수 있다.
MPI는 row norm을 일정하게 맞춰 이런 scale-induced bias를 줄이고, load balancing에도 간접적으로 도움을 준다고 해석할 수 있다.
공개된 근거에서 확인되는 점
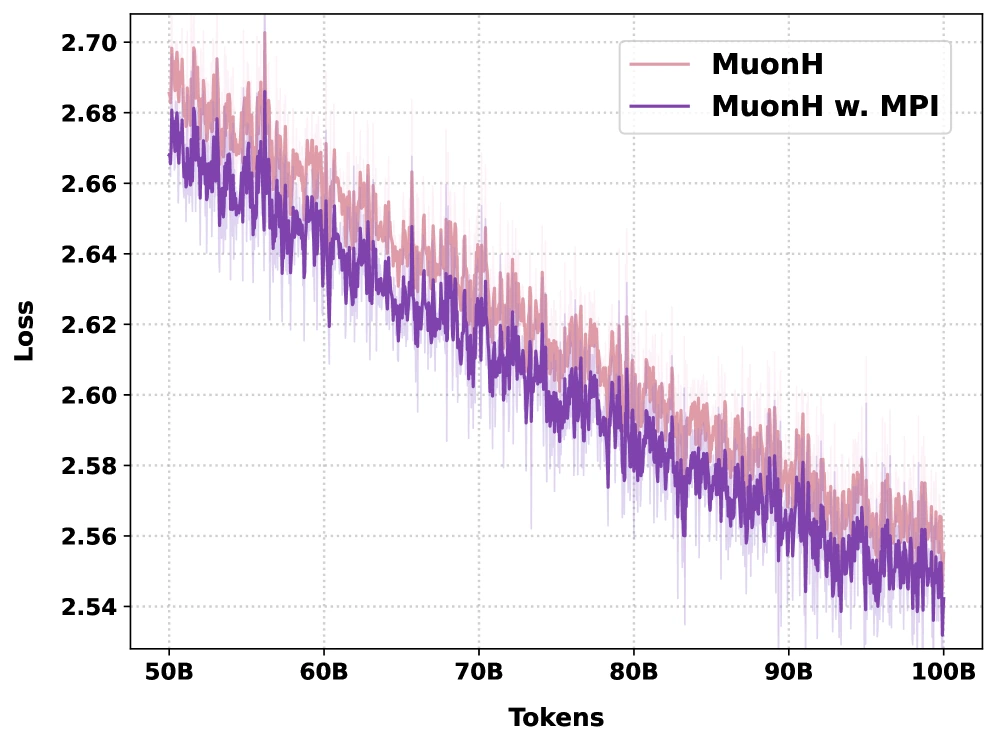
첫 번째 근거는 1B 규모에서 optimizer가 바뀌어도 MPI 효과가 유지된다는 점이다.
저자들은 AdamW, AdamH, Muon, MuonH 네 설정에서 100B tokens pretraining을 수행하고, 25개 downstream benchmark 평균 정확도를 비교한다.
평균 정확도는 AdamW에서 42.26→43.56, AdamH에서 42.59→43.93, Muon에서 43.01→43.55, MuonH에서 42.78→43.98로 올라간다.
개선폭은 각각 +1.30, +1.34, +0.54, +1.20 point다.
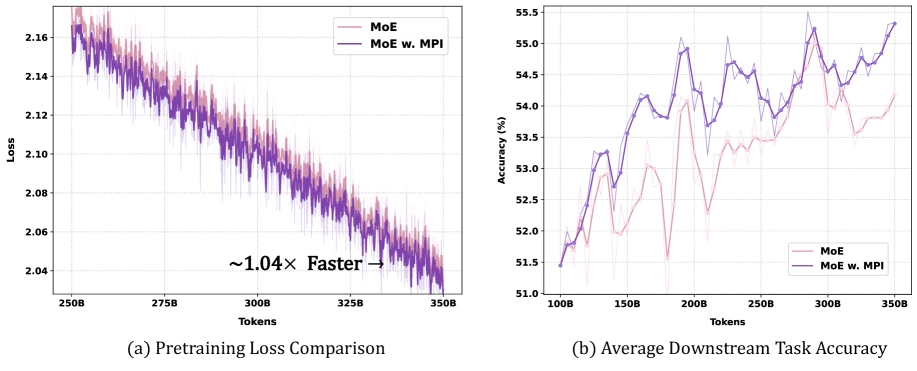
두 번째 근거는 3B와 11B scale-up 실험이다.
모든 모델은 FineWeb-Edu에서 샘플링한 350B tokens로 pretrain되고, 이후 100B tokens midtraining을 거친다.
Perplexity(bits per byte) 기준으로 3B에서는 validation 0.764→0.754, math 1.688→1.581, code 1.376→1.296으로 개선된다.
11B에서는 validation 0.728→0.723, math 1.852→1.581, code 1.263→1.259다.
도전적 benchmark 묶음에서도 평균이 오른다.
3B는 ARC-C, MMLU, TriviaQA, NaturalQs, BBH, GSM8K, MBPP 평균이 36.37→38.70으로 +2.33 point, 11B는 40.92→42.76으로 +1.84 point 개선된다.
다만 모든 항목이 일방적으로 오르지는 않는다.
예를 들어 11B MBPP는 45.12→44.87로 소폭 낮아진다.
따라서 이 결과는 “MPI가 모든 task를 무조건 올린다”보다, 라우터 alignment가 평균적으로 convergence와 downstream 효율을 개선한다는 쪽으로 읽는 편이 안전하다.
세 번째 근거는 라우터-expert alignment 자체를 측정한 후분석이다.
논문은 Rprime[i]가 Wg[i]에 얼마나 잘 정렬되는지 나타내는 normalized projection 값 lambda를 layer별로 보고한다.
12개 layer 평균을 계산하면 vanilla MoE는 약 0.269, MPI는 약 0.658이다.
즉 성능 개선이 단순한 training noise가 아니라, 저자들이 목표로 삼은 geometry 변화와 함께 나타난다는 점을 보여 주려는 분석이다.
| 관찰 축 | Vanilla MoE | MoE w. MPI | 해석 |
|---|---|---|---|
| 1B 25-task 평균 정확도, AdamW | 42.26 | 43.56 | +1.30 point |
| 1B 25-task 평균 정확도, MuonH | 42.78 | 43.98 | +1.20 point |
| 3B challenging benchmark 평균 | 36.37 | 38.70 | +2.33 point |
| 11B challenging benchmark 평균 | 40.92 | 42.76 | +1.84 point |
| 3B MaxVioBatch | 1.133 | 1.024 | batch-level expert imbalance 감소 |
| 3B MaxVioGlobal | 0.964 | 0.711 | global expert imbalance 감소 |
12-layer 평균 lambda |
0.269 | 0.658 | router row와 expert principal direction 정렬 강화 |
효율 면에서도 논문은 MPI가 현실적인 비용 안에 들어온다고 주장한다.
11B pretraining에서 vanilla MoE throughput은 하루 34.97B tokens이고, MPI slowdown은 0.2%로 보고된다.
또한 MPI는 추가 communication overhead가 없고, inference 시에는 모델 로드 시점에 power iteration으로 router weight를 미리 계산할 수 있어 inference overhead가 없다고 설명한다.
이 대목은 실무적으로 중요하다.
라우터 설계 개선이 serving path를 복잡하게 만들지 않는다면, 기존 MoE inference stack과의 호환성이 훨씬 좋아진다.
Ablation이 말하는 것
MPI에서 중요한 선택은 두 가지다.
첫째, power iteration을 실제로 넣을 것인가.
둘째, retraction으로 norm을 고정할 것인가.
논문은 ablation에서 둘 다 필요하다고 주장한다.
특히 retraction 없이 power iteration만 쓰면 router norm scale이 흔들리며 학습 안정성이 깨질 수 있고, AdamW나 Muon처럼 별도 weight constraint가 없는 optimizer에서 문제가 더 커질 수 있다고 설명한다.
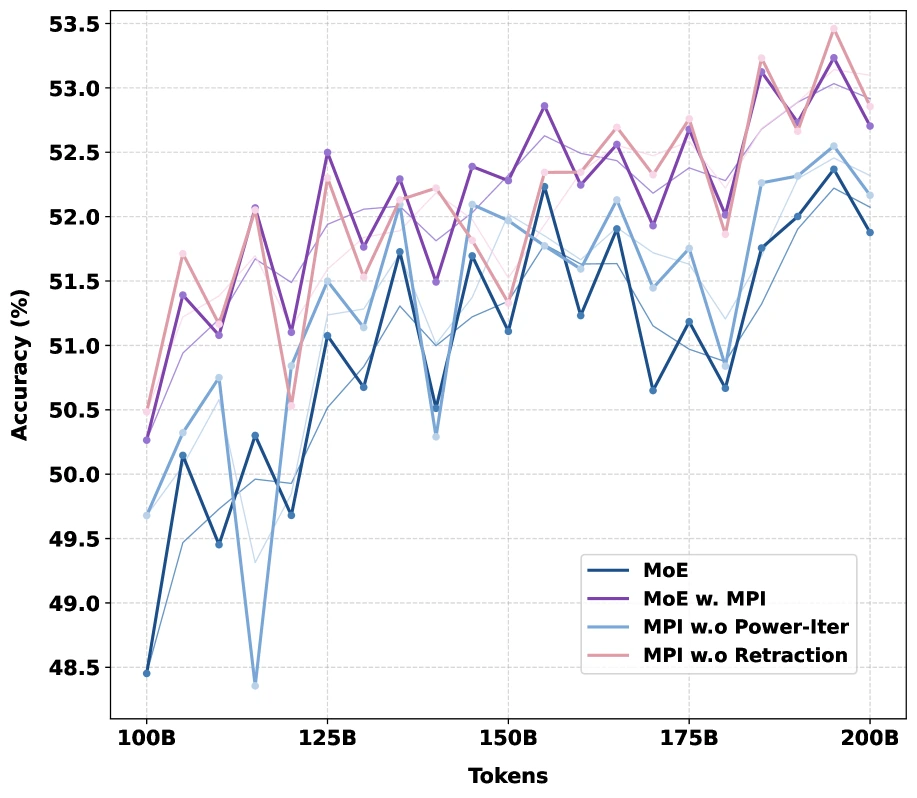
Cprime 값에 대한 실험도 흥미롭다.
Validation perplexity는 Cprime=1에서 0.8896, 2에서 0.8547, 4에서 0.8533, 8에서 0.8563이며, vanilla MoE는 0.8884로 보고된다.
너무 작은 norm은 baseline과 큰 차이가 없고, 너무 큰 norm은 다시 scale 문제를 만들 수 있다.
논문 설정에서는 4 근처가 가장 좋지만, 이 값은 모델 구조와 expert 수, optimizer에 따라 다시 검증해야 할 하이퍼파라미터로 보는 것이 맞다.
또한 expert weight choice에 대한 실험도 있다.
후보는 Wg, Wp, Wo인데, 저자들은 큰 차이는 없지만 현재 실험에서는 Wg가 약간 유리해 기본값으로 택했다고 적는다.
이는 MPI가 특정 matrix 하나에만 원리적으로 묶인다기보다, expert를 대표할 weight subspace를 어디서 잡을지 선택하는 설계 공간을 남겨 둔다는 뜻이다.
실무 관점에서의 해석
이 논문의 장점은 MoE 라우터를 “학습되니까 괜찮다”로 두지 않고, expert matrix와의 관계를 명시적인 geometry 문제로 바꾼 데 있다.
MoE scaling에서는 expert 수, capacity factor, load-balancing loss, communication pattern 같은 시스템 이슈가 자주 주목받는다.
MPI는 그보다 더 안쪽에서, expert를 대표한다는 라우터 row의 의미 자체를 어떻게 정의할 것인가를 묻는다.
실무적으로는 세 가지 함의가 있다.
첫째, MoE 성능 개선이 꼭 더 복잡한 router network나 새로운 dispatch system을 뜻하지는 않는다.
MPI는 기존 linear router shape를 유지하면서 weight update 쪽에 구조적 bias를 넣는다.
둘째, 이 방식은 inference path를 거의 건드리지 않기 때문에, pretraining recipe 개선으로 흡수하기 쉽다.
셋째, load balancing이 auxiliary loss만의 문제가 아니라 router row norm과 expert representation alignment의 문제일 수도 있음을 보여 준다.
반대로 한계도 명확하다.
공개된 표면은 아직 paper 중심이다.
공식 code release나 checkpoint bundle이 보이지 않으므로, 재현성은 논문 구현 설명과 TorchTitan·MegaBlocks 기반 training setup에 의존한다.
또 실험은 저자들이 선택한 MoE 구조, FineWeb-Edu, MuonH 중심 대규모 설정, OLMES 평가 묶음 안에서 읽어야 한다.
특히 일부 task에서 개선이 작거나 음수인 항목이 있기 때문에, MPI를 모든 sparse model에 바로 넣는 보편적 해법으로 보는 것은 이르다.
그럼에도 이 작업은 MoE router 연구의 좋은 방향을 보여 준다.
Sparse scaling의 병목은 expert를 많이 두는 것만으로 풀리지 않는다.
어떤 token을 어떤 expert에 보낼지, 그리고 그 결정을 내리는 row가 실제 expert의 어떤 성질을 대변해야 하는지가 중요하다.
MPI는 그 질문에 “전문가 행렬의 주성분 방향”이라는 비교적 명확한 답을 제시한다.
대형 MoE pretraining에서 작은 training overhead와 zero inference overhead가 정말 유지된다면, 이런 router geometry 설계는 다음 세대 sparse model recipe에서 꽤 실용적인 한 줄이 될 가능성이 있다.