3D reconstruction, metric depth, camera pose, SLAM, streaming video reconstruction은 모두 “공간 이해”라는 이름 아래 묶이지만, 실제 평가는 자주 따로 논다.
어떤 모델은 짧은 multi-view 입력에서 강하고, 어떤 모델은 긴 주행 시퀀스에서 버티며, 또 어떤 모델은 egocentric 또는 robot wrist-view 같은 embodied setting에서 급격히 흔들린다.
그래서 단일 데이터셋의 평균 점수만으로는 “이 모델이 공간 파운데이션 모델인가”를 판단하기 어렵다.
SpatialBench: Is Your Spatial Foundation Model an All-Round Player?는 이 문제를 벤치마크 설계로 정면에서 다룬다.
논문과 공식 프로젝트 페이지 기준 SpatialBench는 19개 데이터셋, 546개 장면, 72,540개 평가 프레임, 41개 모델 변형, 6개 reconstruction 패러다임, 5개 task suite, 4개 input-density regime을 하나의 deterministic protocol로 묶는다.
핵심 질문은 단순히 “누가 1등인가”가 아니라, 모델이 도메인·시점·입력 밀도·메모리 제약이 바뀌어도 올라운더로 남는가다.
공개 패키지도 논문 하나에 그치지 않는다. arXiv와 Hugging Face Papers 항목은 공식 프로젝트 페이지, GitHub benchmark harness, Hugging Face의 SpatialBenchmark 데이터셋, DA-Next-5M/DA-Next 배포 표면으로 이어진다.
다만 확인 시점의 Hub API에서는 SpatialBenchmark 본체 tar 파일은 올라와 있지만, DA-Next-5M과 DA-Next 저장소는 .gitattributes만 가진 placeholder 상태였다.
따라서 이 글은 SpatialBench의 공개 벤치마크 패키지와 논문 실험을 중심으로 보되, DA-Next 모델/대규모 학습 데이터 공개는 아직 성숙도를 분리해 읽는다.

무엇을 해결하려는가
공간 모델 평가는 지금 세 가지 이유로 흔들리기 쉽다.
첫째, 패러다임이 다르다.
DUSt3R/MASt3R류의 optimization 기반 방법, VGGT/DA3 같은 feed-forward 모델, streaming·chunk-wise 모델, SLAM backend, test-time training 방식은 같은 문제를 푸는 것처럼 보이지만 입력 길이, 메모리 사용, inference protocol이 다르다.
하나의 논문 안에서만 비교하면 그 모델이 유리한 조건이 평가 조건이 되기 쉽다.
둘째, 입력 밀도와 sequence length가 결과를 바꾼다.
짧은 sparse view에서는 full-context attention이 유리하지만, dense long sequence에서는 같은 방식이 GPU 메모리나 시간 제한에 걸릴 수 있다.
반대로 bounded-memory 또는 streaming 모델은 정확도 ceiling은 낮아도 긴 sequence를 끝까지 처리할 수 있다.
SpatialBench가 single, sparse, medium, dense 네 regime을 분리하는 이유다.
셋째, 도메인 shift가 크다. indoor static scene, outdoor roaming, autonomous driving, egocentric view, robot wrist-view는 카메라 motion, scale, occlusion, object interaction, depth distribution이 다르다.
기존 벤치마크가 normal viewpoint 중심이면 embodied/robotics setting에서 모델이 얼마나 무너지는지 잘 보이지 않는다.
핵심 아이디어 / 구조 / 동작 방식
SpatialBench의 설계는 “가능한 많은 모델을 한 표에 넣는다”보다 “같은 장면과 같은 frame index로 평가한다”에 가깝다.
모든 scene은 RGB, metric depth, camera-to-world pose, intrinsics 형식으로 정규화되고, 각 scene에서 사용할 평가 frame은 미리 고정된다.
즉 모델마다 임의의 frame sampling을 쓰지 않고, 같은 single/sparse/medium/dense split을 소비한다.
평가 축은 크게 다섯 가지다.
Depth estimation은 AbsRel, SqRel, RMSE, threshold accuracy를 본다.
Camera pose는 rotation/translation accuracy와 AUC를 본다.
Medium/dense regime에서는 trajectory ATE/RPE와 point-cloud reconstruction F-score도 함께 보고, 일부 prior-aware setting에서는 depth 또는 camera prior를 넣었을 때의 개선 폭을 측정한다.
따라서 “깊이만 잘 맞춘 모델”과 “pose/trajectory까지 안정적인 모델”을 분리해서 읽을 수 있다.
| 구성 요소 | SpatialBench에서의 의미 | 왜 중요한가 |
|---|---|---|
| Deterministic frame sampling | 546개 장면의 평가 프레임을 single/sparse/medium/dense로 고정 | 모델별 cherry-picking이나 sampling 차이를 줄인다 |
| 5개 공간 도메인 | room, roaming, driving, ego-view, wrist-view | normal view 성능과 embodied OOD 성능을 분리한다 |
| 6개 모델 패러다임 | optimization, feed-forward, online/streaming, chunk-wise, SLAM, TTT | 서로 다른 reconstruction 전략을 같은 protocol로 비교한다 |
| 5개 task suite | depth, pose, trajectory, point cloud, prior-input 분석 | 하나의 평균 점수 대신 실패 모드를 쪼갠다 |
| 4개 입력 밀도 | single, sparse, medium, dense | 정확도 ceiling과 long-sequence scalability를 동시에 본다 |
GitHub 저장소는 이 설계를 실행 가능한 harness로 옮기려 한다. benchmark/README.md는 YAML config와 model adapter 방식으로 새 모델을 넣는 흐름을 설명하고, config 디렉터리를 end-to-end, online, chunk, TTT, prior, optimization 등으로 나눠 둔다.
README 기준으로 많은 adapter가 이미 populated 상태지만, slam/ config는 reserved/empty로 표시된다.
즉 논문은 넓은 비교를 제시하지만, 공개 repo는 아직 main branch 중심으로 빠르게 채워지는 초기 benchmark harness에 가깝다.
공개된 근거에서 확인되는 점
논문의 main table은 SpatialBench의 메시지를 꽤 선명하게 보여 준다.
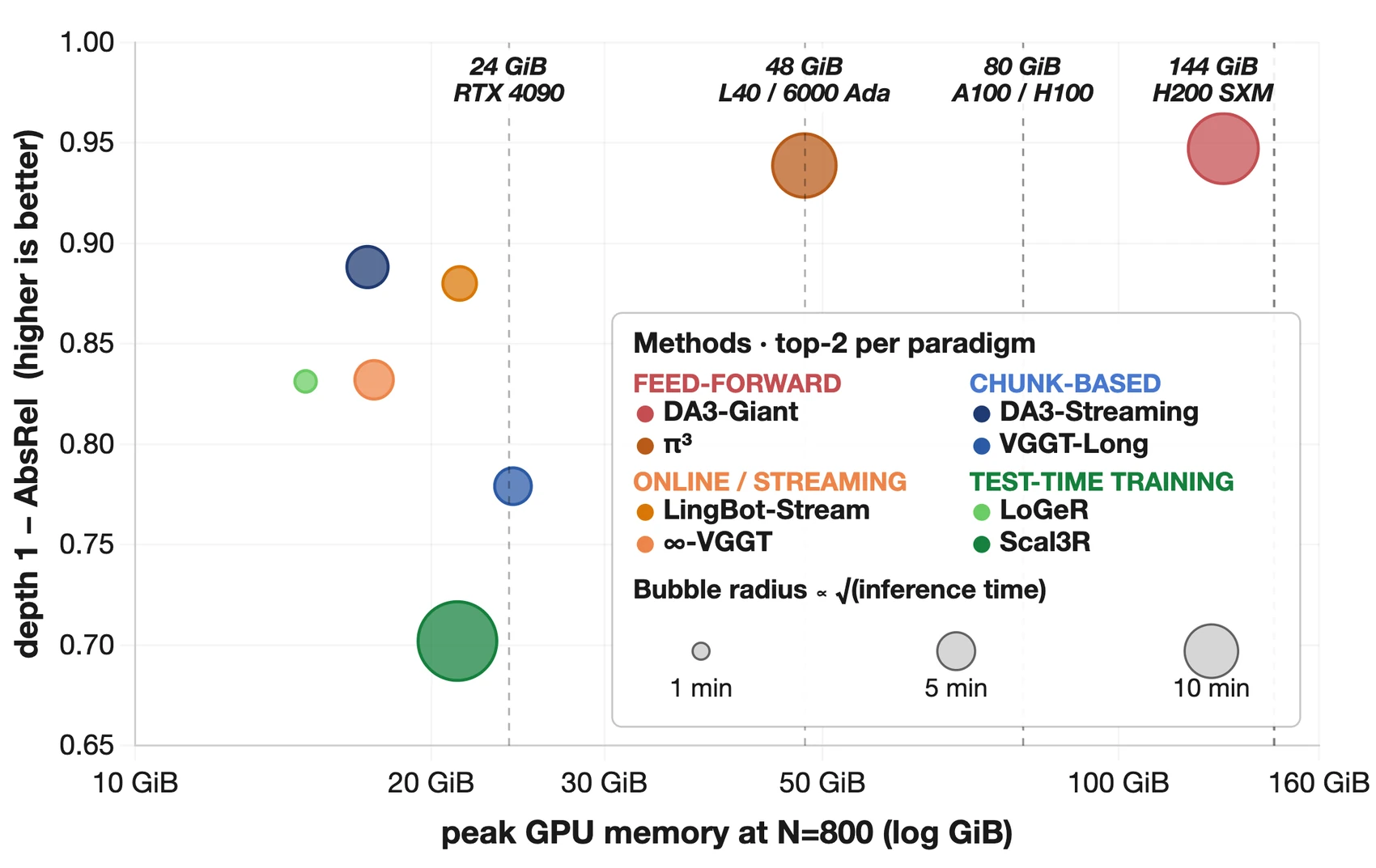
DA3-Giant, VGGT-Omega, π³ 계열처럼 full-context 또는 강한 feed-forward 계열은 sparse/medium setting에서 높은 AUC@30과 낮은 depth error를 낼 수 있다.
하지만 dense regime으로 넘어가면 OOM 또는 timeout이 자주 등장한다.
반대로 VGGT-Long, DA3-Streaming, LongStream 계열은 dense long sequence를 처리할 수 있지만, 정확도와 trajectory 품질에서 별도 trade-off를 갖는다.
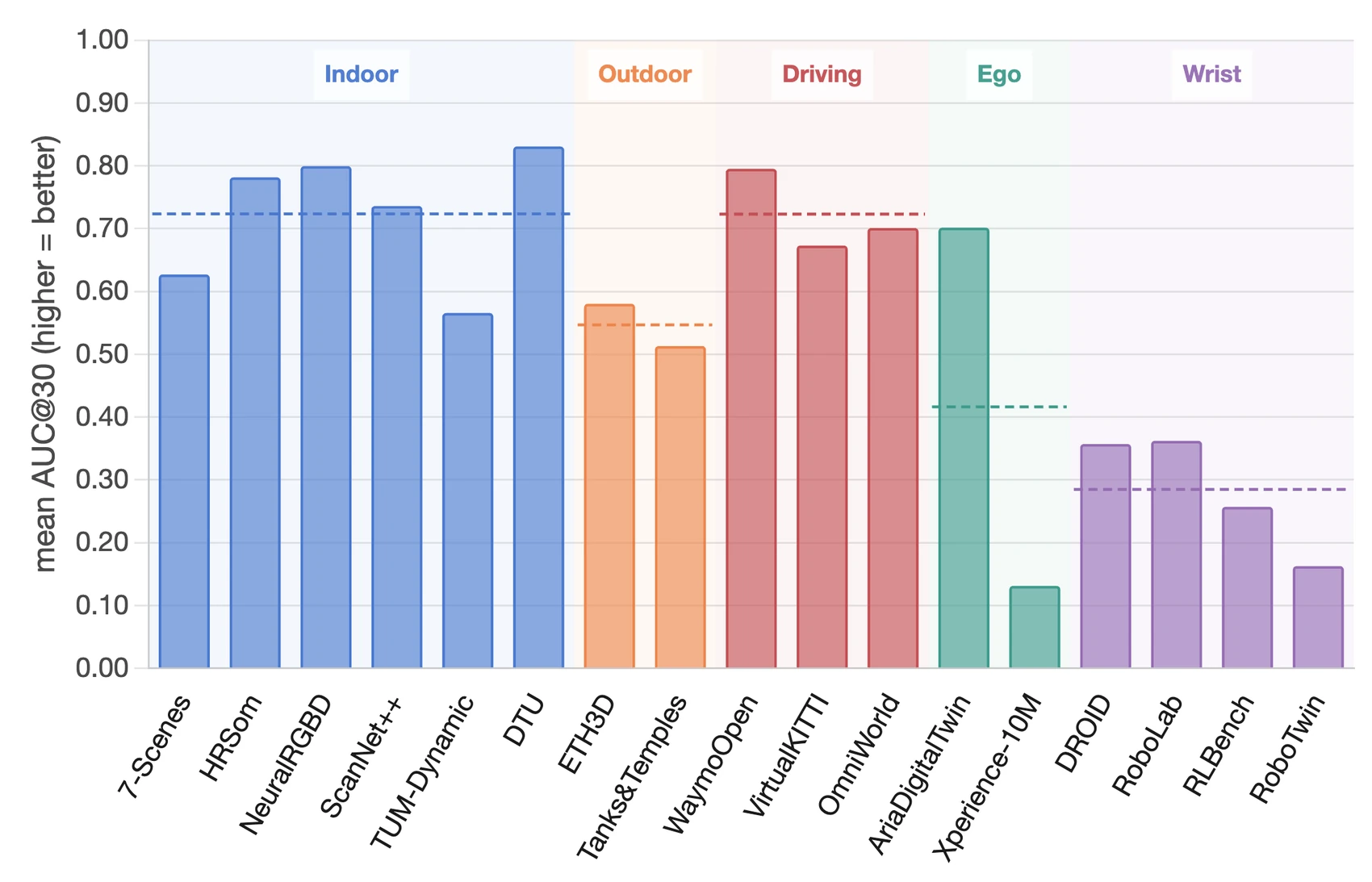
도메인별 결과도 중요하다.
논문은 egocentric과 wrist-view가 현재 모델의 주요 OOD failure mode라고 해석한다.
공식 domain-level plot에서도 indoor와 driving은 상대적으로 높은 AUC@30 평균을 보이지만, wrist-view는 전반적으로 낮고 ego-view는 dataset별 편차가 크다.
이는 로봇 조작, wearable camera, hand-object interaction처럼 카메라와 객체가 강하게 얽히는 상황이 아직 공간 파운데이션 모델의 약점임을 시사한다.
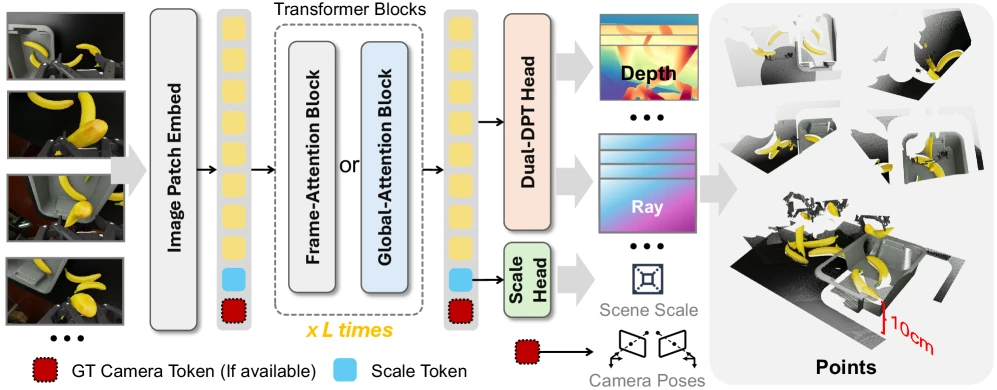
DA-Next는 이 failure mode를 겨냥해 제안된다.
논문은 DA-Next-5M을 Xperience, Aria Digital Twin, Colosseum, HOI4D, RLBench, Robolab, RoboTwin에서 모은 5.5M frames / 22K scenes 또는 sequences 규모의 egocentric·wrist-view 중심 데이터셋으로 설명한다.
DA-Next 모델은 Depth Anything 3 / DA3-Giant 계열을 기반으로 scale token을 추가하고, 선택적으로 camera pose를 token으로 넣어 metric scale과 geometric guidance를 학습한다.
Main table의 headline은 DA-Next가 DA3-Giant 대비 sparse/medium setting에서 depth AbsRel을 각각 47.4% / 59.3% 낮추고, camera AUC@30을 3.1% / 5.5% 높인다는 점이다.
다만 DA-Next도 dense regime에서는 OOM으로 표시된다.
즉 DA-Next는 embodied/wrist domain gap을 줄이는 강한 baseline이지만, “긴 dense sequence까지 한 번에 해결한 올라운더”라기보다 data/domain alignment로 성능 ceiling을 끌어올린 방향에 가깝다.
공개 표면을 정리하면 다음과 같다.
| 공개 표면 | 확인되는 내용 | 해석 |
|---|---|---|
| HF Papers / arXiv | 2605.27367, SpatialBench, v1, cs.CV, CC BY 4.0 |
논문의 canonical identity와 초록·수치의 기준 |
| Project page | benchmark coverage, findings, scene explorer, leaderboard, official figures | 독자가 결과와 시각 자료를 확인할 수 있는 주 공개 표면 |
GitHub Ropedia/SpatialBench |
benchmark harness, README, leaderboard, model adapters, pyproject.toml license text CC-BY-4.0 |
실행을 의도한 초기 공개 repo지만 tags/releases는 없음 |
HF dataset ropedia-ai/SpatialBenchmark |
_split_log.jsonl, single/sparse/medium/dense/pointcloud.tar, 약 107.9GB storage, 현재 API downloads 59 / likes 1 |
SpatialBench 평가 데이터 패키지는 실제로 올라와 있음 |
HF dataset/model DA-Next-5M, DA-Next |
현재 API 기준 .gitattributes만 존재, usedStorage 0, gated false |
논문이 소개한 데이터/모델의 배포 표면은 있으나 아직 실질 파일은 비어 있음 |
실무 관점에서의 해석
SpatialBench의 가장 큰 의미는 공간 모델 평가를 정확도 표 하나에서 운영 조건 표준화로 옮긴다는 데 있다.
실제 팀이 3D reconstruction 모델을 고를 때는 “AUC@30이 가장 높은가”만 묻지 않는다.
어떤 GPU에서 돌아가는지, dense video를 끝까지 처리하는지, metric depth와 pose를 동시에 주는지, robot wrist-view처럼 제품에 가까운 입력에서 버티는지를 함께 본다.
SpatialBench는 이 질문들을 한 프로토콜 안에 놓는다.
또 하나의 메시지는 data scaling에 대한 경고다.
논문은 단순히 더 많은 데이터셋을 섞는 것보다 도메인 정렬과 데이터 품질이 중요하다고 주장한다.
Egocentric/wrist-view가 약점이면, 일반 indoor/outdoor 데이터를 더 넣는 것만으로는 부족하다.
실제 실패 도메인에 맞춘 high-quality metric supervision, pose refinement, mask-based curation이 필요하다는 것이다.
DA-Next-5M을 함께 제안한 이유도 여기에 있다.
실무적으로는 SpatialBench를 “모델 하나를 골라 주는 leaderboard”보다 평가 설계 템플릿으로 읽는 편이 유용하다.
예를 들어 로봇팀이라면 wrist-view와 dense regime을, AR/egocentric팀이라면 ego-view와 metric scale을, mapping팀이라면 trajectory/point-cloud F-score를 더 크게 봐야 한다.
평균 점수가 높아도 제품 입력 도메인에서 낮으면 선택 기준에서 탈락할 수 있다.
반대로 공개 성숙도는 아직 조심스럽게 봐야 한다.
GitHub repo는 공개 직후 기준 stars 77, forks 0, open issues 1, tags/releases 없음으로 확인됐다.
GitHub API의 license 필드는 null이었고, top-level LICENSE 파일도 보이지 않았지만 pyproject.toml은 CC-BY-4.0 license text를 포함한다.
또한 DA-Next-5M/DA-Next Hub 저장소는 링크는 있지만 아직 파일이 비어 있었다.
이 조합은 “논문·프로젝트·benchmark dataset 중심의 초기 공개 release”로 보는 것이 안전하다.
한계와 caveat
첫째, SpatialBench는 deterministic protocol을 제공하지만, 3D/spatial model의 모든 실제 사용 조건을 덮지는 않는다.
긴 streaming, SLAM backend, prior injection, test-time training은 계산 비용과 구현 detail에 민감하다.
논문 표의 OOM/timeout은 단순 실패라기보다 각 방법의 operating envelope를 함께 보여 주는 값이다.
둘째, DA-Next의 개선은 중요한 baseline이지만 dense long-sequence scalability 문제를 완전히 해결한 것은 아니다.
Table 1에서 DA-Next는 sparse/medium에서 강한 개선을 보이나 dense regime은 OOM으로 남는다.
따라서 DA-Next는 domain-aligned training의 효과를 보여 주는 사례이지, 모든 input density에서 올라운더가 된 증거는 아니다.
셋째, 공개 Hub 표면이 빠르게 바뀔 수 있다.
확인 시점에는 SpatialBenchmark 데이터셋 tar bundle이 올라와 있었고, DA-Next-5M/DA-Next는 placeholder에 가까웠다.
이후 모델 weight나 대규모 데이터가 채워지면 재현성과 사용성 평가는 달라질 수 있다.
그럼에도 SpatialBench가 제시하는 방향은 분명하다.
공간 파운데이션 모델은 이제 “한 장면을 잘 복원한다”에서 “서로 다른 도메인과 입력 밀도, 메모리 제약을 가로질러 어디까지 버티는가”로 평가되어야 한다.
SpatialBench는 그 질문을 꽤 큰 공개 프로토콜로 만든 첫 기준선 중 하나다.
참고 링크
- Hugging Face Papers: SpatialBench: Is Your Spatial Foundation Model an All-Round Player?
- arXiv: arXiv:2605.27367 / HTML
- Project page: ropedia.github.io/SpatialBench
- GitHub: Ropedia/SpatialBench
- Hugging Face dataset: ropedia-ai/SpatialBenchmark
- Hugging Face dataset: ropedia-ai/DA-Next-5M
- Hugging Face model: ropedia-ai/DA-Next