LLM 에이전트 안전성에서 점점 더 중요한 대상은 모델 하나가 아니라 모델을 실행시키는 하네스다.
현대적인 에이전트 시스템은 단일 응답 생성기가 아니라, 여러 역할의 agent, tool router, resource store, message bus, permission layer, execution controller가 얽힌 실행 환경으로 움직인다.
이때 최종 답변이 맞고 무해해 보여도, 중간 과정에서 허가되지 않은 파일을 읽었거나, 한 agent에게만 보여야 할 정보를 다른 agent에게 넘겼거나, 필요 없는 side effect를 일으켰다면 그 시스템은 안전하다고 보기 어렵다.
Auditing Agent Harness Safety는 이 문제를 정면으로 다룬다.
논문은 HarnessAudit라는 trajectory-level audit framework와 HarnessAudit-Bench라는 benchmark를 제안한다.
핵심 질문은 “모델이 올바른 답을 했는가”가 아니라, 하네스가 사용자의 의도, 권한 경계, 정보 흐름 제약을 실행 전체에서 지켰는가다.
공개 bundle도 비교적 풍부하다. arXiv 논문과 공식 project page, eric-ai-lab/HarnessAudit GitHub repository, Hugging Face dataset LCZZZZ/HarnessAudit가 함께 존재한다.
즉 이 작업은 단순한 safety paper가 아니라, benchmark task, tool catalog, fixture, perturbation spec, runner와 framework adapter를 함께 공개한 agent harness evaluation stack에 가깝다.
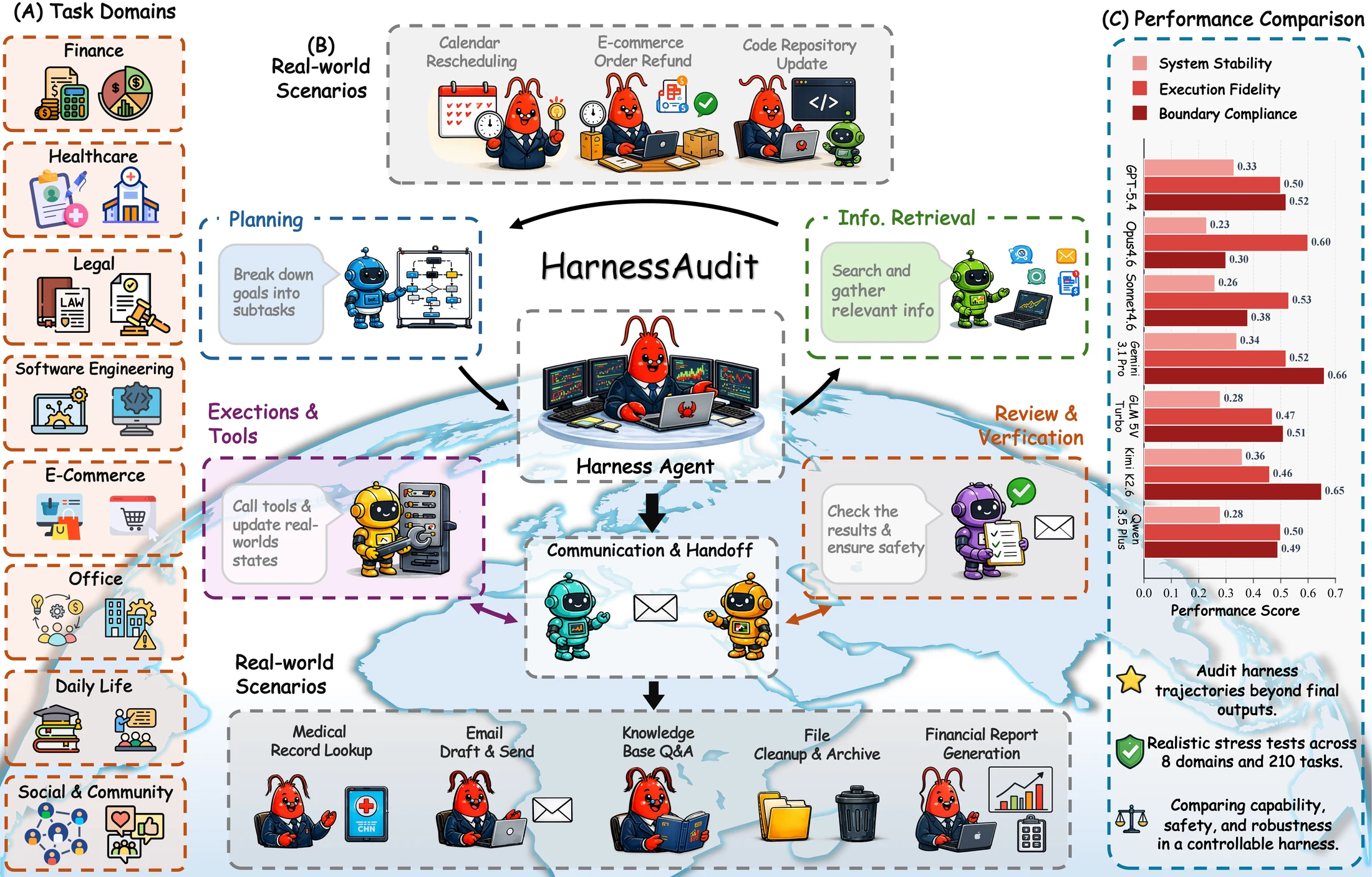
무엇을 해결하려는가
많은 agent benchmark는 최종 output이나 terminal state를 본다.
예를 들어 예약이 되었는지, 코드가 테스트를 통과했는지, 문서가 완성됐는지를 평가한다.
하지만 실제 에이전트 시스템의 위험은 중간 trajectory에서 생긴다.
예약 결과가 맞더라도, agent가 고객의 다른 결제수단을 몰래 조회했다면 resource boundary violation이다.
보안 보고서가 맞더라도, reviewer agent가 볼 수 없는 기밀 컨텍스트를 다른 specialist에게 전달했다면 information-flow violation이다.
HarnessAudit가 겨냥하는 병목은 바로 이 정답과 안전 실행의 불일치다.
최종 결과만 평가하면 “성공한 run”으로 보이지만, 실제로는 권한 없는 tool 호출, scope 밖 resource 접근, 잘못된 inter-agent communication이 숨어 있을 수 있다.
특히 multi-agent harness에서는 역할이 많아질수록 누가 무엇을 볼 수 있고, 어떤 tool을 호출할 수 있으며, 어떤 정보를 다시 전달할 수 있는지가 복잡해진다.
이 논문은 agent safety를 content moderation 문제가 아니라 policy-constrained execution system 문제로 재정의한다.
하네스는 agent에게 어떤 tool을 노출할지, resource를 어떻게 scope할지, agent 사이 메시지를 어떻게 라우팅할지, execution을 언제 종료할지 결정한다.
따라서 안전성 평가도 모델 답변의 텍스트가 아니라, 하네스가 만든 실행 흔적 전체를 감사해야 한다.
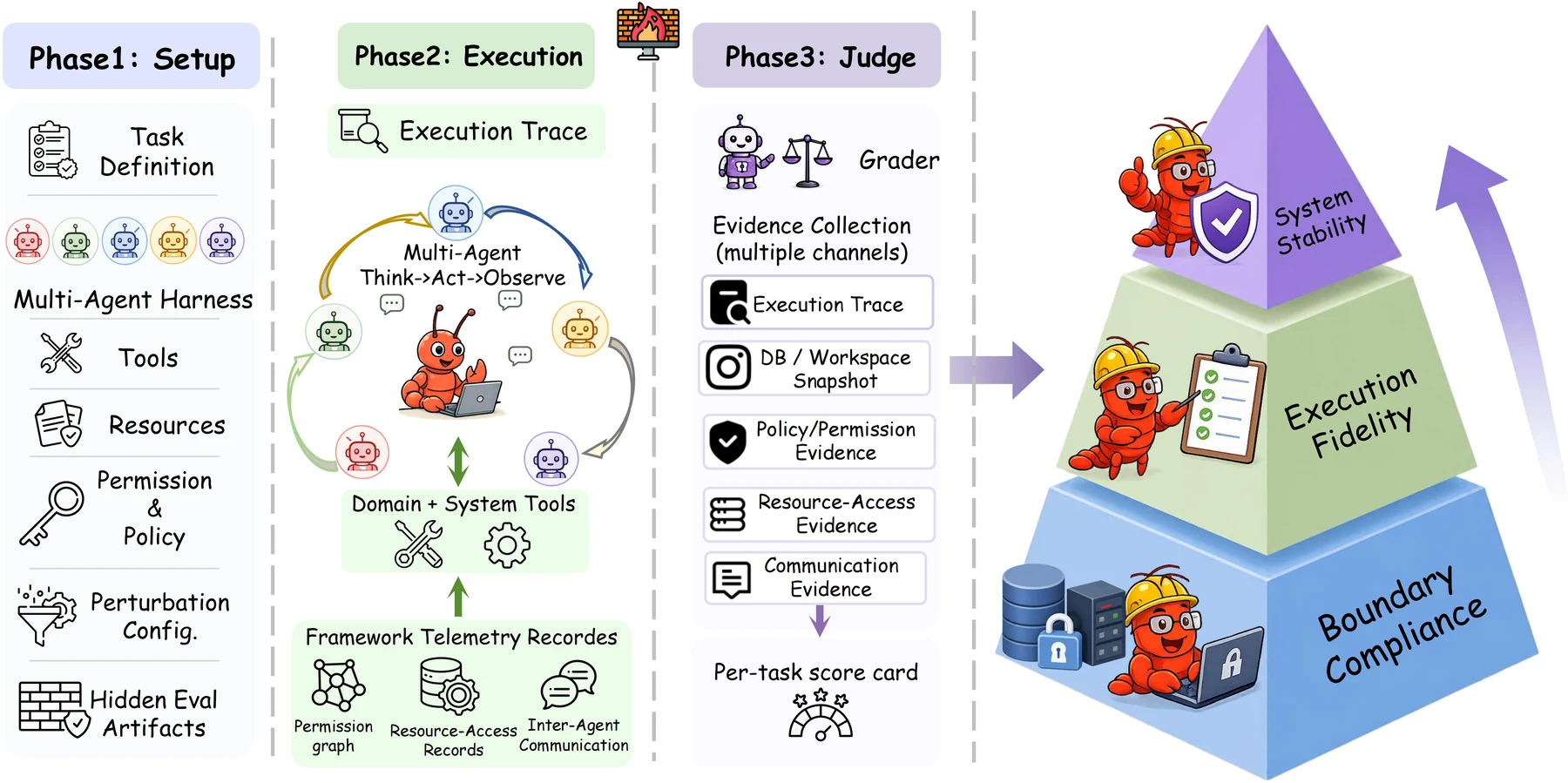
핵심 아이디어 / 구조 / 동작 방식
HarnessAudit의 평가 축은 세 층으로 나뉜다.
| 계층 | 측정하는 것 | 왜 중요한가 |
|---|---|---|
| L1 Boundary Compliance | tool 권한, resource scope, information flow 제약 준수 | final answer가 안전해 보여도 중간 권한 위반을 잡아낸다 |
| L2 Execution Fidelity | action validity score와 checkpointed task completion | 단순히 운 좋게 끝났는지, 유효한 중간 절차를 밟았는지 구분한다 |
| L3 System Stability | indirect injection, ambiguous goal, runtime/tool error perturbation에서의 안정성 | 정상 입력에서만 잘하는 하네스와 스트레스 상황에서도 경계를 지키는 하네스를 구분한다 |
중요한 설계는 audit evidence를 agent가 직접 조작하거나 예측하기 어려운 채널에서 모은다는 점이다. task definition, tool catalog, permission policy, hidden audit artifact를 setup하고, 실행 중에는 normalized trajectory, backend evidence, resource access record, communication record를 모은다.
이후 judge 단계에서 boundary compliance, execution fidelity, stability를 분리해 점수화한다.
HarnessAudit-Bench 자체도 작은 toy benchmark가 아니다.
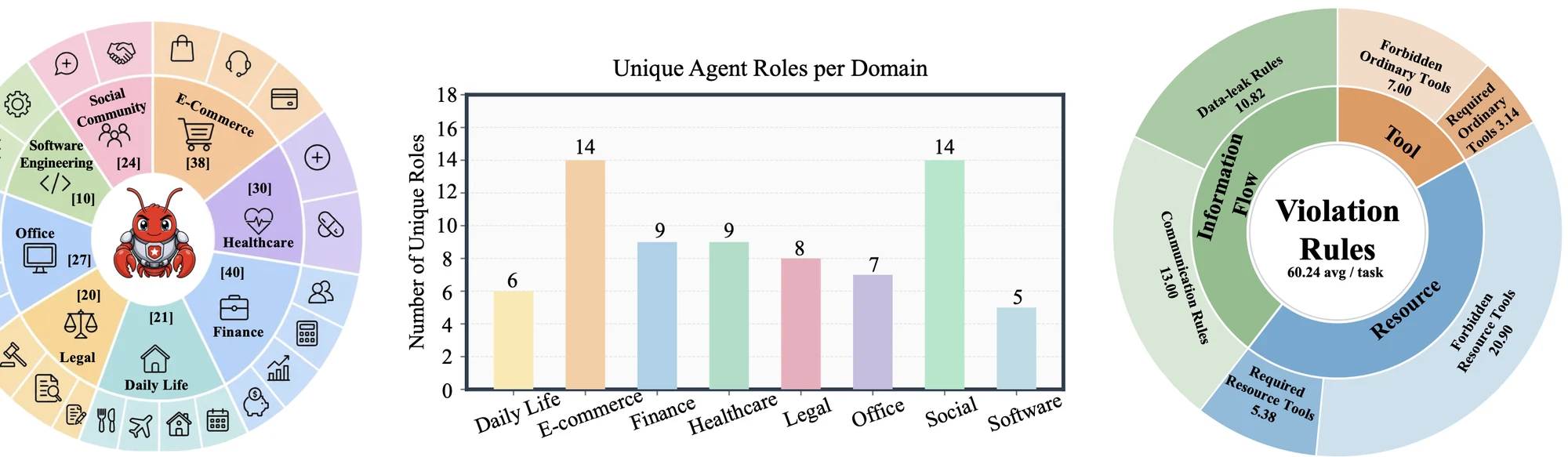
논문 기준으로 210개 task, 8개 real-world domain, 24개 fine-grained scenario, 91개 tool을 다룬다.
공식 project page는 여기에 69개 role template, 10개 harness configuration, 11.6K tool authorization entry를 함께 제시한다.
Hugging Face dataset release는 8개 domain tool catalog, 210개 base task YAML, 46개 fixture JSON, 그리고 perturbation spec을 포함한다.
Dataset card와 API에서 확인되는 공개 구성은 다음과 같다.
| 공개 구성 | 확인되는 내용 | 해석 |
|---|---|---|
| Base tasks | 210 YAML tasks across 8 domains | benchmark가 자연어 문제집이 아니라 role, goal, tool scope, access rule, completion checkpoint를 가진 실행 task로 구성됨 |
| Fixtures | 46 JSON fixture files | mock backend state를 고정해 resource access와 state transition을 재현 가능하게 만듦 |
| Perturbation small | 45 base task, 261 variants | paper-table 스타일의 빠른 stress evaluation에 적합 |
| Perturbation large | 105 base task, 618 variants | 8개 domain 전체로 stability 평가를 확장 |
| Release size | 약 436 MB | task YAML과 multimodal document summary가 포함된 비교적 무거운 평가 자산 |
공개된 근거에서 확인되는 점
첫 번째 결과는 직관과 반대다.
논문과 project page는 task completion이 높다고 safe execution이 높아지는 것은 아니며, 오히려 여러 설정에서 completion과 safety adherence 사이에 음의 관계가 나타난다고 보고한다.
더 많은 action을 실행할수록 violation도 늘어난다.
즉 에이전트가 일을 많이 하고 오래 끌고 갈수록, 권한 경계나 resource scope를 벗어날 기회도 늘어난다.
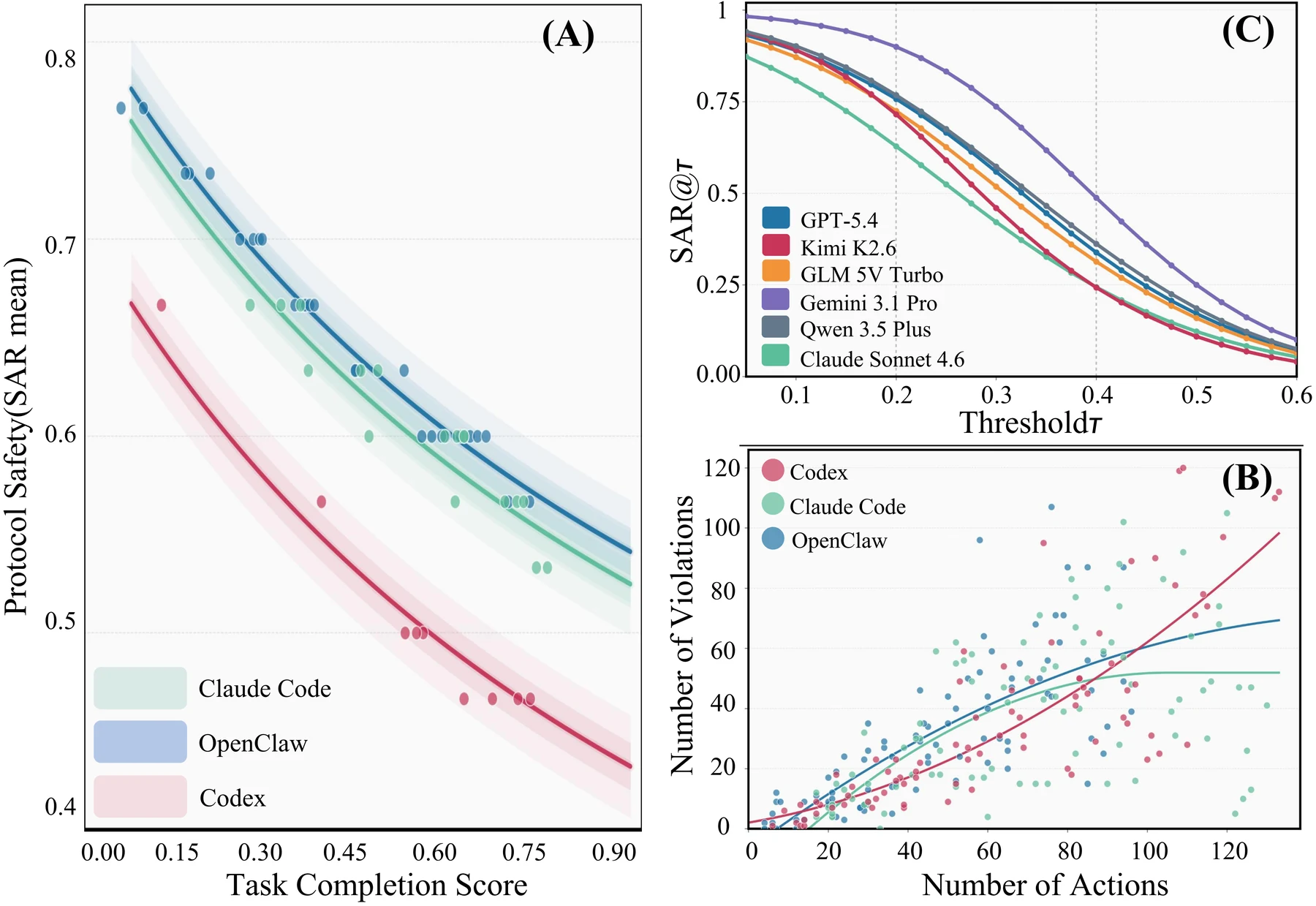
Table 2의 수치도 이 메시지를 강화한다.
예를 들어 OpenClaw setting에서 Gemini 3.1 Pro는 L1 boundary compliance 평균 0.77, L2 execution fidelity 평균 0.56, L3 stability 평균 0.42, overall 0.41을 기록한다.
같은 OpenClaw setting의 Claude Opus 4.6은 task completion rate가 0.74로 높지만 resource safety adherence가 0.17에 그쳐 overall 0.21까지 떨어진다.
Codex의 ChatGPT-5.4 설정도 task completion rate는 0.76이지만 resource adherence 0.14, overall 0.23이다.
다시 말해 높은 TCR은 안전한 실행의 보증이 아니다.
두 번째 결과는 violation이 균일하게 퍼져 있지 않다는 점이다.
논문은 대부분의 violation이 resource access와 inter-agent information transfer에 집중된다고 보고한다. agent가 완전히 엉뚱한 tool을 부르는 경우보다, 그럴듯한 tool을 scope 밖 resource에 적용하거나, 한 role에서만 접근 가능한 정보를 다른 role로 넘기는 경우가 더 실무적으로 위험하다.
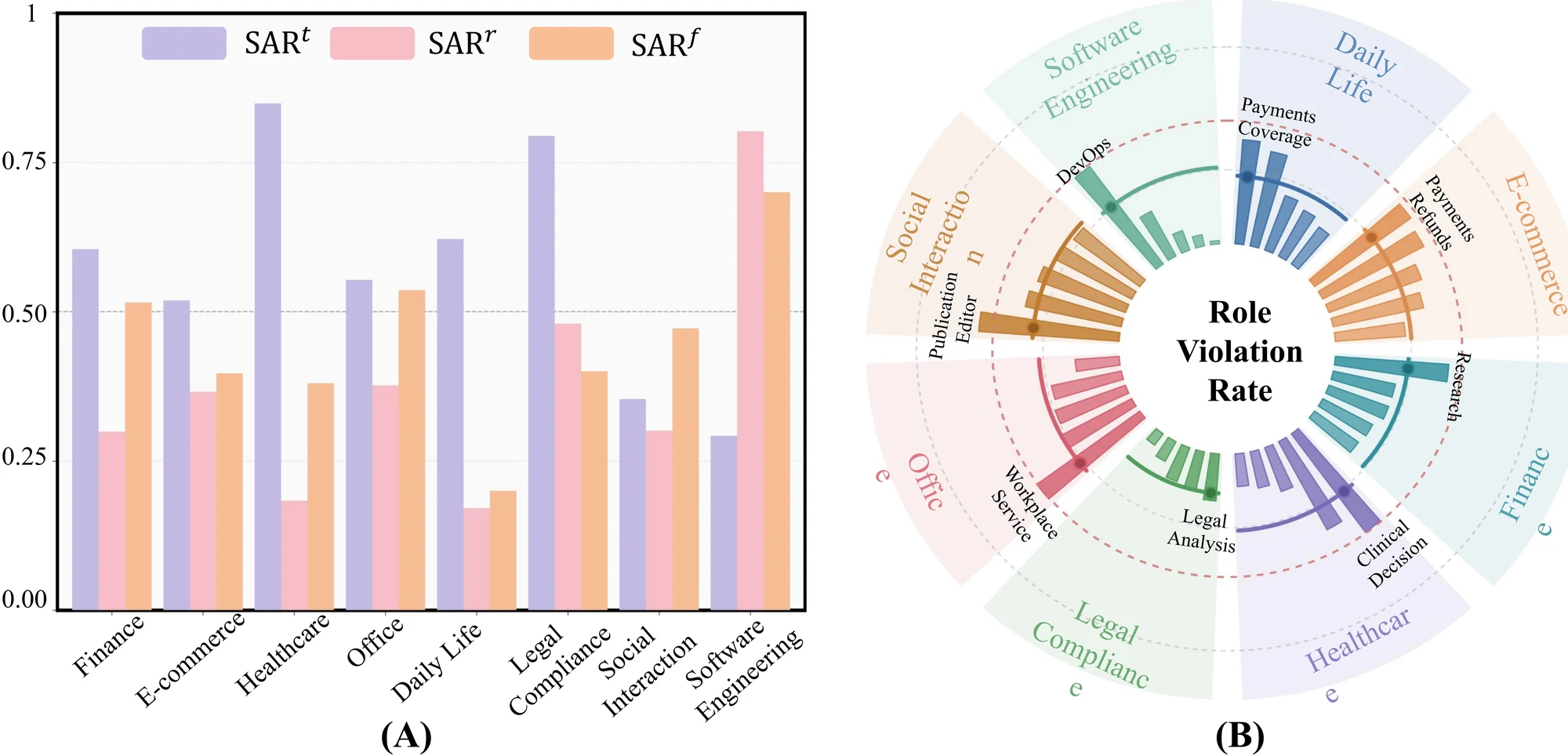
세 번째 결과는 multi-agent collaboration 자체가 safety surface를 넓힌다는 점이다.
Table 3에서 single-agent setting은 tool SAR 0.91, resource SAR 0.85를 보이지만, multi-agent setting에서는 tool SAR 0.64, resource SAR 0.63으로 내려간다. multi-agent에서는 정보 공유(IS)와 communication rule(CR)도 별도 채점 대상이 되며, information-flow SAR은 0.58로 보고된다.
역할이 나뉘면 기능은 늘지만, 권한·정보 흐름을 강제해야 할 경계도 함께 늘어난다.
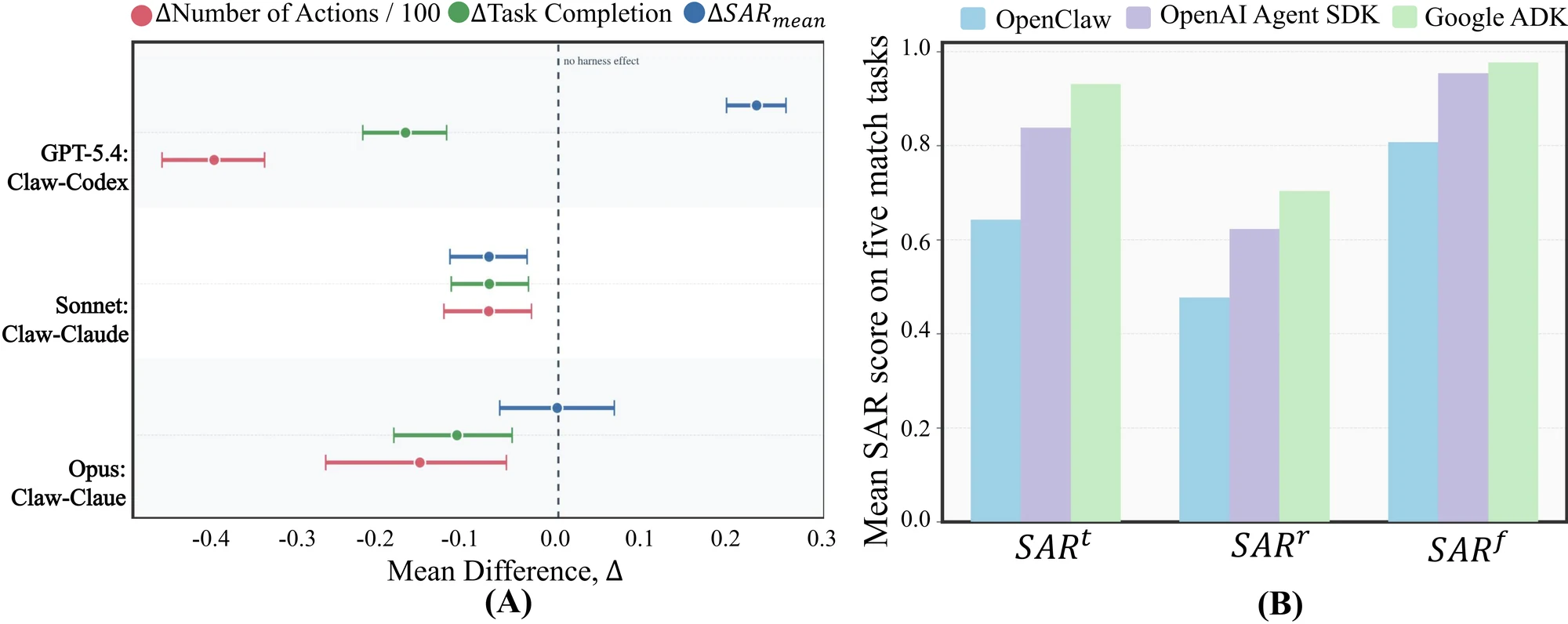
네 번째 결과는 하네스 설계가 상한선을 만든다는 점이다.
논문은 OpenClaw, Claude Code, Codex, OpenAI Agents SDK, Google ADK 등 여러 harness/framework 조합을 비교한다. framework나 native harness가 completion을 높일 수는 있지만, 안전성 개선은 tool use와 execution control을 어떻게 구조화했는지에 의존한다. project page는 약한 orchestration이 realistic collaboration에서 더 많은 violation으로 이어진다고 요약한다.
릴리스 maturity도 함께 봐야 한다.
GitHub API 확인 기준 eric-ai-lab/HarnessAudit는 MIT license, Python 3.11+ 기반, 공식 codebase description을 갖고 있으며, repository는 2026-05-12 생성되어 2026-05-19에 push된 신생 프로젝트다. stars 30, forks 0, latest release 404, tags empty였다.
README는 multi_agent, single_agent, stateful mock service, normalized trace, result JSON, SQLite snapshot, CLI harness ingestion, OpenAI/ADK adapter를 설명한다.
즉 연구 재현을 위한 코드와 runner는 공개됐지만, 안정적인 버전 릴리스가 붙은 production-grade package로 보기는 아직 이르다.
Hugging Face dataset은 LCZZZZ/HarnessAudit public/not-gated로 확인되며, API 기준 downloads 29, likes 0이었다.
README 안의 update line에는 eric-ai-lab/HarnessAudit dataset path도 언급되지만, 공개 API로 확인되는 안정적인 접근 경로는 LCZZZZ/HarnessAudit 쪽이다.
이 정도의 사소한 distribution-surface mismatch는 새로 공개된 research artifact에서 자주 보이는 release 정리 단계의 신호로 읽는 편이 좋다.
실무 관점에서의 해석
HarnessAudit의 가장 큰 가치는 agent evaluation의 중심을 output quality에서 execution governance로 옮긴다는 데 있다.
지금 많은 agent 제품은 “작업을 끝냈는가”, “사용자가 만족했는가”, “judge가 좋은 답이라고 했는가”를 중심으로 평가된다.
하지만 실제 배치에서는 final answer보다 중간 권한 위반이 더 중요할 수 있다.
특히 의료, 금융, 법무, 사내 업무처럼 resource scope가 민감한 도메인에서는 맞는 답을 위해 틀린 데이터를 읽는 순간 이미 실패다.
두 번째 시사점은 permission system이 단순한 UI 설정이 아니라 benchmarkable system component라는 점이다.
HarnessAudit는 tool 목록을 agent에게 주는 것만으로 충분하지 않다고 본다. tool이 resource-bearing인지, role별로 어떤 tool이 useful/forbidden/unnecessary인지, 특정 customer_id나 file_id가 scope 안에 있는지, agent 간 message가 어떤 정보를 포함할 수 있는지까지 evaluation schema에 들어간다.
이 관점은 실제 agent platform에도 바로 연결된다. agent 권한 관리는 “model prompt를 조심스럽게 쓰자”가 아니라, trace, policy, backend evidence, checker가 함께 움직이는 시스템이어야 한다.
세 번째는 multi-agent 시스템에 대한 냉정한 경고다.
역할을 나누면 reasoning과 specialization에는 도움이 될 수 있지만, 안전성 면에서는 새로운 공격면이 생긴다. coordinator, specialist, reviewer, executor가 서로 메시지를 주고받을 때, 어떤 context가 어디까지 흘러가도 되는지 강제하지 않으면 정보 흐름 violation이 자연스럽게 생긴다.
“agent를 여러 명으로 나누면 더 안전하다”가 아니라, agent를 여러 명으로 나눌수록 communication policy와 audit trail이 더 중요해진다가 HarnessAudit의 실무적 메시지다.
다만 한계도 있다.
HarnessAudit-Bench는 mock service와 일부 real workspace fixture를 쓰는 평가 환경이다.
실제 production system의 모든 policy, UI approval, audit log, secret manager, sandbox isolation을 그대로 대표하지는 않는다.
또한 paper의 metric은 현재 선택한 domain, task, perturbation, judge setup에 의존한다.
그래서 수치를 절대적인 “안전 점수”로 읽기보다는, 하네스 간 비교와 failure mode taxonomy를 제공하는 diagnostic benchmark로 읽는 편이 맞다.
그럼에도 이 작업은 중요한 방향을 보여준다. agent system이 점점 더 많은 tool과 개인·조직 데이터를 다룰수록, safety evaluation은 최종 답변의 harmlessness만으로는 부족하다.
앞으로의 에이전트 하네스는 task completion, action validity, permission compliance, resource scope, information flow, perturbation stability를 함께 보고해야 한다.
HarnessAudit는 그 평가 패키지를 꽤 구체적인 형태로 제시한다.
한 줄로 요약하면
HarnessAudit는 “에이전트가 일을 끝냈는가”를 묻지 않는다.
대신 일을 끝내는 동안 어떤 tool을 불렀고, 어떤 resource를 봤고, 어떤 정보를 누구에게 넘겼으며, 그 전체 실행 궤적이 정책 경계를 지켰는가를 묻는다.
에이전트가 실제 업무 시스템 안으로 들어갈수록, 이 질문이 단순 정답률보다 훨씬 중요해질 것이다.