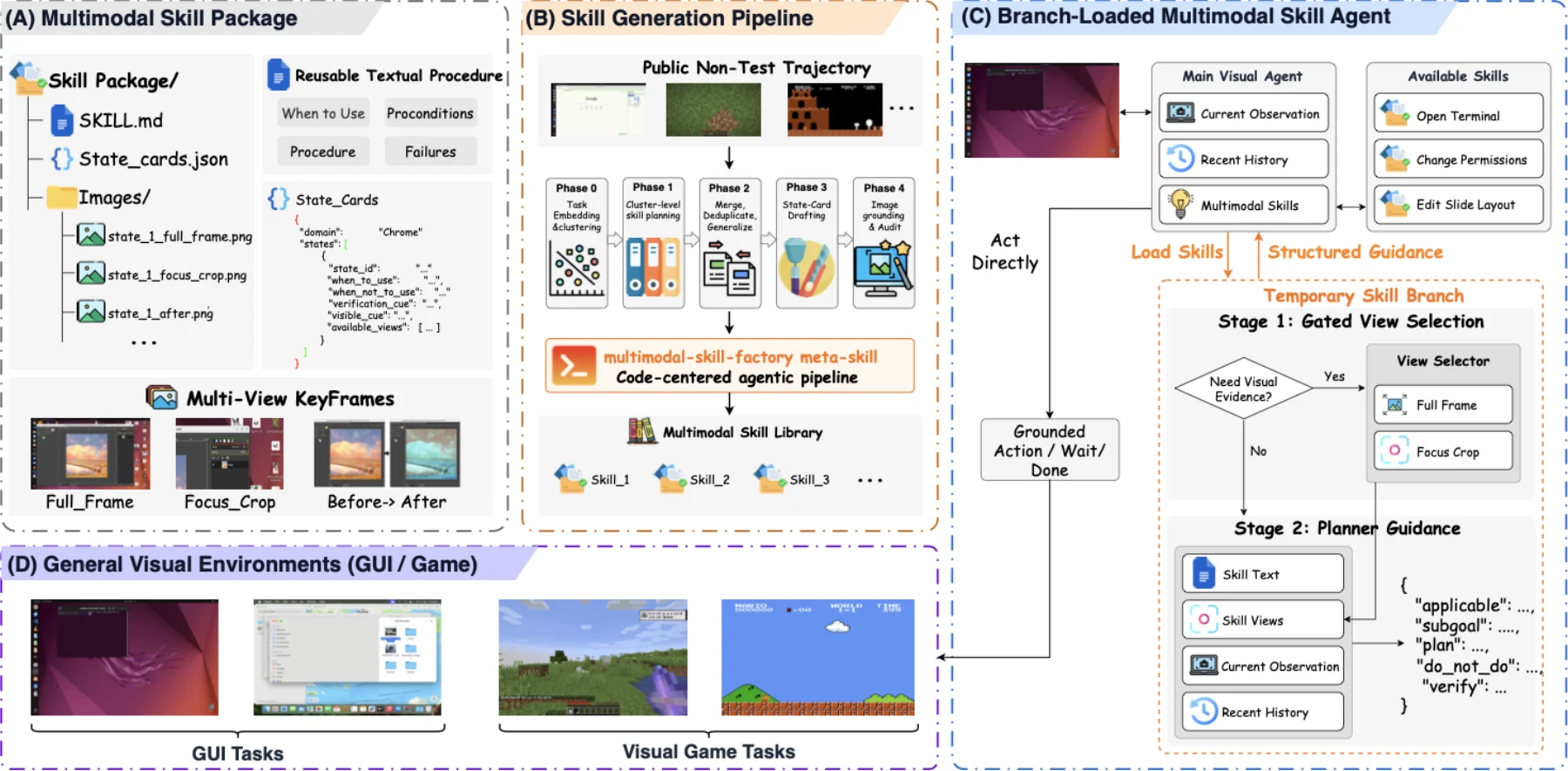
에이전트 스킬을 SKILL.md 같은 텍스트 절차로 저장하는 접근은 코드 에이전트나 CLI 자동화에서는 꽤 자연스럽다. 하지만 화면을 보고 행동해야 하는 visual agent에서는 한계가 빠르게 드러난다. “차트를 만들라”는 절차 자체보다 더 어려운 것은 지금 Calc가 어느 시트에 있는지, 대화상자가 아직 준비되지 않았는지, 완료 상태가 화면상으로 어떻게 보이는지 판단하는 문제다. 즉 시각 에이전트의 스킬은 단순한 프롬프트 조각이 아니라 상태를 인식하고, 진행/실패의 시각 증거를 해석하고, 다음 행동을 제한하는 절차 기억이어야 한다.
MMSkills: Towards Multimodal Skills for General Visual Agents는 이 지점을 정면으로 다룬다. Hugging Face Papers, arXiv HTML, 공식 프로젝트 페이지, GitHub 저장소, Hugging Face Dataset 릴리스를 함께 보면, MMSkills의 핵심은 스킬을 “텍스트 절차”에서 텍스트 + 상태 카드 + 멀티뷰 스크린샷 keyframe으로 확장하는 것이다. 그리고 이 많은 시각 증거를 그대로 main context에 밀어 넣지 않고, 임시 branch가 필요한 evidence만 골라 본 뒤 압축된 guidance를 main agent에 돌려주는 구조를 제안한다.
이 글은 MMSkills를 새로운 benchmark 점수표가 아니라, 시각 에이전트의 외부 절차 기억을 어떤 포맷으로 저장하고 어떻게 불러올 것인가에 대한 시스템 설계로 읽는다.
왜 텍스트 스킬만으로는 부족한가
기존 agent skill 시스템은 대체로 “무엇을 하라”를 저장한다. 함수 호출 방법, 코드 패턴, 툴 사용 순서, 체크리스트 같은 것들이다. 그러나 GUI나 게임 환경에서 reusable skill이 실제로 도움이 되려면 “언제 그 절차를 적용하면 안 되는가”와 “완료 또는 실패가 화면에서 어떻게 보이는가”가 함께 있어야 한다.
MMSkills가 formalize하는 multimodal procedural knowledge는 이 차이를 세 부분으로 나눈다.
- Representation: 스킬 패키지 안에 무엇을 넣을 것인가. 단순 절차뿐 아니라 state card, visual cue, verification cue, full-frame/focus/before/after view가 필요하다.
- Generation: 평가 데이터가 아닌 공개 interaction trajectory에서 어떻게 재사용 가능한 스킬 패키지를 만들 것인가. 논문은 workflow grouping, procedure induction, visual grounding, meta-skill-guided auditing을 사용한다.
- Utilization: 런타임에서 image context를 과도하게 쓰지 않고도 multimodal evidence를 어떻게 참조할 것인가. 여기서 branch loading이 핵심 장치다.
중요한 점은 MMSkills가 “스크린샷을 많이 넣으면 좋아진다”는 주장이 아니라는 것이다. 오히려 논문은 unfiltered image와 state description을 main context에 직접 넣는 방식이 context pollution과 over-anchoring을 만들 수 있다고 본다. 그래서 main agent는 가벼운 후보 스킬 힌트만 들고 있다가, 필요할 때만 임시 branch가 state card와 keyframe을 고른다.
MMSkill 패키지: SKILL.md 옆에 상태와 증거를 붙인다
논문에서 하나의 MMSkill은 대략 (D, P, S, K)로 표현된다. D는 compact descriptor, P는 reusable textual procedure, S는 runtime state cards, K는 각 state card에 대응하는 keyframe bundle이다. 공개 데이터셋의 실제 파일 트리로 보면 더 직관적이다.
<package>/<domain>/<skill>/
├── SKILL.md
├── runtime_state_cards.json
└── Images/
├── full-frame screenshots
├── focus crops
└── optional before/after transition views
SKILL.md는 사람이 읽을 수 있는 절차와 적용 조건을 담고, runtime_state_cards.json은 branch planner가 런타임에 읽을 compact state metadata를 담는다. 이미지들은 좌표를 복사하기 위한 템플릿이 아니라, 해당 절차 상태를 인식하고 검증하기 위한 reference evidence다.
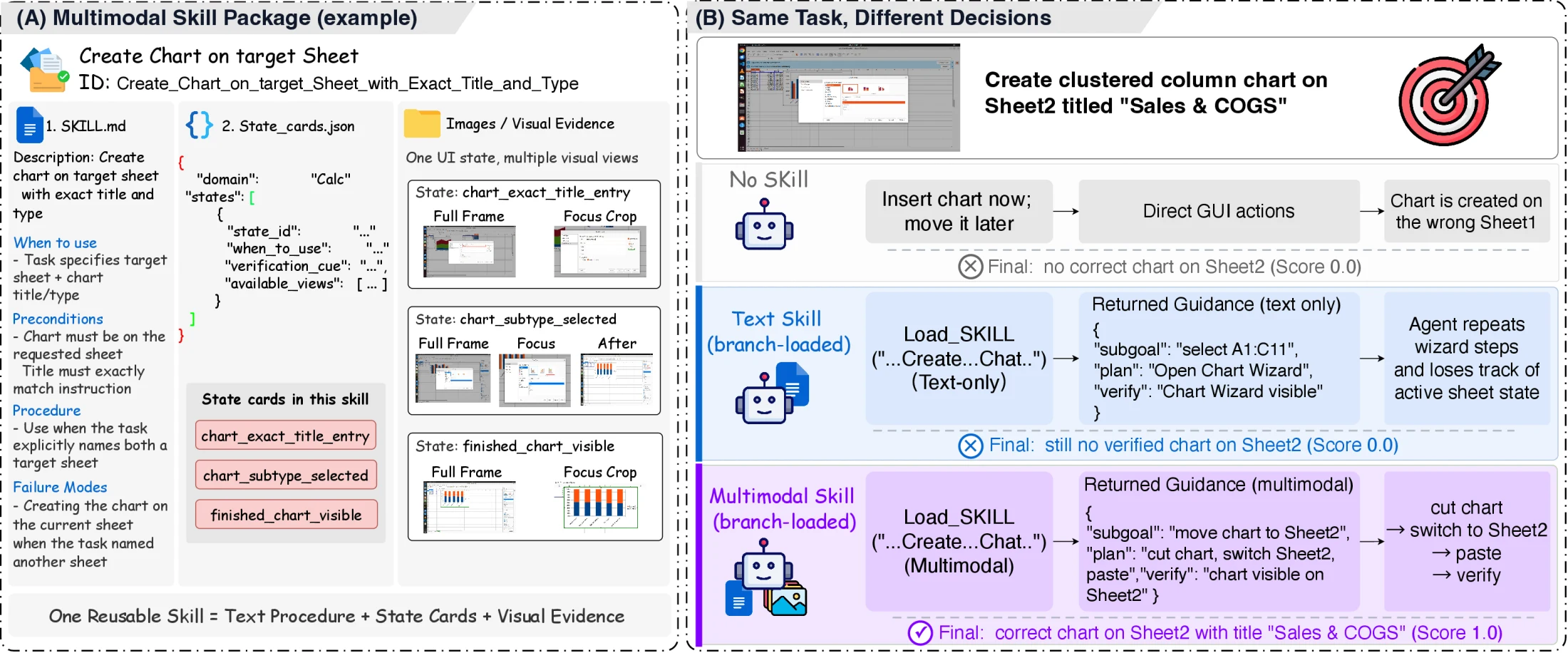
이 예시가 보여주는 핵심은 텍스트 절차의 실패 모드다. “차트 만들기” 절차를 알고 있어도, 현재 active sheet가 목표 시트인지 확인하지 못하면 잘못된 위치에 결과를 만든다. MMSkills는 절차 옆에 state card와 focus crop을 붙여, branch가 live screen과 reference evidence를 비교하도록 만든다. 따라서 main agent가 받는 것은 전체 패키지가 아니라 “이 상태에서는 어떤 subgoal을 수행하고, 어떤 행동은 피하며, 어떤 시각 조건이면 완료로 볼 수 있다”는 structured guidance다.
Branch loading: 스킬 evidence를 main context에서 분리한다
MMSkills의 가장 실용적인 설계 포인트는 branch loading이다. main trajectory 안에 모든 스킬 텍스트와 이미지를 삽입하지 않고, 임시 branch가 두 단계를 수행한다.
- View selection: 현재 observation과 short history를 보고, 후보 MMSkill 중 어떤 state card와 어떤 view가 필요한지 고른다.
- Planner guidance: 선택된 evidence를 live environment와 대조한 뒤, main agent가 쓸 수 있는 compact guidance를 반환한다.
이 구조는 두 가지를 동시에 해결한다. 첫째, main context는 계속 live environment 중심으로 유지된다. 둘째, 시각 evidence는 “필요할 때만” 사용되므로 무관한 screenshot이 action grounding을 방해할 가능성이 줄어든다. 논문 표현대로라면 branch는 skill evidence와 live observation을 alignment한 뒤, executable action grounding은 main agent의 현재 화면에 남겨 둔다.
공개 GitHub 저장소도 이 관점을 반영한다. mm_agents/mm_skill_agent.py를 중심으로 mm_skill, general_text_skill, general 모드를 구분하고, OSWorld integration에서는 --agent_type mm_skill 형태로 실행하도록 안내한다. 또 Codex, OpenClaw, Claude Code에서 쓸 수 있는 agent adapter를 제공해, 전체 515개 스킬 asset을 한 번에 넣는 대신 Hugging Face Dataset에서 필요한 패키지만 검색·다운로드하는 흐름을 제시한다.
릴리스 상태: 논문만이 아니라 데이터셋과 런타임이 같이 있다
이번 작업에서 확인한 companion source는 꽤 풍부하다.
| 표면 | 확인한 내용 |
|---|---|
| Hugging Face Papers | 2605.13527 paper page와 markdown mirror 제공 |
| arXiv | v2 HTML/PDF, figure/table/caption 제공 |
| Project page | overview, demo/case, skill library, submission page 제공 |
| GitHub | DeepExperience/MMSkills, Apache-2.0, runtime/adapter/OSWorld integration 코드 제공 |
| Hugging Face Dataset | zhangkangning/mmskills, public/non-gated, Apache-2.0 card, 515개 공개 skill package 제공 |
Hugging Face Dataset card 기준 공개 패키지는 Ubuntu 247개, macOS 234개, VAB-Minecraft 24개, Mario 10개로 구성되어 총 515개다. 전체적으로 1,488개 state card, 3,141개 view, 3,153개 image가 공개 파일 트리로 배포된다. GitHub 저장소에는 OSWorld-ready runtime subset, task-to-skill mapping, agent adapter, install scripts가 있으며, Dataset은 full package archive에 가깝다.
다만 release maturity는 분리해서 봐야 한다. GitHub API 기준 저장소는 공개이고 Apache-2.0 라이선스를 달고 있지만, 이 글 작성 시점에는 별도 GitHub release나 tag가 없다. 즉 paper + project + dataset + source repo는 이미 공개되어 있지만, 안정 버전이 태깅된 제품형 릴리스라기보다는 빠르게 열린 연구/런타임 bundle에 가깝다.
결과: 점수 상승보다 “행동이 짧아졌다”가 더 흥미롭다
논문은 OSWorld, macOSWorld, VAB-Minecraft, Super Mario Bros에서 no-skill, text-only skill, MMSkills 조건을 비교한다. OSWorld overall만 보면 MMSkills는 모든 보고 모델에서 no-skill보다 높다.
| 모델 | No skill | Text-only | MMSkills | MMSkills - No skill |
|---|---|---|---|---|
| Gemini 3.1 Pro | 44.08 | 40.76 | 50.11 | +6.03pp |
| Gemini 3 Flash | 36.65 | 40.27 | 47.97 | +11.32pp |
| Qwen3-VL-235B | 21.34 | 28.57 | 39.17 | +17.83pp |
| GLM-5V | 28.71 | 36.61 | 38.51 | +9.80pp |
| Kimi-K2.6 | 34.98 | 39.66 | 46.59 | +11.61pp |
| Qwen3-VL-8B-Instruct | 10.78 | 14.93 | 25.40 | +14.62pp |
보수적으로 읽어야 할 부분도 있다. 일부 domain에서는 text-only가 특정 모델에서 도움이 되고, 다른 곳에서는 직접적인 skill load가 오히려 방해가 된다. 하지만 전체 패턴은 분명하다. multimodal evidence가 들어간 branch-loaded skill은 단순 텍스트 힌트보다 더 안정적으로 transfer된다.
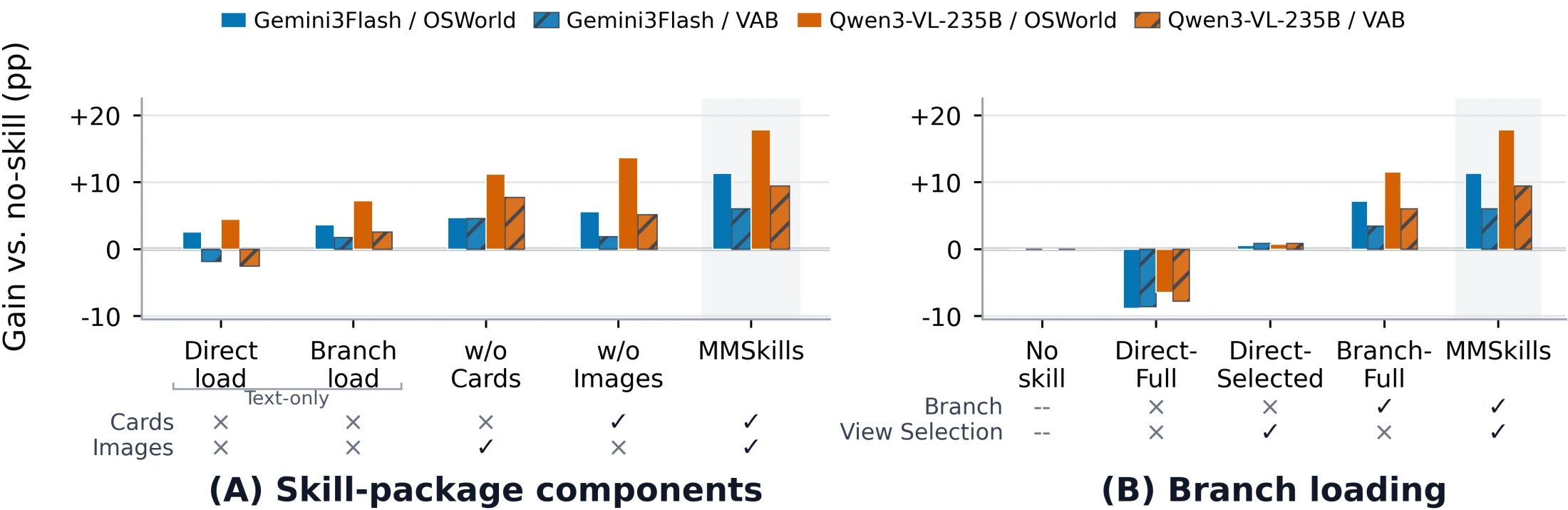
특히 ablation에서 눈에 띄는 것은 direct loading의 실패다. 카드를 쓰지 않거나 이미지가 없는 경우 성능이 낮아지고, branch 없이 직접 full context에 evidence를 넣으면 오히려 성능을 해칠 수 있다. 이는 시각 에이전트의 skill memory가 단순 RAG처럼 “많이 넣기” 문제가 아니라, 어떤 evidence를 언제 격리해서 볼 것인지의 routing 문제임을 보여준다.
MMSkills는 더 많이 생각하게 하기보다 덜 헤매게 한다
Table 3의 skill invocation 분석도 실용적이다. MMSkills는 상담 횟수를 늘리면서도 평균 step 수를 줄인다. 예를 들어 OSWorld에서 Gemini 3 Flash는 text-only 조건에서 평균 15.64 step까지 늘지만, MMSkills에서는 11.86 step으로 no-skill 13.11보다도 짧아진다. Qwen3-VL-235B는 OSWorld에서 no-skill 15.22 step, text-only 13.34 step, MMSkills 9.87 step으로 줄어든다.
이 차이는 “스킬을 불렀기 때문에 비용이 늘었다”가 아니라 “스킬 branch가 잘못된 탐색을 줄였다”에 가깝다. VAB-Minecraft에서도 Gemini 3 Flash는 MMSkills 호출 coverage가 81.90%까지 올라가면서 평균 step은 13.75로 줄고, Qwen3-VL-235B도 27.07 step으로 no-skill보다 7.67 step 짧아진다.
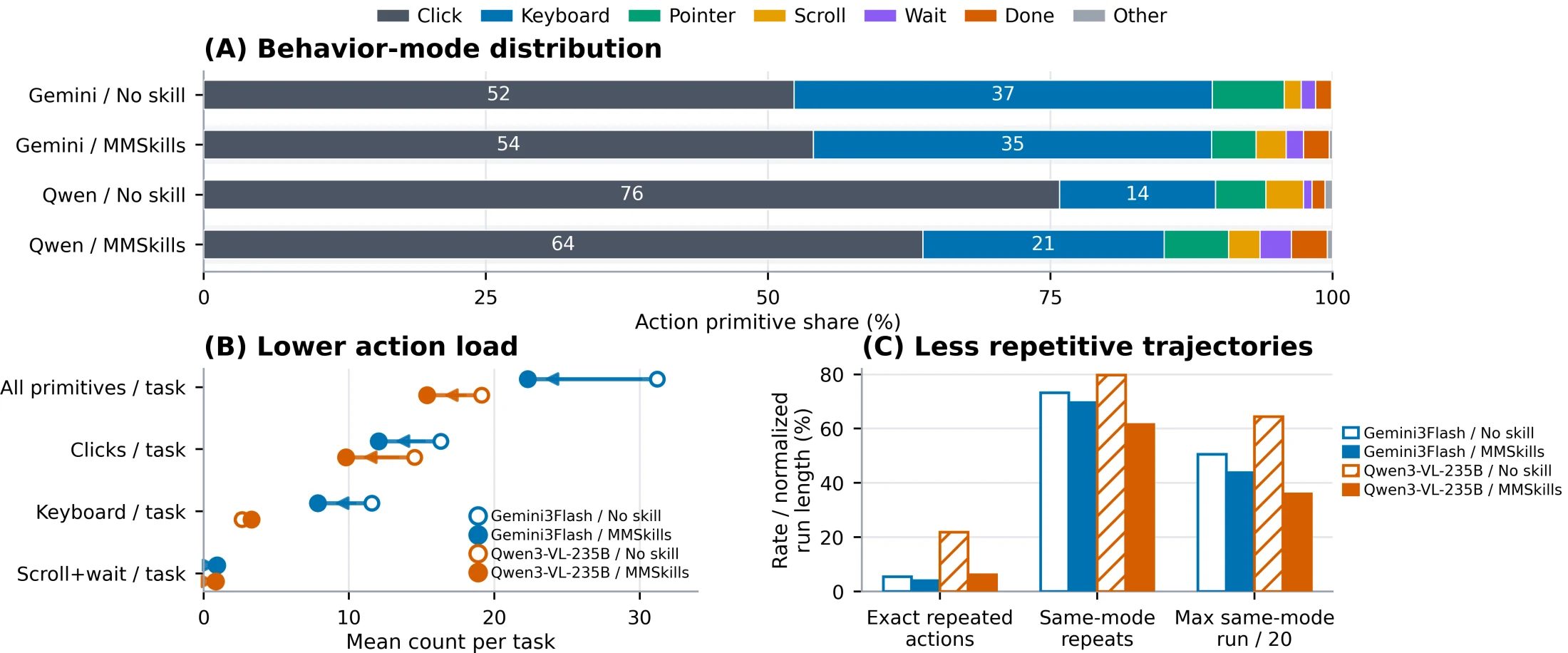
논문은 이를 low-level primitive 관점에서도 분석한다. Qwen3-VL-235B의 OSWorld click share는 75.8%에서 63.7%로 낮아지고, exact repeated actions는 21.8%에서 6.2%로 줄어든다. GUI 에이전트가 실패할 때 흔히 보이는 “같은 곳을 계속 클릭하기”가 줄어드는 셈이다. 이 부분은 점수보다 더 중요할 수 있다. 실제 에이전트 운영에서 체감되는 품질은 benchmark success rate뿐 아니라, 얼마나 짧고 덜 반복적이며 완료 판단을 잘하는지에서 나오기 때문이다.
Case study가 보여주는 것: 스킬은 행동을 대신하지 않고 판단을 좁힌다
MMSkills의 trace figure를 보면 branch guidance가 main agent의 행동을 대체하지 않는다. branch는 “이 상태에서 어떤 스킬이 적용 가능한가”, “어떤 시각 cue가 맞는가”, “다음 subgoal은 무엇인가”를 알려주고, 실제 GUI action은 main agent가 live observation에 맞춰 수행한다.

이 분리는 제품 설계에서도 중요하다. 시각 reference를 action coordinate template처럼 취급하면 화면 해상도, theme, 앱 버전, localization에 취약해진다. 반대로 evidence를 “상태를 확인하는 근거”로만 쓰고 최종 action grounding은 live screen에 맡기면, 스킬은 더 portable한 절차 기억이 된다.
실무적으로 가져갈 만한 설계 원칙
MMSkills에서 바로 재사용할 수 있는 원칙은 네 가지다.
- 스킬은 절차와 적용 조건을 함께 가져야 한다.
when_to_use,when_not_to_use, visible cue, verification cue가 없는 절차는 GUI에서 위험하다. - visual evidence는 전체 context에 넣지 말고 stage를 나눠야 한다. main agent에는 compact hint를 두고, branch가 필요한 state/view만 읽는 구조가 더 안전하다.
- focus crop은 비용 대비 효과가 크다. Table 3에서도 focus crop이 가장 많이 선택된다. 전체 화면은 global context, before/after는 transition/completion evidence로 쓰면 된다.
- 스킬 라이브러리는 dataset이자 runtime artifact다. MMSkills는 논문 표만이 아니라 Dataset file tree, runtime agent, adapter, submission/review flow를 함께 제공한다. 외부 절차 기억을 운영하려면 이 packaging이 필요하다.
이 관점에서 MMSkills는 이전에 다룬 SkillsVote와도 보완적이다. SkillsVote가 “어떤 스킬을 추천하고, 어떤 실행 증거를 라이브러리 진화에 반영할 것인가”라는 거버넌스 문제에 가깝다면, MMSkills는 “시각 에이전트 스킬 자체를 어떤 multimodal package로 표현하고, runtime에서 어떻게 안전하게 consult할 것인가”에 답한다.
한계와 다음 질문
논문도 한계를 명확히 둔다. MMSkills는 source trajectory coverage에 의존한다. 공개 non-test trajectory가 특정 앱/도메인을 충분히 덮지 못하면 좋은 스킬을 만들기 어렵다. 또한 trajectory-to-skill generator와 visual grounding 과정에서 오류가 생길 수 있고, branch loading은 추가 inference cost를 만든다. 안전-critical 또는 embodied domain으로 확장하려면 더 강한 verification과 online repair가 필요하다.
또 하나의 실무 질문은 “스킬 evidence가 오래되었을 때 어떻게 감지하고 교체할 것인가”다. GUI는 앱 업데이트와 UI 변화에 민감하다. MMSkills는 state card와 visual evidence를 구조화해 이 문제를 다룰 발판을 제공하지만, 장기 운영에서는 stale evidence detection, regression test, human review queue 같은 governance layer가 함께 필요하다.
그래도 방향은 분명하다. 시각 에이전트의 외부 기억은 더 이상 텍스트 prompt library만으로 충분하지 않다. 좋은 스킬은 절차, 상태, 시각 증거, 검증 cue, 그리고 evidence를 격리해서 보는 runtime protocol까지 포함해야 한다. MMSkills는 그 패키징과 사용법을 꽤 구체적으로 보여주는 초기 reference implementation이다.
Sources
- Hugging Face Papers: MMSkills: Towards Multimodal Skills for General Visual Agents
- arXiv: 2605.13527
- Project: deepexperience.github.io/MMSkills
- GitHub: DeepExperience/MMSkills
- Dataset: zhangkangning/mmskills