에이전트가 한 번 문제를 풀며 남긴 trace는 꽤 풍부하다.
어떤 파일을 열었는지, 어떤 명령을 실행했는지, 어디서 실패했고 어떤 검증 피드백을 받았는지가 모두 남는다.
하지만 그 trace를 다음 작업에 다시 붙여 넣는 것과, 미래의 에이전트가 읽고 따를 수 있는 절차적 스킬로 추상화하는 것은 다른 문제다.
SkillEvolBench: Benchmarking the Evolution from Episodic Experience to Procedural Skills는 바로 이 간극을 벤치마크로 만든다.
논문의 질문은 “스킬이 있으면 도움이 되는가”가 아니라, 더 좁고 까다롭다.
한 번의 작업 경험이 verifier feedback을 거쳐 외부 skill library에 기록된 뒤, 라이브러리가 frozen된 상태에서도 context shift, adversarial shortcut, composition을 견딜 수 있는가를 본다.
공식 arXiv 초록과 프로젝트 페이지 기준으로 SkillEvolBench는 180개 tasks, 6개 real-world agent environments, 30개 skill families를 포함한다.
실험은 Claude Code, Codex CLI, Gemini CLI라는 세 agent harness와 10개 model configuration으로 수행된다.
결론은 다소 냉정하다.
현재 에이전트는 acquisition이나 replay에서 지역적으로 적응하는 경우가 있지만, 그 경험을 안정적인 reusable skill로 만드는 데는 아직 약하다.
특히 raw trajectory reuse가 distilled skill보다 자주 더 낫다는 결과는, 지금의 skill abstraction이 유용한 문맥 단서를 버리고 있을 수 있음을 보여 준다.
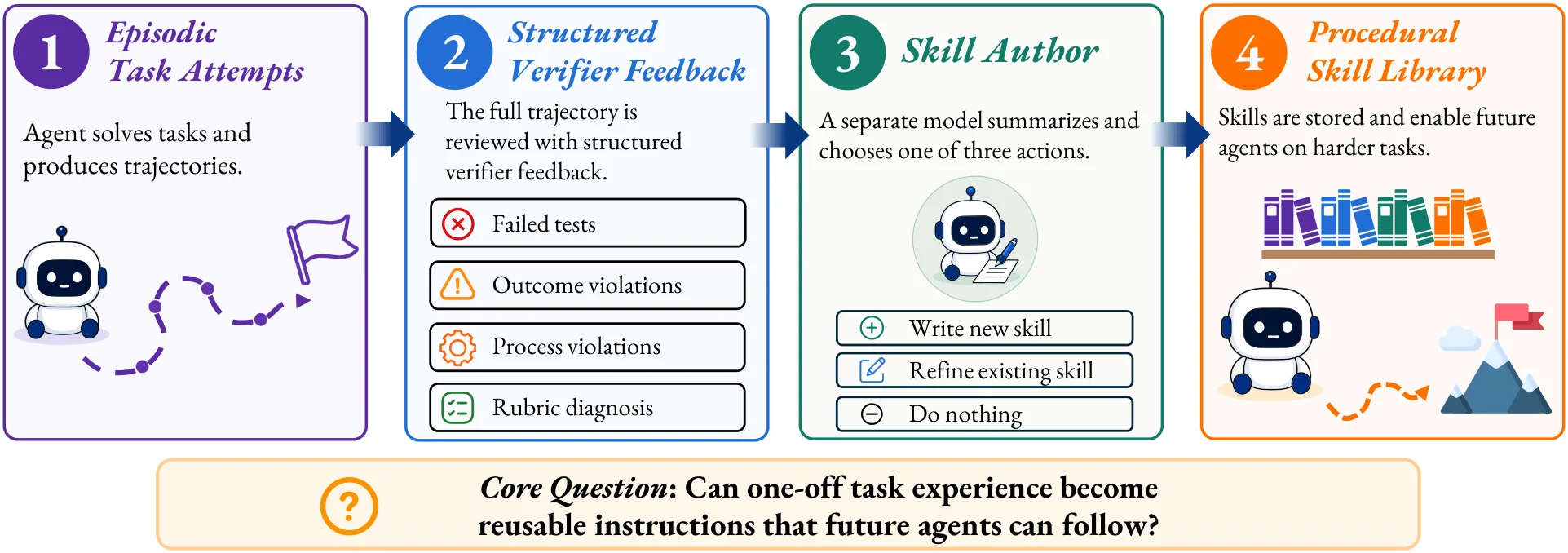
무엇을 평가하려는가
SkillEvolBench가 겨냥하는 대상은 에이전트의 “기억” 일반이 아니다.
더 정확히는 episodic experience에서 procedural skill로 넘어가는 변환 단계다.
기존 experience reuse 방식은 과거 trajectory, reflection, exemplar를 검색해 다음 task에 넣는 쪽에 가깝다.
이것도 유용하지만, 과거 episode에는 재사용 가능한 절차와 우연한 fixture detail, 실패한 가설, 임시 patch가 섞여 있다.
미래 task가 표면적으로 조금만 바뀌어도 그대로 replay하기 어렵다.
반대로 skill은 “언제 이 절차를 적용하고, 어떤 순서로 무엇을 점검하며, 어떤 실패를 피해야 하는가”를 명시해야 한다.
이 차이를 측정하기 위해 논문은 각 task family를 여섯 역할로 나눈다.
앞의 세 역할은 학습 구간이고, 뒤의 세 역할은 frozen deployment 구간이다.
| 단계 | 역할 | 평가 의도 |
|---|---|---|
| Acquisition | canonical | 기본 절차를 처음 노출한다 |
| Acquisition | enriched | 초기 절차가 놓치는 sub-capability를 드러낸다 |
| Acquisition | variant | 표면 형식을 바꾸되 같은 latent procedure를 유지한다 |
| Frozen deployment | context-shift | 더 넓은 요청 속에서 필요한 skill을 암묵적으로 호출하는지 본다 |
| Frozen deployment | adversarial | 얕은 검증을 통과할 수 있는 shortcut에 저항하는지 본다 |
| Frozen deployment | composition | 목표 skill이 다른 skill과 결합되는지 본다 |
이 설계가 중요한 이유는 replay 성능과 transfer 성능을 분리하기 때문이다. acquisition task를 다시 풀 때 좋아지는 것은 “원래 문제를 더 잘 기억한다”는 신호일 수 있다.
하지만 deployment task에서 library update가 금지된 상태로 context shift와 composition을 통과해야, 비로소 경험이 절차적 지식으로 굳었다고 볼 수 있다.
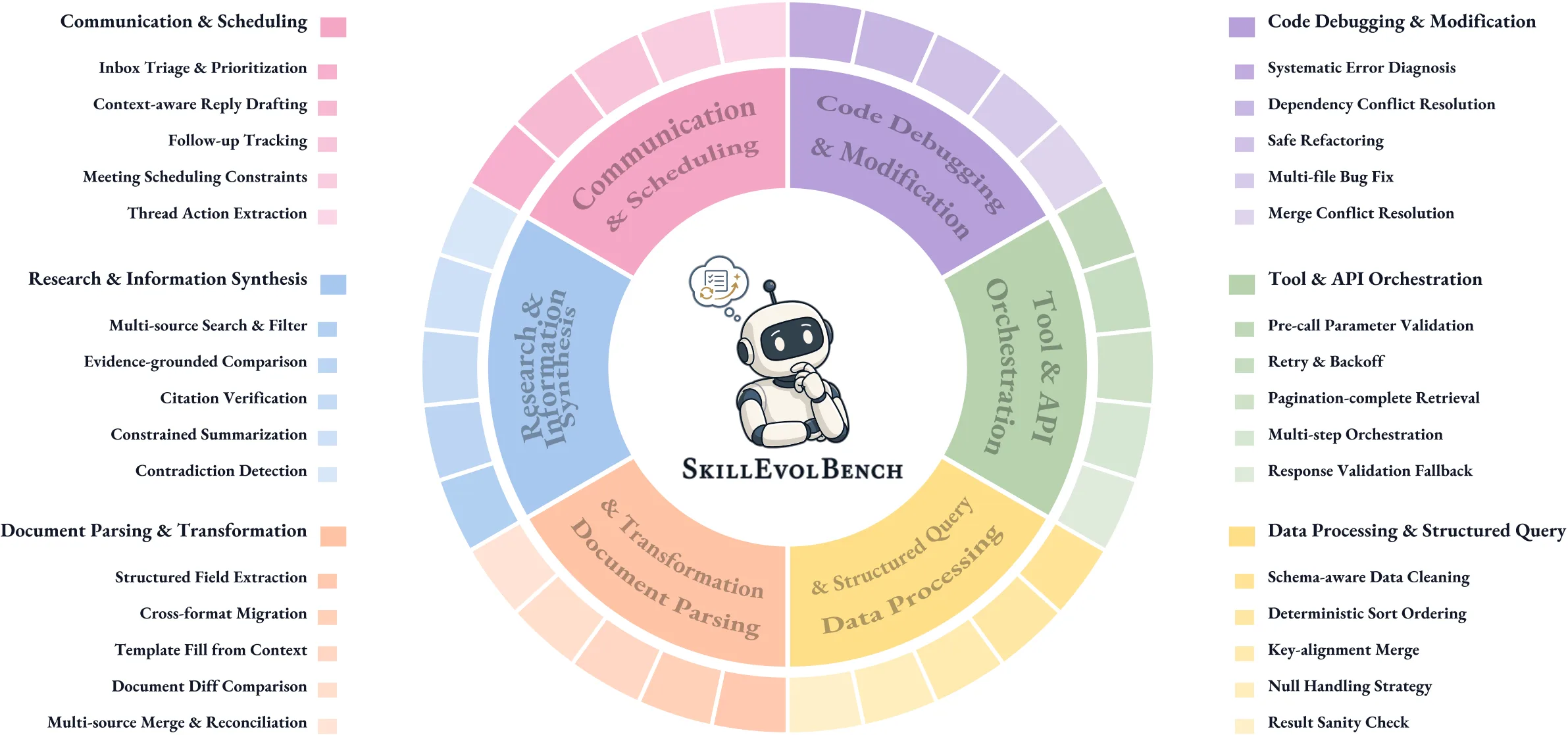
벤치마크 구조와 프로토콜
6개 환경은 agent work의 실제 작업 형태를 넓게 덮는다.
논문과 프로젝트 페이지는 code modification, API orchestration, data processing, document transformation, research synthesis, communication operations를 예로 든다.
여기서 family는 주제 라벨이 아니라 반복 가능한 절차 단위다.
예를 들어 diagnosis, validation, extraction, reconciliation, coordination처럼 “다른 fixture에서도 적용될 수 있는 방법”이 family의 중심이다.
프로토콜은 environment-scoped lifelong episode로 동작한다.
한 environment 안에서는 acquisition task를 수행하면서 compacted trajectory summary와 verifier feedback이 생성된다.
별도의 host-side Skill Author가 이 evidence와 현재 family skill state를 보고 skill을 새로 쓰거나, 고치거나, 업데이트를 건너뛴다.
이후 deployment에 들어가면 library는 frozen된다.
에이전트는 skill을 읽고 사용할 수 있지만, 더 이상 만들거나 수정할 수 없다. deployment가 끝나면 replay로 acquisition task를 다시 풀어 local recovery를 측정하고, 다음 environment로 넘어갈 때 library scope를 reset한다.
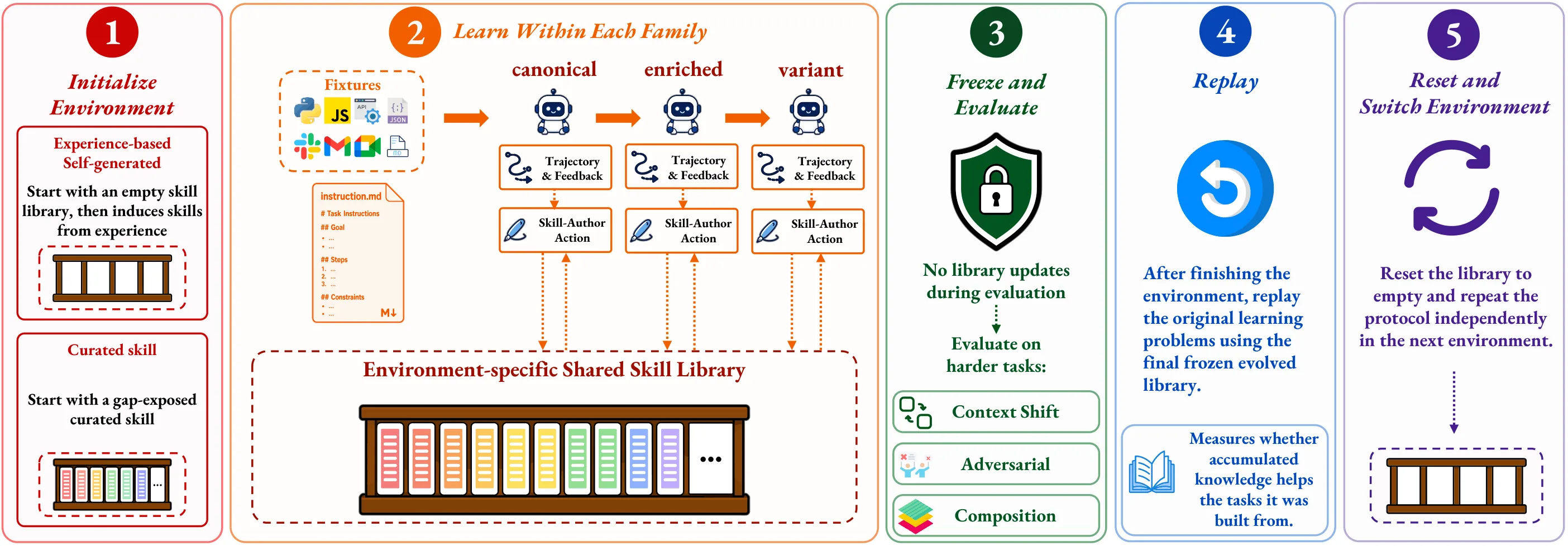
실험 조건도 이 분리를 반영한다.
| 조건 | 의미 |
|---|---|
| NO-SKILL | persistent memory나 skill library 없이 base capability를 측정 |
| RAW-TRAJECTORY | 같은 family의 compacted acquisition trajectory를 직접 검색해 사용 |
| CURATED-STATIC | human-written gap-exposed curated skill을 주되 수정하지 않음 |
| CURATED-REVISION | curated seed를 실패한 acquisition attempt 이후 수정 |
| CURATED-REVISION-ALWAYS | acquisition attempt마다 curated skill을 수정 |
| SELFGEN-ZERO-SHOT | metadata만 보고 생성한 skill을 고정 사용 |
| SELFGEN-REVISION | canonical trajectory evidence에서 skill을 유도하고 이후 실패 시 수정 |
| SELFGEN-ALWAYS | acquisition attempt마다 self-generated skill을 업데이트 |
측정 지표는 Learning Success Rate(LSR), Replay Success Rate(RSR), Deployment Success Rate(ESR), Context-Shift Success Rate(CSSR), Adversarial Robustness Success Rate(ARSR), Composition Success Rate(CompSR)로 나뉜다.
이 지표 분해가 SkillEvolBench의 핵심 장점이다.
하나의 평균 점수만 보면 “skill이 도움이 됐다”처럼 보이는 경우도, CSSR에서는 invocation 실패, ARSR에서는 shortcut 취약성, CompSR에서는 weak modularity로 갈라질 수 있다.
공개된 근거에서 확인되는 점
Primary source 기준으로 확인한 공개 상태는 다음과 같다.
| 공개 표면 | 확인한 내용 | 해석 |
|---|---|---|
| arXiv | 2605.24117, v1 submitted 2026-05-22, cs.AI, arXiv DOI pending |
논문의 canonical identity와 초록·실험 서술의 기준 |
| Project page | overview, official figures, leaderboard script, Paper button 제공 | benchmark positioning과 시각 자료가 가장 깔끔하게 정리됨 |
| GitHub search | skillevolbench/skillevolbench.github.io는 project page repo로 확인 |
별도 실행 코드 repo는 project page에서 Code Coming soon으로 표시됨 |
| Hugging Face dataset API | skillevolbench/skillevolbench, license cc-by-4.0, skills 30 rows, tasks 180 rows |
data artifact는 공개되어 있으며 skills/tasks parquet config를 제공 |
| Project page buttons | Code와 Data 버튼은 페이지상 Coming soon 표기 |
project page의 버튼 상태와 HF dataset 공개 상태가 완전히 동기화되어 있지는 않음 |
HF dataset metadata는 특히 useful하다. skills config에는 family id, environment id, latent skill id, description, task ids, gap summaries, curated skill이 들어가고, tasks config에는 task id, skill id, environment, split, role, difficulty, instruction, rubric, task spec, environment/test/solution files가 들어간다.
즉 논문 숫자인 30개 family와 180개 task는 공개 dataset metadata에서도 다시 확인된다.
다만 지금 기준으로 이 공개 상태를 “완전한 runnable benchmark framework가 모두 공개됐다”고 표현하면 과하다. project page의 Code 버튼은 아직 Coming soon이고, dataset card는 메타데이터와 parquet 구조를 제공하지만 별도의 실행 harness repo나 CI runner 문서는 project page에서 직접 연결되어 있지 않다.
따라서 현재 읽을 때는 논문·프로젝트 페이지·HF dataset이 공개된 diagnostic benchmark release로 보는 편이 안전하다.
실험 결과가 말하는 것
논문의 주장은 단순히 “skills do not work”가 아니다.
더 정확한 메시지는 local adaptation은 보이지만 durable skill formation은 불안정하다는 것이다.
첫째, skill 조건은 acquisition이나 replay에서는 좋아질 수 있다.
예를 들어 논문은 SELFGEN-REVISION의 Claude Opus 4.6이 NO-SKILL 대비 LSR +5.5pp, RSR +10.0pp를 보인다고 설명한다.
하지만 같은 조건은 ESR, CSSR, CompSR에서는 하락한다.
이는 agent가 원래 문제 근처에서는 회복했지만, frozen deployment transfer까지 안정화하지 못했다는 뜻이다.
둘째, deployment 지표의 실패 축이 서로 다르다.
GPT-5.4의 CURATED-REVISION-ALWAYS는 ESR, ARSR, CompSR에서 개선되지만 CSSR은 하락한다.
이는 skill 자체가 일부 상황에서는 유효하지만, 더 넓은 request 안에서 필요한 순간에 불러오는 implicit invocation이 약할 수 있음을 뜻한다.
Gemini 3 Flash는 CSSR과 CompSR에서는 강해지는 케이스가 있지만 ARSR이 크게 떨어져 shortcut vulnerability가 드러난다.
셋째, raw trajectory가 distilled skill보다 강한 경우가 많다.
프로젝트 페이지와 논문은 RAW-TRAJECTORY가 평균 RSR, ESR, ARSR, CompSR에서 가장 강한 baseline이라고 설명하며, 해당 평균을 각각 48.2%, 37.6%, 44.7%, 25.7%로 제시한다.
이것은 꽤 중요한 신호다. skill abstraction이 정말 잘 되고 있다면 compact skill이 raw episode를 이겨야 한다.
그런데 많은 경우 raw trace가 보존한 구체적 맥락과 절차 단서가 distilled skill에서 사라진다.
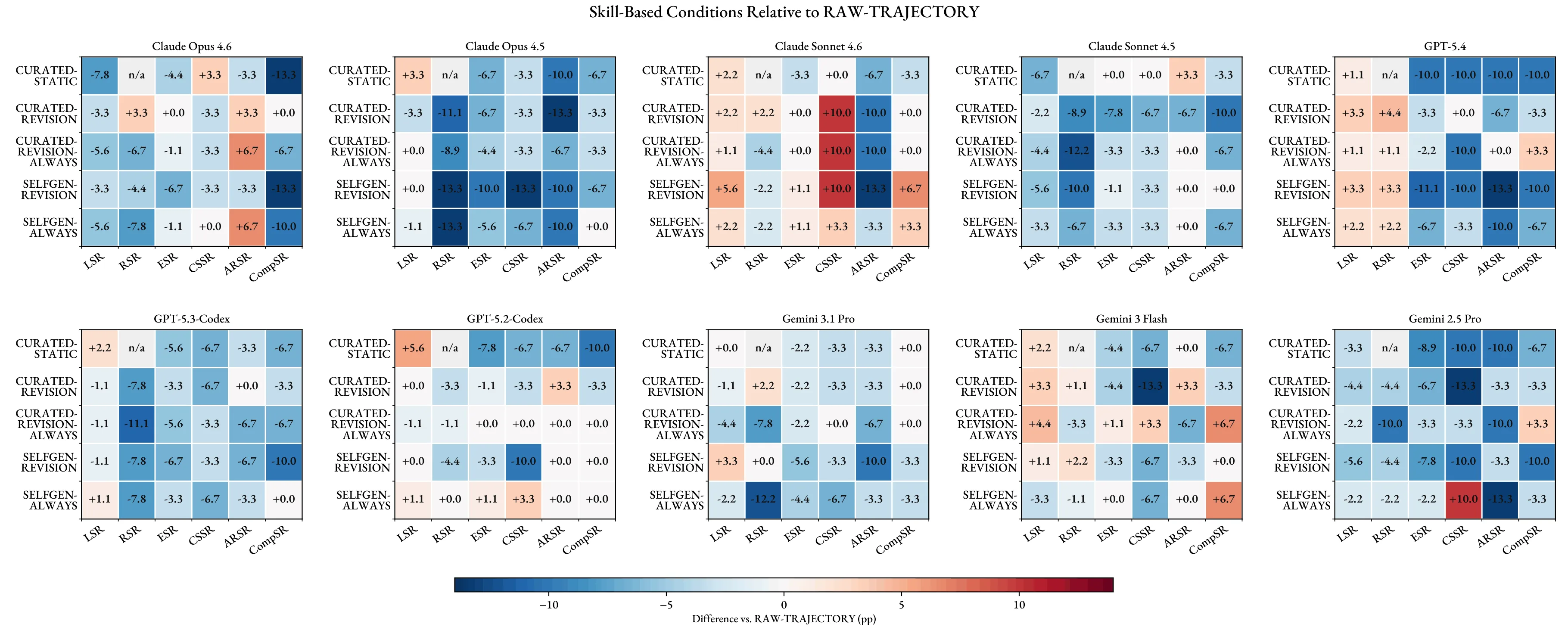
넷째, 더 많이 업데이트한다고 단조롭게 좋아지지 않는다.
ALWAYS 정책은 더 많은 coverage를 만들 수 있지만, episode-specific drift와 procedural clutter를 함께 만든다.
Tier-3 resource forcing도 비슷하다. scripts, references, assets 같은 추가 파일을 더 쓰게 만들면 library는 커지지만, frozen deployment success가 안정적으로 올라가지는 않는다.
논문은 이것을 capacity 문제가 아니라 selective abstraction 문제로 해석한다.
무엇을 저장할지, 무엇을 버릴지, 어떤 resource를 미래 agent가 언제 load해야 할지가 아직 어렵다는 뜻이다.
AI Lab 관점의 해석
SkillEvolBench가 유용한 이유는 agent skill ecosystem의 성숙도를 꽤 날카롭게 찌르기 때문이다.
요즘 많은 agent system은 “memory”, “skills”, “workflow library”, “trajectory reuse”라는 이름으로 외부 지식을 붙인다.
하지만 그 지식이 실제로 durable procedure인지, 아니면 이전 episode의 흔적을 보기 좋게 요약한 것인지는 별도로 검증해야 한다.
이 논문의 설계에서 배울 점은 세 가지다.
- Skill formation은 update 직후가 아니라 frozen deployment에서 봐야 한다. 업데이트가 허용되는 동안 성공한 것은 test-time repair일 수 있다.
- Raw trajectory baseline을 반드시 둬야 한다. distilled skill이 raw trace보다 못하면 abstraction layer가 정보를 잃고 있다는 뜻이다.
- 성공률 하나보다 deployment axis 분해가 중요하다. context shift, adversarial shortcut, composition은 서로 다른 실패 모드다.
실무적으로는 agent memory를 만들 때 “더 많은 메모리”보다 “좋은 persistence policy”가 중요하다는 결론으로 이어진다.
실패한 episode를 바로 skill에 쓰는 것은 위험하다.
성공한 episode도 그대로 skill이 되는 것은 아니다. verifier feedback, process check, hidden edge case, future invocation 조건을 함께 보고, episode-specific detail과 general procedure를 분리해야 한다.
한계와 caveat
첫째, SkillEvolBench 자체가 diagnostic benchmark이므로, 특정 product agent의 운영 성능을 바로 예측한다고 보기는 어렵다.
6개 환경과 30개 family는 넓지만, 각 조직의 실제 workflow와 verifier는 다를 수 있다.
둘째, skill authoring prompt와 update policy의 설계가 결과에 큰 영향을 줄 가능성이 있다.
논문의 결과는 “모든 self-generated skill이 본질적으로 안 된다”라기보다, 현재 비교한 agent harness·model·authoring 조건에서는 robust reusable skill formation이 아직 불안정하다는 증거로 읽어야 한다.
셋째, release maturity는 계속 확인해야 한다. arXiv와 project page는 충분한 설명과 official figure를 제공하고, HF dataset도 공개되어 있다.
그러나 project page의 Code button은 여전히 Coming soon이며, 실행 harness까지 포함한 별도 code release가 공식적으로 연결된 상태는 아니었다.
그럼에도 SkillEvolBench는 agent evaluation에서 매우 중요한 기준선을 제시한다.
앞으로 “우리 에이전트가 경험에서 배운다”고 말하려면, acquisition score가 아니라 frozen deployment에서 context shift, adversarial robustness, composition을 함께 보여 줘야 한다.
그리고 distilled skill이 raw trajectory를 이기지 못한다면, 문제는 retrieval이 아니라 abstraction일 수 있다.
참고 링크
- arXiv: SkillEvolBench: Benchmarking the Evolution from Episodic Experience to Procedural Skills
- arXiv HTML: 2605.24117v1
- Project page: skillevolbench.github.io
- HF Papers: huggingface.co/papers/2605.24117
- HF dataset: skillevolbench/skillevolbench