대부분의 에이전트 벤치마크는 사용자가 먼저 명시적인 요청을 던진다는 전제에서 출발한다.
모델은 지시를 받고, 도구를 고르고, 상태를 바꾸고, 마지막에 성공 여부를 평가받는다.
하지만 진짜 개인 비서형 에이전트가 어려운 지점은 그 반대편에 있다.
사용자가 아직 요청하지 않았지만, 지금 개입하면 도움이 되는 순간을 스스로 알아차릴 수 있는가.
그리고 그 개입이 너무 이르거나, 너무 잦거나, 잘못된 목표를 건드리지는 않는가.
Proactive Agent Research Environment: Simulating Active Users to Evaluate Proactive Assistants는 이 문제를 정면으로 다룬다.
논문은 **Pare(Proactive Agent Research Environment)**라는 평가 환경과 Pare-Bench라는 143개 시나리오 벤치마크를 제안한다.
핵심은 간단하다. proactive assistant는 정적 로그나 평면적인 tool-call API만으로는 제대로 평가하기 어렵고, 실제 사용자처럼 앱 화면을 순서대로 탐색하는 active user simulator와 상호작용해야 한다는 것이다.
흥미로운 점은 Pare가 사용자와 비서를 일부러 비대칭으로 만든다는 데 있다.
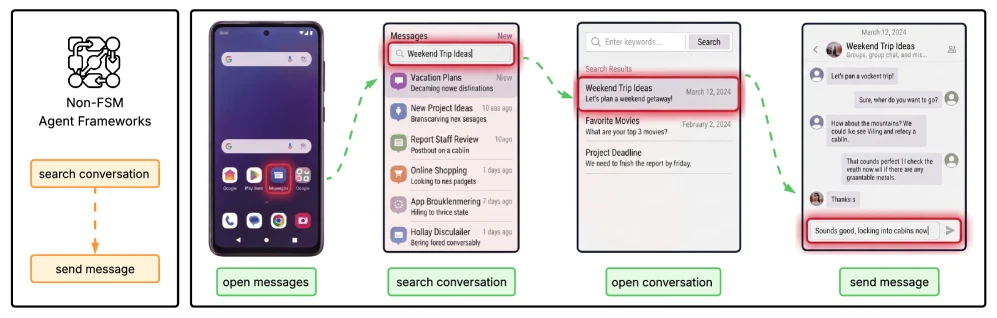
사용자는 모바일 앱처럼 현재 화면에서 가능한 action만 수행할 수 있고, 앱 내부를 단계적으로 이동해야 한다.
반면 assistant는 여러 앱의 backend API를 직접 읽고 실행할 수 있다.
이 차이는 실제 스마트폰/개인비서 배치와 닮아 있다.
사용자는 화면을 보고 움직이지만, 비서는 권한이 주어지면 여러 앱을 가로질러 직접 작업할 수 있다.
무엇을 해결하려는가
Pare가 겨냥하는 첫 번째 문제는 proactive agent 평가에서 사용자 행동이 빠져 있다는 점이다. reactive agent는 사용자의 명령을 기다린 뒤 행동하면 된다.
반면 proactive assistant는 사용자의 행동, 알림, 앱 상태 변화를 관찰하면서 숨어 있는 목표를 추론해야 한다.
사용자가 무엇을 보고 있는지, 어떤 정보를 아직 확인하지 않았는지, 지금 제안하면 너무 이른지까지 평가 대상이 된다.
기존 접근은 이 고리를 충분히 닫지 못했다.
논문은 ProactiveAgent, ContextAgent, ProAgent 같은 선행 작업이 proactive assistance를 다루기는 하지만, 대개 정적 샘플이나 자연어 이벤트 설명에 기대며 사용자가 실제 환경을 탐색하고 상태를 바꾸는 과정을 모델링하지 못한다고 지적한다.
사용자와 assistant가 같은 환경을 함께 바꾸고, 그 결과가 다음 행동에 영향을 주는 구조가 없으면, goal completion을 제대로 평가하기 어렵다는 주장이다.
두 번째 문제는 앱을 flat API 집합으로만 모델링하는 관성이다. assistant 입장에서는 send_message(recipients, message) 같은 API를 바로 호출할 수 있다.
하지만 사용자는 실제로 메시지 앱을 열고, 대화를 검색하고, 대화방을 열고, 내용을 입력한 뒤 전송해야 한다.
이 순서형 제약을 지우면 사용자의 정보 접근성, 개입 타이밍, proposal acceptance를 제대로 평가할 수 없다.
세 번째 문제는 개입의 품질을 성공률 하나로만 볼 수 없다는 점이다. proactive assistant는 성공하면 유용하지만, 너무 많이 제안하면 귀찮고, 너무 빨리 제안하면 사용자가 아직 충분한 맥락을 모으지 못했을 수 있다.
Pare-Bench가 proposal rate, acceptance rate, read actions, gather-context decision까지 따로 보는 이유가 여기에 있다.
이 벤치마크의 핵심 질문은 “작업을 끝냈는가”만이 아니라, 언제, 얼마나 조심스럽게, 얼마나 설득력 있게 개입했는가다.
핵심 아이디어 / 구조 / 동작 방식
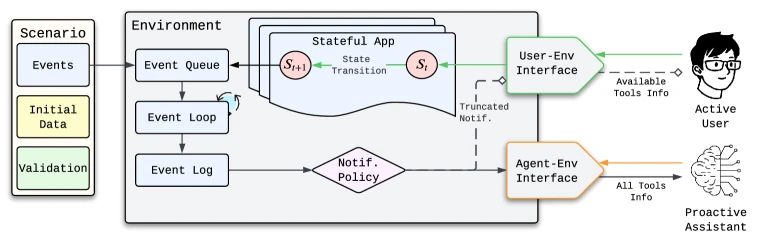
Pare는 기존 Agent Research Environment(ARE)를 확장해 active user simulator를 넣는다.
가장 중요한 설계는 사용자와 assistant의 action interface를 다르게 둔 것이다.
| 구성 요소 | Pare에서의 역할 | 실무적으로 중요한 이유 |
|---|---|---|
| FSM 기반 앱 | 각 앱 화면과 가능한 사용자 action을 finite state machine으로 모델링 | 사용자가 실제 UI를 단계적으로 탐색하는 제약을 반영 |
| User simulator | 현재 앱 상태에서 허용된 action만 수행하고, truncated notification을 받음 | 사용자가 정보 일부만 본 상태에서 판단하는 상황을 재현 |
| Proactive assistant | read-only observation, proposal, 승인 후 execution을 수행 | 비서가 여러 앱 API를 가로질러 작업하는 배치 구조를 반영 |
| Environment events | 이메일, 캘린더, 메시지 같은 외부 이벤트를 시간 순서로 주입 | 사용자가 명령하지 않아도 assistant가 개입 기회를 찾아야 함 |
| Scenario oracle | 최종 환경 상태가 latent user goal을 만족했는지 검증 | 단순 대화 품질이 아니라 실제 상태 변화의 성공을 평가 |
논문은 이 상호작용을 Stackelberg POMDP로 정식화한다.
사용자가 먼저 행동하고, proactive agent는 사용자의 행동과 환경 이벤트를 관찰한 뒤 제안할지 말지 결정한다.
제안이 사용자에게 받아들여지면 assistant가 실행 모드로 넘어가고, 그렇지 않으면 계속 관찰한다.
이 구조는 “agent가 사용자를 대신한다”보다 사용자 주도권을 유지한 채 필요한 순간에만 권한을 얻는다는 쪽에 가깝다.
assistant 구조도 observe와 execute로 나뉜다.
Observe mode에서는 read-only tool과 wait, send_message_to_user 같은 control action만 사용할 수 있다.
이 단계의 목적은 사용자의 행동과 알림을 보면서 intervention opportunity를 찾는 것이다.
사용자가 proposal을 받아들이면 Execute mode로 들어가고, 이때는 여러 앱의 flat API를 이용해 실제 상태 변경을 수행한다.
실행이 끝나면 다시 observe mode로 돌아간다.
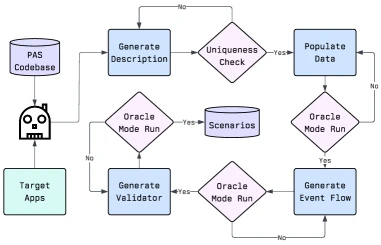
Pare-Bench는 이 환경 위에 만든 143개 시나리오다.
논문 기준 시나리오는 communication, productivity, scheduling, lifestyle 앱을 포괄하며, 실제 포함 앱은 cab, note, email, calendar, contacts, reminder, shopping, messaging, apartment 등으로 구성된다.
시나리오 생성은 LLM 기반 agent가 description, data population, event flow, validation을 만들고, oracle mode 실행 검증과 인간 검토를 거치는 파이프라인을 따른다.
공개된 근거에서 확인되는 점
메인 실험은 7개 LLM 기반 proactive assistant를 Pare-Bench에서 비교한다. closed-source 모델로 Claude 4.5 Sonnet, GPT-5, Gemini 3 Pro, Gemini 3 Flash를 쓰고, open-weight 계열로 Qwen 3 4B Instruct, Llama 3.2 3B Instruct, Gemma 3 4B Instruct를 넣는다.
사용자 시뮬레이터는 기본적으로 GPT-5-mini이며, 각 시나리오는 최대 10턴으로 실행된다.
핵심 결과는 꽤 냉정하다.
가장 높은 평균 success rate도 42% 수준에 머문다.
Gemini 3 Flash가 42.1%, Claude 4.5 Sonnet이 42.0%로 거의 같고, GPT-5는 37.4%, Gemini 3 Pro는 35.1%다.
작은 open-weight 모델은 더 낮다.
Qwen 3 4B Instruct는 18.5%, Llama 3.2 3B는 10.0%, Gemma 3 4B는 3.0%에 그친다.
| 모델 | Success@4 | Success^4 | Success Rate | Proposal Rate | Acceptance Rate | 해석 |
|---|---|---|---|---|---|---|
| Claude 4.5 Sonnet | 60.8% | 18.2% | 42.0% | 12.8% | 78.2% | 적게 제안하지만 가장 높은 acceptance를 보임 |
| Gemini 3 Flash | 64.3% | 16.1% | 42.1% | 19.1% | 67.1% | 성공률은 최고권이지만 더 많은 제안이 필요 |
| GPT-5 | 57.3% | 17.5% | 37.4% | 28.1% | 70.2% | proposal rate가 높아 goal inference 과신 가능성 |
| Qwen 3 4B Instruct | 35.0% | 6.3% | 18.5% | 20.5% | 63.7% | proposal은 꽤 받아들여지지만 실행이 병목 |
| Llama 3.2 3B Instruct | 23.8% | 1.4% | 10.0% | 23.0% | 58.4% | 반복 실행 일관성이 크게 약함 |
| Gemma 3 4B Instruct | 7.7% | 0.7% | 3.0% | 14.2% | 17.6% | 소극적이면서도 proposal 품질이 낮음 |
여기서 Success@4와 Success^4의 차이가 중요하다.
Success@4는 네 번의 실행 중 한 번이라도 성공했는지를 보고, Success^4는 네 번 모두 성공했는지를 본다.
Claude도 60.8%에서 18.2%로 크게 떨어지고, Llama는 23.8%에서 1.4%로 더 심하게 무너진다.
즉 proactive assistance는 한 번 운 좋게 맞히는 능력과 반복적으로 안정적인 능력 사이의 간극이 크다.
proposal quality도 분리해서 봐야 한다.
Claude는 proposal rate가 12.8%로 가장 낮으면서 acceptance rate가 78.2%로 가장 높다.
논문은 이를 Claude가 비교적 확신이 있을 때만 제안하는 패턴으로 해석한다.
반대로 GPT-5는 proposal rate가 28.1%로 가장 높다. acceptance rate는 70.2%로 낮지 않지만, 사용자를 더 자주 방해해야 비슷한 성공률을 얻는다는 점에서 실무적으로는 비용이 있다.
Qwen 3 4B의 결과도 흥미롭다. acceptance rate는 63.7%로 그리 낮지 않은데 success rate는 18.5%다.
이는 작은 모델에서 goal inference보다 execution이 더 큰 병목일 수 있음을 시사한다.
제안 자체는 그럴듯하게 받아들여지지만, 실제 여러 앱 상태를 바꿔 목표를 완수하는 단계에서 실패한다는 뜻이다.
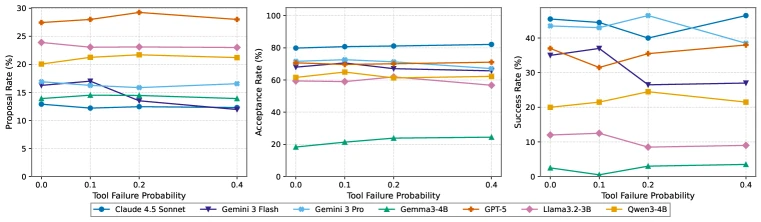
강건성 실험도 유용하다.
Pare는 tool failure probability와 spurious environment noise를 조절해 assistant가 실패와 잡음 속에서도 안정적인지를 본다.
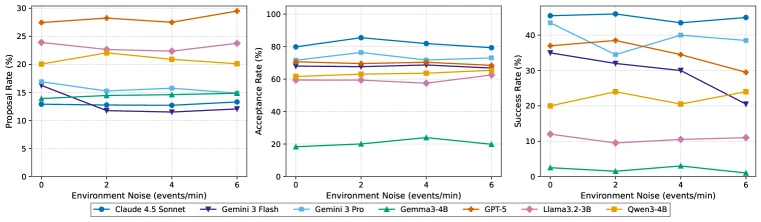
Appendix의 decision analysis는 이 벤치마크가 왜 “proactive” 평가인지 잘 보여준다.
사용자 응답은 단순 accept/reject가 아니라 gather context도 포함한다.
사용자가 아직 알림의 일부만 봤기 때문에, assistant 제안이 맞을 수도 있지만 지금은 판단할 수 없어 직접 이메일이나 앱을 더 확인하는 경우다.
GPT-5는 gather context가 23.4%, Qwen은 26.5%, Llama는 29.1%로 높고, Gemma는 74.7%까지 올라간다.
이는 많은 proposal이 “틀렸다”기보다 너무 이르다는 실패 양상을 드러낸다.
사용자 모델 ablation도 중요한 근거다.
논문은 GPT-5-mini, Claude 4.5 Sonnet, Qwen 3 4B를 사용자 시뮬레이터로 바꿔 보며 proactive assistant 순위가 얼마나 유지되는지 확인한다.
Claude 사용자 모델은 가장 엄격해 acceptance와 success가 전반적으로 낮아지고, Qwen 사용자 모델은 더 관대해 acceptance가 높아진다.
그럼에도 상대적 순위는 대체로 보존되고, same-model bias도 관찰되지 않는다고 보고한다.
즉 Pare-Bench의 절대 수치는 user simulator 선택에 민감하지만, 비교 신호는 어느 정도 안정적이라는 주장이다.
릴리스 관점에서는 이제 논문만이 아니라 공식 repository와 documentation까지 함께 읽어야 한다.
논문과 README가 연결하는 deepakn97/pare repository는 MIT 라이선스의 Python 연구 코드로 공개되어 있고, 현재 GitHub tree 기준 pare/scenarios/benchmark/ 아래 143개 benchmark scenario Python 파일이 실제로 들어 있다.
문서 사이트도 uv run pare scenarios list, uv run pare benchmark sweep --split full --observe-model gpt-5 --execute-model gpt-5, trace export, annotation workflow를 별도 섹션으로 설명한다.
즉 Pare-Bench는 단순한 paper-only proposal이 아니라, 적어도 source 기반으로 inspect/run/annotate할 수 있는 연구 artifact에 가깝다.
| 공개 표면 | 확인한 내용 | 해석 |
|---|---|---|
| GitHub repository | deepakn97/pare, MIT license, Python 중심 코드, README와 docs, 143개 benchmark scenario 파일 |
논문 주장과 연결된 companion code가 존재한다 |
| 실행·문서화 | Python 3.12+, uv, pare CLI, benchmark sweep, scenario generation, trace export, annotation commands |
재현·확장 흐름은 문서화되어 있지만 연구용 실행 환경을 전제한다 |
| 패키징 성숙도 | pyproject.toml 버전은 0.0.1이고 GitHub Releases/tags는 아직 비어 있음 |
안정 배포 패키지라기보다 빠르게 갱신되는 research code release로 보는 편이 안전하다 |
| 운영 caveat | OpenAI/Hugging Face/AWS Bedrock 계열 provider credential이 필요할 수 있음 | 벤치마크 재현성은 모델 접근권과 provider 설정에 영향을 받는다 |
실무 관점에서의 해석
Pare-Bench의 가장 큰 의미는 proactive assistant를 “더 똑똑한 tool caller”가 아니라 사용자와 함께 움직이는 mixed-initiative system으로 평가한다는 데 있다.
지금 많은 agent benchmark는 tool selection, parameter correctness, final task success에 집중한다.
하지만 개인 비서형 agent에서는 그 앞단의 질문이 더 중요하다.
사용자가 아직 명령하지 않은 목표를 모델이 어떻게 알아차리는가.
사용자가 충분한 맥락을 갖기 전에 끼어들지 않는가.
제안은 받아들일 만큼 구체적인가.
실행은 승인 이후에만 일어나는가.
이 관점은 제품 설계에도 직접 연결된다. proactive assistant가 항상 관찰해야 한다면 privacy boundary가 핵심이 된다.
논문은 사용자의 모든 화면 픽셀을 보는 대신 API-level action과 notification을 관찰하는 구조를 하나의 privacy boundary로 제시한다.
또한 Impact Statement에서 continuous observation은 edge/on-device model에 더 적합하다고 주장한다.
실무적으로는 작은 on-device observer가 계속 관찰하고, 사용자가 승인한 뒤에만 큰 executor를 호출하는 구조가 자연스럽다.
또 하나의 메시지는 개입 비용을 지표에 넣어야 한다는 점이다.
GPT-5처럼 proposal을 많이 던져 성공률을 끌어올리는 모델과, Claude처럼 적게 제안하면서 더 높은 acceptance를 얻는 모델은 사용자 경험이 다르다.
단순 success rate만 보면 비슷해 보여도, 실제 제품에서는 불필요한 알림, premature suggestion, gather-context delay가 모두 비용이다.
Pare-Bench는 proposal rate와 acceptance rate를 같이 보게 만들어 이 차이를 드러낸다.
다만 한계도 분명하다.
Pare는 실제 화면 이미지가 아니라 tool-call 수준에서 앱 상호작용을 모델링한다.
이는 평가를 확장 가능하게 만들고 privacy boundary를 단순화하지만, 실제 multimodal assistant가 겪는 visual grounding 문제는 빠져 있다.
또한 user simulator가 LLM 기반이기 때문에 피로도, 감정, 신뢰 성향, 개인별 선호 같은 인간 차이를 충분히 담지 못한다.
논문 자체도 이를 future work로 인정한다.
내가 보기에 Pare-Bench는 완성된 proactive assistant 평가의 끝이라기보다, 필요한 평가 축을 잘 드러낸 출발점에 가깝다.
특히 “사용자 상태를 FSM으로 제한하고, assistant에는 더 넓은 API를 열어 두며, proposal과 execution을 승인 경계로 분리한다”는 설계는 앞으로 개인 비서형 agent benchmark에서 반복될 가능성이 높다.
에이전트가 점점 더 많은 앱과 개인 데이터를 다루게 될수록, 단순한 task success보다 관찰 권한, 개입 타이밍, 사용자 승인, 반복 안정성이 더 중요한 평가 단위가 될 것이기 때문이다.
한 줄로 요약하면
Pare-Bench는 proactive assistant 평가를 “사용자가 시킨 일을 처리했는가”에서 “능동적으로 움직이는 사용자를 관찰하며, 적절한 순간에, 받아들일 만한 제안을 하고, 승인 이후 실제 앱 상태를 안전하게 바꿨는가”로 바꾼다.
그리고 현재 최고권 모델도 이 설정에서는 평균 42% 수준의 success rate에 머문다는 점을 보여준다.