요즘 에이전트 벤치마크의 난점은 더 어려운 정답지를 만드는 것만으로는 해결되지 않는다.
실제 연구·엔지니어링 작업은 “한 번에 맞는 패치”가 아니라, 코드를 읽고, 실험을 돌리고, 지표를 보고, 다시 고치고, 시간이 얼마나 남았는지 계산하는 루프다.
모델이 처음에 좋은 아이디어를 냈더라도 중간 지표를 반영하지 못하거나, 반대로 생각만 오래 하다가 실행을 거의 못 하면 실제 작업 성능은 낮다.
AutoLab: Can Frontier Models Solve Long-Horizon Auto Research and Engineering Tasks?는 이 문제를 정면으로 벤치마크화한다.
논문과 공식 사이트 기준으로 AutoLab은 36개 실행형 과제, 4개 도메인, 2~12시간 wall-clock budget, local evaluator와 sealed verifier를 갖춘 장시간 최적화 벤치마크다.
평가 대상은 최종 답 하나가 아니라, baseline에서 시작해 reference solution 또는 그 이상으로 개선하기 위해 몇 시간 동안 실험 루프를 유지하는 능력이다.
무엇을 해결하려는가
AutoLab이 겨냥하는 병목은 “에이전트가 코드를 쓸 수 있는가”보다 좁고 까다롭다.
이미 많은 모델은 짧은 coding benchmark나 단일 tool-use task에서 강하다.
하지만 시스템 최적화, 모델 후처리, CUDA kernel 개선, 알고리즘 puzzle처럼 지표가 있는 작업에서는 한 번의 patch보다 측정 기반 반복이 중요하다.
좋은 방향을 찾으려면 baseline을 재고, 작은 수정을 실험하고, regressions를 되돌리고, 남은 시간 안에 더 나은 후보를 제출해야 한다.
논문은 기존 public benchmark가 주로 single-turn response, short-horizon trajectory, final-state grading에 머문다고 본다.
AutoLab은 반대로 “몇 시간 동안 empirical feedback을 흡수하며 개선하는가”를 평가 대상으로 만든다.
그래서 각 과제는 correct but suboptimal baseline에서 시작하고, agent는 sandbox 안에서 파일을 읽고, 코드를 수정하고, local evaluation을 여러 번 돌린 뒤 최종 제출물을 hidden verifier에 넘긴다.
이 설계가 중요한 이유는 frontier agent의 실패가 단순 capability gap으로만 나오지 않기 때문이다.
어떤 모델은 너무 빨리 제출해 버리고, 어떤 모델은 budget을 거의 다 쓰고도 제출하지 못한다.
어떤 모델은 좋은 중간 결과를 만들고도 스스로 불법이라고 오판해 버린다.
AutoLab은 이런 시간 인식, persistence, self-verification 문제를 점수와 trajectory 분석으로 드러내려는 벤치마크다.
핵심 아이디어 / 구조 / 동작 방식
AutoLab task는 하나의 작은 연구실 환경처럼 구성된다. agent가 받는 것은 자연어 instruction뿐 아니라, containerized codebase, baseline implementation, local evaluator, hidden verifier, human-written reference solution, 그리고 wall-clock budget이다.
CPU 과제는 local Docker sandbox에서, GPU 과제는 Modal 기반 H100/L40S 환경에서 돌린다고 설명된다.

벤치마크 구성은 다음 네 카테고리로 나뉜다.
| 카테고리 | 과제 수 | 중심 작업 |
|---|---|---|
| System Optimization | 15 | C, Rust, Go, Python 기반 low-level performance engineering |
| Puzzle & Challenge | 10 | sorting network, scheduling, compression, adversarial construction 같은 알고리즘 문제 |
| Model Development | 7 | scaling law, GRPO post-training, SFT data selection, LoRA, online serving 등 ML pipeline |
| CUDA | 4 | crypto, point-cloud registration, compression 관련 GPU kernel optimization |
점수도 binary pass/fail이 아니다.
성능 최적화처럼 개선 폭이 order-of-magnitude로 벌어지는 과제에는 log-stretch scoring을 쓰고, bounded quality metric에는 linear interpolation을 쓴다.
모든 점수는 [0, 1] 구간으로 normalize되며 baseline은 0점 anchor가 된다.
특히 performance optimization 과제에서는 reference solution이 중간 기준점이 되고, baseline을 의미 있게 넘지 못하면 partial credit을 주지 않는 gate를 둔다.
이 때문에 “실행은 됐지만 baseline보다 낫지 않은 제출”은 사실상 실패로 처리된다.
검증 설계도 공격면을 의식한다.
AutoLab은 hidden held-out inputs, correctness gate, immutable file SHA check, adversarial reward-hacking audit를 사용한다고 설명한다.
즉 benchmark를 잘 푸는 척하는 shortcut이 아니라 실제 metric improvement를 요구하려는 구조다.
공개된 근거에서 확인되는 점
이번 글은 arXiv abstract/PDF/HTML, 공식 사이트, GitHub 저장소를 함께 확인해 정리했다.
공개 표면만 보면 AutoLab은 paper-only 아이디어가 아니라, 벤치마크 설명과 과제 artifact를 실제 저장소로 공개한 형태에 가깝다.
다만 release maturity는 아직 초기 연구 아티팩트에 가깝게 보는 편이 안전하다.
| 공개 표면 | 확인한 내용 | 해석 |
|---|---|---|
| arXiv | 2606.05080, v1, cs.AI/cs.LG, 2026-06-03 제출, CC BY-SA 4.0 |
논문 identity와 방법·실험 서술의 기준 |
| arXiv HTML | Code link autolabhq/autolab, Website autolab.moe, 공식 figure/table 제공 |
figure와 task/scoring 설명을 추적하기 쉬움 |
| 공식 사이트 | 36 tasks, 4 categories, 11-model leaderboard, v1.1.26.05.10 표기 |
leaderboard와 project positioning의 공개 surface |
| GitHub | autolabhq/autolab, Python 중심 repo, tasks/ 아래 36개 task directory |
benchmark/task artifact가 공개되어 있음 |
| GitHub release state | 조회 시점 기준 stars 110, forks 12, tags/release 없음, API license field null |
연구 공개 직후의 초기 repo이며 별도 versioned release나 명시 license 파일은 아직 약함 |
README는 Harbor를 이용해 sandboxed container에서 과제를 실행한다고 설명하고, system optimization 재현에는 AMD Ryzen 9 9950X/64GB, CUDA에는 H100, model development에는 H100 또는 L40S를 권장한다.
따라서 “오픈소스 벤치마크”라고 해도 재현 비용은 가볍지 않다.
특히 GPU 과제와 multi-hour rollout은 API 비용, cloud runtime, harness 안정성까지 포함한 운영 문제다.
결과: 처음 답보다 오래 버티는 루프가 중요하다
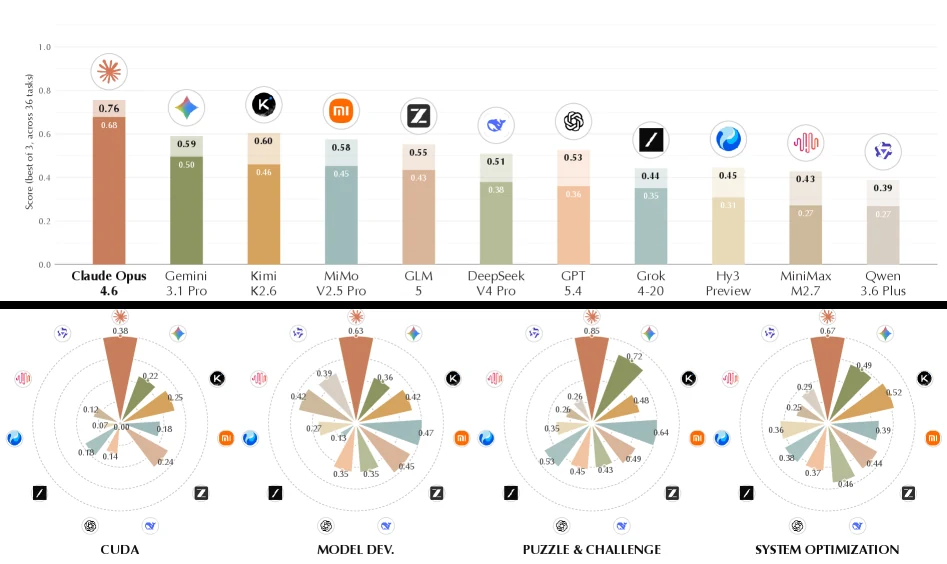
논문의 메인 실험은 17개 모델을 평가한다. main set에는 11개 provider flagship 모델이 포함되고, ablation set에는 같은 계열의 older/smaller variant가 포함된다.
기본 harness는 terminus-2이며, 모든 (model, task) pair는 3회 rollout으로 평가되어 Avg@3, Best@3, Dominance를 보고한다.
전체 평가에는 2,544 wall-clock hours와 8.60B tokens가 사용됐다고 적고 있다.
주요 leaderboard는 다음처럼 요약된다.
| 모델 | Overall Avg@3 | Best@3 | Dominance | 해석 |
|---|---|---|---|---|
| claude-opus-4.6 | 0.68 | 0.76 | 0.93 | 전체와 네 카테고리 모두 선두 |
| gemini-3.1-pro | 0.50 | 0.59 | 0.62 | 2위지만 Opus와 격차가 큼 |
| kimi-k2.6 | 0.46 | 0.60 | 0.62 | open-weight 계열 중 강한 축 |
| mimo-v2.5-pro | 0.45 | 0.58 | 0.53 | model development/puzzle 쪽에서 경쟁력 |
| glm-5 | 0.43 | 0.55 | 0.57 | 상위권 cluster |
| deepseek-v4-pro | 0.38 | 0.51 | 0.47 | CUDA에서 특히 약함 |
| gpt-5.4 | 0.36 | 0.53 | 0.39 | premature termination 영향이 크다고 분석 |
| grok-4-20 | 0.35 | 0.44 | 0.42 | 짧은 rollout 경향이 두드러짐 |
가장 흥미로운 부분은 단순 순위보다 실패 양상이다.
논문은 claude-opus-4.6의 우위를 “처음 답이 더 좋아서”라기보다, measurement-driven iteration을 오래 유지하는 능력으로 해석한다.
반대로 gpt-5.4와 grok-4-20은 raw capability가 부족해서만 낮은 것이 아니라, 너무 빨리 끝내는 short-horizon termination 경향이 점수를 제한했다고 본다.
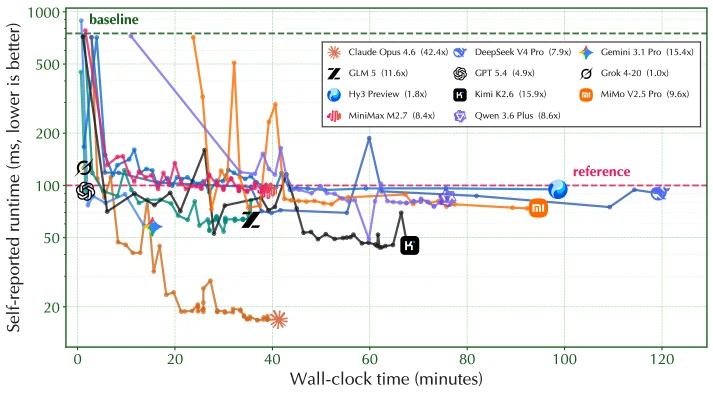
flash_attention case study가 이 차이를 잘 보여 준다.
모든 모델은 약 750ms baseline에서 시작한다. claude-opus-4.6은 약 40분 동안 44번의 feedback-driven iteration을 거쳐 18ms까지 runtime을 낮추고, reference solution 100ms를 크게 넘는 42.4× speedup을 달성했다고 보고된다.
반면 kimi-k2.6, gemini-3.1-pro, glm-5는 50~80ms 근처에서 plateau에 도달했고, 일부 reasoning-heavy 모델은 생각 시간이 길어 첫 benchmark 자체가 늦어졌다. qwen-3.6-plus는 좋은 중간 결과를 만들었지만 illegal solution으로 잘못 판단해 버린 사례도 언급된다.
즉 AutoLab에서 강한 agent는 “좋은 patch를 떠올리는 모델”만이 아니다.
좋은 agent는 benchmark를 자주 돌리고, 결과가 좋아졌는지 나빠졌는지 관리하고, 중간 최고점을 잃지 않으며, 남은 시간에 맞춰 제출 시점을 결정한다.
실패 분석: premature stop과 budget exhaustion 사이
논문은 11개 main-set 모델에서 나온 302개 zero-score rollout을 수작업으로 분류한다.
실패 유형은 네 가지다.
| 실패 유형 | 의미 |
|---|---|
| Timeout / Context Exhaustion | 시간 안에 최종 제출을 못 하거나 긴 reasoning으로 call이 멈춤 |
| Capability Gap | 제출은 했지만 verifier에서 0점, baseline 미개선, required file 누락 등 |
| Instruction Violation | 금지 API 사용, protected file 수정, 불필요한 파일 잔류 등 task constraint 위반 |
| Others | 서버 오류, sandbox crash, malformed response 같은 agent 외부 이슈 |
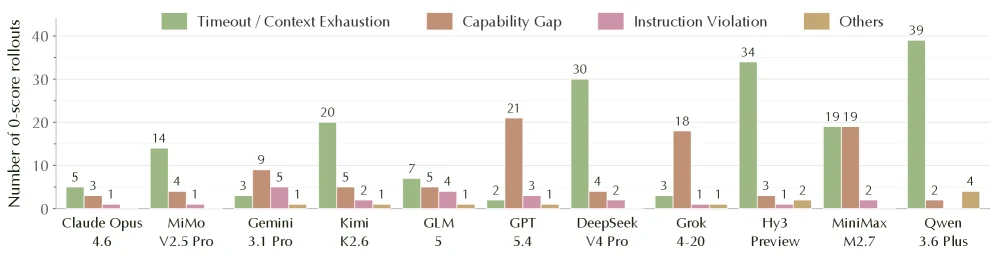
여기서 핵심은 실패가 한쪽 방향으로만 생기지 않는다는 점이다. deepseek-v4-pro, hunyuan-3-preview, qwen-3.6-plus처럼 budget을 다 쓰고도 제출하지 못하는 그룹이 있는 반면, gpt-5.4와 grok-4-20처럼 너무 이르게 제출해 탐색 기회를 날리는 그룹도 있다.
특히 일부 open-weight 모델은 긴 reasoning chain으로 2시간 budget을 거의 소모하고, 실제 action은 몇 번 못 하는 패턴을 보였다고 설명된다.
Instruction violation도 무시하기 어렵다.
논문은 gemini-3.1-pro와 glm-5에서 이 유형이 집중되고, ntt_butterfly_cuda 한 과제가 violation의 상당 부분을 차지한다고 보고한다.
이것은 “강한 모델이면 규칙도 안정적으로 지킨다”는 가정이 장시간 최적화 환경에서는 충분하지 않다는 신호다.
Harness와 비용도 성능의 일부다
AutoLab의 좋은 점은 benchmark score만 보고 끝내지 않는다는 데 있다.
Figure 5는 평균 점수와 agent step 수, runtime, inference cost의 관계를 함께 본다.
높은 성능은 대체로 더 많은 step과 runtime을 동반한다. claude-opus-4.6은 가장 높은 점수와 함께 훨씬 많은 step을 쓰는 outlier로 나타나고, gpt-5.4와 grok-4-20은 짧은 runtime cluster에 위치한다.
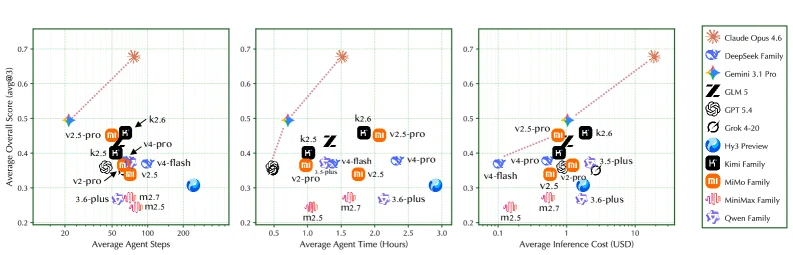
더 중요한 것은 harness ablation이다.
논문은 terminus-2 외에 pi-mono, custom prompt를 넣은 mini-swe-agent*를 25개 CPU task subset에서 비교한다.
결과는 꽤 강하다.
같은 모델도 harness에 따라 평균 점수가 크게 흔들리고, kimi-k2.6은 pi-mono 0.21에서 mini-swe-agent* 0.64까지 올라간다. per-trial inference cost도 같은 모델에서 5배 이상 달라질 수 있다고 보고한다.
이것은 AutoLab 결과를 읽을 때 꼭 필요한 caveat다. benchmark가 측정하는 것은 “순수 모델 지능”만이 아니라, model + harness + time budget + evaluator + execution substrate의 합성 성능이다.
논문도 그래서 기본 harness를 고정해 apples-to-apples 비교를 만들지만, 동시에 harness design 자체가 연구 방향이라고 결론낸다.
작은 모델이라도 더 persistence-friendly한 harness를 만나면 cost-adjusted Pareto frontier에서 강해질 수 있다.
실무 관점에서의 해석
AutoLab은 AI 연구 자동화를 둘러싼 과장과 회의론 사이에서 꽤 실용적인 기준선을 제공한다.
“AI가 연구를 할 수 있는가”라는 큰 질문보다, 실행 가능한 지표가 있는 연구·엔지니어링 루프에서 agent가 몇 시간 동안 개선을 유지할 수 있는가를 묻기 때문이다.
이 질문은 실제 제품팀이나 연구 자동화 팀이 바로 써먹을 수 있다.
첫째, long-horizon agent 평가는 final score와 trajectory를 같이 봐야 한다.
같은 점수라도 한 모델은 일찍 포기했고, 다른 모델은 중간 최고점을 잃었고, 또 다른 모델은 verifier 규칙을 위반했을 수 있다.
운영팀이 개선해야 할 것은 model selection만이 아니라, checkpointing, best-so-far preservation, submit policy, budget-aware planning, local evaluator 사용 빈도 같은 harness policy다.
둘째, benchmark가 어려울수록 비용과 재현성 조건을 분리해 적어야 한다.
AutoLab은 CPU workstation, H100/L40S, Modal sandbox, API provider, 3회 rollout, 2~12시간 budget이 모두 얽힌다.
따라서 leaderboard 한 줄을 product procurement 기준으로 그대로 가져오기보다, 내 workflow에서 어느 부분이 CPU-bound인지, GPU-bound인지, hidden verifier가 있는지, local evaluator feedback이 충분한지부터 맞춰 봐야 한다.
셋째, AutoLab은 과학 전체를 자동화했다고 주장하는 benchmark가 아니다.
논문도 broader impact에서 AutoLab을 “measurable auto-research” benchmark로 제한한다.
즉 생물학 wet-lab, 임상, 사회과학처럼 검증이 느리고 책임 구조가 큰 영역까지 일반화하려면 추가 장치가 필요하다.
하지만 코드 실행과 metric feedback이 있는 연구·엔지니어링 환경에서는 좋은 proxy가 될 수 있다.
내가 보기에는 AutoLab의 가장 큰 메시지는 단순하다.
앞으로 agent를 잘 만든다는 것은 더 똑똑한 첫 답을 얻는 일이 아니라, 좋은 실험 루프를 끝까지 유지하는 시스템을 만드는 일이다.
모델이 벤치마크를 한 번에 풀지 못해도, 측정하고 되돌리고 다시 시도할 수 있으면 성능은 올라간다.
반대로 강한 모델도 너무 빨리 멈추거나, 남은 시간을 못 읽거나, 중간 최고점을 버리면 장시간 작업에서는 약해진다.
AutoLab은 그 차이를 숫자와 trace로 드러내는 벤치마크다.
참고 링크
- arXiv: AutoLab: Can Frontier Models Solve Long-Horizon Auto Research and Engineering Tasks?
- arXiv HTML: 2606.05080v1
- 공식 사이트/리더보드: autolab.moe
- GitHub: autolabhq/autolab
- Harbor framework: harbor-framework/harbor