비디오 생성 모델이 “짧은 클립을 그럴듯하게 만든다”를 넘어 사용자의 입력에 반응하는 interactive world model로 확장되면서, 평가 방식도 바뀌어야 한다.
한 장면의 화질이나 텍스트 프롬프트 충실도만으로는 이제 부족하다.
사용자가 앞으로 이동하라고 했을 때 실제로 공간적으로 앞으로 가는지, 네 번째 턴까지 같은 세계 상태를 유지하는지, 시점 전환과 사건 편집을 섞어도 물리적으로 말이 되는지를 함께 봐야 한다.
WBench: A Comprehensive Multi-turn Benchmark for Interactive Video World Model Evaluation은 이 문제를 정면으로 다룬다.
Fudan University와 Meituan LongCat Team이 공개한 이 벤치마크는 289개 테스트 케이스, 1,058개 interaction turn, 22개 자동 sub-metric, 20개 모델 평가를 하나의 프로토콜로 묶는다.
핵심은 “월드 모델을 게임 엔진처럼 본다”는 관점이다.
좋은 월드 모델은 렌더러처럼 화면을 예쁘게 만들고, 디렉터처럼 세계 설정을 지키며, 컨트롤러처럼 입력을 실행하고, 메모리처럼 상태를 보존하며, 엔진처럼 물리적 인과를 유지해야 한다.
공개 범위도 비교적 넓다. arXiv 논문과 Hugging Face Papers 항목은 공식 프로젝트 페이지, GitHub 저장소, Hugging Face 데이터셋, 평가용 weight bundle로 이어진다.
GitHub README는 full dataset, evaluation code, model weights 공개를 공지하고, 프로젝트 페이지는 leaderboard와 dataset gallery를 함께 제공한다.
따라서 WBench는 단순한 논문 제안이 아니라, 현재 인터랙티브 비디오 월드 모델을 비교하기 위한 공개 평가 패키지에 가깝다.
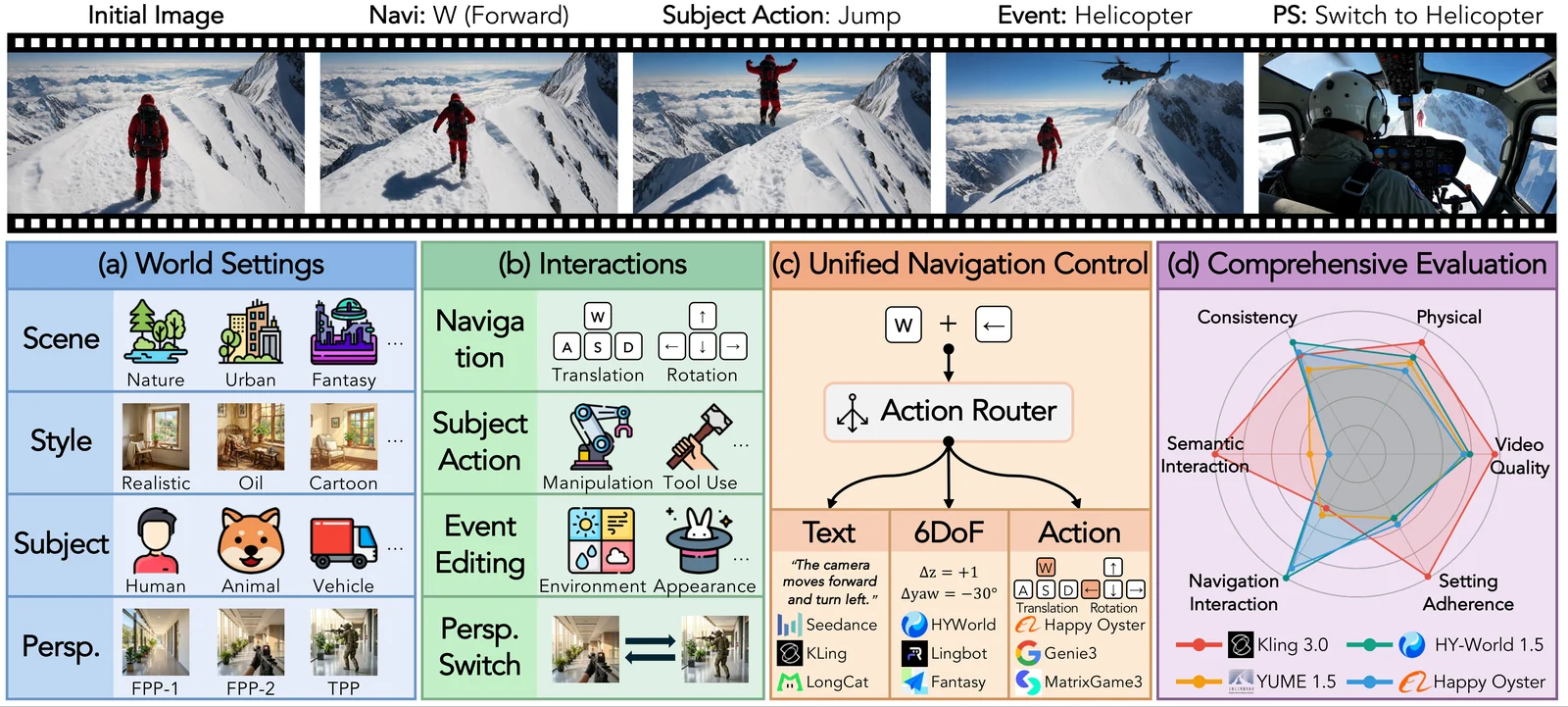
무엇을 해결하려는가
기존 비디오 생성 평가는 대체로 정적이다.
VBench류의 benchmark는 perceptual quality, motion smoothness, temporal flicker 같은 화질 지표를 잘 측정하지만, 사용자가 여러 턴에 걸쳐 세계를 조작하는 상황을 충분히 보지 않는다.
반대로 일부 world model benchmark는 navigation이나 memory를 보더라도 open-domain 장면, semantic interaction, first-person/third-person perspective, 다양한 control interface를 하나의 기준으로 비교하기 어렵다.
WBench가 겨냥하는 병목은 이 분절된 평가 표준이다.
논문은 interactive world model에 필요한 역할을 다섯 가지로 나눈다. renderer는 비디오 품질, director는 초기 세계 설정 준수, controller는 상호작용 실행, memory는 다중 턴 일관성, engine은 물리적 합리성을 담당한다.
한 모델이 화질은 좋지만 navigation을 못하거나, camera pose는 잘 따라가지만 subject identity를 잃는다면, 평균 점수 하나로는 원인을 찾기 어렵다.
또 하나의 중요한 문제는 control interface 차이다.
어떤 모델은 텍스트 프롬프트를 받으며, 어떤 모델은 6-DoF camera pose를 받고, 또 다른 모델은 W/A/S/D 같은 discrete action을 받는다.
WBench는 navigation을 text, 6-DoF pose, discrete action control로 매핑해 서로 다른 native interface를 가진 모델을 같은 navigation subset에서 비교하려 한다.
이 설계가 없으면 “텍스트 기반 비디오 모델”과 “전용 월드 모델”을 공정하게 나란히 놓기 어렵다.
핵심 아이디어 / 구조 / 동작 방식
WBench의 한 테스트 케이스는 크게 world setting과 interaction sequence로 구성된다. world setting은 scene, style, perspective, subject 네 속성을 포함한다.
예를 들어 장면은 자연·도시·실내·판타지·스포츠처럼 나뉘고, 스타일은 photorealistic뿐 아니라 anime, cartoon, CG, oil painting, ink wash 등으로 확장된다. perspective는 first-person과 third-person을 모두 포함하고, subject는 사람·동물·로봇·차량·기타 객체를 포괄한다.
Interaction은 네 종류다. navigation은 W/S/A/D와 좌우상하 회전으로 카메라 또는 주체의 이동을 지시한다. subject action은 조작, 이동, 도구 사용, 전투, 제스처처럼 주체가 하는 행동을 다룬다. event editing은 날씨 변화, 시간대 변화, 객체 등장, 환경 상태 변화처럼 외부에서 세계를 바꾸는 지시다. perspective switching은 first-person과 third-person 사이의 전환, 같은 주체 또는 다른 주체로의 전환, scope mode 전환을 포함한다.
| 구성 요소 | WBench에서의 의미 | 평가상 의미 |
|---|---|---|
| World setting | scene, style, perspective, subject | 초기 프레임과 프롬프트가 어떤 세계를 정의하는지 고정한다 |
| Navigation | text, 6-DoF pose, discrete action으로 매핑되는 이동/회전 | 서로 다른 control interface를 가진 모델을 같은 subset에서 비교한다 |
| Semantic interaction | subject action, event editing, perspective switching | 단순 카메라 이동이 아닌 의미적 조작을 테스트한다 |
| Multi-turn sequence | 케이스당 2-9턴, 평균 3.7턴 | 오류 누적, 상태 보존, 장기 일관성을 드러낸다 |
| Evaluation suite | 5개 차원, 22개 sub-metric | 화질·지시 이행·일관성·물리성을 분리해 진단한다 |
데이터 규모는 작아 보일 수 있지만, 밀도는 높다.
논문과 프로젝트 페이지 기준 WBench는 289개 케이스와 1,058개 interaction turn을 제공한다.
이 중 navigation은 158개 케이스로 가장 크고, event edit 65개, subject action 76개, perspective switch 31개가 포함된다. first-person은 약 62%, third-person은 약 38%이며, 네 턴짜리 케이스가 가장 흔하다.
즉 단일 prompt-response 테스트가 아니라, 같은 세계를 여러 번 조작하면서 모델의 상태 유지 능력을 보는 구조다.
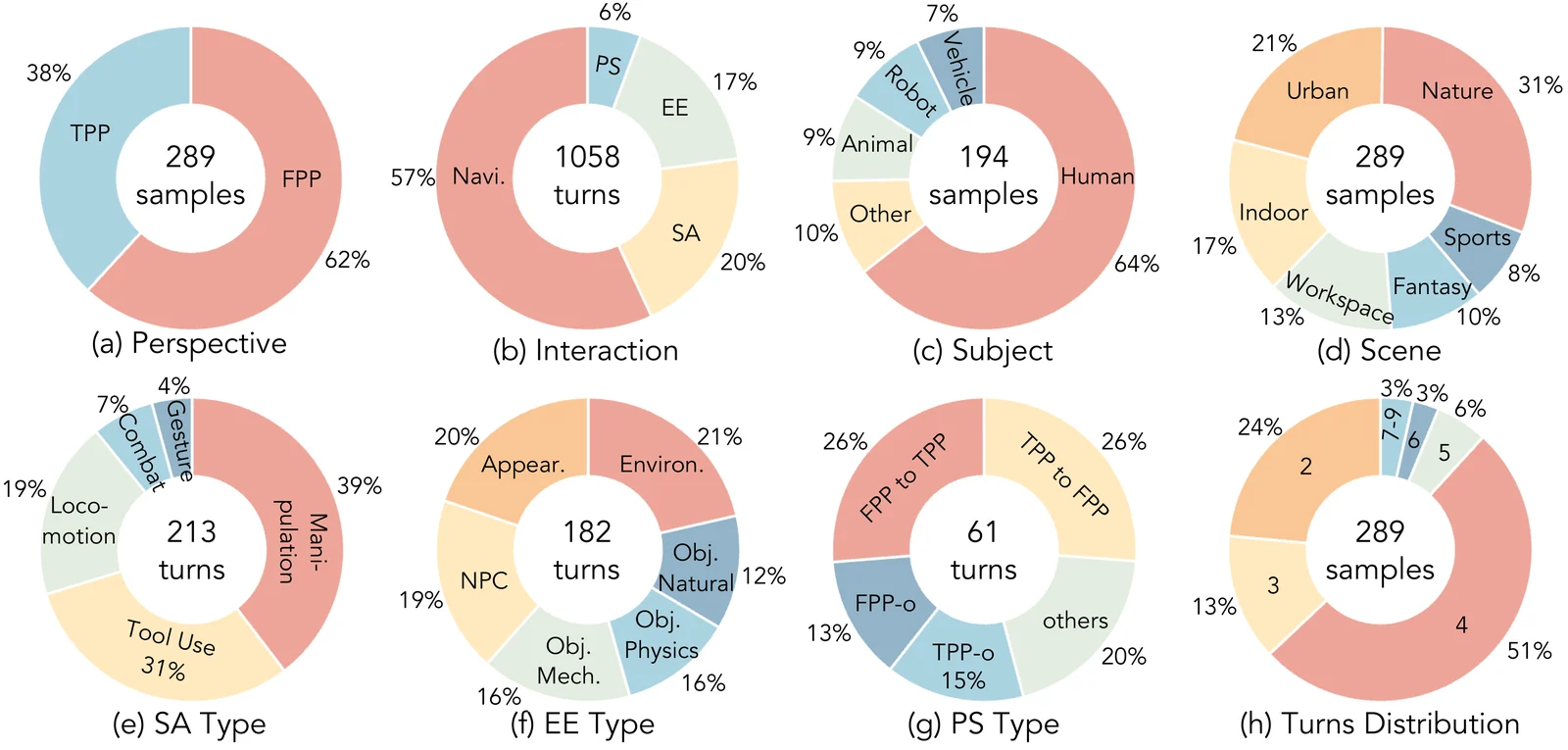
공개된 근거에서 확인되는 점
평가 suite는 다섯 차원으로 나뉜다.
Video Quality는 aesthetic quality, imaging quality, temporal flickering, dynamic degree, motion smoothness, HPSv3-Norm을 포함한다.
Setting Adherence는 scene adherence와 subject adherence를 본다.
Interaction Adherence는 navigation trajectory, event editing, subject action, perspective switching으로 나뉜다.
Consistency는 background, subject, spatial, gated spatial, perspective, segment continuity, geometric, photometric consistency를 포함한다.
Physical 차원은 visual plausibility와 causal fidelity를 측정한다.
중요한 점은 metric validation이다.
논문은 자동 지표가 사람 선호와 맞는지 확인하기 위해 400명의 crowd annotator로 blind pairwise comparison을 수행했다고 보고한다.
10개 평가 aspect에서 model-level human win rate와 WBench score의 Spearman correlation을 계산했고, 모든 aspect가 ρ≥0.94, 네 aspect가 ρ=1.00을 달성했다고 제시한다.
물론 이는 model-ranking granularity에서의 정렬이며, 개별 샘플의 미묘한 물리 오류까지 완벽히 판정한다는 뜻은 아니다.
리더보드 결과는 WBench의 문제의식을 잘 보여준다.
20개 모델 navigation split에서 Kling 3.0은 평균 79.2로 전체 1위지만 consistency에서는 LingBot-World가 강하고, physical에서는 Wan 2.7이 높다.
HY-World 1.5와 Happy Oyster 같은 전용 world model은 navigation에서 강하지만, text-driven 모델이 setting adherence나 일부 semantic interaction에서 앞서는 양상이 나온다.
논문은 이를 “no single model dominates all dimensions”로 요약한다.
| 공개 근거 | 확인된 내용 | 해석 |
|---|---|---|
| arXiv / HF Papers | 제목, 저자, 289 cases, 1,058 turns, 22 metrics, 20 models | 벤치마크의 중심 기여는 multi-turn world model evaluation이다 |
| Project page | leaderboard, key findings, metric comparison, dataset gallery | 논문 수치뿐 아니라 결과 탐색용 공개 웹 표면이 있다 |
| GitHub README | dataset, evaluation code, weights 공개 공지와 quick start | 평가 파이프라인 실행을 의도한 저장소 형태다 |
| Hugging Face dataset API | meituan-longcat/WBench, MIT license tag, full/navi/non_navi/first_person/third_person split |
케이스와 이미지/마스크 자산이 Hub에 공개되어 있다 |
| Hugging Face weights API | meituan-longcat/WBench-weights, Apache-2.0 tag, HPSv3·Qwen2-VL·Qwen3VL visual plausibility 등 평가 weight bundle |
metric 실행에 필요한 외부 모델 자산을 별도 bundle로 배포한다 |
| GitHub metadata | MIT license, Python repo, 공개 직후 80 stars, releases/tags 없음 | 공개 초기 연구 artifact이며 안정된 versioned release라기보다는 main branch 중심이다 |
릴리스 성숙도에는 caveat가 있다.
GitHub 저장소는 MIT 라이선스이고 full evaluation pipeline을 제공하지만, 현재 GitHub API 기준 latest release는 404이고 tag 목록도 비어 있다.
README는 docs/installation.md를 안내하지만, 확인 시점의 repository root contents에서는 docs/ 디렉터리가 보이지 않았다.
또한 text-conditioned model generation은 구현되어 있지만, README의 model type 표에서 camera-conditioned와 action-conditioned model generation example은 아직 coming soon으로 표시된다.
따라서 지금의 WBench는 “표준화된 장기 운영 플랫폼”이라기보다, 논문 공개 직후 빠르게 검증해 볼 수 있는 초기 공개 benchmark bundle로 보는 편이 정확하다.
실무 관점에서의 해석
WBench의 가장 좋은 점은 월드 모델 평가를 “화질 점수”에서 끌어내린다는 데 있다.
지금까지 많은 비디오 생성 모델은 예쁜 샘플 몇 개와 평균적 화질 지표로 강하게 보일 수 있었다.
하지만 interactive world model이 제품이나 시뮬레이터가 되려면, 사용자의 연속 입력을 이해하고, 같은 세계를 잃지 않고, 이동과 사건과 시점 전환을 같이 처리해야 한다.
WBench는 이 요구를 다섯 축과 22개 metric으로 쪼개어 어느 능력이 부족한지 진단하게 만든다.
특히 navigation과 semantic interaction을 분리한 점이 중요하다.
논문은 navigation이 video quality, consistency, physical compliance와 거의 독립적으로 움직인다고 분석한다.
다시 말해 잘 그리는 모델이 꼭 잘 움직이는 것은 아니고, camera control이 좋다고 subject control이 좋은 것도 아니다.
이는 모델 개발팀에게 분명한 메시지를 준다. world model을 개선하려면 renderer를 키우는 스케일링만으로는 부족하고, 공간 상태 표현, control grounding, subject identity 유지, causal event modeling을 별도 축으로 다뤄야 한다.
실무 도입 관점에서는 평가 비용도 봐야 한다.
WBench는 SAM2, Depth Anything v3, MegaSAM, DreamSim, HPSv3, VLM scoring, visual plausibility regressor 등 여러 specialist model과 LMM을 조합한다.
README도 wbench-main과 wbench-vp 두 환경을 나누고, VLM metric에는 Volcengine ARK의 Doubao-Seed-2.0-lite API key를 요구한다.
즉 “한 번 다운로드해 CPU에서 빠르게 도는 작은 benchmark”가 아니라, GPU metric, precompute, VLM API, 별도 plausibility environment를 함께 운영해야 하는 평가 스택이다.
한계도 논문이 직접 밝힌다.
현재 테스트셋은 continuous control보다 discrete action sequence에 초점을 둔다. physical dimension은 일부 LMM 기반 평가에 의존하기 때문에 미묘한 물리 현상에서는 신뢰도가 떨어질 수 있다.
또한 real-time evaluation과 더 넓은 domain 확장은 앞으로의 과제로 남아 있다.
그럼에도 WBench는 2026년 현재 인터랙티브 비디오 월드 모델의 병목을 꽤 선명하게 잘라 보여준다.
예쁜 동영상 생성과 조작 가능한 세계 모델 사이에는 아직 큰 간극이 있고, 그 간극을 측정하는 기준선이 필요하다는 점이다.
참고 링크
- HF Papers: WBench: A Comprehensive Multi-turn Benchmark for Interactive Video World Model Evaluation
- arXiv: arXiv:2605.25874 / HTML
- Project page: meituan-longcat.github.io/WBench
- GitHub: meituan-longcat/WBench
- Hugging Face dataset: meituan-longcat/WBench
- Hugging Face weights: meituan-longcat/WBench-weights