PaddleOCR-VL-1.6은 PaddlePaddle이 공개한 0.9B급 문서 파싱 Vision-Language Model이다.
Hugging Face 모델 카드 기준으로는 image-text-to-text 파이프라인, Apache-2.0 라이선스, PaddleOCR 라이브러리 태그를 가진 공개 모델이며, 기술보고서는 이 모델을 PaddleOCR-VL-1.5 위에 쌓은 업그레이드로 설명한다.
흥미로운 점은 업그레이드 방향이다.
모델을 더 크게 키운 것이 아니라, 이전 모델이 여전히 불안정하거나 데이터가 희박하거나 라벨 신뢰도가 낮은 구간을 찾아 다시 데이터 엔진과 후학습 파이프라인을 설계했다.
공식 표현으로는 Under-Optimized Region Refinement와 Progressive Post-Training이다.
최종 수치는 OmniDocBench v1.6 overall 96.33%로 제시된다.
이 글은 Hugging Face 모델 페이지, 기술보고서, PaddleOCR 공식 문서, vLLM/FastDeploy/GGUF 배포 자료를 함께 읽어, PaddleOCR-VL-1.6을 “OCR 모델 하나”가 아니라 문서 ingestion을 위한 compact VLM 파이프라인으로 해석한다.
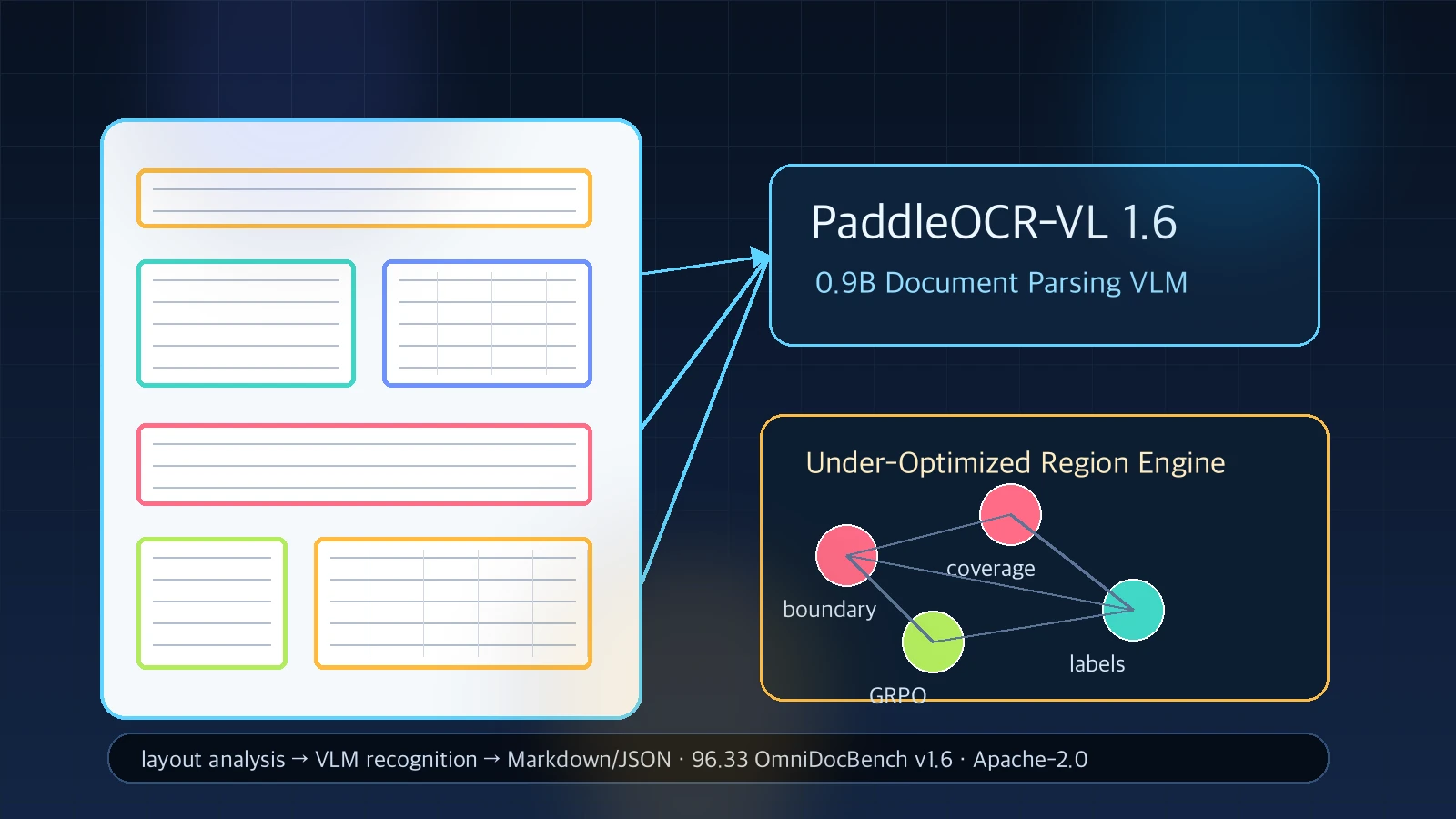
무엇을 해결하려는가
문서 AI 파이프라인의 병목은 단순히 “글자를 읽는 것”에서 끝나지 않는다.
실제 PDF나 스캔 문서에는 본문, 표, 수식, 차트, 도장, 캡션, 복잡한 레이아웃, 읽기 순서가 함께 들어 있다.
후속 LLM/RAG 시스템이 제대로 쓰려면 이 모든 요소가 Markdown, JSON, 구조화된 region 정보로 안정적으로 변환되어야 한다.
기술보고서는 PaddleOCR-VL-1.5가 이미 강한 0.9B baseline이지만, 남은 오류가 균일한 noise가 아니라 특정 약점 구간에 몰려 있다고 본다.
작은 시각 변형에 출력이 흔들리는 샘플, feature space에서 주변 데이터가 희박한 long-tail 문서, 그리고 모델이 높은 확신으로 틀리는 라벨 오류 구간이 남는다는 것이다.
그래서 PaddleOCR-VL-1.6의 질문은 “더 큰 모델을 만들 것인가”가 아니다.
더 정확히는, 이미 강한 compact 문서 VLM에서 어디를 다시 데이터로 보강해야 성능이 오르는가다.
이 방향은 실무적으로 중요하다.
문서 파싱은 대형 VLM을 한 번 호출하는 문제라기보다, 수많은 페이지를 안정적으로 처리하고 품질·비용·배포 환경을 맞춰야 하는 ingestion infrastructure에 가깝기 때문이다.
공식 문서도 이 점을 강하게 경고한다.
PaddleOCR-VL 성능을 재현하려면 VLM component만 직접 Transformers, vLLM, SGLang, FastDeploy에 던지는 것과 전체 PaddleOCR-VL 파이프라인을 실행하는 것을 구분해야 한다.
문서 파싱 pipeline은 layout analysis와 VLM recognition을 결합하고, 이 둘을 함께 써야 논문·모델 카드의 품질 주장에 가까워진다.
핵심 아이디어 / 구조 / 동작 방식
PaddleOCR-VL-1.6 시스템은 크게 두 단계로 읽을 수 있다.
첫째는 PP-DocLayoutV3 기반 layout analysis다.
전체 페이지에서 표, 수식, 텍스트 블록, 차트 같은 요소를 찾고 reading order와 region crop을 만든다.
둘째는 PaddleOCR-VL-1.6-0.9B가 각 요소를 인식해 Markdown/JSON 등으로 변환하는 VLM recognition이다.
기술보고서는 이번 업그레이드에서 PP-DocLayoutV3는 유지하고, PaddleOCR-VL-1.6-0.9B 쪽을 집중적으로 개선했다고 설명한다.
모델 자체는 Native Resolution Visual Encoder, Adaptive MLP Connector, ERNIE-4.5-0.3B Language Model을 결합한 compact architecture를 이어간다.
Hugging Face API의 safetensors metadata도 BF16 parameters 958,588,736개로 표시되어, 모델 카드의 0.9B framing과 맞는다.
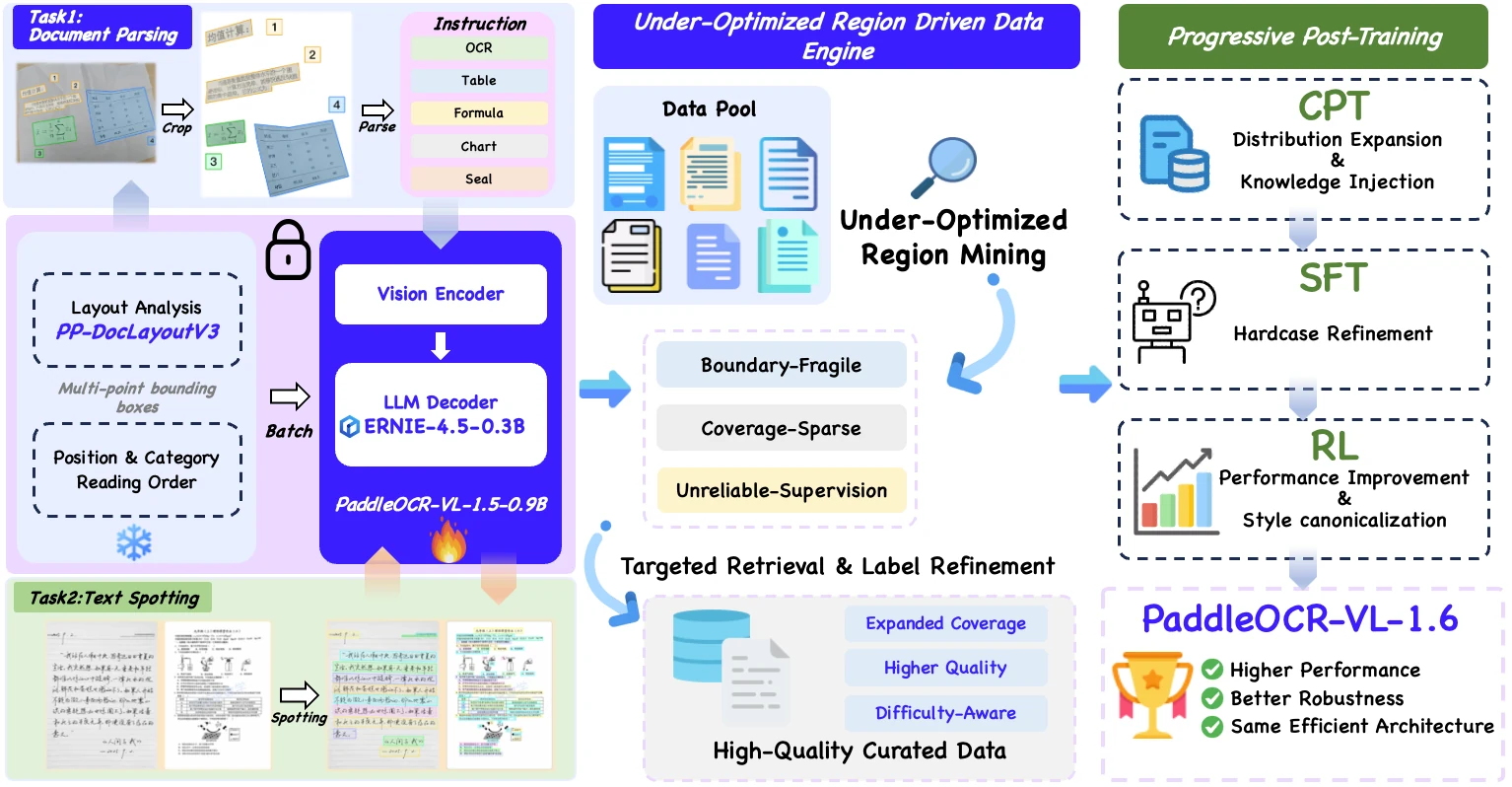
핵심은 data engine이다.
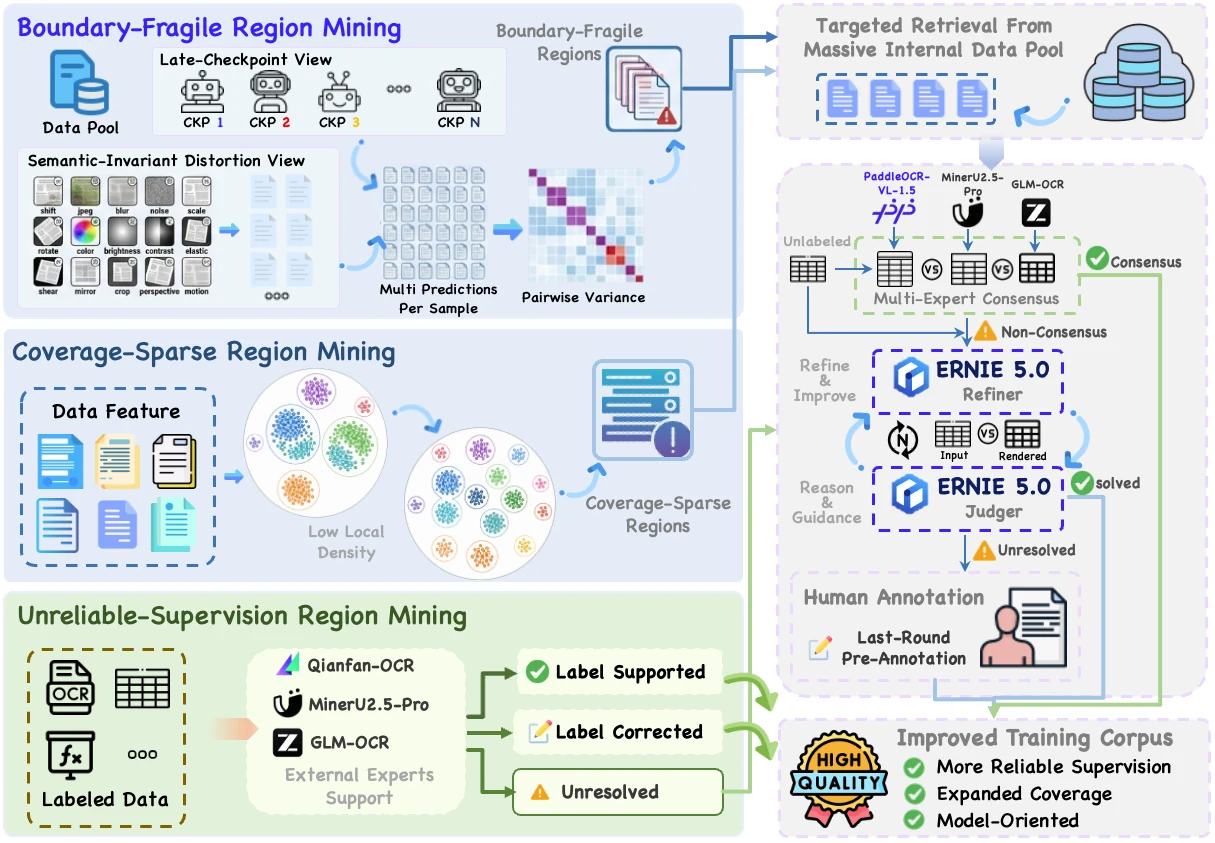
보고서는 약점 구간을 세 종류로 나눈다.
| 약점 구간 | 진단 방식 | 후속 처리 |
|---|---|---|
| Boundary-fragile region | 학습 후반 checkpoint 8개와 semantic-preserving distortion 16종을 조합해 128개 prediction을 만들고, pairwise normalized edit distance로 불안정성을 측정 | top fragile sample을 seed로 삼아 유사 문서를 검색·보강 |
| Coverage-sparse region | 문서 feature space에서 연결성이 낮은 작은 outlier cluster를 찾아 long-tail 분포를 확인 | 고서, 희귀 문자, 산업용 표처럼 underrepresented pattern을 보강 |
| Unreliable-supervision region | Qianfan-OCR, GLM-OCR, MinerU2.5-Pro 같은 독립 expert parser와 기존 label을 비교 | expert consensus로 label을 교정하거나 hard case로 넘김 |
이후 새로 가져온 샘플과 라벨이 불안정한 샘플은 multi-expert consensus와 render-guided Judge-and-Refine pipeline을 거친다.
특히 표와 수식처럼 문자열 비교만으로 품질을 판단하기 어려운 경우, 후보 출력을 다시 렌더링해 원본 이미지와 같은 modality로 비교한다.
보고서는 hard case refinement에 ERNIE 5.0을 사용한다고 설명한다.
후학습은 세 단계다.
Continued Pre-Training은 전체 curated data를 넓게 흡수하는 단계이고, 보고서 기준 16.8M training samples를 사용한다.
Supervised Fine-Tuning은 hard sample과 correction sample에 집중하며 7.3M samples를 쓴다.
마지막 RL 단계는 GRPO를 사용하되, compact model에서 RL data quality가 민감하다는 이유로 improvement potential, entropy-based uncertainty, rollout reward distribution을 함께 본 high-potential sample mining을 적용한다.
공개된 근거에서 확인되는 점
Hugging Face 배포 표면부터 보면, PaddleOCR-VL-1.6은 단순 논문 발표가 아니라 실제 사용을 염두에 둔 release bundle이다.
모델 repo에는 model.safetensors, config.json, chat_template.jinja, custom modeling/processing code, tokenizer, inference.yml이 함께 올라와 있다.
API 기준 생성일은 2026-05-27, 마지막 수정은 2026-06-03, gated가 아니며, 현재 확인 시점의 Hub counter는 downloads 4,829, likes 213이다.
config는 텍스트 hidden size 1024, 18 layers, 16 attention heads, max position embeddings 131,072를 노출한다. vision config는 hidden size 1152, 27 layers, patch size 14를 가진 PaddleOCRVisionModel로 표시된다. preprocessor는 대략 112,896~1,003,520 pixel 범위의 입력 처리를 기본값으로 둔다.
이런 수치는 모델 카드의 “compact 0.9B document VLM” 주장을 파일 단위에서 확인하게 해 준다.
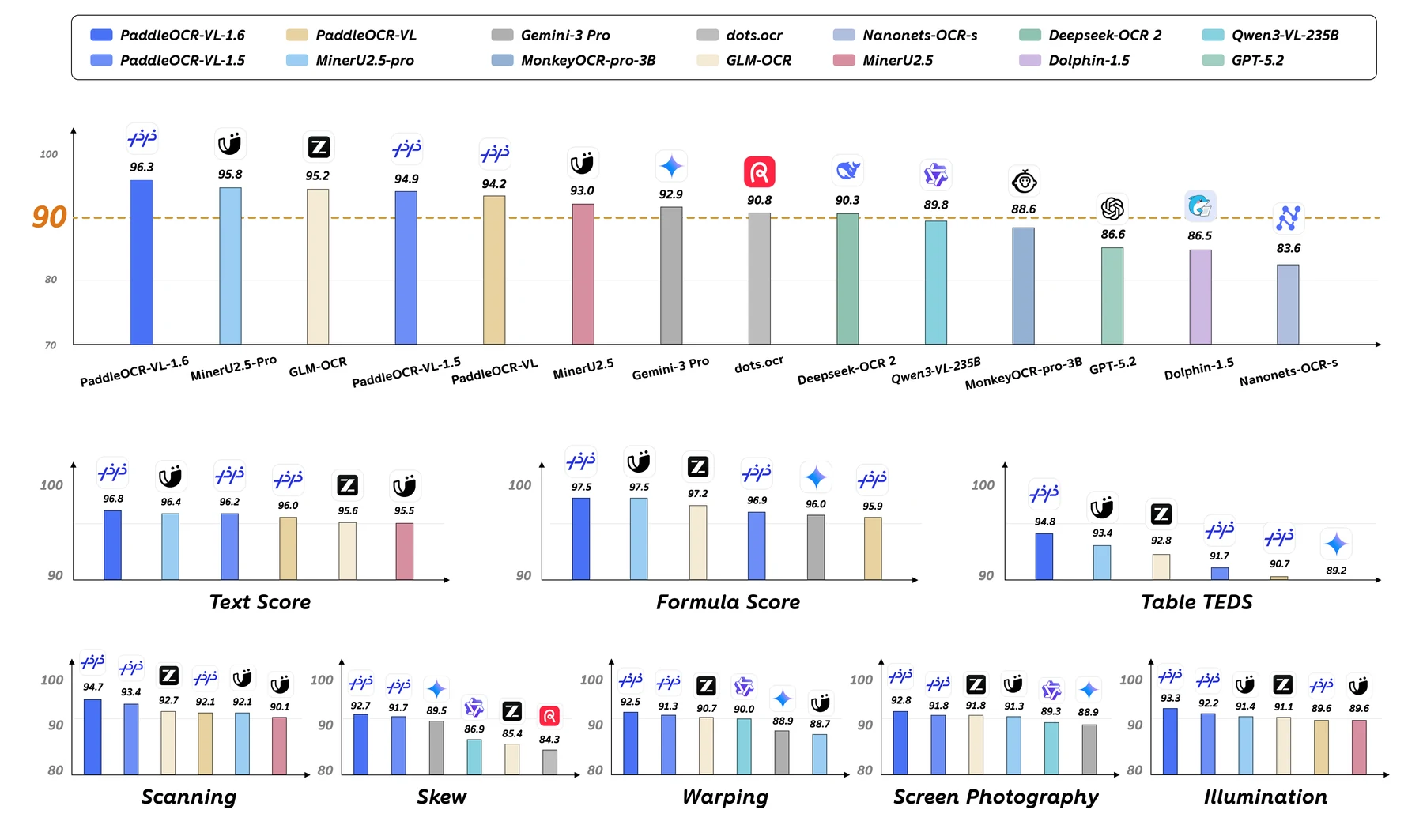
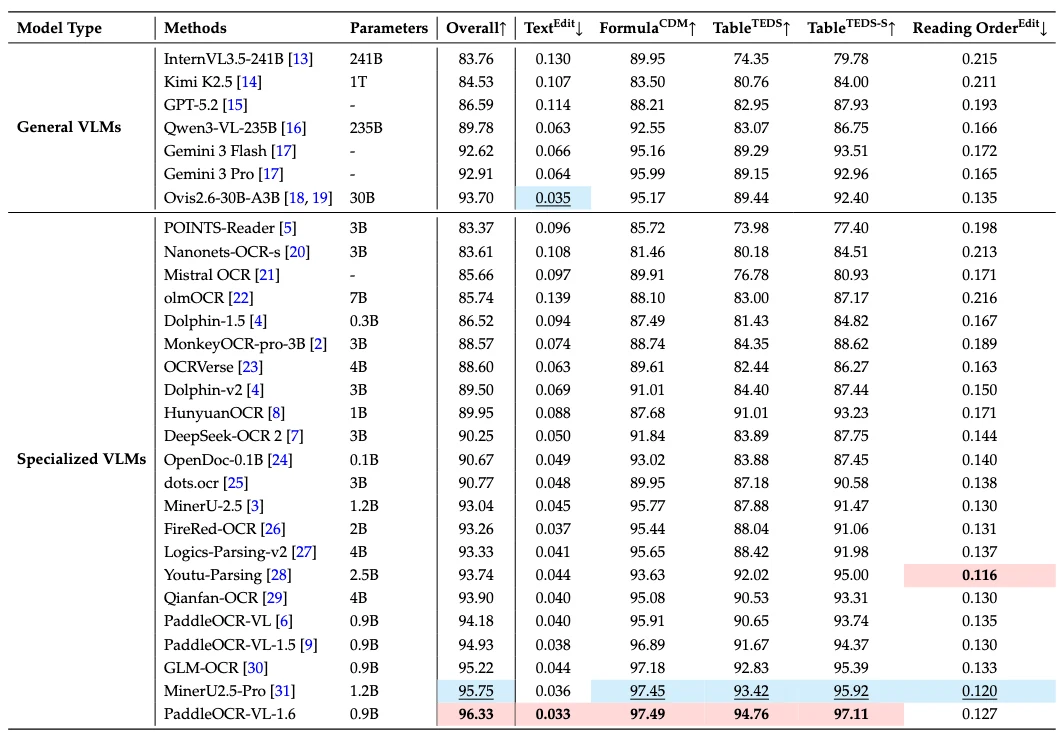
성능 근거는 공식 README와 기술보고서가 모두 OmniDocBench v1.6 overall 96.33%를 전면에 둔다.
README의 OmniDocBench 표 주석은 대부분의 비교 수치가 OmniDocBench official leaderboard에서 왔고, Gemini-3 Pro, Qwen3-VL-235B-A22B-Instruct, PaddleOCR-VL-1.6은 독립 평가라고 적는다.
따라서 이 결과는 유용한 공식 근거이지만, 완전히 동일한 조건의 제3자 재현 benchmark라고 과대해석하면 안 된다.
기술보고서의 ablation은 “왜 모델 크기보다 데이터 엔진과 단계별 후학습이 핵심인가”를 보여 준다.
| 단계 | Overall ↑ | Text Edit ↓ | Formula CDM ↑ | Table TEDS ↑ | Table TEDS-S ↑ |
|---|---|---|---|---|---|
| PaddleOCR-VL-1.5 | 94.93 | 0.038 | 96.89 | 91.67 | 94.37 |
| + CPT | 95.62 | 0.035 | 97.32 | 93.03 | 95.82 |
| + SFT | 96.25 | 0.034 | 97.37 | 94.74 | 97.09 |
| + RL | 96.33 | 0.033 | 97.49 | 94.76 | 97.11 |
가장 큰 도약은 CPT와 SFT에서 나온다.
CPT는 overall을 94.93에서 95.62로, Table TEDS를 91.67에서 93.03으로 올린다.
SFT는 overall을 96.25까지 밀어 올리고 Table TEDS를 94.74까지 올린다.
RL은 96.25에서 96.33으로 작지만 양의 추가 이득을 준다.
즉 보고서가 말하는 story는 “RL이 모든 것을 해결했다”보다, high-value data construction과 staged supervised adaptation이 대부분의 성능을 만든 뒤 RL이 마지막을 다듬었다에 가깝다.
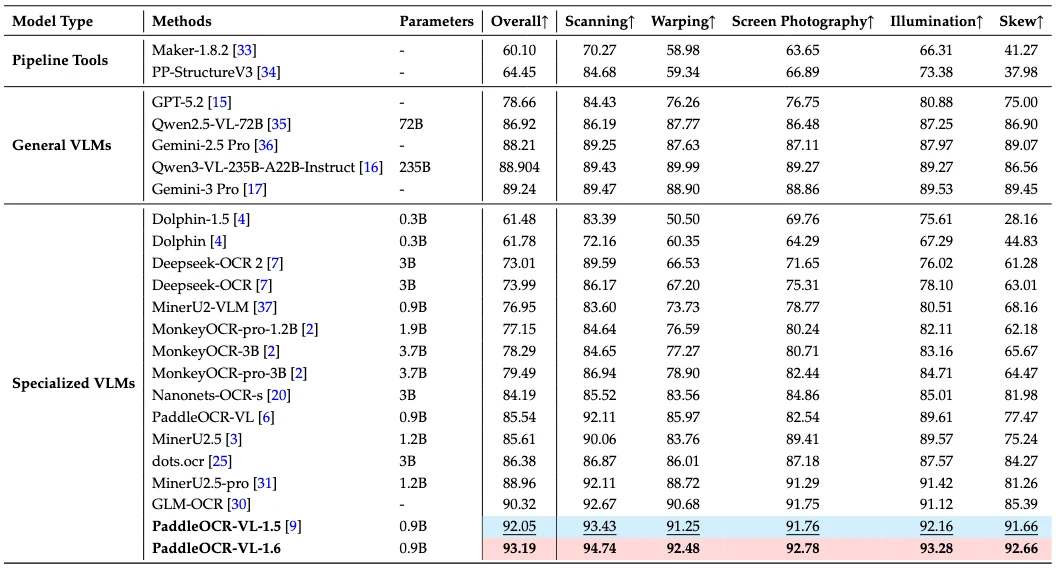
Real5-OmniDocBench도 중요하다.
공식 dataset card/API를 보면 Real5-OmniDocBench는 imagefolder 형식의 공개 dataset이고, API 기준 6,777개 sibling file과 약 16.8GB storage를 가진다.
README는 scanning, warping, screen-photography, illumination, skew 다섯 real-world scenario에서 PaddleOCR-VL-1.6이 새 기록을 냈다고 설명한다.
문서 파싱 모델이 실제 배포에서 흔히 만나는 저품질 입력을 의식하고 있음을 보여 주는 대목이다.
배포 측면에서는 선택지가 꽤 넓다.
기본 PaddleOCR CLI는 paddleocr doc_parser ... --pipeline_version v1.6 형태이고, Python API는 PaddleOCRVL(pipeline_version="v1.6")로 JSON/Markdown 저장을 지원한다.
VLM backend는 vLLM server, SGLang, FastDeploy, llama.cpp server와 연결할 수 있고, 별도 Hugging Face repo PaddleOCR-VL-1.6-GGUF에는 PaddleOCR-VL-1.6-GGUF.gguf와 PaddleOCR-VL-1.6-GGUF-mmproj.gguf가 공개되어 있다.
다만 사용 환경 제약도 명확하다.
모델 카드 설치 예시는 PaddlePaddle 3.2.1 이상과 paddleocr[doc-parser]>=3.6.0을 요구하고, macOS 사용자는 Docker 환경을 쓰라고 적는다.
공식 문서의 hardware matrix도 backend별 지원 상태가 다르다.
예를 들어 PaddlePaddle 자체 경로는 x64 CPU와 Apple Silicon을 지원으로 표시하지만, vLLM/SGLang/FastDeploy 계열은 GPU·CUDA·backend 조합의 제약을 받는다.
실무에서는 “모델 파일이 있다”와 “내 배포 환경에서 전체 문서 파이프라인이 안정적으로 돈다”를 분리해서 봐야 한다.
실무 관점에서의 해석
내가 보기에 PaddleOCR-VL-1.6의 가장 중요한 메시지는 compact model scaling보다 문서 데이터 엔진의 정밀화다.
0.9B라는 크기는 작지만, 남은 오류를 boundary, coverage, supervision 문제로 나눠 찾고, 각각 다른 데이터 보강·라벨 교정·후학습 경로로 처리한다.
이 방식은 OCR/문서 VLM에서 꽤 현실적이다.
문서 오류는 “전체적으로 조금 나쁘다”보다 특정 레이아웃, 특정 문자군, 특정 화질, 특정 표 구조에서 몰아서 터지는 경우가 많기 때문이다.
RAG나 사내 문서 ingestion 관점에서는 두 가지 시사점이 있다.
첫째, PaddleOCR-VL-1.6은 텍스트 OCR만이 아니라 표·수식·차트·도장·spotting을 포함한 document-to-structure 모델로 봐야 한다.
둘째, 전체 품질은 VLM 하나가 아니라 layout detector, crop 전략, post-processing, backend server, Markdown/JSON export까지 합쳐진 pipeline 품질이다.
공식 문서가 VLM-only 실행과 full pipeline 실행을 구분하라고 경고하는 이유도 여기에 있다.
동시에 신중하게 봐야 할 부분도 있다.
성능표는 공식/벤더 발표 자료이고, 일부 비교는 독립 평가라고 명시되어 있어 완전한 외부 leaderboard 재현과는 다르다.
Hugging Face 모델은 custom code와 trust_remote_code 류의 실행 표면을 갖기 때문에 운영 환경에서는 dependency isolation과 security review가 필요하다.
또한 법률, 금융, 의료, 계약서처럼 한 글자 오류가 큰 비용으로 이어지는 문서에서는 96.33 overall이라는 숫자만으로 자동화를 닫으면 안 된다. confidence filtering, 원문 region 링크, human review, task-specific validation이 여전히 필요하다.
그럼에도 PaddleOCR-VL-1.6은 문서 AI의 방향을 잘 보여준다.
더 큰 general VLM을 부르는 대신, 문서 파싱에 맞춘 layout pipeline과 compact VLM, 그리고 약한 데이터 구간을 겨냥한 학습 엔진을 묶는다.
이 조합은 앞으로 문서 기반 에이전트, RAG indexer, OCR-to-dataset pipeline에서 꽤 실용적인 기준점이 될 수 있다.
“문서를 읽는 모델”이라기보다, 문서를 LLM이 쓸 수 있는 구조로 바꾸는 ingestion layer로 읽을 때 가치가 더 선명하다.