임베딩 모델은 검색 시스템의 가장 아래쪽 인터페이스다.
사용자가 쿼리를 넣고, 문서·이미지·영상·오디오·PDF를 찾아내며, RAG가 모델에 넣을 근거를 고르는 거의 모든 단계가 결국 “무엇을 같은 벡터 공간에 놓을 것인가”로 환원된다.
그런데 실제 데이터는 텍스트만으로 존재하지 않는다.
제품 사진, 슬라이드 PDF, 회의 녹음, 짧은 영상, 차트와 표가 모두 같은 지식 저장소 안에 섞인다.
Gemini Embedding 2: A Native Multimodal Embedding Model from Gemini는 이 문제를 Google DeepMind가 Gemini 계열 모델로 어떻게 풀었는지 설명하는 기술 보고서다.
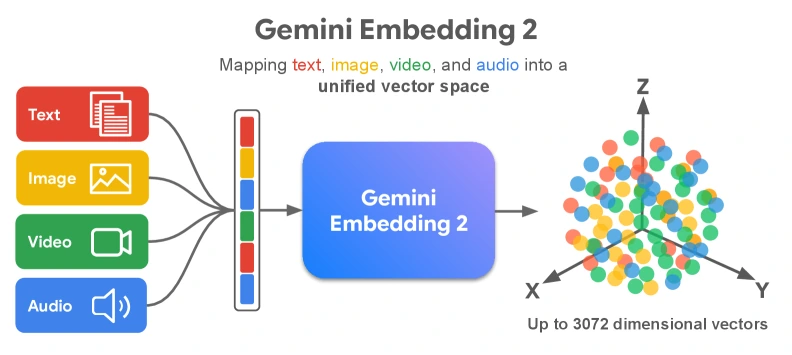
핵심은 별도의 이미지 임베더, 오디오 임베더, 비디오 임베더를 이어 붙이는 것이 아니라, 텍스트·이미지·비디오·오디오·문서와 그 조합을 하나의 unified embedding space로 직접 보내는 네이티브 멀티모달 임베딩 모델을 만든다는 점이다.
공식 문서 기준 모델 ID는 gemini-embedding-2이며, Gemini API와 Vertex AI/Gemini Enterprise 계열 문서에서 제공된다.
Google의 2026년 3월 발표 당시에는 Public Preview로 소개됐고, 현재 Gemini API 모델 문서에는 Stable 모델로 정리되어 있다.
공개된 것은 API/서비스형 모델이지 오픈 웨이트는 아니므로, 이 글은 “로컬에 받아 실행하는 모델 카드”가 아니라 검색·RAG 제품 설계 관점에서 읽는 멀티모달 embedding report에 가깝다.
무엇을 해결하려는가
기존 멀티모달 검색 파이프라인은 대개 cascade 형태다.
오디오는 ASR로 텍스트화한 뒤 텍스트 임베딩을 만들고, 영상은 프레임 추출·captioning·OCR을 거쳐 텍스트 또는 이미지 임베딩으로 바꾸며, PDF는 OCR과 layout parser를 통과한다.
이 방식은 구현하기 쉽지만, 각 변환 단계가 정보를 버린다.
ASR이 애매한 발음을 잘못 텍스트로 고정하면 downstream 검색은 이미 바뀐 쿼리를 검색하게 된다.
영상도 1개의 caption으로 압축하는 순간 장면·시간·음성·텍스트의 상호작용이 사라진다.
Gemini Embedding 2의 문제의식은 이 병목을 모델 내부로 가져오는 것이다.
논문은 Gemini의 멀티모달 능력을 활용해 arbitrary combination of interleaved inputs를 embedding으로 만들고, single-modality task, cross-modal task, multimodal task를 함께 학습한다.
즉 “이미지를 설명문으로 바꾼 뒤 텍스트 검색한다”가 아니라, 이미지와 텍스트가 같은 의미 공간에서 직접 비교되도록 훈련한다는 방향이다.
이 방향은 RAG에도 중요하다.
에이전트가 보고서 PDF, 제품 사진, 녹음된 회의, 짧은 데모 영상까지 근거로 써야 한다면, retrieval layer가 텍스트 chunk만 잘 찾아서는 부족하다.
하나의 쿼리로 텍스트 문서와 이미지, 오디오, 영상 근거를 함께 후보화할 수 있어야 한다.
Gemini Embedding 2는 바로 그 retrieval substrate를 목표로 한다.
핵심 아이디어 / 구조 / 동작 방식
논문이 설명하는 모델 구조는 “Gemini를 encoder로 다시 쓰기 위한 임베딩화”에 가깝다.
입력은 modality별 토큰화 과정을 거쳐 Gemini 계열 모델 M에 들어가고, 평균 풀링과 projection 함수 f를 거쳐 최종 embedding이 된다.
학습 예제는 query, positive target, 선택적 hard negative target으로 구성되며, loss는 cosine similarity 기반 NCE와 in-batch negative를 사용한다.
분류처럼 label 수가 작은 task에서는 같은 query나 같은 positive target이 batch 안에서 잘못 negative로 쓰이지 않도록 mask를 둔다.
중요한 설계는 세 가지다.
첫째, multi-task multi-stage training이다.
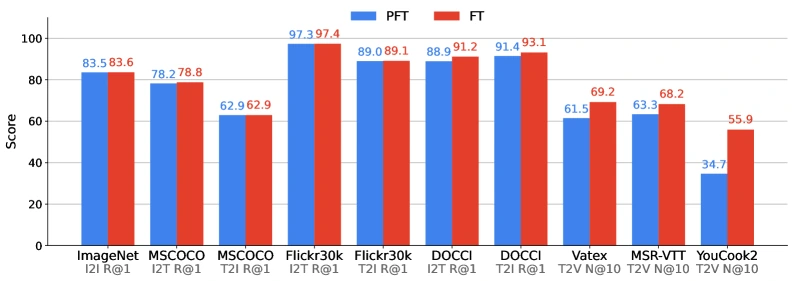
Pre-fine-tuning 단계에서는 auto-regressive generation에 맞춰져 있던 파라미터를 encoding task에 적응시키기 위해 대량의 noisy query-target pair를 사용한다.
이 단계는 image, text, code task를 중심으로 진행된다.
Fine-tuning 단계에서는 text, code, document, image, audio, video task를 모두 포함하고, 일부 task는 hard negative triplet까지 사용한다.
논문은 modality 간 균형이 sampling rate와 batch size에 민감하다고 밝힌다.
둘째, Matryoshka Representation Learning, MRL이다.
기본 embedding은 3,072차원이지만, 하나의 모델이 768·1,536차원 같은 작은 prefix dimension에서도 쓸 수 있도록 overlapping sub-dimension loss를 함께 둔다.
공식 Gemini API 문서도 gemini-embedding-2의 output dimension을 128부터 3,072까지 유연하게 지원하며, 권장 dimension으로 768, 1,536, 3,072를 제시한다.
실무적으로는 품질, 저장 비용, ANN latency 사이의 스위치를 모델 바깥이 아니라 output dimensionality 설정으로 조절할 수 있다는 뜻이다.
셋째, model soup이다.
Google은 서로 다른 fine-tuning run 또는 같은 run의 checkpoint를 단순/가중 평균해 modality별 일반화 성능을 끌어올린다.
이 대목은 멀티모달 임베딩의 어려움을 잘 보여 준다.
특정 영상 benchmark에 맞춰 fine-tuning하면 그 benchmark는 좋아지지만 다른 domain이 떨어질 수 있다.
논문 Table 6도 MSR-VTT와 Vatex 데이터를 추가하면 해당 지표는 크게 오르지만 YouCook2는 약간 손상될 수 있음을 보이고, model soup가 이 trade-off를 완화한다고 설명한다.
공개된 근거에서 확인되는 점
논문과 Google DeepMind 페이지가 강조하는 첫 번째 숫자는 cross-modal retrieval 성능이다.
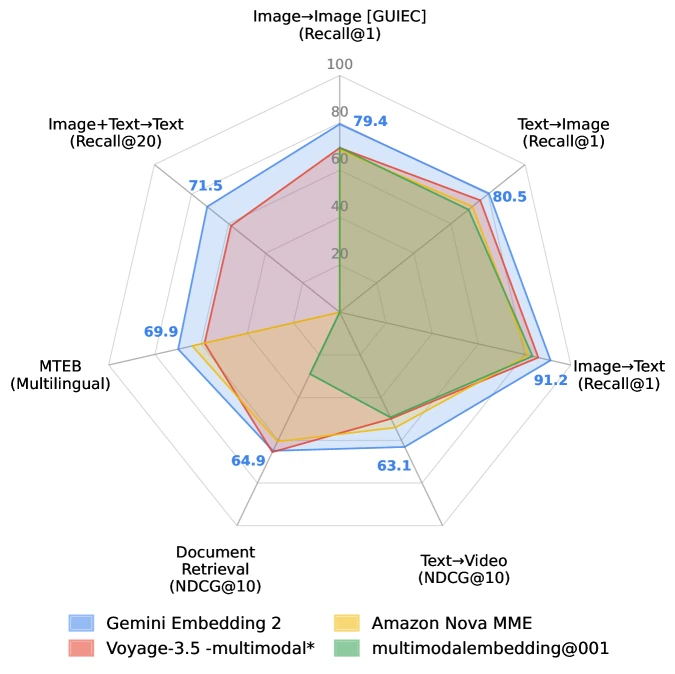
Table 1 기준 Gemini Embedding 2는 전체 평균 77.2로 Amazon Nova MME 68.2, Voyage-3.5-multimodal 70.0, Google legacy multimodalembedding@001 64.1보다 높게 보고된다.
세부적으로는 MSCOCO text-to-image Recall@1 62.9, Flickr30k 89.1, DOCCI 93.4, TextCaps 89.6을 기록한다. image-to-text에서도 MSCOCO 78.8, Flickr30k 97.4, DOCCI 91.3, TextCaps 97.4다.
비디오 쪽에서는 text-to-video NDCG@10 평균 63.1을 제시한다.
Vatex 68.8, MSR-VTT 68.0, YouCook2 52.5로, 비교 대상보다 대체로 높다.
논문은 평가 시 video를 1 FPS로, 최대 32 frame까지 embed했다고 적는다.
이 조건은 실무적으로 중요하다.
Gemini Embedding 2가 영상을 지원한다는 말은 “긴 영화를 한 번에 완벽하게 요약 검색한다”가 아니라, 모델과 API가 허용하는 범위 안에서 영상 정보를 embedding pipeline에 직접 넣을 수 있다는 뜻에 가깝다.
문서 검색에서는 ViDoRe V2 NDCG@10 64.9를 보고한다.
이 수치는 Amazon Nova MME 60.6과 legacy multimodal model 28.9보다 높지만, Voyage-3.5-multimodal의 65.5에는 약간 낮다.
따라서 “모든 benchmark에서 절대 1위”라기보다, 텍스트·이미지·비디오·오디오·문서까지 모두 다루는 단일 모델로 폭넓은 성능을 확보했다는 쪽이 더 정확한 해석이다.
텍스트 전용 능력도 유지된다.
Table 2에서 Gemini Embedding 2는 MMTEB Multilingual mean by task 69.9를 기록하며, 이전 text-only Gemini Embedding 68.4/68.32보다 높게 보고된다.
MTEB Code v1 mean by task는 84.0으로, 이전 Gemini Embedding 76.0보다 크게 오른다.
논문은 Gemini로 합성한 고품질 코드 데이터가 CodeFeedbackMT, CodeFeedbackST, SyntheticText2SQL 같은 task에서 평균 +15.81 point 개선을 만들었다고 분석한다.
| 항목 | Gemini Embedding 2에서 확인되는 값 | 해석 |
|---|---|---|
| Output dimension | 128–3,072, 권장 768/1,536/3,072 | MRL 기반으로 저장 비용과 품질을 조절 |
| Input token limit | 8,192 | 긴 텍스트 chunk와 코드·문서 맥락에 유리 |
| Text → Image MSCOCO R@1 | 62.9 | caption/image retrieval에서 강한 cross-modal alignment |
| Text → Video Vatex NDCG@10 | 68.8 | 영상 검색을 별도 caption pipeline 없이 직접 다루는 방향 |
| ViDoRe V2 NDCG@10 | 64.9 | layout·embedded text가 섞인 문서 검색에서 경쟁력 |
| MMTEB multilingual mean | 69.9 | 멀티모달화가 텍스트 benchmark를 희생하지 않았다는 근거 |
| MTEB Code mean | 84.0 | 코드 검색에서도 이전 Gemini Embedding 대비 큰 개선 |
| MSEB native audio mrr@10 | 73.99 | ASR→text cascade 70.40보다 높음 |
오디오 결과는 특히 흥미롭다.
Massive Sound Embedding Benchmark의 passage retrieval split에서 native audio 입력은 평균 mrr@10 73.99를 기록하고, ASR로 먼저 텍스트화한 baseline은 70.40에 머문다.
같은 언어 안의 retrieval은 75.58 대 73.58, cross-lingual retrieval은 72.56 대 67.55다.
논문의 해석처럼, 중간 ASR이 애매한 음향 신호를 하나의 텍스트로 hard decision하는 순간 검색 신호가 손상될 수 있다.
반대로 raw audio embedding은 억양, 발음, 강조, 언어 간 semantic alignment를 더 연속적인 표현으로 보존할 가능성이 있다.
API/제품 관점에서 읽어야 할 점
gemini-embedding-2는 논문만 있는 모델이 아니라 실제 API 문서가 있는 제품 모델이다.
Gemini API model page는 지원 입력을 text, image, video, audio, PDF로 제시하고, output은 embedding이라고 정리한다.
별도 embeddings guide는 embedContent 호출 예시를 제공하며, gemini-embedding-2에서는 예전 task_type 필드를 쓰지 말고 prompt 안에 task instruction을 넣으라고 설명한다.
예컨대 검색 쿼리는 task: search result | query: ..., 문서는 title: ... | text: ... 같은 형식을 권한다.
Vertex AI/Gemini Enterprise 문서의 operational limit도 같이 봐야 한다.
문서 기준으로 이미지는 prompt당 최대 6개, PDF는 prompt당 1개 파일과 최대 6페이지, 비디오는 audio 포함 80초 또는 audio 없는 120초, 오디오는 180초 같은 제한이 있다.
즉 “모든 모달리티를 하나의 임베딩 공간으로”라는 큰 그림은 맞지만, production ingestion에서는 chunking, frame sampling, page splitting, metadata filtering을 별도로 설계해야 한다.
또 하나의 실무 포인트는 re-indexing이다.
Gemini Embedding 2는 기존 text-only embedding model과 “동일 벡터를 보존한다”고 주장하는 호환 레이어가 아니다.
따라서 기존 gemini-embedding-001이나 다른 text embedding index를 그대로 둔 채 멀티모달 질의를 바로 섞는 업그레이드로 보면 위험하다.
하나의 unified space를 쓰려면 문서, 이미지, 오디오, 영상 asset을 같은 모델/설정/dimension으로 다시 embedding하고, index schema에 modality, timestamp, source, chunk/page/frame 정보를 함께 저장하는 편이 안전하다.
실무 관점에서의 해석
내가 보기에 Gemini Embedding 2의 가장 큰 의미는 “멀티모달 RAG의 기본 단위가 caption이 아니라 embedding input 자체로 이동한다”는 데 있다.
지금까지 많은 시스템은 이미지와 오디오를 텍스트로 설명한 뒤 검색했다.
이는 텍스트 LLM 중심 생태계에서는 자연스럽지만, 검색 계층에서는 정보 손실이 크다.
Gemini Embedding 2는 이미지+질문, 오디오+텍스트, 문서+설명 같은 interleaved input을 직접 representation으로 만드는 쪽을 제안한다.
다만 이 모델이 모든 팀의 검색 문제를 자동으로 해결하는 것은 아니다.
첫째, closed API 모델이므로 비용, rate limit, data governance, 지역, 장애 대응을 확인해야 한다.
둘째, 멀티모달 single index는 편하지만 score calibration과 filtering이 더 중요해진다.
이미지와 텍스트가 같은 공간에 있어도, 제품에서는 “이 쿼리에는 문서 page를 우선할지, 영상 scene을 우선할지, 오디오 발화를 우선할지”를 ranking layer가 판단해야 한다.
셋째, benchmark는 대부분 공개 task와 Google이 구성한 평가에 기반하므로, 의료·법률·제조·보안 같은 도메인에서는 별도 offline eval과 human review가 필요하다.
그럼에도 방향성은 분명하다.
검색 인프라는 더 이상 텍스트 chunk database만으로 충분하지 않다.
기업 데이터는 처음부터 multimodal이고, 에이전트는 점점 더 많은 형태의 근거를 동시에 다뤄야 한다.
Gemini Embedding 2는 이 변화를 “여러 specialized embedder를 붙이는 아키텍처”가 아니라, Gemini 기반의 하나의 semantic representation layer로 다루려는 시도다.
결론적으로 Gemini Embedding 2는 멀티모달 검색을 위한 강한 제품 신호다.
논문은 NCE, MRL, multi-stage training, model soup라는 학습 레시피를 공개하고, 공식 문서는 API surface와 operational limit를 제시한다.
실무자는 이를 보고 “우리도 모든 데이터를 한 벡터 DB에 넣자”로 곧장 뛰기보다, 어떤 modality를 어떤 granularity로 쪼개고, 어떤 task instruction과 dimension을 쓰며, 어떤 평가셋으로 검색 품질을 검증할지부터 설계해야 한다.
그 설계가 있다면 Gemini Embedding 2는 text-only RAG를 multimodal retrieval system으로 확장하는 강력한 후보가 된다.