문서 VLM 평가는 이제 OCR 한두 줄을 맞히는 문제에서 멀어지고 있다.
실제 행정·공공 업무 문서는 수십 페이지의 표, 부록, 일정표, 수치, 예외 조건이 얽혀 있고, 질문 하나에 답하려면 서로 떨어진 페이지의 단서를 연결해야 한다.KOLongDoc는 이 지점을 겨냥한 한국어 장문 문서 VLM 벤치마크다.
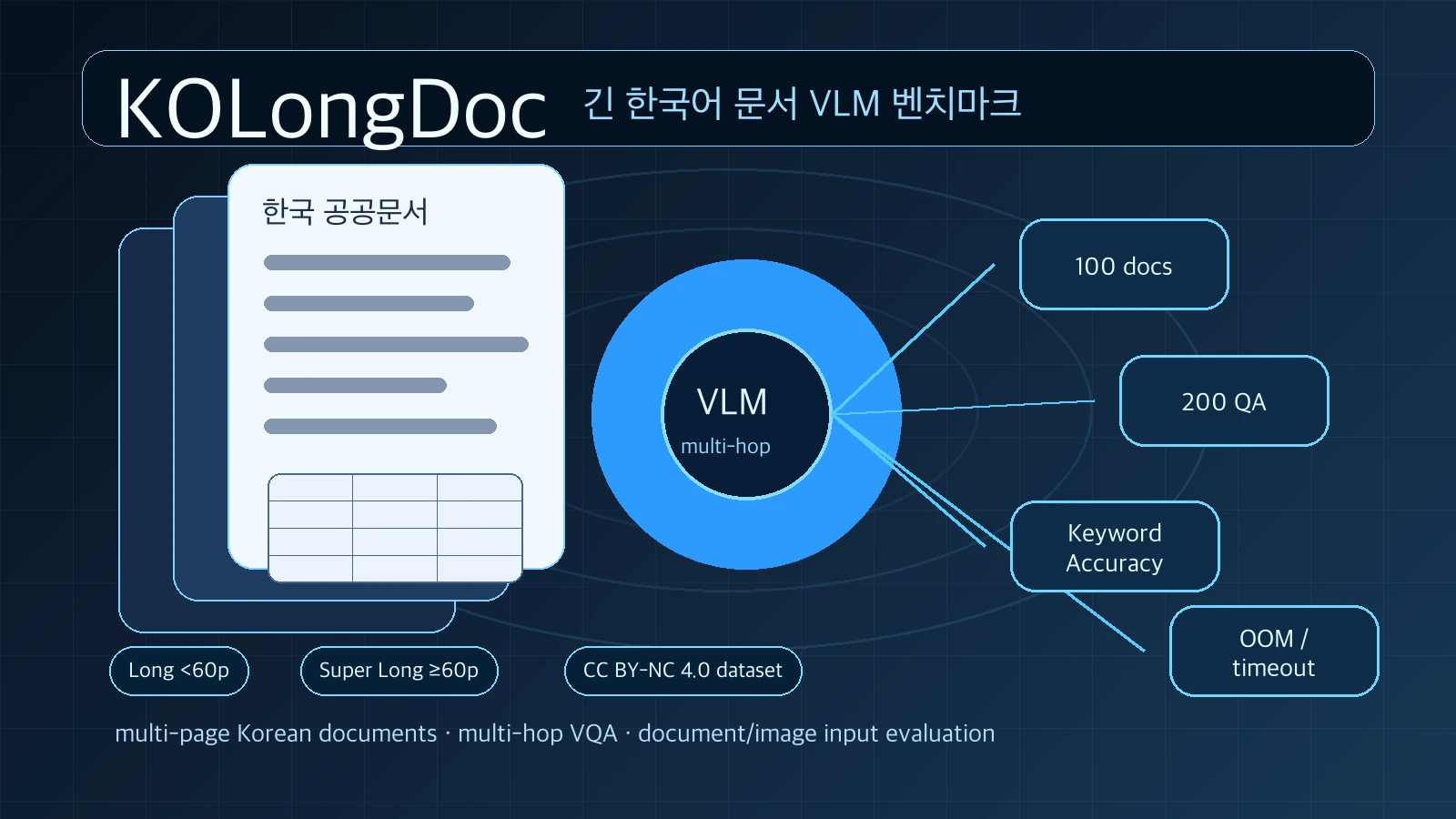
공식 README와 Hugging Face 데이터셋 카드 기준 KOLongDoc는 한국어 공공문서 기반의 100개 문서 / 200개 multi-hop QA로 구성된다.
핵심은 “한국어를 읽는가”만이 아니다.
VLM이 긴 고해상도 문서를 이미지 입력 또는 텍스트 추출 입력으로 받았을 때, 여러 페이지의 근거를 연결하고 정답에 필요한 키워드를 빠뜨리지 않는지를 본다.
무엇을 해결하려는가
한국어 멀티모달 벤치마크는 이미 여러 갈래로 존재한다.
KOLongDoc README는 KO-VQA, KO-VDC, KO-OCRAG, KOFFVQA, KoViDoRe, K-MMBench/K-MMStar, K-DTCBench, K-LLaVA-W 등을 비교 대상으로 언급한다.
각각 문서 이해, OCR, 표·차트 이해, 이미지 기반 VQA, 문서 retrieval처럼 중요한 축을 다뤄 왔다.
하지만 KOLongDoc가 문제 삼는 공백은 더 구체적이다.
길이가 긴 고해상도 한국어 문서에서 multi-hop VQA를 종합적으로 보는 벤치마크가 부족하다는 것이다.
예를 들어 한 질문이 특정 표에서 최대값을 찾고, 다른 페이지의 비교 대상과 다시 대조하고, 마지막으로 정답 형식에 맞춰 수치와 명칭을 함께 내야 한다면 단순 OCR 정확도나 단일 이미지 VQA 점수만으로는 충분하지 않다.
이런 설정은 RAG나 문서 자동화 제품에도 직접 연결된다.
PDF를 텍스트로 뽑아 LLM에 넣는 방식은 레이아웃·표·이미지 근거를 잃을 수 있고, 반대로 PDF 페이지를 이미지로 모두 넣는 방식은 GPU 메모리와 context budget에 부딪힌다.
KOLongDoc는 그 두 경로를 모두 평가 대상으로 두면서, 한국어 장문 문서 이해를 모델 품질과 운영 제약이 함께 걸린 문제로 만든다.
핵심 아이디어 / 데이터 구성
KOLongDoc의 데이터 구성은 작지만 의도적으로 무겁다.
문서 수는 100개이고, 각 문서마다 2개의 multi-hop QA가 붙어 총 200문항이 된다.
문서는 페이지 수에 따라 Long document와 Super Long document로 나뉜다.
| 구분 | 기준 | 문서 수 | QA 수 | 해석 |
|---|---|---|---|---|
| Long document | 60페이지 미만 | 68 | 136 | 일반적인 장문 PDF이지만 여전히 multi-page 추론이 필요하다 |
| Super Long document | 60페이지 이상 | 32 | 64 | 모델 입력 길이, 이미지 수, GPU 메모리 한계를 더 강하게 압박한다 |
| Total | - | 100 | 200 | 문서당 2개 QA로 구성된 한국어 장문 문서 평가 세트 |
QA 제작 방식도 벤치마크의 성격을 잘 보여 준다.
저장소에는 gemini-prompt.txt가 포함되어 있고, 이 프롬프트는 단일 정보만으로 답할 수 있는 질문이 아니라 여러 이미지·표·다이어그램 단서를 종합해야 하는 질문을 만들도록 요구한다.
이후 사람 검수자가 난이도, multi-hop 여부, 질문 품질, 답변 correctness를 확인하고, 정량 평가에 필요한 keyword를 직접 선별한다.

대표 예시는 이 벤치마크가 왜 단순 질의응답이 아닌지 보여 준다.
해양수질측정망 문항은 구리 농도가 가장 높은 정점, 아연 농도가 가장 높은 정점, 두 정점의 TOC 비교를 함께 요구한다.
교육운영계획 문항은 두 교육과정의 비용 계산과 동시 수강 가능 여부 판단을 함께 묻는다.
둘 다 “문서 안에 답이 있다”에서 끝나지 않고, 떨어진 근거를 찾아 조합해야 한다.
평가 방식과 코드 표면
평가는 Keyword 기반 Accuracy로 정의된다.
모델 답변 안에 사람이 지정한 필수 키워드가 얼마나 포함되어 있는지를 계산한다.
Hard version은 모든 키워드가 맞아야 1점이고, Soft version은 일부 키워드만 맞아도 부분 점수를 준다.
이 방식은 LLM-as-a-judge나 BERTScore처럼 평가 모델의 사전지식에 기대는 방식을 줄이고, 최소한 반드시 포함해야 할 정답 단서를 명시한다는 장점이 있다.
입력 방식은 두 가지다. text 설정에서는 pymuPDF로 PDF 텍스트를 추출해 모델에 넣고, image 설정에서는 PDF 페이지를 이미지로 변환해 VLM에 넣는다.
README 기준 평가는 max_token: 8192, A100 80GB GPU 1장 환경에서 수행됐다.
저장소의 eval.py도 이 구성을 반영해 KLongDocURL_L_ver1.xlsx, KLongDocURL_SL_ver1.xlsx를 읽고, 모델별 evaluation function을 불러와 long/super-long, image/text 조합을 각각 저장한다.
실행 표면은 아직 연구용 harness에 가깝다. eval.sh는 base_model, huggingface_token, dataset_path, image_path를 채우는 형태이고, 코드 분기는 Qwen, Gemma, EXAONE, Gukbap-Ovis2, VARCO-VISION, Bllossom 계열을 모델명 문자열로 나눠 처리한다.
즉 pip 패키지나 안정화된 CLI라기보다, 공개 데이터셋과 함께 쓰는 평가 스크립트 묶음으로 보는 편이 안전하다.
공개된 근거에서 확인되는 점
결과 표의 메시지는 꽤 분명하다.
README 표기 기준 Gemini 계열은 image 입력에서 강하고, 많은 오픈소스 VLM은 super-long 또는 image 입력에서 OOM/timeout에 걸린다.
장문 문서 VQA가 모델 정확도뿐 아니라 GPU memory envelope, 입력 형태, 페이지 수에 의해 크게 좌우된다는 뜻이다.
| 관찰 지점 | README에서 확인되는 예 | 해석 |
|---|---|---|
| Image 입력의 강한 closed model | gemini-3.5-flash (image) Hard Avg. Acc 82.58, Soft Avg. Acc 91.15 |
페이지 이미지를 직접 보는 설정에서 상위 모델은 높은 keyword 회수율을 보인다 |
| Text 입력의 비용/성능 균형 | gemini-3.5-flash (text) Hard Avg. Acc 68.52, Soft Avg. Acc 76.76 |
텍스트 추출 입력도 유효하지만, 이미지 입력 대비 시각·레이아웃 근거 손실이 생길 수 있다 |
| Open-source long-context 병목 | 여러 open-source 모델이 super-long 또는 image 설정에서 OOM/timeout |
벤치마크가 정확도뿐 아니라 실제 장문 처리 가능성을 드러낸다 |
| Keyword 기반 scoring | Hard는 100% keyword match, Soft는 부분 credit | 필수 정답 단서 누락을 직접 벌하지만, 표현 다양성이나 동의어 처리는 별도 주의가 필요하다 |
Hugging Face 배포 표면도 함께 봐야 한다.Markr-AI/KOLongDoc 데이터셋은 API 기준 private/gated가 아니며, license:cc-by-nc-4.0, modality:document, library:datasets, arxiv:2412.18424 태그를 갖는다.
확인 시점의 API 카운터는 downloads 249, likes 2이고, 파일 목록에는 KLongDocURL_L_ver1.xlsx, KLongDocURL_SL_ver1.xlsx, dataset/less_60, dataset/more_60 아래 PDF들이 보인다.
다만 Hugging Face Dataset Viewer는 1.24GB 규모 Parquet scan limit 문제로 바로 열리지 않을 수 있으므로, 실무 재현에서는 viewer보다 파일 단위 다운로드와 로컬 로딩을 전제로 잡는 편이 낫다.
GitHub 저장소의 공개 성숙도는 아직 초기 release에 가깝다.
GitHub API 기준 저장소는 2026년 4월 생성됐고, 최신 push는 2026년 6월 초이며, stars 6, forks 0, open issues 0이다. /releases/latest는 404이고 tags 목록도 비어 있다.
또한 GitHub API의 license 필드는 null이며 top-level contents에도 별도 LICENSE 파일이 보이지 않는다.
데이터셋 쪽은 HF card의 CC BY-NC 4.0을 따르되, 평가 코드의 재사용 범위는 저장소 라이선스 표기가 정리되기 전까지 조심스럽게 봐야 한다.
실무 관점에서의 해석
KOLongDoc의 가장 큰 가치는 한국어 문서 AI 평가를 짧은 OCR/단일 이미지 이해에서 긴 PDF를 끝까지 처리하는 운영 문제로 끌어올린다는 데 있다.
실제 기업이나 공공기관의 문서 RAG 시스템은 “첫 페이지 요약”보다 “부록 표까지 뒤져서 조건을 만족하는 값 찾기”에서 흔들린다.
KOLongDoc의 multi-hop QA는 바로 그 실패 모드를 겨냥한다.
두 번째 가치는 image 입력과 text 입력을 나눠 보여 준다는 점이다.
텍스트 추출 기반 pipeline은 비용과 처리량 면에서 매력적이지만, 표 구조, 페이지 배치, 그림 속 텍스트가 손상될 수 있다.
이미지 기반 pipeline은 시각 근거를 더 보존하지만, 페이지 수가 늘면 메모리와 latency가 급격히 불리해진다.
KOLongDoc 결과표의 OOM/timeout은 단순한 실패 표기가 아니라, 어떤 제품 설계가 현실적인지 묻는 신호다.
반대로 한계도 분명하다.
100문서/200문항은 날카로운 smoke test로는 유용하지만, 모든 한국어 문서 도메인을 대표한다고 말하기에는 작다.
Keyword 기반 scoring은 필수 단서 누락을 잡는 데 강하지만, 정답의 표현 다양성, 단위 변환, 동의어, 근거 설명의 품질을 모두 포괄하지는 않는다.
따라서 KOLongDoc를 단독 leaderboard로 보기보다, 한국어 장문 문서 QA 파이프라인을 점검하는 고난도 회귀 테스트 세트로 읽는 것이 더 실용적이다.
그럼에도 공개된 데이터셋, QA 생성 프롬프트, 모델별 평가 코드, Hard/Soft 결과표가 함께 나온 점은 의미가 크다.
한국어 문서 AI를 만드는 팀이라면 KOLongDoc를 그대로 한 번 돌려 보는 것만으로도 자신들의 pipeline이 어디서 무너지는지 볼 수 있다.
텍스트 추출이 약한지, 이미지 입력이 너무 비싼지, super-long 문서에서 context가 잘리는지, keyword 기반 정답 회수가 불안정한지가 꽤 빨리 드러날 것이다.