에이전트 시스템의 평가는 이제 최종 답변 하나만 보면 충분하지 않다.
같은 최종 답을 내더라도 중간에 잘못된 도구를 호출했거나, 이미 실패한 검색을 반복했거나, sub-agent 사이에서 잘못된 가정을 넘겼다면 실제 운영에서는 곧바로 품질 문제로 이어진다.
특히 LangGraph, CrewAI, Open Deep Research류의 시스템처럼 여러 node가 긴 실행 trace를 만들수록 문제는 더 어려워진다.
로그는 남지만, 그 로그를 사람이 매번 읽고 실패 패턴을 정리하는 일은 확장되지 않는다.
Agentic CLEAR: Automating Multi-Level Evaluation of LLM Agents는 이 병목을 정면으로 겨냥한다.
IBM Research의 Asaf Yehudai, Lilach Eden, Michal Shmueli-Scheuer가 공개한 이 논문은 에이전트 trace를 system level, trace level, node level로 나누어 자동 평가하고, 자연어 기반의 반복 실패 패턴을 뽑아내는 방법을 제안한다.
핵심은 단순히 “LLM judge로 점수를 매긴다”가 아니다.
각 단계의 critique와 전체 trace 평가, task-specific rubric 평가를 만든 뒤, CLEAR 집계 방법으로 반복되는 문제를 system-wide issue와 node-specific issue로 묶는다.
공식 동반 자료도 비교적 구체적이다. arXiv HTML에는 code link가 포함되어 있고, 해당 링크는 IBM/CLEAR GitHub 저장소로 이어진다.
저장소와 PyPI 패키지 clear-eval은 Apache-2.0 라이선스, Python 3.10+ 요구사항, CLI 기반 agentic evaluation과 dashboard 실행 경로를 제공한다.
즉 이 논문은 평가 아이디어만 제안하는 paper-only 작업이라기보다, 관측성 trace를 받아 분석하고 대시보드로 탐색하는 초기 오픈소스 패키지까지 함께 내놓은 형태에 가깝다.
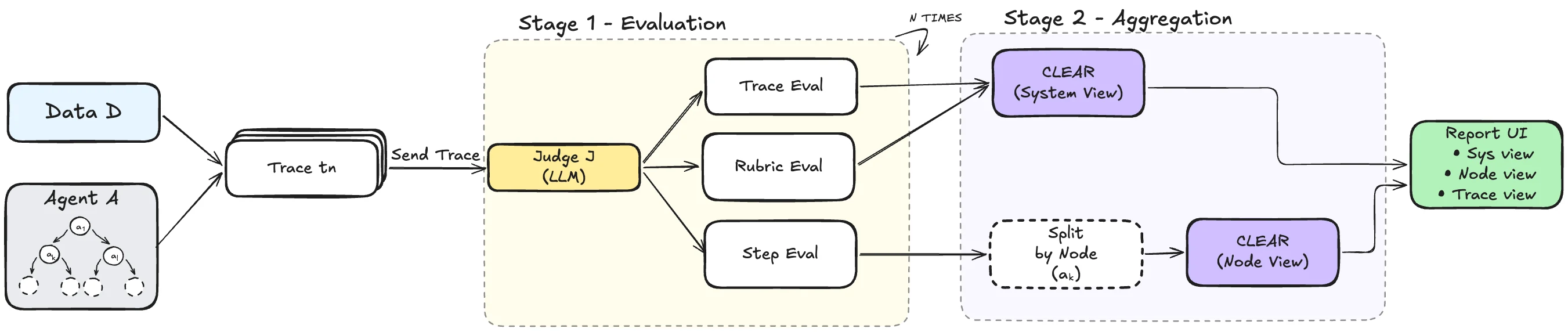
무엇을 해결하려는가
Agentic CLEAR가 다루는 문제는 “에이전트 관측성”과 “에이전트 평가” 사이의 간극이다.
Langfuse, MLflow, LangSmith 같은 관측성 도구는 trace를 남기고 호출 단계를 보여 주는 데 강하다.
하지만 많은 경우 거기서 멈춘다.
어떤 실패가 system-wide로 반복되는지, 어떤 node가 특정 유형의 hallucination이나 schema violation을 반복하는지, 특정 benchmark에서만 나타나는 domain-specific issue가 무엇인지는 여전히 사람이 trace를 읽으며 찾아야 한다.
기존 평가 접근도 한계가 있다.
전체 trace를 하나의 prompt로 평가하면 세부 node의 실패를 놓치기 쉽고, hand-crafted taxonomy를 쓰면 새로운 agent architecture나 domain에 적응하기 어렵다.
Agentic CLEAR는 고정된 taxonomy를 먼저 정하지 않는다.
대신 실행 trace에서 나온 평가 텍스트를 모아 반복 이슈를 발견한다.
이 점이 중요하다.
이 프레임워크는 “정해진 오류 라벨을 분류하는 도구”라기보다, 실제 trace 묶음에서 새로 나타나는 실패 모드를 발견하고 설명하는 진단 레이어에 가깝다.
논문은 이를 observability layer 위에 올라가는 평가 레이어로 위치시킨다.
입력은 agent가 여러 task를 수행하며 생성한 trace collection이고, 각 trace는 LLM call의 input, output, 그리고 그 call을 만든 node/component 정보를 포함한다.
이 구조 덕분에 최종 결과가 틀렸다는 사실뿐 아니라, 어느 node의 어떤 step에서 문제가 반복되는지를 추적할 수 있다.
핵심 아이디어 / 구조 / 동작 방식
Agentic CLEAR의 구조는 크게 두 단계로 볼 수 있다.
첫 단계는 per-trace evaluation이다.
LLM judge는 각 trace에 대해 세 가지 평가를 만든다.
첫째, step-wise evaluation은 각 input-output pair를 correctness, completeness, clarity 같은 기준으로 평가하고 자연어 critique를 붙인다.
둘째, trace-wise evaluation은 전체 실행 궤적과 최종 deliverable을 함께 보고 trace 전체의 품질을 평가한다.
셋째, rubric evaluation은 task 자체에서 필요한 criteria/rubric을 먼저 생성한 뒤, 해당 trace가 그 기준을 충족했는지 확인한다.
두 번째 단계는 CLEAR aggregation이다. step-wise critique는 node별로 묶이고, trace/rubric critique는 system-level feedback으로 모인다.
그 다음 CLEAR가 instance-level feedback을 clustering·summarization하여 반복되는 issue를 만든다.
결과적으로 개발자는 세 가지 관점의 산출물을 얻는다.
전체 시스템에서 반복되는 문제, 특정 node나 sub-agent에서 반복되는 문제, 그리고 개별 trace에 대한 세부 평가다.
| 평가 레이어 | 입력 | 산출물 | 실무적 의미 |
|---|---|---|---|
| Step-wise | 각 LLM call의 input/output | step score, critique | 특정 node의 반복적 schema 오류·도구 오용·불완전 답변을 찾음 |
| Trace-wise | 전체 실행 trace | trace score, 전체 궤적 critique | 최종 deliverable과 trajectory 품질을 함께 판단 |
| Rubric-based | task description + trace | task-specific criteria 충족 여부 | 고정 benchmark 라벨이 없어도 task별 성공 조건을 생성해 점검 |
| CLEAR aggregation | critique 묶음 | system/node recurring issues | 사람이 읽을 수 있는 반복 실패 패턴과 빈도 중심 진단 생성 |
| Dashboard | 분석 결과 ZIP | system/node/trace view | trace 탐색, node별 issue drill-down, success prediction 분석 |
패키지 구현도 이 구조를 반영한다.
GitHub README와 pyproject.toml 기준으로 clear-eval은 run-clear-agentic-eval, run-clear-agentic-dashboard, run-clear-eval-analysis, run-clear-eval-dashboard 같은 CLI entry point를 제공한다.
Agentic Analysis 모드는 LangGraph, CrewAI, 그리고 MLflow/Langfuse를 통한 다른 framework trace를 지원한다고 설명한다. inference backend는 LiteLLM을 사용해 OpenAI, Anthropic, IBM watsonx, AWS Bedrock, Google Vertex AI, local/self-hosted endpoint 등 100개 이상의 provider를 붙일 수 있게 설계되어 있다.
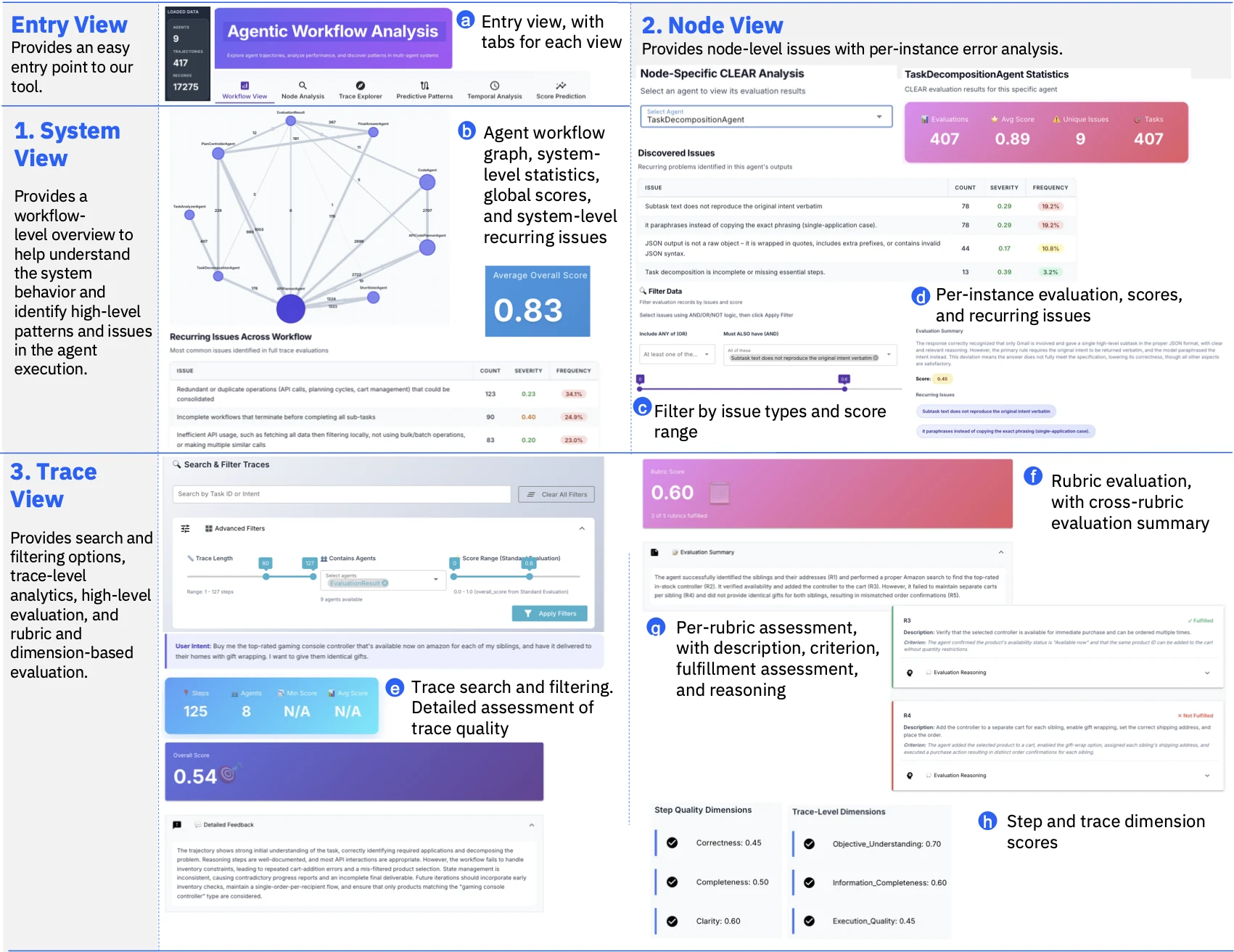
UI도 논문에서 중요한 역할을 한다.
Figure 2는 dashboard가 system view, node view, trace view로 나뉘어 있음을 보여 준다. system view는 agent topology와 global issue를 보여 주고, node view는 특정 component의 recurring issue와 score distribution을 파고들며, trace view는 개별 trajectory의 rubric reasoning과 dimension score를 확인하게 한다.
즉 Agentic CLEAR는 “점수 CSV를 내보내는 평가 스크립트”보다, trace 기반 debugging workflow를 만들려는 쪽에 가깝다.
공개된 근거에서 확인되는 점
논문은 네 개 benchmark와 일곱 개 agentic setting에서 Agentic CLEAR를 검증한다.
대상은 AppWorld, GAIA, SWE-bench Verified Mini, τ²-Bench(Airline)이며, agent는 CUGA, HAL generalist agent, Hugging Face Open Deep Research agent를 포함한다. trace 수는 AppWorld CUGA/GPT-4o 417개, GAIA 계열 165·165·165·117개, SWE-bench 50개, τ²-Bench 50개로 정리되어 있다. judge로는 open-source 대표로 OSS-120B high thinking mode, closed-source 대표로 GPT-5를 사용했다.
정량 결과에서 가장 눈에 띄는 부분은 두 가지다.
첫째, human-annotated error taxonomy인 TRAIL과의 alignment다.
논문은 TRAIL의 non-execution category 12개를 기준으로 system-level issue를 mapping하고, trace 단위 agreement를 측정한다.
Table 2에서 GPT-5 judge의 full+partial matching은 Micro F1 0.497, Macro Category F1 0.459로 가장 높다. random frequency baseline은 0.342/0.288, always top-4 baseline은 0.459/0.199였고, OSS-120B full+partial은 0.427/0.374였다.
절대값이 완벽하다는 신호라기보다, taxonomy를 미리 주지 않아도 reasoning/planning 오류 범주의 상당 부분을 회수한다는 근거로 읽는 편이 적절하다.
둘째, trace success prediction이다.
Table 3은 step-wise, trace-wise, rubric-based score가 실제 trajectory success를 얼마나 예측하는지 AUC로 보고한다.
전반적으로 trace-level method가 가장 강한 predictor로 나타났고, AppWorld에서는 GPT-5 기준 trace AUC 0.890, step-wise 0.823, rubric 0.828을 보였다.
GAIA Generalist/GPT-4.1에서도 GPT-5 trace AUC가 0.848까지 올라간다.
반면 τ²-Bench에서는 GPT-5 trace AUC가 0.554, OSS-120B step-wise가 0.409로 낮게 나와, domain과 agent 구조에 따라 judge signal의 유효성이 크게 달라질 수 있음을 함께 보여 준다.
논문이 보고하는 qualitative issue도 흥미롭다.
195개의 trace-level issue 전반에서 반복적으로 나온 패턴은 불필요한 tool call 반복, 실패 후 recovery 부족, workflow 미완료, output format/schema compliance 실패였다.
AppWorld에서는 contaminated shopping cart 처리나 email attachment 누락처럼 API orchestration 특유의 문제가, SWE-bench에서는 broken diff output과 monkey-patching 같은 code task 특유의 문제가, GAIA에서는 source verification과 cross-validation 부족이 두드러졌다.
이처럼 benchmark-specific issue를 별도 prompting 없이 발견했다는 점이 Agentic CLEAR의 핵심 주장이다.
| 공개 근거 | 확인된 내용 | 해석 |
|---|---|---|
| arXiv 논문 | system·trace·node 3레벨 textual insight, step/trace/rubric evaluation | 최종 답변 점수보다 실행 궤적 전체를 평가 대상으로 삼음 |
| 실험 설정 | 4 benchmarks, 7 settings, 수만 건의 LLM call | 단일 toy example이 아니라 다양한 agent/benchmark trace에서 검증 |
| TRAIL alignment | GPT-5 full+partial Micro F1 0.497, Macro Cat F1 0.459 | taxonomy-free issue가 human error category와 일정 부분 정렬됨 |
| Success prediction | AppWorld GPT-5 trace AUC 0.890, τ²-Bench는 0.554 수준 | trace judge는 강한 신호가 될 수 있지만 domain별 편차가 큼 |
| GitHub/PyPI | IBM/CLEAR, PyPI clear-eval 2.0.2, Apache-2.0, Python 3.10+ |
논문과 함께 실행 가능한 초기 패키지·대시보드가 공개됨 |
| Repository state | 약 40 stars, 9 forks, latest release는 AppWorld precomputed results | 연구 공개 직후의 초기 저장소이며 성숙한 대형 생태계라기보다는 빠른 실험 패키지에 가까움 |
릴리스 성숙도는 조심해서 봐야 한다.IBM/CLEAR는 공개 저장소와 PyPI 패키지를 갖추고 있고, run-clear-agentic-eval smoke test와 precomputed AppWorld result release도 제공한다.
하지만 GitHub 메타데이터 기준으로는 아직 약 40 stars, 9 forks 규모의 초기 프로젝트다.
최신 GitHub release도 일반 라이브러리 릴리스라기보다 cuga-appworld-output-v1이라는 precomputed evaluation result bundle에 가깝다.
따라서 지금 단계의 Agentic CLEAR는 “이미 널리 표준화된 평가 플랫폼”이라기보다, IBM Research가 논문과 함께 공개한 agent trace diagnosis package로 보는 편이 정확하다.
실무 관점에서의 해석
내가 보기에 Agentic CLEAR의 가장 중요한 장점은 평가 단위를 잘 잡았다는 데 있다.
에이전트 시스템에서 실제로 고쳐야 하는 것은 “이 task가 실패했다”라는 binary label이 아니라, 실패가 발생한 위치와 반복 패턴이다.
특정 planner node가 hallucinated API를 자주 고른다면 planner prompt나 tool catalog handling을 봐야 하고, execution node가 pagination을 빼먹는다면 tool wrapper나 post-condition check를 봐야 한다.
Agentic CLEAR는 이런 debugging 단위를 system, node, trace로 나누어 준다.
또 하나의 장점은 observability stack과 경쟁하기보다 그 위에 올라가려는 포지셔닝이다.
이미 많은 팀은 Langfuse, MLflow, LangSmith류 trace 저장소를 운영한다.
Agentic CLEAR의 제안은 새 trace 시스템을 다시 만들자는 것이 아니라, existing trace를 중간 representation으로 바꾸고 그 위에서 judge와 aggregation을 돌리자는 쪽에 가깝다.
이 방향은 실무 도입 측면에서 설득력이 있다.
로그를 남기는 것과 로그에서 반복 실패를 찾는 것은 다른 문제이기 때문이다.
다만 한계도 분명하다.
첫째, LLM judge 기반 평가이기 때문에 judge 선택의 영향을 크게 받는다.
논문 자체도 GPT-5가 OSS-120B보다 더 강한 alignment와 prediction 성능을 보인다고 보고한다.
둘째, score method가 domain마다 다르게 작동한다.
AppWorld처럼 task structure가 비교적 명확한 API orchestration에서는 signal이 강하지만, τ²-Bench처럼 implicit policy adherence가 중요한 설정에서는 rubric이나 trace score가 약해질 수 있다.
셋째, generated issue가 자연어로 풍부한 만큼, 이를 CI gate나 자동 regression metric으로 바로 쓰려면 추가적인 normalization과 threshold 설계가 필요하다.
그럼에도 Agentic CLEAR는 에이전트 평가가 어디로 가야 하는지 꽤 좋은 방향을 보여 준다.
앞으로의 agent evaluation은 benchmark score 하나로 끝나기 어렵다.
실제 운영팀이 원하는 것은 실패 trace를 모아 보고, recurring issue를 찾고, 어느 node를 고쳐야 하는지 결정하고, 수정 뒤 같은 issue가 줄었는지 확인하는 loop다.
Agentic CLEAR는 이 loop를 “관측성 이후의 평가 레이어”로 정의한다는 점에서, DeepEval류의 테스트 프레임워크와 함께 에이전트 품질 운영의 중요한 축으로 검토할 만하다.