긴 컨텍스트 LLM의 병목은 더 이상 “컨텍스트 창을 몇 토큰까지 열 수 있는가”만이 아니다.
에이전트가 저장소 전체를 읽고, 웹 탐색 기록을 유지하고, 긴 대화 메모리를 계속 들고 가려면 수십만~100만 토큰을 실제로 빠르게 처리해야 한다.
문제는 표준 softmax attention의 비용이 문맥 길이에 대해 제곱으로 커지고, 특히 prefill과 decode의 attention 경로가 배포 비용을 직접 밀어 올린다는 점이다.
MiniMax Sparse Attention(MSA)은 이 병목을 GQA(Grouped Query Attention) 위에서 다시 설계한다.
핵심은 모든 query가 모든 key를 보는 대신, 각 GQA 그룹이 중요한 KV 블록만 고르게 하는 것이다.
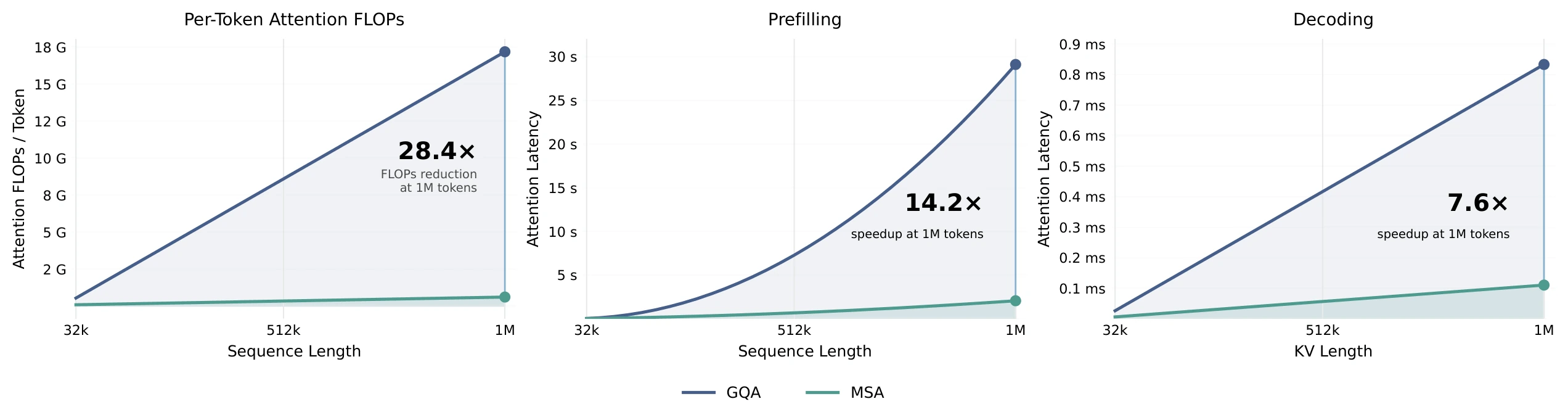
논문은 109B 파라미터 MoE 실험에서 MSA가 full-attention/GQA 기준 품질을 대체로 유지하면서 1M context에서 per-token attention compute를 28.4× 줄였고, H800 기준 prefill 14.2×, decode 7.6× wall-clock speedup을 보고한다.
흥미로운 점은 이 작업이 논문 아이디어에만 머물지 않는다는 것이다.
MiniMax는 MSA inference kernel을 별도 GitHub 저장소로 공개했고, MSA가 들어간 공개 모델 표면으로 Hugging Face의 MiniMax-M3도 연결해 두었다.
따라서 이 글에서는 논문의 sparse attention 구조, 커널 설계, 109B 실험 결과, 그리고 공개된 코드/모델 배포 상태를 함께 본다.
무엇을 해결하려는가
Long-context 모델은 보통 세 가지 압력을 동시에 받는다.
첫째, 전체 attention을 유지하면 긴 문맥에서 prefill 비용이 급격히 커진다.
둘째, decode에서는 KV cache를 계속 읽어야 하므로 latency와 throughput이 동시에 흔들린다.
셋째, sparse나 linear 대체 구조를 쓰더라도 실제 GPU 커널에서 tensor core utilization이 나오지 않으면 이론상 FLOPs 절감이 wall-clock 절감으로 이어지지 않는다.
MSA가 겨냥하는 지점은 이 세 압력의 교차점이다.
논문은 sparse attention을 “모델이 대충 적은 토큰만 보게 하는 방법”으로 두지 않고, GQA 구조와 block-level GPU 실행에 맞춘 선택-후-정확 attention 문제로 다룬다.
선택은 가벼운 Index Branch가 맡고, 실제 output은 Main Branch가 선택된 블록 안에서 표준 softmax attention으로 계산한다.
즉 MSA의 질문은 “full attention을 완전히 버릴 수 있는가”가 아니라 “대부분의 query에서 실제로 필요한 KV 블록만 빠르게 찾아, 그 블록 안에서는 정확한 attention을 하게 만들 수 있는가”에 가깝다.
이 framing 덕분에 기존 GQA 기반 Transformer와 하드웨어 실행 경로를 최대한 재사용하면서도 1M context 비용을 크게 낮추려 한다.
핵심 아이디어 / 구조 / 동작 방식
MSA layer는 두 갈래로 나뉜다.
Index Branch는 query token과 과거 KV 블록을 점수화해 GQA 그룹별 Top-k 블록을 고른다.
Main Branch는 선택된 블록의 token들에 대해서만 기존 scaled dot-product attention을 수행한다.
논문 기본 설정은 block size B_k=128, 선택 블록 수 k=16이다.
따라서 query 하나가 보는 원거리 예산은 최대 2,048 tokens이고, 가장 최근 local block은 점수와 무관하게 항상 포함된다.
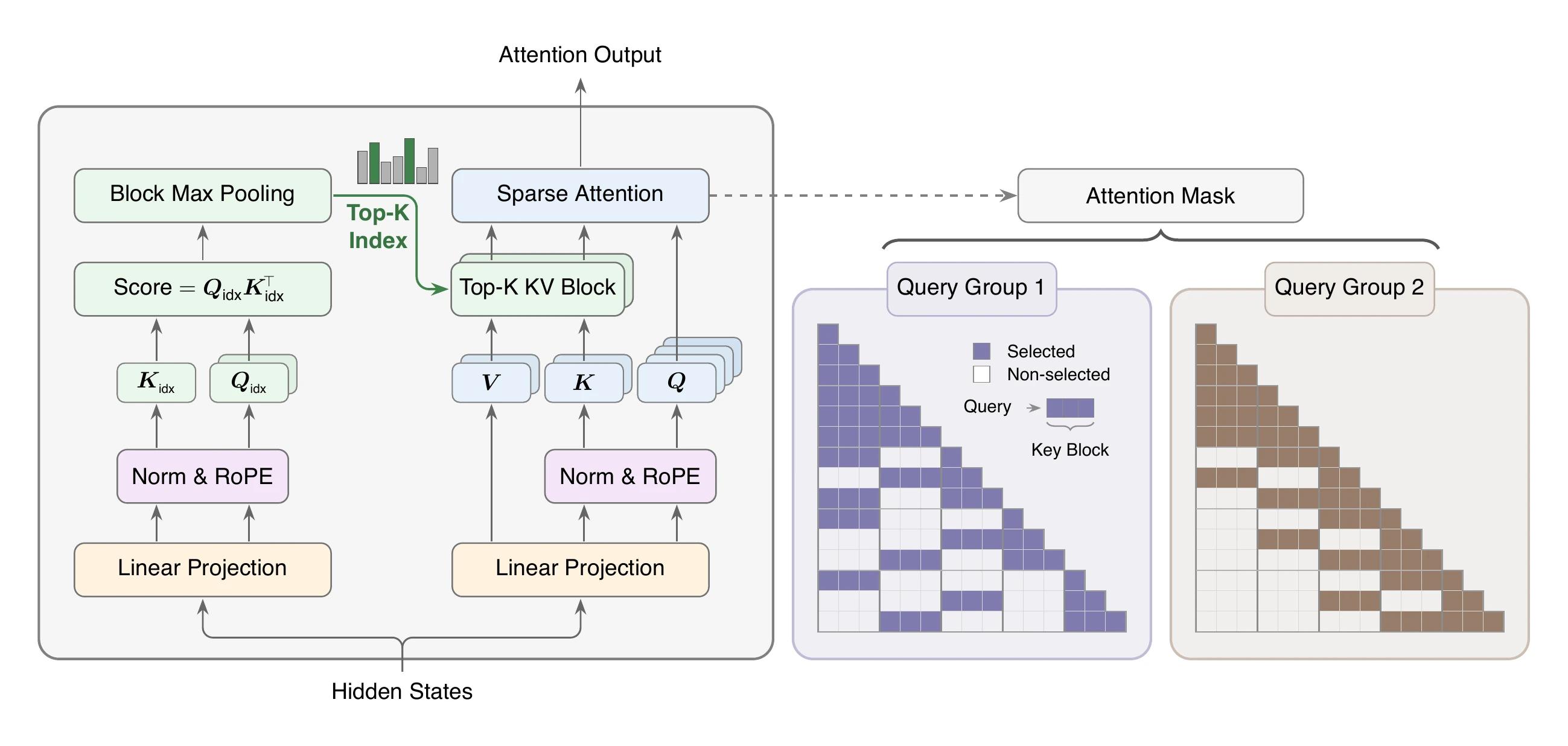
구조를 단순화하면 다음과 같다.
| 구성 요소 | 논문에서의 역할 | 실무적 의미 |
|---|---|---|
| Index Branch | GQA 그룹마다 KV 블록 점수를 계산하고 Top-k 블록을 선택한다. | attention 전체를 계산하지 않고도 원거리 후보를 고른다. |
| Local block forcing | 현재 query가 속한 최근 블록은 항상 포함한다. | 학습 안정성과 근접 문맥 보존을 위한 안전장치다. |
| Main Branch | 선택된 블록에 대해 표준 softmax attention을 수행한다. | sparse지만 선택된 support 안에서는 근사 attention이 아니라 정확 attention이다. |
| KL alignment loss | Index Branch 분포를 Main Branch의 attention 분포에 맞춘다. | selector가 실제 attention mass를 따라가도록 학습한다. |
| Stop-gradient / warmup | auxiliary loss가 backbone을 흔들지 않게 하고, sparse 전환 전 indexer를 먼저 맞춘다. | 기존 dense checkpoint를 MSA로 바꿀 때 품질 붕괴를 줄인다. |
여기서 중요한 설계 선택은 Index Branch가 “작은 별도 attention”처럼 동작하지 않는다는 점이다.
논문은 index query projection과 index key projection만 추가하고, value head를 붙여 별도 출력을 만들기보다 selector 역할에 집중시킨다.
학습도 Main Branch의 attention 분포를 teacher처럼 사용해 KL loss로 맞추며, stopgrad를 통해 auxiliary KL gradient가 backbone representation을 직접 흔들지 않게 한다.
계산 관점에서는 per-query attention cost가 O(N)에서 O(kB_k)로 내려간다. k=16, B_k=128이면 sequence length가 128K든 1M이든 Main Branch가 직접 보는 token 예산은 고정된다.
물론 Index Branch 점수화 비용은 남지만, GQA의 KV 그룹 수와 작은 index dimension을 활용해 전체 attention 비용 대비 가볍게 만든다.
커널 설계에서 확인되는 점
MSA 논문은 알고리즘만 제안하지 않고, sparse prefill을 실제 GPU에서 빠르게 돌리기 위한 커널 경로를 함께 설명한다.
첫 번째는 exp-free Top-k다.
Top-k 선택에는 softmax의 지수/정규화 값이 필요하지 않다.
점수 순서만 보존되면 되므로 raw score를 바로 정렬/선택해 softmax 계산을 건너뛴다.
저자들은 H800에서 torch.topk와 TileLang radix-select를 비교했고, 배포 설정에 가까운 k=16 구간에서 특화 커널이 가장 빠르다고 보고한다.
두 번째는 Main Branch의 sparse attention을 query-outer가 아니라 KV-outer로 구성하는 것이다.
선택된 KV 블록을 기준으로 그 블록을 필요로 하는 query들을 모아 tensor-core MMA를 더 잘 채우는 방식이다. sparse pattern은 블록별 인기도가 불균등하기 때문에, 논문은 pre-scheduled tile chunking과 two-phase combine으로 skew를 처리하고 atomic update를 피한다.
세 번째는 training path다.
MSA는 Index Branch를 KL loss로 학습하므로 sparse attention forward와 별도로 log-sum-exp 계열 값이 필요하다.
논문은 이 LSE 계산을 forward에 fuse하고, backward에서는 dynamic load balancing을 사용해 sparse KL loss 계산의 병목을 줄인다.
즉 MSA의 핵심은 “Top-k 블록을 고른다”는 단일 아이디어보다, selector 학습과 block-sparse 실행을 같이 맞춘 데 있다.
공개 GitHub 저장소도 이 방향을 뒷받침한다.MiniMax-AI/MSA는 fmha_sm100이라는 Python package로 구성되어 있고, README 기준 NVIDIA SM100, CUDA nvcc, Python 3.10+, Linux x86_64를 요구한다.
저장소에는 dense FMHA와 sparse_topk_select를 JIT 컴파일하는 csrc stack, CuTe-DSL 기반 sparse attention stack, sparse prefill adapter, benchmark script와 smoke/integration/regression test가 들어 있다.
공개된 근거에서 확인되는 점
논문 실험은 공개 MiniMax-M3 모델 카드의 428B/23B activated 설정과 구분해서 읽어야 한다.
논문 본문의 검증 모델은 41-layer MoE, 약 109B total parameters, token당 6B activated parameters, 64 query heads, 4 KV heads, head dimension 128, 3T token training budget이다.
첫 번째 경로인 MSA-PT는 처음부터 sparse pretraining을 하고, 두 번째 경로인 MSA-CPT는 2.6T token full-attention checkpoint를 MSA로 바꾼 뒤 400B token을 계속 학습한다.
두 경로 모두 40B token indexer warmup을 둔다.
대표 수치는 다음처럼 요약할 수 있다.
| 항목 | 논문/공개 소스에서 확인한 내용 | 해석 |
|---|---|---|
| 1M context compute | 109B 실험 모델에서 per-token attention compute 28.4× 감소 | 긴 문맥에서 attention FLOPs 자체를 줄이는 것이 핵심 목표다. |
| H800 wall-clock | 논문 abstract 기준 prefill 14.2×, decode 7.6× speedup | 커널 co-design이 이론 FLOPs 절감을 실제 속도로 일부 전환했다는 주장이다. |
| 일반 benchmark | MMLU 67.0(Full) / 67.2(MSA-PT) / 66.8(MSA-CPT), MMLU-Pro 38.5 / 38.8 / 39.1 | dense baseline과 큰 격차 없이 유지되는 행이 많다. |
| 장기 검색 | RULER-32K 75.0(Full) / 77.5(MSA-PT) / 75.7(MSA-CPT) | sparse pretraining이 long-context retrieval에 유리하게 적응할 수 있음을 시사한다. |
| 128K 확장 | HELMET-128K overall 46.53(Full) vs 45.93(MSA-CPT), RULER-128K overall 72.00 vs 72.12 | 긴 문맥 확장에서는 subset별 편차가 있지만 overall은 근접하다. |
| 공개 kernel repo | MIT license, Python package fmha_sm100 v0.1.1, SM100/CUDA 중심, releases/tags 없음 |
runnable artifact는 있으나 아직 초기 배포 형태다. |
| 공개 모델 표면 | Hugging Face MiniMaxAI/MiniMax-M3, not gated, Transformers image-text-to-text, model card 기준 428B total / 23B activated / 1M context |
논문 실험과 별개의 production-grade 모델 표면으로 봐야 한다. |
MiniMax-M3 모델 카드는 MSA를 “1M context scaling”의 핵심으로 설명한다.
카드 기준 M3는 native multimodal training을 거친 약 428B total / 23B activated 모델이고, M2 대비 1M context에서 prefill 9×, decode 15× speedup 및 per-token compute 1/20 수준을 주장한다.
다만 이 수치는 모델 카드의 제품/모델 비교이고, 논문 본문의 109B 실험 수치와는 분리해 읽는 편이 안전하다.
공개 저장소 관점에서는 아직 maturity caveat가 있다.MiniMax-AI/MSA는 2026년 6월 11일 생성된 초기 저장소이고, 확인 시점 기준 GitHub releases와 tags는 비어 있었다.
README는 설치, smoke test, benchmark command, package layout을 제공하지만 hardware target은 SM100 중심이다.
즉 일반 사용자가 노트북이나 기존 A100/H100 환경에서 바로 같은 수치를 재현하는 범용 라이브러리라기보다, Blackwell/SM100 계열 sparse attention kernel release에 가깝다.
실무 관점에서의 해석
MSA의 실무적 가치는 “long context를 더 크게 열었다”보다 “긴 문맥 비용을 운영 가능한 형태로 낮추려 했다”에 있다.
1M context가 제품 기능이 되려면 prefill 한 번, decode 한 토큰의 비용이 모두 중요하다.
특히 repository-scale code reasoning, persistent memory agent, long video/document assistant처럼 입력이 길고 반복 요청이 많은 시스템에서는 attention path의 상수 배율 차이가 곧 serving budget 차이가 된다.
내가 보기에 MSA의 강점은 세 가지다.
첫째, GQA와 잘 맞는다.
대부분의 현대 LLM이 이미 GQA 구조를 쓰기 때문에, 그룹별 selector를 붙이는 설계는 완전히 새로운 backbone으로 갈아타는 것보다 이전 비용이 낮다.
둘째, 선택된 블록 안에서는 정확 softmax attention을 유지한다.
이는 aggressive sparse drop 방식보다 품질 해석이 쉽다.
셋째, 논문이 커널 설계를 전면에 둔다. sparse attention은 종종 이론 FLOPs는 작지만 실제 GPU utilization이 낮은데, MSA는 Top-k, KV-outer attention, KL loss kernel까지 함께 다룬다.
하지만 제한도 분명하다.
논문 수치는 MiniMax의 대규모 내부 학습/커널 환경에 크게 의존한다.
공개 repo는 초기 상태이고, no release/tag 상태라서 production dependency로 고정하기에는 아직 신호가 부족하다.
또한 SM100 target이 강하게 드러나므로, 현재 인프라가 H100/A100 중심인 팀은 바로 이식 가능한지 별도 검증이 필요하다.
모델 카드의 MiniMax-M3는 not gated로 공개되어 있지만 license는 other/MiniMax community license라서 상업적 사용 조건도 따로 확인해야 한다.
그래도 방향성은 중요하다.
긴 컨텍스트 경쟁이 단순 window size 경쟁에서 어떤 attention interaction을 실제로 계산할 것인가로 이동하고 있기 때문이다.
MSA는 이 문제를 모델 아키텍처, training conversion, inference kernel, 공개 모델 배포까지 하나의 vertical slice로 연결한 사례다.
앞으로 long-context serving stack을 설계하는 팀이라면, full attention, sliding window, retrieval/compression뿐 아니라 이런 GQA-aware block sparse attention도 평가 축에 넣어야 한다.