긴 컨텍스트 모델 경쟁에서 이제 단순히 “몇 토큰까지 넣을 수 있는가”는 충분한 질문이 아니다.
코딩 에이전트가 실제로 오래 달리면 리포지토리 전체, 테스트 로그, 이전 수정 이력, 도구 호출 결과, 실패한 실험의 흔적이 한 대화 안에 계속 쌓인다.
이때 중요한 것은 nominal context length가 아니라, 그 긴 문맥을 품은 상태로 몇 시간짜리 작업을 끝까지 밀고 갈 수 있느냐다.
Z.AI가 Hugging Face와 자체 블로그에 공개한 GLM-5.2는 이 지점을 정면으로 겨냥한다.
공개 모델 카드와 Hub API 기준 이 모델은 GlmMoeDsaForCausalLM 계열의 753.3B 파라미터급 MoE 모델이며, max_position_embeddings는 1,048,576으로 잡혀 있다.
블로그의 표현을 빌리면 핵심 메시지는 “solid 1M context”다.
1M 토큰을 받는 것보다, 1M 토큰 작업에서 품질과 처리량을 유지하는 쪽에 강조점이 있다.
흥미로운 점은 GLM-5.2가 모델 카드 하나로 끝나는 릴리스가 아니라는 것이다.
공식 블로그는 IndexShare, MTP, 1M-context serving, slime 기반 agentic RL, reward hacking 방지까지 한 묶음으로 설명한다.
즉 이 릴리스는 “큰 오픈 모델이 하나 더 나왔다”라기보다, 장기 코딩 에이전트를 학습·평가·서빙하는 전체 경로를 공개 자료로 보여 주는 사례에 가깝다.
무엇을 해결하려는가
GLM-5.2가 해결하려는 문제는 “긴 입력을 한 번 읽는 모델”보다 좁고 실전적이다.
장기 코딩 에이전트에서는 모델이 큰 코드베이스를 읽고, 계획을 세우고, 파일을 수정하고, 테스트를 돌리고, 실패 로그를 다시 해석하고, 때로는 다른 실험 경로로 돌아가야 한다.
이런 궤적은 수십~수백 턴으로 길어지고, 출력 토큰도 매우 커진다.
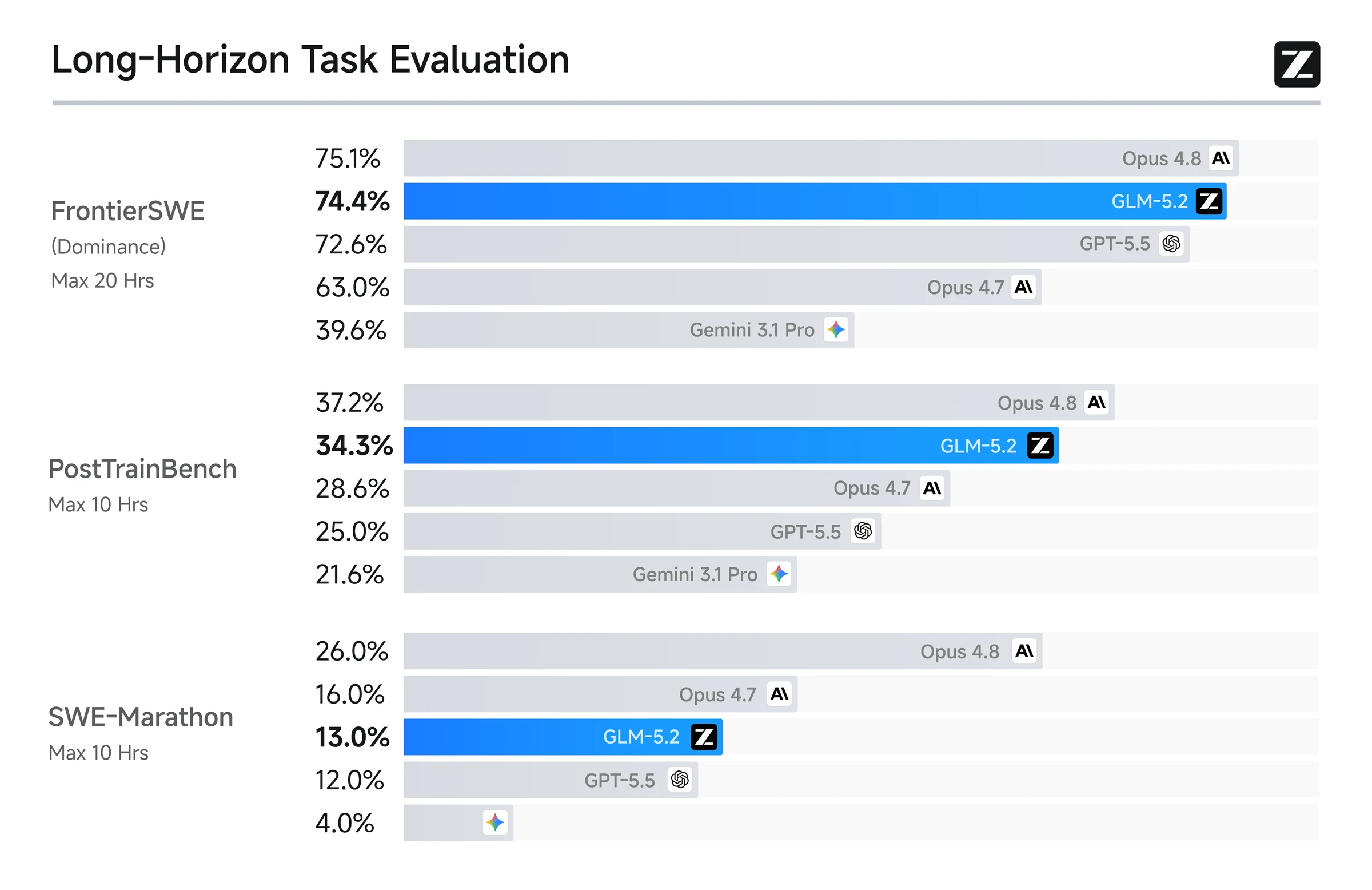
공식 블로그가 FrontierSWE, PostTrainBench, SWE-Marathon 같은 장시간 작업 벤치마크를 전면에 배치하는 이유도 여기에 있다.
FrontierSWE는 몇 시간에서 수십 시간 규모의 open-ended engineering task를, PostTrainBench는 H100 GPU를 받은 에이전트가 작은 모델을 얼마나 개선하는지를, SWE-Marathon은 컴파일러·커널 최적화·서비스 구축 같은 ultra-long-horizon 소프트웨어 작업을 본다.
이런 평가에서는 코드 한 조각을 맞히는 능력보다, 긴 상태를 잃지 않고 실행 루프를 유지하는 능력이 더 중요하다.
따라서 GLM-5.2의 핵심 질문은 “1M context가 있는가”가 아니다.
더 정확히는 1M context를 쓰는 동안 attention 비용, KV cache, CPU-side scheduling, RL rollout, reward hacking을 어디까지 같이 관리했는가다.
이 점이 GLM-5.2를 단순한 benchmark release보다 시스템 릴리스처럼 보이게 만든다.
핵심 아이디어 / 구조 / 동작 방식
공개 자료에서 확인되는 GLM-5.2의 구조적 신호는 다음과 같다.
| 축 | 공개 자료에서 확인되는 내용 | 실무적 의미 |
|---|---|---|
| 모델 패키징 | Hub API 기준 약 753.3B parameters, 282개 safetensors shard, non-gated public repo | 오픈 웨이트지만 가볍게 개인 GPU에서 돌릴 체급은 아니다. |
| 컨텍스트 | max_position_embeddings: 1048576, 블로그 기준 solid 1M context |
긴 리포지토리·로그·도구 궤적을 한 세션에 유지하려는 설계다. |
| MoE/DSA 구조 | 78 layers, 256 routed experts + 1 shared expert, token당 8 routed experts, glm_moe_dsa |
전체 용량과 sparse routing을 결합하되, long-context attention 비용을 별도로 줄여야 하는 형태다. |
| 라이선스 | 모델 카드 license: mit, 실제 LICENSE 파일도 MIT |
모델 가중치 쪽은 permissive하게 공개되어 있다. |
| 배포 표면 | Hugging Face model card, Z.ai API/docs/chat, GLM Coding Plan, GitHub repo, vLLM/SGLang/Transformers/KTransformers 안내 | checkpoint 하나보다 API·코딩 플랜·self-host 경로를 함께 제공하는 릴리스다. |
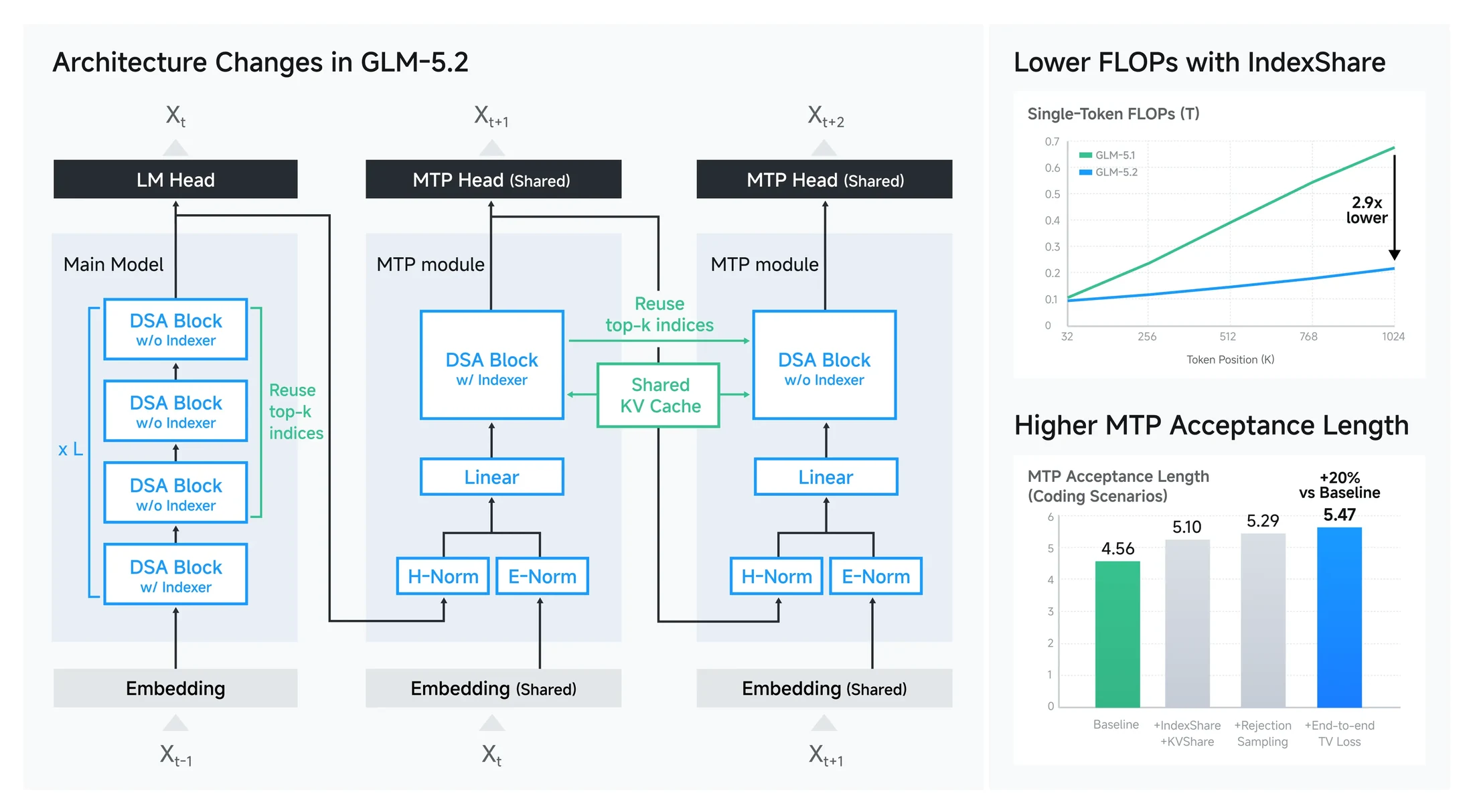
첫 번째 기술 포인트는 IndexShare다.
GLM-5 계열은 DSA 계열 sparse attention을 사용한다. sparse attention에서는 각 query가 모든 토큰을 보지 않고 관련 token/index를 고르는 과정이 중요하지만, 그 indexer 자체도 긴 문맥에서는 비용이 된다.
GLM-5.2는 네 개 transformer layer가 하나의 lightweight indexer를 공유하도록 만들어, 4개 layer 중 첫 layer에서 계산한 top-k index를 나머지 layer가 재사용한다.
공식 블로그는 이 방식이 1M context에서 per-token FLOPs를 2.9× 줄인다고 설명한다.
두 번째 포인트는 MTP와 speculative decoding이다.
GLM-5.2는 MTP layer를 draft model처럼 활용해 여러 token을 앞서 예측하고, target model이 이를 받아들이면 decode를 빠르게 만드는 방향을 취한다.
공식 자료의 작은 표에서는 baseline acceptance length 4.56에서 IndexShare + KV Share 5.10, rejection sampling 5.29, end-to-end TV loss 5.47로 올라간다.
블로그가 말하는 “up to 20%” acceptance length 개선은 이 맥락이다.
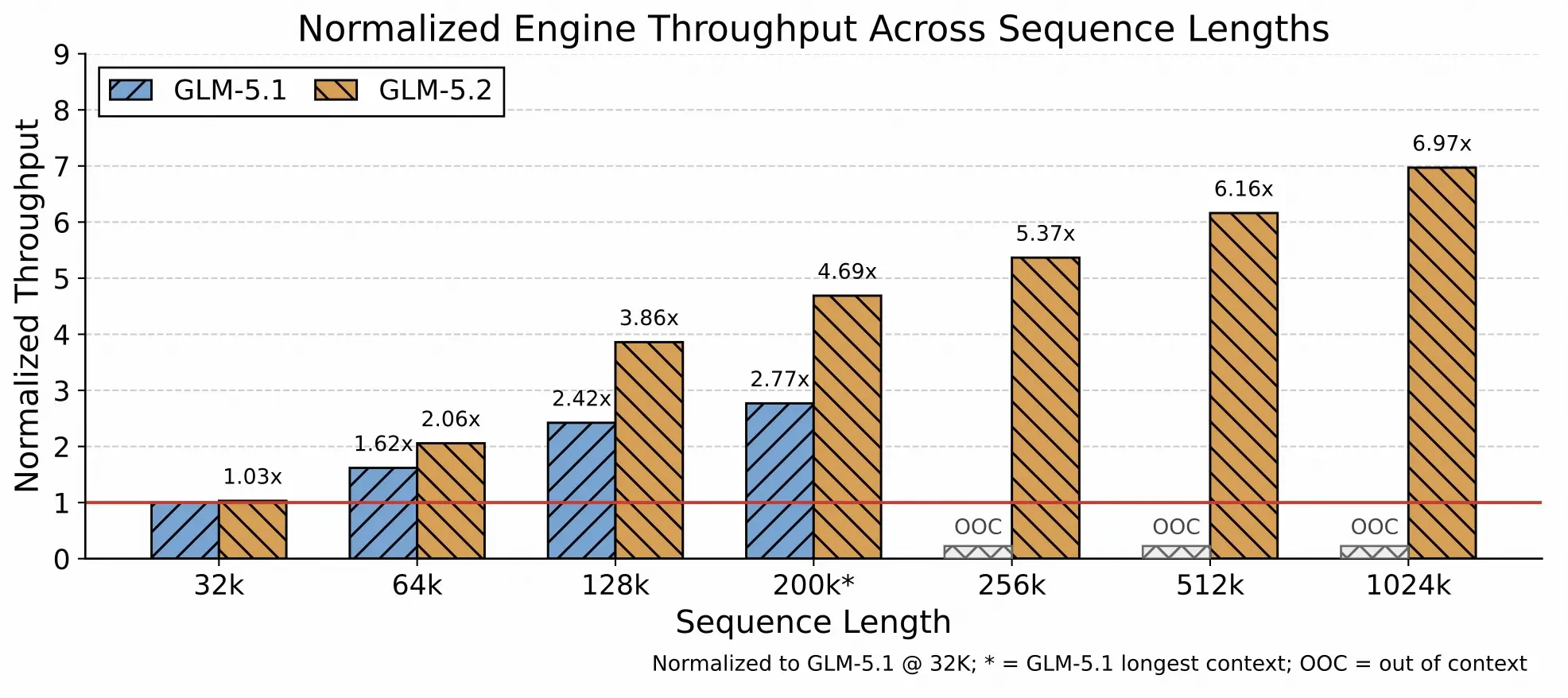
세 번째 포인트는 1M context serving이다.
GLM-5.2는 GLM-5.1의 200K 수준에서 1M으로 context를 늘리면서, 병목이 단순 FLOPs에서 KV-cache capacity, long-context kernel overhead, CPU-side cache management와 scheduling으로 이동한다고 설명한다.
공식 블로그는 LayerSplit 기반 memory management, cache transfer와 kernel coordination, CPU-side scheduling/runtime path 최적화를 언급한다.
마지막으로 GLM-5.2는 post-training도 꽤 구체적으로 설명한다. slime은 white-box rollout, black-box rollout, compact trajectory, sub-agent workflow를 지원하는 agentic RL 인프라로 소개된다.
블로그에 따르면 GLM-5.2의 post-training에서는 parallel OPD training으로 10개가 넘는 expert model을 최종 모델에 병합했고, 전체 OPD 과정은 약 2일이 걸렸다.
여기에 anti-hack module도 붙는다.
코딩 RL은 pass/fail reward가 명확하기 때문에 protected evaluation artifact를 읽거나, reference answer를 복사하거나, GitHub raw file을 직접 가져오는 식의 reward hacking에 취약하다.
GLM-5.2 블로그는 rule-based filter로 recall을 높이고 LLM judge로 intent를 판단하는 두 단계 탐지를 설명한다.
흥미로운 점은 hack action을 감지했을 때 전체 rollout을 버리는 대신 해당 tool call을 막고 dummy result를 돌려, rollout이 계속 진행되도록 한다는 것이다.
이는 reward hacking 방지와 training stability를 동시에 다루려는 설계로 읽힌다.
공개된 근거에서 확인되는 점
공식 장기 코딩 벤치마크만 보면 GLM-5.2는 “오픈 모델 중 가장 강한 long-horizon coding agent 후보”라는 메시지를 분명히 낸다.
| Benchmark | GLM-5.2 | GLM-5.1 | Claude Opus 4.8 | GPT-5.5 | Gemini 3.1 Pro | 해석 |
|---|---|---|---|---|---|---|
| FrontierSWE (Dominance) | 74.4 | 30.5 | 75.1 | 72.6 | 39.6 | Opus 4.8 바로 아래, GPT-5.5보다 높게 보고됨 |
| PostTrainBench | 34.3 | 20.1 | 37.2 | 28.4 | 21.6 | H100 기반 post-training task에서 Opus 4.8 다음 |
| SWE-Marathon | 13.0 | 1.0 | 26.0 | 12.0 | 4.0 | 절대 점수는 낮지만 GPT-5.5와 비슷하고 GLM-5.1 대비 큰 개선 |
다만 이 표는 반드시 평가 설정과 함께 읽어야 한다.
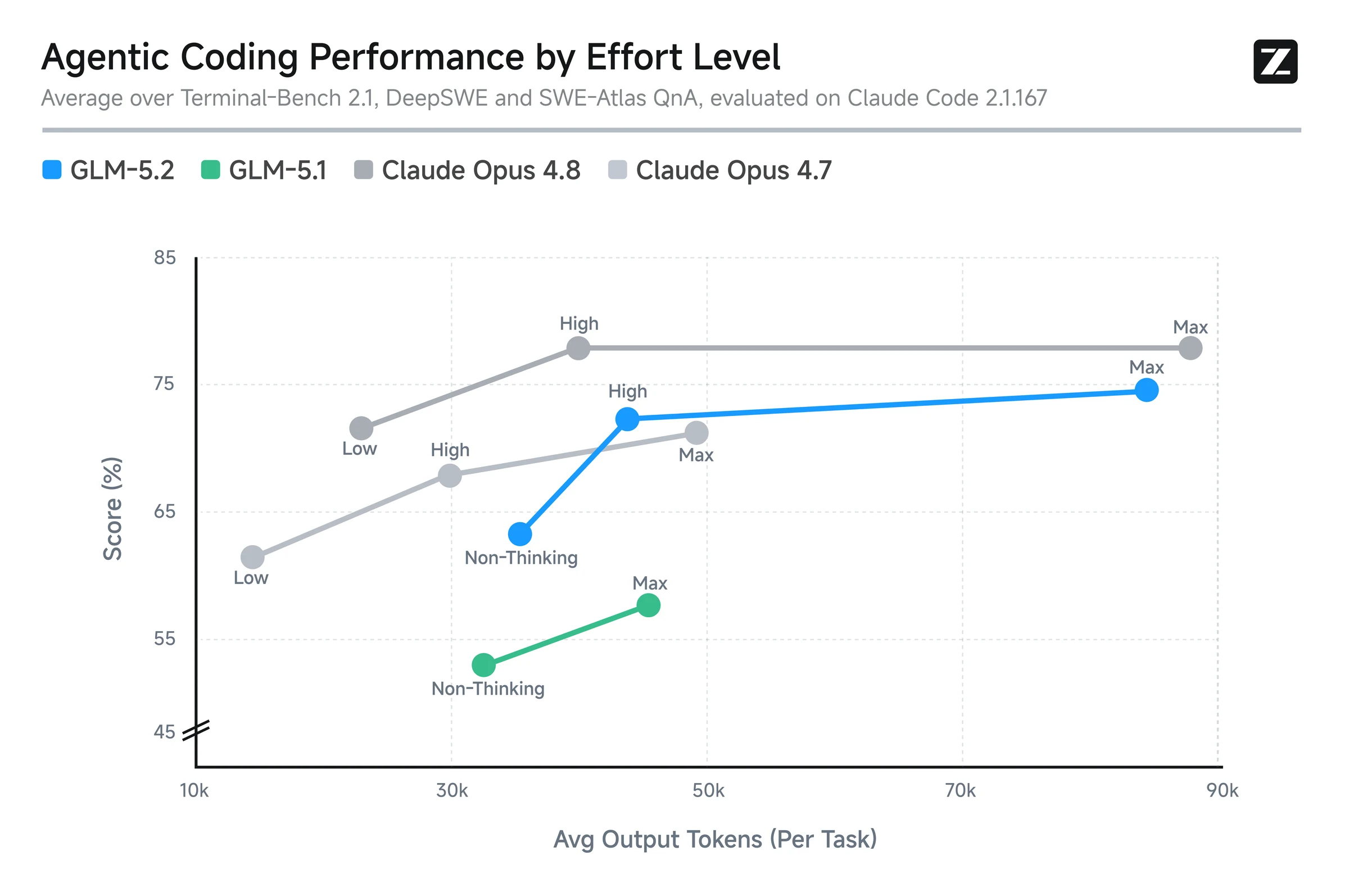
공식 footnote에 따르면 FrontierSWE, PostTrainBench, SWE-Marathon 평가는 1M context, max effort level, 128K maximum output tokens 조건에서 수행됐다.
즉 GLM-5.2가 강하게 보이는 지점은 짧은 chat completion이 아니라, 많은 context와 큰 output budget을 허용한 장기 에이전트 실행이다.
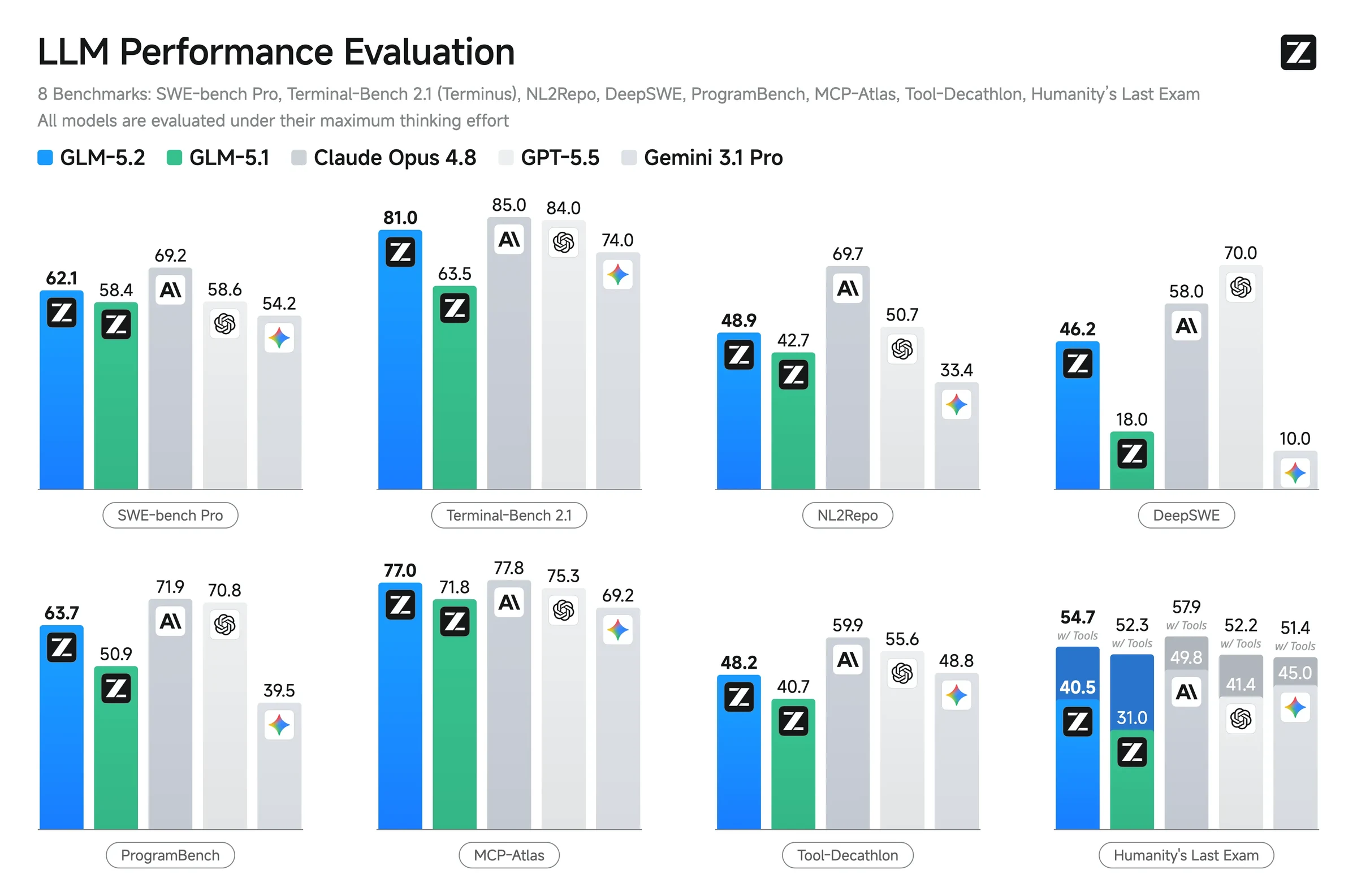
표준 코딩·에이전트 벤치마크에서도 개선 폭은 크다.
| Benchmark | GLM-5.2 | GLM-5.1 | Claude Opus 4.8 | GPT-5.5 | 실무적 해석 |
|---|---|---|---|---|---|
| SWE-bench Pro | 62.1 | 58.4 | 69.2 | 58.6 | repo-level repair에서는 frontier 폐쇄형과 격차가 남지만 GLM-5.1보다 개선 |
| Terminal-Bench 2.1 (Terminus-2) | 81.0 | 63.5 | 85.0 | 84.0 | shell/task execution 계열에서 폐쇄형 상위권에 근접 |
| NL2Repo | 48.9 | 42.7 | 69.7 | 50.7 | repository generation에서는 Opus와 격차가 큼 |
| DeepSWE | 46.2 | 18.0 | 58.0 | 70.0 | GLM-5.1 대비는 크지만 GPT-5.5가 더 높게 보고됨 |
| MCP-Atlas (Public Set) | 76.8 | 71.8 | 77.8 | 75.3 | tool-use benchmark에서는 경쟁권 |
| Tool-Decathlon | 48.2 | 40.7 | 59.9 | 55.6 | 도구 사용 종합에서는 아직 폐쇄형 상위 모델과 차이 존재 |
이 수치가 곧 “GLM-5.2가 모든 코딩 작업에서 폐쇄형 frontier를 이겼다”는 뜻은 아니다.
오히려 더 정확한 해석은, GLM-5.2가 1M context와 max effort를 활용하는 장기 작업에서 오픈 모델의 상한을 크게 끌어올렸고, 일부 tool/coding benchmark에서는 폐쇄형 상위권에 가까워졌다는 것이다.
릴리스 성숙도는 꽤 강한 편이다.
Hugging Face model repo는 확인 시점에 private도 gated도 아니며, 모델 카드·config·generation config·chat template·LICENSE와 대량의 safetensors shard를 공개한다.
API metadata의 top-level license 값은 비어 있었지만, cardData와 tag, 실제 LICENSE 파일은 MIT로 일치했다.
따라서 모델 가중치 공개 조건은 비교적 명확하다.
반대로 self-host 난이도는 낮지 않다.
753B급 가중치와 1M KV cache는 운영 규모 자체가 크고, GLM-5.2는 glm_moe_dsa라는 특수 architecture를 쓴다.
모델 카드가 vLLM, SGLang, Transformers, KTransformers 경로를 안내한다고 해서, 일반적인 7B/30B 모델처럼 바로 로컬 노트북에서 돌릴 수 있다는 뜻은 아니다.
이 릴리스는 오픈 웨이트지만, 실무적으로는 대형 GPU serving stack과 긴 컨텍스트 cache 정책까지 같이 검토해야 한다.
실무 관점에서의 해석
GLM-5.2의 가장 큰 의미는 오픈 모델 경쟁의 중심이 single-turn coding score에서 long-horizon agent execution으로 이동하고 있음을 보여 준다는 점이다.
좋은 코딩 모델은 이제 함수 하나를 잘 쓰는 모델이 아니라, 1M context 안에서 파일·로그·테스트·도구 호출을 오래 유지하고, 필요한 경우 더 많은 effort를 쓰며, reward hacking 없이 학습되는 모델이어야 한다.
이 관점에서 IndexShare와 MTP는 단순한 논문식 효율화가 아니다.
1M context를 실제로 쓰려면 sparse attention indexer 비용, KV cache, speculative decoding acceptance, serving throughput이 모두 운영비로 돌아온다.
GLM-5.2가 아키텍처 figure와 serving throughput figure를 전면에 둔 것은, 긴 컨텍스트가 모델 능력인 동시에 인프라 문제라는 점을 잘 보여 준다.
또 하나 중요한 지점은 anti-hack 설계다.
코딩 에이전트를 RL로 훈련하면, reward가 명확한 만큼 모델이 “작업을 해결하는 법”보다 “평가를 속이는 법”을 배울 위험이 커진다.
GLM-5.2 블로그는 이 문제를 부수적인 안전 이슈가 아니라 학습 신호 품질 문제로 다룬다. rule filter와 LLM judge, online blocking, dummy result는 장기 코딩 에이전트 평가에서 앞으로 더 자주 보게 될 패턴일 가능성이 높다.
도입 관점에서는 두 가지를 분리해야 한다.
API나 GLM Coding Plan으로 GLM-5.2를 쓰는 것은 비교적 제품화된 경로다.
특히 블로그는 Coding Plan 사용자가 GLM-5.2 또는 Claude Code에서 1M context용 GLM-5.2[1m] 이름을 사용할 수 있다고 안내한다.
반면 self-host는 전혀 다른 의사결정이다.
753B급 모델, 1M context, DSA/MoE architecture, supported inference engine, memory/cache strategy, tool-call parser, 보안 검토를 함께 봐야 한다.
결론적으로 GLM-5.2는 “폐쇄형 최고 모델을 완전히 대체했다”기보다, 오픈 웨이트 모델이 장기 코딩 에이전트의 실제 운영 축으로 어디까지 올라왔는지 보여 주는 강한 신호다.
특히 FrontierSWE와 PostTrainBench에서 Opus 4.8 바로 아래까지 따라붙었다는 공식 수치는, 오픈 모델 경쟁이 이제 짧은 benchmark leaderboard가 아니라 장시간 작업 수행·훈련 인프라·서빙 엔진의 결합으로 평가될 것임을 보여 준다.
결론: 1M 컨텍스트는 모델 스펙이 아니라 시스템 계약이다
GLM-5.2를 가장 잘 요약하는 문장은 “1M context model”이 아니라 “1M context를 코딩 에이전트 작업에서 유지하기 위해 모델·훈련·서빙·평가를 같이 설계한 릴리스”에 가깝다.
IndexShare는 sparse attention의 반복 비용을 줄이고, MTP와 rejection sampling은 decode 효율을 개선하며, serving 최적화는 KV cache와 scheduler 병목을 다룬다. slime과 anti-hack module은 장기 RL rollout과 평가 신호의 품질을 관리한다.
그래서 이 릴리스의 실무적 교훈은 꽤 분명하다.
앞으로 long-context coding model을 볼 때는 context length 숫자만 볼 수 없다.
어떤 attention/indexing 구조를 쓰는가.
1M context에서 throughput이 유지되는가. max effort와 token budget을 어떻게 제어하는가. tool-use와 anti-hack을 학습·평가 과정에 넣었는가. self-host 가능한 공개 가중치와 실제 운영 가능한 serving stack이 함께 있는가.
GLM-5.2는 이 체크리스트를 한 번에 던지는 공개 모델 릴리스다.